
Vision Transformer with Deformable Attention
🌞欢迎来到一起看论文
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
核心思想
DAT的核心思想主要包括以下几个方面:
可变形注意力(Deformable Attention):传统的Transformer使用标准的自注意力机制,这种机制会处理图像中的所有像素,导致计算量很大。而DAT引入了可变形注意力机制,它只关注图像中的一小部分关键区域。这种方法可以显著减少计算量,同时保持良好的性能。
动态采样点:在可变形注意力机制中,DAT动态地选择采样点,而不是固定地处理整个图像。这种动态选择机制使得模型可以更加集中地关注于那些对当前任务最重要的区域。
即插即用:DAT的设计允许它适应不同的图像大小和内容,使其在多种视觉任务中都能有效工作,如图像分类、对象检测等。
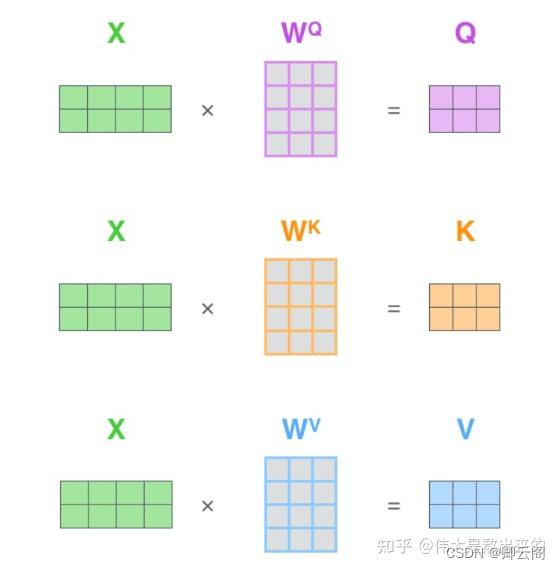
attention机制中的query,key,value
Query、Key的作用是用来在token之间搬运信息的,而Value本身就是从当前token当中提取出来的信息。本质上都是 对X的线性变换。
本文提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。不同于DCN,在整个特征图上针对不同像素学习不同的offset,作者建议学习几组query无关的offset,将key和value移到重要区域(如图1(d)所示),这是针对不同query的全局注意力通常会导致几乎相同的注意力模式的观察结果。这种设计既保留了线性空间的复杂性,又为Transformer的主干引入了可变形的注意力模式。
具体来说:
对于每个注意力模块,首先将参考点生成为统一的网格,这些网格在输入数据中是相同的;
然后,offset网络将query特征作为输入,并为所有参考点生成相应的offset。这样一来,候选的key /value被转移到重要的区域,从而增强了原有的自注意力模块的灵活性和效率,从而捕获更多的信息特征。
本文提出了Deformable Attention,在特征映射中重要区域的引导下,有效地建模Token之间的关系。这些集中的regions由offset网络从query中学习到的多组Deformable sampling点确定。采用双线性插值对特征映射中的特征进行采样,然后将采样后的特征输入key投影得到Deformable Key。
给定输入特征图,生成一个点的统一网格作为一个token,利用Linear layer把我们的query做出来,query留着后面直接做attention。
用这个query做一个offset,(告诉我attention的范围是什么),原始的图像经过down sample,比如上图剩下了4个Reference Points,然后加上offsets,对Reference Points发生了移动,移动到相应的位置,然后在这个位置我们取它临近的4个token,然后经过线性插值操作,这些token叫做Sample Features,然后把插值出来的token送到我们的这个value projection,key projection有了query,key,value,然后一起做attention。由于我们时间上取的token的位置不是一个整数,所以position of embedding也要相应的变化,对其进行Relative Position Bias Offsets 操作,然后一起做attention操作。Offset,首先输入是H*W*C,这个是我们query的尺寸,经过stride=r的,卷积核大小的k*k的,DWConv,然后是激活函数,然后再做一个1*1的convolution,就是对每一个channel做MLP。





旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)