
论文详解——《InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions》
文章目录
论文地址:《InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions》
Abstract
原文翻译:
摘要与近年来large-scale vision Transformer(ViTs)取得的巨大进展相比,基于卷积神经网络(cnn)的大型模型尚处于早期阶段。本文提出了一种新的large-scale CNN-based foundation model,称为InternImage。
类似于VIT,该模型可以通过增加参数和训练数据获得增益。与最近的CNN聚焦于large dense kernels不同,InternImage采用了可变形卷积作为核心算子,因此我们的模型不仅具有检测和分割等下游任务所需的大的有效接收域,同时也具有受输入信息和任务信息制约的自适应空间聚集。
因此,提出的InternImage减少了传统CNN的bias of inductive bias,使得它可以像VIT一样,可以从海量数据中学习具有大规模参数的更强、更鲁棒的patterns。在ImageNet、COCO和ADE20K等具有挑战性的基准测试中,我们的模型的有效性得到了验证。值得一提的是,InternImage-H在COCO测试开发上实现了65.4 mAP,在ADE20K上实现了62.9 mIoU,超越了目前领先的CNNs和VITs。
1. Introduction
原文翻译
随着Transformer在大规模语言模型中的显著成功[3-8],vision transformer (ViTs)[2,9 - 15]也席卷了计算机视觉领域,成为大规模视觉基础模型研究和实践的首选。一些先行者[16-20]已经尝试将VIT扩展到具有超过10亿个参数的非常大的模型,这超越了卷积神经网络(convolutional neural networks, cnn),显著提高了各种计算机视觉任务的性能极限,包括基本的分类、检测和分割。虽然这些结果表明,在海量参数和数据的时代,CNN不如VIT,但我们认为,当具备类似的operator-/architecture-level designs、scaling-up parameters,massive data时,基于cnn的基础模型也可以实现与vit相当甚至更好的性能。
为了弥补CNN和VIT之间的差距,我们首先从两个方面总结了它们的差异:
(1)从operator层面[9,21,22],VIT的多头自我注意(MHSA)具有长程依赖和自适应空间聚集(见图1(a))。得益于灵活的MHSA, VIT可以从海量数据中学习比CNN更强大、更健壮的表示。
(2)从architecture角度[9,22,23]来看,VIT除MHSA外,还包含一系列标准CNN所不包含的高级组件,如Layer normalized (LN)[24]、前馈网络(FFN)[1]、GELU[25]等。尽管最近的研究[21,22]通过使用具有非常大的核(如31×31)的密集卷积(如图1 ©所示),将远程依赖引入cnn中进行了有意义的尝试,但与目前最先进的大规模VIT[16, 18 - 20,26]在性能和模型规模方面仍有相当大的差距。
在本工作中,我们专注于设计一个基于CNN的基础模型,可以有效地扩展到大规模的参数和数据。具体来说,我们从一个flexible convolution variant-deformable convolution (DCN)开始[27,28]。通过将其与一系列类似于Transformer的定制块级和结构级设计相结合,我们设计了一个全新的卷积骨干网,名为InternImage。

图1: 比较不同的核心operator。
(a)显示了multihead self-attention (MHSA)[1]的全局聚合,其计算和内存开销在需要高分辨率输入的下游任务中是昂贵的。
(b)将MHSA的范围限制在一个本地窗口[2] (Swin Transformer ),以降低成本。
(c ) 是一个具有非常大的核的深度卷积,以模拟长期依赖关系。
(d)是一种可变形的卷积,具有与MHSA相似的良好特性,对于大规模模型足够有效。我们从它开始,建立一个大规模的CNN。
如图1所示,不同于核非常大的CNN如31×31 [22], InternImage的核心算子是一个动态稀疏卷积,常见的窗口大小为3×3,
(1)其采样偏移量灵活,可以从给定的数据中动态学习适当的接收域(可以是长范围,也可以是短范围);
(2)根据输入数据自适应调整采样偏移量和调制标量,实现了VIT式的自适应空间聚集,降低了正则卷积的over-inductive bias;
(3)卷积窗口是一个常见的3×3,避免了由于large dense kernels 导致的优化问题和昂贵的成本[22,29]。
