
gpt-4-vision-preview-azure上可以用啦
GPT-4V接口gpt-4-vision-preview简介
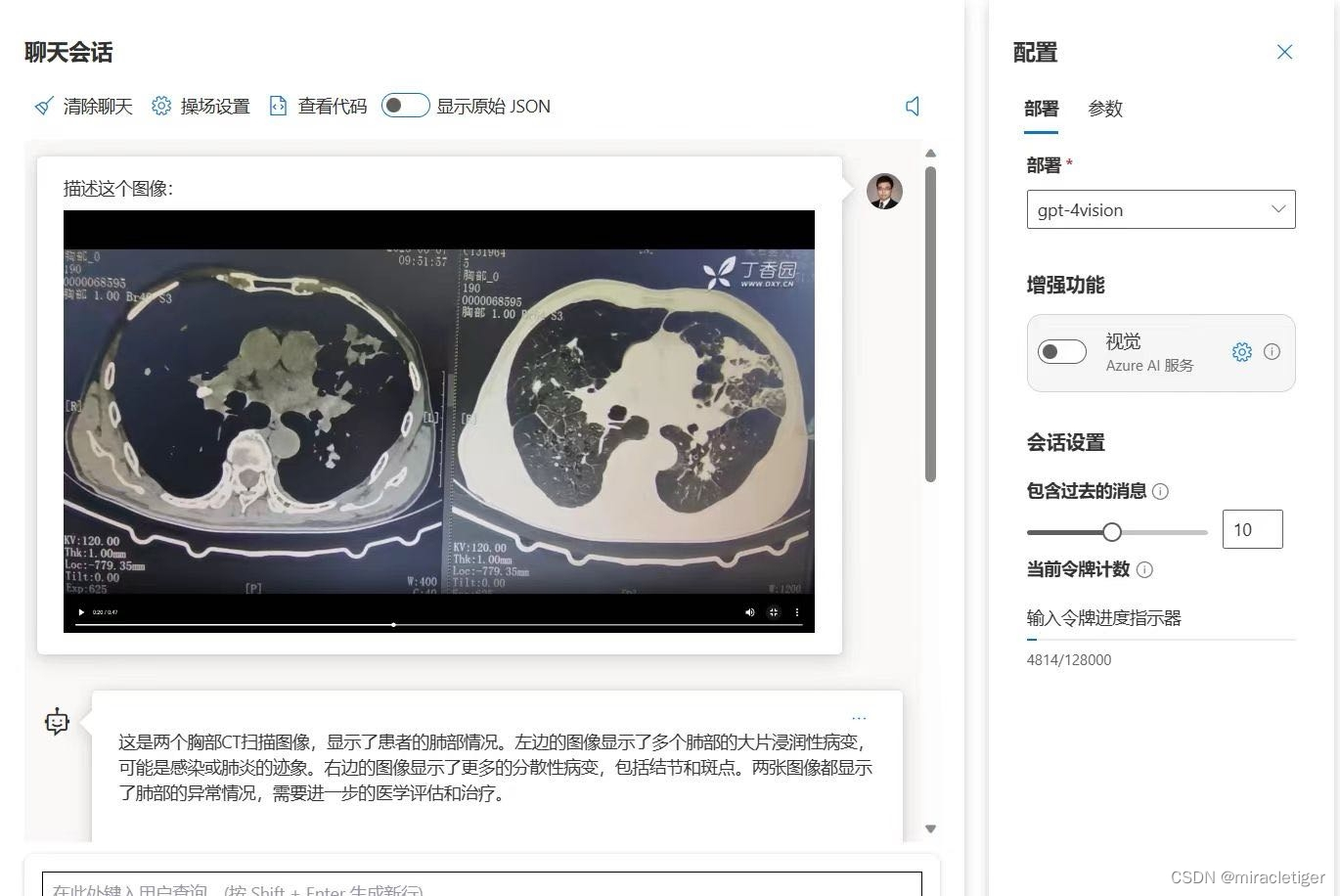
GPT-4V全称是GPT-4 with Vision,是一个多模态的能力,它可以理解图片,为用户解析图片并回答图片相关的问题。
GPT-4V可以准确理解图像的内容,识别图像中物体、计算物体的数量、提供图片相关的洞察和信息、提取文本等。更为强大的是,它可以识别表格转化成markdown格式,也可以针对柱状图等信息图表进行分析。
早先,GPT-4V刚推出的时候只有Web版本可以使用。在2023年11月6日,OpenAI官方推出了gpt-4-vision-preview版本接口,大家可以调用接口实现图像的理解。
与纯文本的大语言模型不同的是,图像的理解包含图片的解析,这部分无法单纯使用文本的tokens计算输入,而官方则是通过图像的清晰度(像素)来计算的。
在azure上使用GPT-4 Turbo with Vision Preview
GPT-4 Turbo with Vision Preview = gpt-4 (vision-preview). 如需部署模型, 在oai.azure.com 左侧边栏Deployments 下选的模型gpt-4. 模型版本 select vision-preview. (⚠️,模型属于公开预览,因此不建议放在生产环境使用)
可部署区域: Australia East , Sweden Central, Switzerland North, West US
api 版本选择用 2023-12-01-preview
GPT-4-Turbo 单订阅单区域 TPM:10K
常见文档:
https://learn.microsoft.com/en-us/azure/ai-services/openai/gpt-v-quickstart?tabs=image&pivots=rest-api
在azure 的Azure AI Studio 使用示例

调用代码
import os
import requests
import base64
# Configuration
GPT4V_KEY = "YOUR_API_KEY"
encoded_image = base64.b64encode(open(IMAGE_PATH, 'rb').read()).decode('ascii')
headers = {
"Content-Type": "application/json",
"api-key": GPT4V_KEY,
}
# Payload for the request
payload = {
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant that helps people find information."
}
]
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800
}
