
【论文阅读】Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
研究动机
状态空间模型(SSMs)在长序列建模方面展现出了巨大潜力,如Mamba。然而,将SSMs应用于视觉数据表示存在挑战,因为视觉数据对位置敏感,且需要全局上下文以理解视觉信息。

本文贡献
-
提出Vision Mamba (Vim) 模型:作者提出了一个新颖的通用视觉模型,称为Vision Mamba(简称Vim),它利用双向状态空间模型(SSM)来实现数据依赖的全局视觉上下文建模,并使用位置嵌入来实现位置感知的视觉识别。
-
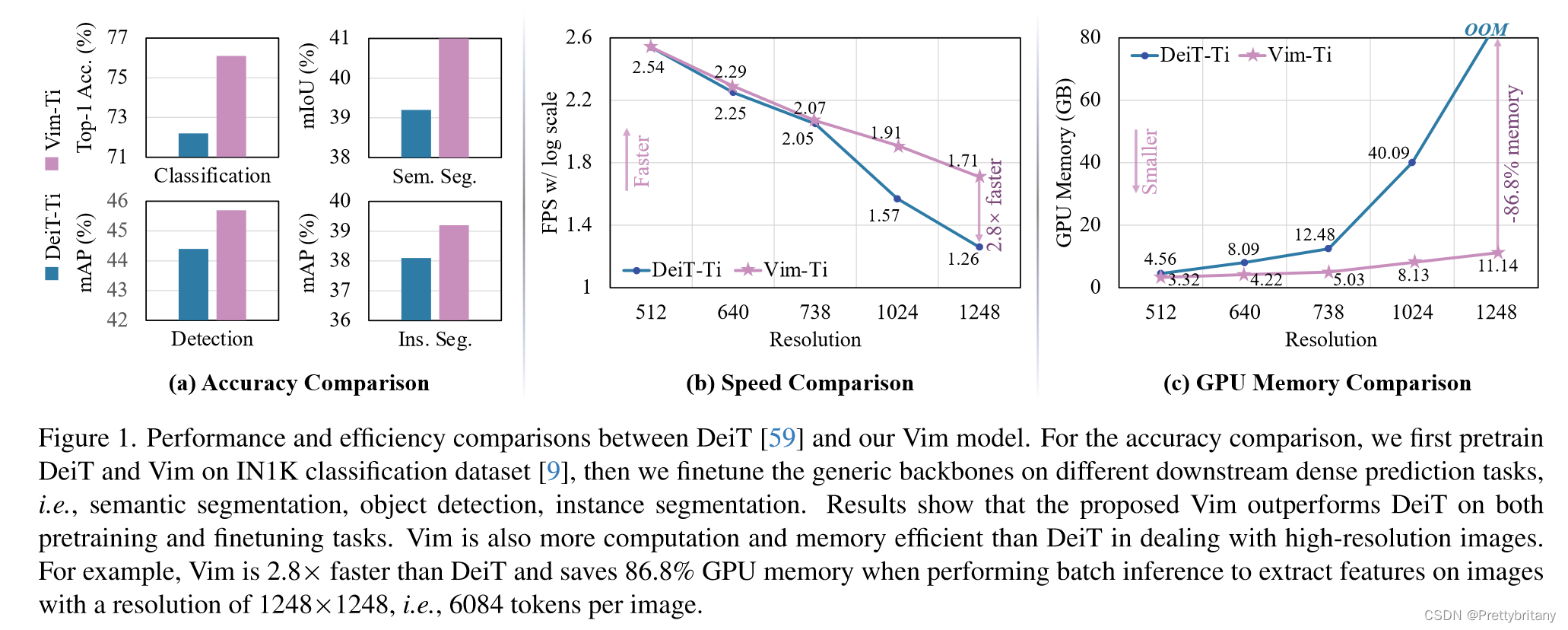
效率与性能的平衡:Vim在保持与视觉Transformer(如DeiT)相同或更好的建模能力的同时,显著降低了计算复杂度和内存使用。具体来说,Vim在处理1248×1248分辨率的图像时,比DeiT快2.8倍,并且节省了86.8%的GPU内存。
-
广泛的实验验证:作者在ImageNet分类、COCO目标检测和ADE20k语义分割等任务上对Vim进行了广泛的实验,结果表明Vim在这些任务上的性能均优于或至少可与现有的视觉Transformer模型相媲美。
研究方法

Vision Mamba (Vim) 的目标是将先进的状态空间模型 (SSM),即 Mamba,引入到计算机视觉领域。首先,将输入的二维图像转换为展平的二维块;接下来,将其线性投影到大小为 $𝐷$ 的向量,并添加位置嵌入:


Vim块

实验
图像分类
表 1 将 Vim 与基于 ConvNet、基于 Transformer 和基于 SSM 的骨干网络进行了比较。与基于 ConvNet 的 ResNet 相比,Vim 表现出更优越的性能。例如,当参数大致相似时,Vim-Small 的 top-1 准确率达到 80.3,比 ResNet50 高 4.1 个百分点。与传统的基于自注意力的 ViT 相比,Vim 在参数数量和分类准确率方面都有相当大的优势。与高度优化的 ViT 变体(即 DeiT )相比,VimTiny 比 DeiT-Tiny 高 0.9 个点,Vim-Small 比 DeiT 高 0.5 个点。与基于 SSM 的 S4ND-ViTB 相比,Vim 以减少 3 倍的参数实现了类似的 top-1 准确率。

语义分割
如表 2 所示,Vim 在不同尺度上始终优于 DeiT:Vim-Ti 比 DeiT-Ti 高 1.0 mIoU,Vim-S 比 DeiT-S 高 0.9 mIoU。与 ResNet-101 主干网络相比,Vim-S 以减少近 2 倍的参数实现了相同的分割性能。
为了进一步评估研究方法在下游任务上(即分割、检测和实例分割)的效率,本文将骨干网与常用的特征金字塔网络(FPN)模块结合起来,并对其 FPS 和 GPU 内存进行基准测试。如图 3 和图 4 所示,尽管该研究在主干网上附加了一个 heavy FPN,但效率曲线与纯主干网(图 1)的比较结果相似。


目标检测和实例分割


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)