通过上述设计,提出的InternImage可以有效地扩展到大参数大小,并从大规模训练数据中学习更强的表示,在广泛的视觉任务中实现与大规模vit相当甚至更好的性能[2,11,30]。综上所述,我们的主要贡献如下:
(1)提出了一种基于大规模CNN的基础模型——Internimage。据我们所知,它是第一个有效扩展到超过10亿个参数和4亿个训练图像的CNN,并取得了与最先进的vit相当甚至更好的性能,这表明卷积模型也是一个值得大规模模型研究的探索方向。
(2)利用改进的3×3 DCN算子,通过引入长期依赖关系和自适应空间聚集,我们成功地将cnn扩展到大规模设置,并探索了以算子为中心的定制基本块、叠加规则和缩放策略。这些设计有效地利用了操作者,使我们的模型能够从大规模的参数和数据中获得收益。
(3)在具有代表性的视觉任务(包括图像分类、目标检测、实例和语义分割)上对该模型进行了评价,并将模型规模从3000万扩展到10亿,数据规模从100万扩展到4亿,与目前最先进的cnn和大型vit进行了比较。具体来说,我们的模型具有不同的参数大小,可以在ImageNet[31]上始终优于先前的技术。仅在ImageNet-1K数据集上训练,InternImageB的top-1准确率达到84.9%,比基于cnn的对手至少高出1.1点[21,22]。随着大规模参数(即10亿)和训练数据(即4.27亿)的增加,InternImage-H的前一精度进一步提高到89.6%,接近well-engineering ViTs[2,30]和hybrid-ViTs[20]。此外,在具有挑战性的下游基准COCO[32]上,我们的最佳模型InternImage-H获得了最先进的65.4%的box mAP,参数21.8亿,比SwinV2-G[16]高2.3分(65.4比63.1),参数少27%,如图2所示。
2. Related Work
- Vision foundation models.
在具有大规模数据集和计算资源后,卷积神经网络(Convolutional neural networks, CNN)成为视觉识别的主流。从AlexNet[33]中提取,提出了许多更深入、更有效的神经网络架构,如VGG[34]、GoogleNet[35]、ResNet[36]、ResNeXt[37]、EfficientNet[38,39]等。除了结构性设计外,还有更复杂的卷积运算,如深度卷积[40]和变形卷积[27,28]。考虑到Transformer的先进设计,现代CNN通过发现宏观/微观设计中更好的组件,并引入具有长依赖关系的改进卷积[21,41 - 43]或动态权值[44],在视觉任务中表现出良好的性能。视觉基础模型。
近年来,一种新的视觉基础模型集中在基于Transformer的架构上。ViT[9]是其中最具代表性的模型,该模型由于具有全局的接受域和动态的空间聚集,在视觉任务中取得了很大的成功。然而,ViT的全局关注受到昂贵的计算/内存复杂度的影响,特别是在大型特征映射上,这限制了它在下游任务中的应用。为了解决这个问题,PVT[10,11]和Linformer[45]对下采样的键值映射进行全局关注,DAT[46]对值映射中的稀疏样本信息进行变形关注,而HaloNet[47]和SwinTransformer[2]开发了局部注意机制,并使用haloing 和 shift operations在相邻局部区域之间传递信息。
- Large-scale models
扩展模型是提高特征表示质量的一种重要策略,在自然语言处理领域[48]中得到了广泛的研究。受到NLP领域成功的启发,Zhai等人首次将ViT扩展到20亿个参数。Liu等人[16]将分级结构的Swin变压器扩展为一个具有30亿个参数的更深入更宽的模型。有研究人员结合vit和cnn在不同层面的优势,开发出大规模混合vit[20,49]。最近,BEiT-3[17]利用多模态预训练进一步探索了基于ViT的大规模参数的更强表示。这些方法大大提高了基本视觉任务的上限。然而,基于cnn的大型模型在参数总数和性能方面的研究滞后于基于Transformer的体系结构。尽管新提出的cnn[21,41 - 43]通过使用带有非常大的核或递归门控核的卷积引入了长距离依赖,但与最先进的vit相比仍有相当大的差距。在这项工作中,我们的目标是开发一个基于cnn的基础模型,可以有效地扩展到与ViT相当的大规模。
3. Proposed Method
为了设计一个基于cnn的大型基础模型,我们首先从一个灵活的卷积变体,即Deformable convolution v2 (DCNv2)开始,并在此基础上进行一些调整,以更好地适应大型基础模型的要求。然后,我们将调整后的卷积算子与现代backbones (Swin transformer v2,Scaling vision transformers)中使用的先进块设计相结合,构建基本块。最后,我们探讨了基于DCN block的stacking和scaling 原理,构建了一个能够从海量数据中学习strong representations的大规模卷积模型。