GPT4-V_ENDPOINT = "https://xx.openai.azure.com/openai/deployments/gpt-4-vision-preview/chat/completions?api-version=2023-07-01-preview"
# Send request
try:
response = requests.post(GPT4-V_ENDPOINT, headers=headers, json=payload)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
except requests.RequestException as e:
raise SystemExit(f"Failed to make the request. Error: {e}")
# Handle the response as needed (e.g., print or process)
print(response.json())gpt-4-vision-preview接口的计算逻辑
与此前的文本数据类似,gpt-4-vision-preview也是按照输入和输出的tokens计算。如下所示:
GPT-4-Turbo 价格: Prompt $0.01/1000 token, Completion $0.03/1000 token
| 模型名称 | 输入费用 | 输出费用 |
| gpt-4-vision-preview | $0.01 / 1K tokens | $0.03 / 1K tokens |
但是由于多了图像的输入,因此需要先将图像转换成tokens计算。而图像的转换官方提供了一个计算逻辑,是按照图像区域计算,在官方的文档中一个图像的512*512像素区域(tile)算作170个tokens。每个图片需要额外增加一个固定的85个tokens。
举个例子来说,如果你输入一个150px × 150px的图像,那么它的tokens和输入费用计算如下:
| 计算项 | 计算结果 |
| 每1000个tokens费用(固定) | 0.01美元 |
| 512 × 512区域(tiles) | 1 × 1 |
| 总的区域(tiles)数量 | 1 |
| 基本tokens | 85 |
| 区域(tiles)包含的tokens | 170*1 |
| 总的tokens | 170+85 = 255 |
| 总的费用 | 255*0.01/1000 = 0.00255美元 |
可以看到,一个150px × 150px的图像输入价格是0.00255美元。这里最核心的就是区域(tiles)计算。这里是长*宽的像素数计算的。因此,如果你的图片变成513*150,由于长超过了512,向上取整,那么这里就是2*1是2个区域,上面的tokens就变成2*170+85=425,最终的费用就是0.00425美元。如果是513*513大小,那么区域(tiles)就是4个了,最终的tokens就是4*170+85=765个tokens。
参考资料:
OpenAI最新的GPT-4V的多模态API接口是如何计算tokens的?这些计算逻辑背后透露了GPT-4V什么样的模型架构信息? | 数据学习者官方网站(Datalearner)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)