
【提示学习论文】Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models论文原理
Test-Time Prompt Tuning for Zero-Shot Generalization in Vision-Language Models(TPT)(NIPS 2022)
- 提出了测试时间提示调优(TPT),可以使用单个测试样本动态学习自适应提示的方法,不需要训练集参与。
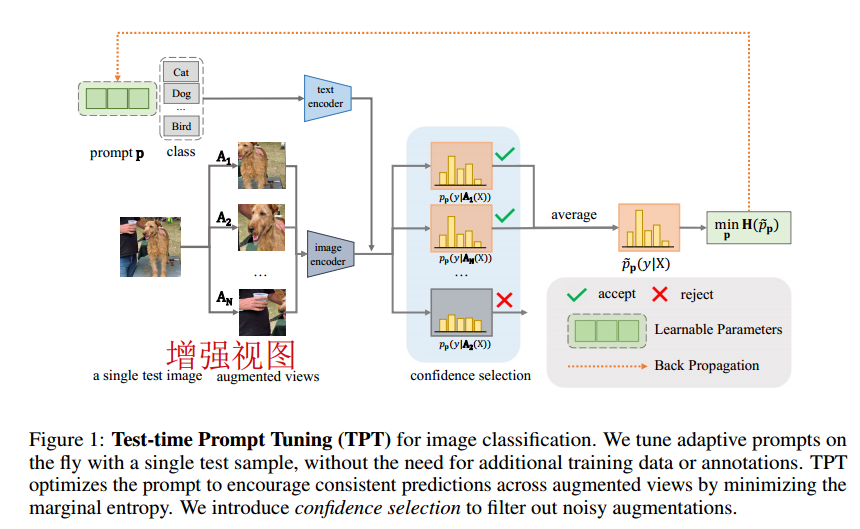
- 对于图像分类,测试样本是一个输入的图像,通过生成多个随机增强视图来执行提示调优,并优化文本提示。调优后的提示符适用于每个任务,不需要任何特定于任务的训练数据或注释。
- TPT没有使用额外的训练数据或注释,保留了zero-shot泛化设置。
1 Introduction
手工提示:a photo of
提示是prompt(可学习向量)
我们在两个不同的下游任务上探索TPT:图像分类和依赖于上下文的视觉推理。对于每个下游任务,我们设计了适合任务性质的定制测试时间调优策略。我们考虑CLIP作为我们的视觉语言基础模型。

对于图像分类,测试样本是一个输入图像。在测试时给定单个样本,我们通过生成多个随机增强视图来执行提示调优,并优化文本提示,以便模型在不同的增强视图中具有一致的预测。这是通过最小化增强视图输出之间的边际熵来实现的。此外,由于一些增强可能会导致误导性的模型预测,我们提出了置信度选择来过滤掉那些“嘈杂”的增强视图。我们放弃了具有高预测熵(即低置信度)的增强视图,并且在一致性优化中只包括高置信度视图。
我们将主要贡献总结如下:
- 我们提出测试时提示调优(TPT),它不需要任何训练数据或注释来优化提示。据我们所知,我们是第一个以zero-shot方式对单个测试样本进行prompt tuning的团队。
- 我们引入置信度选择作为TPT图像分类的一个简单的即插即用模块。它通过过滤掉导致低置信度预测的“噪声”增强,改进了增强视图中的熵最小化。
- 我们在自然分布移位、跨数据集泛化和上下文依赖视觉推理下进行了大量的图像分类实验。TPT以zero-shot的方式改进了CLIP,与需要额外训练数据的提示调优方法相当。
2 Related Work
3 TPT:Test-Time Prompt Tuning
- 首先讨论如何使用手工制作的提示符以zero-shot方式将CLIP应用到下游任务。
- 简要回顾使用下游训练数据的CLIP提示调优方法的最新进展。
- 详细介绍了如何将该方法应用于图像分类任务。
- 介绍了用于上下文相关的视觉推理的TPT,以及该应用程序的背景知识。
3.1 背景
3.2 TPT: Test-Time Prompt Tuning
3.2.1 Why optimize prompts?(为什么要优化提示?)
在推理阶段,唯一可用的信息是没有标签的单个测试样本Xtest,因此,TPT能够基于单个测试样本优化测试时候的提示
p
p
p,目标可以表示为:

- p ∗ p* p∗:优化后的提示
- a r g m i n argmin argmin:表示使得下面损失函数最小化的提示 p ∗ p* p∗
- L ( F ; p ; X t e s t ) L(F; p; Xtest) L(F;p;Xtest):损失函数
- F F F:CLIP 模型
- p p p :提示
- X t e s t X_{test} Xtest :单个测试样本
- 目的是通过测试时的提示调整,使得 CLIP 模型在单个测试样本上的表现最优
- 特别注意,作者的方法不需要任何标签,也不需要zero-shot样本以外的任何数据
3.2.2 TPT for image classification(用于图像分类)
在测试时调整时标签不可用,所以必须选择一个无监督的损失函数进行提示调优。作者设计了一个旨在促进模型在给定测试图像的不同增强视图上的预测一致性的 TPT 目标。使用一组随机增强(记为A)生成测试图像的N个随机增强视图,并最小化平均预测概率分布的熵。公式4为目标表示,公式5为其中的平均概率:

-
P
p
(
y
∣
A
i
(
X
t
e
s
t
)
)
P_{p(y|A_i(X_{test}))}
Pp(y∣Ai(Xtest)):模型在提供提示
p
p
p和测试图像的第
i
i
i个增强视图时产生的类概率向量
提出了置信度选择来筛选出生成高熵(即低置信度)预测的视图
其中,一些增强视图可能缺乏正确分类所需的重要信息,例如,随机裁剪可能已删除重要的图像内容,这会影响分类结果。作者设置了一个置信度阈值 τ τ τ,只有当增强视图的预测熵 H ( p i ) H(pi) H(pi)低于置信度阈值 τ τ τ时,才认为该增强视图是置信度较高的,纳入考虑。
对于每个测试样本,我们会灵活调整阈值 τ τ τ,将N个增强视图的熵取从低到高排,取ρ%处的熵值。
因此,在公式4中的平均概率改进为:

- H(pi):增强视图上预测的自熵
- [H(pi)≤τ]:自熵小于置信度阈值
- 1:啥意思?
3.2.3 TPT for context-dependent visual reasoning(同于上下文的视觉推理)
与图像分类不同的是,每张图像都有一个且只有一个ground-truth标签,在Bongard-HOI中预测的正确性取决于上下文(示例图像),而上下文是二元。
在二元标签的情况下,简单提示策略是为积极和消极,例如“真/假”或“是/否”。
另一方面,使用我们提出的TPT,我们可以直接在测试示例中的示例图像上学习最优token cls。
更重要的是,对于视觉推理,TPT能够以文本提示的形式明确地学习上下文,并借助语言上下文辅助视觉-语言模型的视觉推理。形式上,每个测试中,给出M个图像,TPT目标可以写成:

- y:属于{0,1},

4 Experiments
4.1
数据集:ImageNet-V2、ImageNet-A、ImageNet-R、ImageNet-Sketch
baseline:CoOp、CoCoOp
细节:
- 作者初始化提示为默认的手工提示 “a photo of a”,并基于单个测试图像优化文本输入嵌入空间中的相应 4 个标记。
- 使用随机裁剪,增强单个测试图像 63 次,输入包含原始图像在内的 64 张图像
- 选择置信度最高的前10% 样本(ρ=0.1)
- 使用学习率为 0.005 的 AdamW 优化器,每一步优化提示来最小化边缘熵
结果
- 独立使用 TPT 的准确率比提示集成和现有的少样本提示调整方法更高,包括 CoCoOp。
- 此外,由于 TPT 在测试时进行,因此与现有的基线方法互补。
- 将 TPT 应用于 CoOp 或 CoCoOp 学习到的提示可以进一步提高它们在领域内的 ImageNet 数据的准确性,以及对 OOD 数据的泛化能力。
4.2 跨数据集泛化

表2,将TPT与少样本提示方法比较,发现 TPT 的泛化能力与 ImageNet 训练的 CoCoOp 相当。

图3,原数据集和目标数据集之间没有重叠,我们可以看到少样本提示调整方法的平均准确率改善(矩阵的最后一列)始终为负,这意味着它们的表现比零样本基线要差。而 TPT 则在这 10 个数据集中表现出持续的改进。
图中为相对准确率改善,表示了使用某个方法相对于零样本基线的性能提升程度。

- acc0:相对准确率
- acc:具体方法在特定数据集熵的准确率
- accbase:具体方法零样本基线准确率
5 Ablation Study
消融TPT不同组件的影响
不同参数组上对CLIP进行测试时的优化

图4(a)中,1整个模型、2文本编码器、3视觉编码器、4文本提示。优化文本提示相对于其他实现了最大的性能提升。优化视觉编码器的结果最差,微调图像编码器可能会扭曲预训练特征。
置信度选择的效果
是本文方法的重要部分,置信度将过滤掉少量噪声增强视图。

结果表明,使用置信度最高的前 10% 样本可以获得最高的平均准确率,另外,置信度选择的效果可推广到其他基于熵的测试时优化方法。
效率与准确率之间的权衡
分析影响TPT效率的两个因素
- 增强视图数量N
- 优化步数

图 5(a)中,随着增强视图数量的增加,准确率增加,直到在 N = 64 时达到一个平稳状态。
在图 5(b)中,我们发现将优化步数从 1 增加到 2 可以略微提高准确率(约 0.4%),而多于 2 步则没有显著的性能增益。考虑到性能提升是以线性增加推理时间为代价的,我们使用 1 步 TPT 作为我们的默认设置,这已经能够将零样本 CLIP 的平均准确率提高超过 3%。
6 Conclusion
在这项工作中,我们探讨了如何充分发挥预训练的视觉-语言基础模型作为更好的零样本学习者的潜力。我们开发了测试时提示调整(TPT),这是一种新的提示调整方法,可以根据单个测试样本即时学习自适应提示。我们利用 CLIP 作为基础模型,展示了我们方法在自然分布变化的鲁棒性和跨数据集泛化方面的有效性。TPT 在不需要任何训练数据或注释的情况下提高了 CLIP 的零样本泛化能力。
局限性
虽然 TPT 不需要训练数据或注释,但我们的方法在测试时优化提示时需要一步反向传播。由于 TPT 生成了单个测试样本的多个增强视图,在推理过程中会增加内存成本。
未来方向
TPT 的思想可以应用于其他基础模型,用于各种下游任务,包括其他视觉-语言模型和其他模态的基础模型(例如,预训练的大规模语言模型),以进一步提高它们的零样本泛化能力。这个方向最有趣的部分是设计一个适合模型性质和下游任务性质的测试时目标。此外,还有兴趣探索如何减少 TPT 的内存成本,并使其在计算上更加高效。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)