3.1 Deformable Convolution v3
原文翻译
- Convolution vs. MHSA(比较普通卷积核MHSA)
以往的著作[21,22,50]对CNN和VIT的区别进行了广泛的讨论。在决定InternImage的核心operator之前,我们首先总结了普通卷积和MHSA之间的主要区别。
(1) 长距离依赖( Long-range dependecies)
具有较大effective receptive fields(长距离依赖)的模型通常在下游视觉任务上表现更好[51-53], 有3x3的regular convolution 堆叠的CNN网络的de-facto effective receptive field相对较少。即使有非常深入的模型,基于cnn的模型仍然不能获得像vit那样的长距离依赖关系,这限制了它的性能。
(2) 动态空间聚合(Adaptive spatial aggregation)
与权值受输入动态约束的MHSA(Multi-Head Self-Attention)相比,regular convolution[54]是一个权值静态的算子,具有很强的inductive biases,例如2D locality,neighborhood structure, translation equivalence。与VIT相比,regular convolution构成的模型具有highly-inductive properties,收敛速度更快,需要的训练数据更少,但它也限制了cnn从web-scale 的数据中学习更一般、更健壮的模式。
- Revisiting DCNv2.(回顾DCNv2)
在卷积和MHSA之间搭建桥梁的一种直接方法是将long-range dependencies和adaptive spatial aggregation引入到regular convolution中。我们从DCNv2[28]开始讲解,这是常规卷积的一个一般变体。给定输入 x ∈ R C × H × W x∈R^{C×H×W} x∈RC×H×W,当前像素 p 0 p_0 p0, DCNv2可以表示为:
Eq.1
y ( p 0 ) = ∑ k = 1 K w k m k x ( p 0 + p k + Δ p k ) \mathbf{y}\left(p_0\right)=\sum_{k=1}^K \mathbf{w}_k \mathbf{m}_k \mathbf{x}\left(p_0+p_k+\Delta p_k\right) y(p0)=k=1∑Kwkmkx(p0+pk+Δpk)
其中 K K K为采样点的总数, k k k为采样点的枚举数。 w k ∈ R C × C w_k∈R^{C×C} wk∈RC×C表示第 k k k个采样点的projection weights, m k ∈ R m_k∈R mk∈R表示第 k k k个采样点的modulation scalar,经sigmod 函数归一化处理。 p k p_k pk为在正则卷积中预定义网格采样的第k个位置 ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , + 1 ) , … , ( + 1 , + 1 ) {(−1,−1),(−1,0),…,(0, +1),…,(+1, +1)} (−1,−1),(−1,0),…,(0,+1),…,(+1,+1), ∆ p k ∆p_k ∆pk为第k个网格采样位置对应的偏移量。
从公式中可以看出(1)对于Long-range dependecies,采样偏移量∆pk是灵活的,能够与short-range或long-range features 相互作用; (2)对于Adaptive spatial aggregation,采样偏移 ∆ p k ∆p_k ∆pk和调制标量 m k m_k mk都是可学习的,且受输入 x x x的制约。因此可以发现DCNv2与MHSA具有相似的良好特性,这促使我们基于该算子开发基于大规模cnn的基础模型。
可变形卷积 (Deformabel Convolution) 参考:
《论文及代码详解——可变形卷积(DCNv1)》
《论文及代码详解——可变形卷积(DCNv2)》
- Extending DCNv2 for Vision Foundation Models(在DCNv2的基础上提出DCNv3)
在通常的实践中,DCNv2通常被用作规则卷积的扩展,加载规则卷积的预训练权值并进行微调以获得更好的性能,这并不完全适合需要从头开始训练的大规模视觉基础模型。在本工作中,为了解决这一问题,我们从以下几个方面对DCNv2进行了扩展:
(1) 在卷积神经元之间共享权重 (Sharing weights among convolutional neurons).
与正则卷积相似,原始DCNv2中不同卷积神经单元具有独立的linear projection weights,因此其参数和存储复杂度与采样点总数呈线性关系,这极大地限制了模型的效率特别是在大规模模型中。为了解决这个问题,我们借用了可分离卷积[55]的思想,将原始卷积权值
w
k
w_k
wk分离为depth-wise和point-wise两部分,其中depth-wise部分由原始的location-aware modulation scalar
m
k
m_k
mk负责,point-wise部分是采样点之间的共享投影权值w。
(2) 引入多分组机制(Introducing multi-group mechanism).
multi-group (head)设计最早出现在分组卷积[33]中,广泛应用于MHSA[1]中的Transformers,通过自适应空间聚合,可以有效地从不同位置的不同表示子空间中学习更丰富的信息。受此启发,我们将空间聚集过程分成
G
G
G组,每个组都有单独的采样偏移
∆
p
g
k
∆p_{gk}
∆pgk和调制规模
m
g
k
m_{gk}
mgk,因此在一个卷积层上的不同组可以有不同的空间聚集模式,从而为下游任务带来更强的特征。
(3) 将采样点间的调制标量进行归一化(Normalizing modulation scalars along sampling points.)
原始DCNv2中的modulation scalars由sigmoid函数进行element-wise的归一化。因此,每个调制标量都在[0,1]范围内,所有采样点的modulation scalars之和并不稳定,在0到k之间变化,这就导致在使用大规模参数和数据进行训练时,DCNv2层的梯度不稳定。为了缓解不稳定性问题,我们将基于element-wise的sigmoid归一化改为基于样本点的softmax归一化。这样,将调制标量的和限制为1,使得不同尺度下模型的训练过程更加稳定。
✨✨✨ 结合上述修改,扩展后的DCNv2标记为DCNv3,可以写成Eqn. (2)。
y ( p 0 ) = ∑ g = 1 G ∑ k = 1 K w g m g k x g ( p 0 + p k + Δ p g k ) \mathbf{y}\left(p_0\right)=\sum_{g=1}^G \sum_{k=1}^K \mathbf{w}_g \mathbf{m}_{g k} \mathbf{x}_g\left(p_0+p_k+\Delta p_{g k}\right) y(p0)=g=1∑Gk=1∑Kwgmgkxg(p0+pk+Δpgk)
其中G为聚合组总数。对于第 g g g个group, w g ∈ R C × C ′ w_g∈R^{C×C'} wg∈RC×C′表示group的location-irrelevant projection weights ,其中 C ′ = C / G C'=C/G C′=C/G 表示gropu dimension。 m g k ∈ R m_{gk}∈R mgk∈R 表示第 g g g个group中第 k k k个采样点的modulation scalar,由沿k维的softmax函数归一化。 x g ∈ R C ′ × H × W x_g∈R^{C'×H×W} xg∈RC′×H×W表示切片后的输入特征图。 ∆ p g k ∆p_{gk} ∆pgk为第 g g g组网格采样位置 p k p_k pk对应的偏移量。
总体而言,DCNv3算子作为DCN序列的扩展,具有以下三个优点:
(1)该算子弥补了regular convolution在远距离依赖和自适应空间聚集方面的不足;
(2)与普通MHSA和密切相关的变形注意等基于注意的算子相比[46,56],该算子继承了卷积的inductive bias of convolution,使得我们的模型在训练数据较少、训练时间较短的情况下更高效;
(3)该算子基于稀疏采样,比之前的MHSA[1]、re-parameterizing large kernel[22]等方法具有更高的计算和内存效率。此外,由于采用了稀疏采样,DCNv3只需要一个3×3 kernel 来学习远程依赖关系,这更容易优化,也避免了在大型内核中使用的额外辅助技术,如re-parameterizing[22]。
3.2 InternImage Model
原文翻译
使用DCNv3作为核心算子带来了一个新的问题:如何建立一个能够有效利用核心算子的模型?
在本节中,我们首先介绍了我们模型的basic block其他integral layers的细节,然后我们通过研究这些basic block 的tailored stacking strategy,构建了一个新的基于cnn的基础模型InternImage。最后,我们研究了该模型的scaling-up 规则,以获得参数增加的增益。

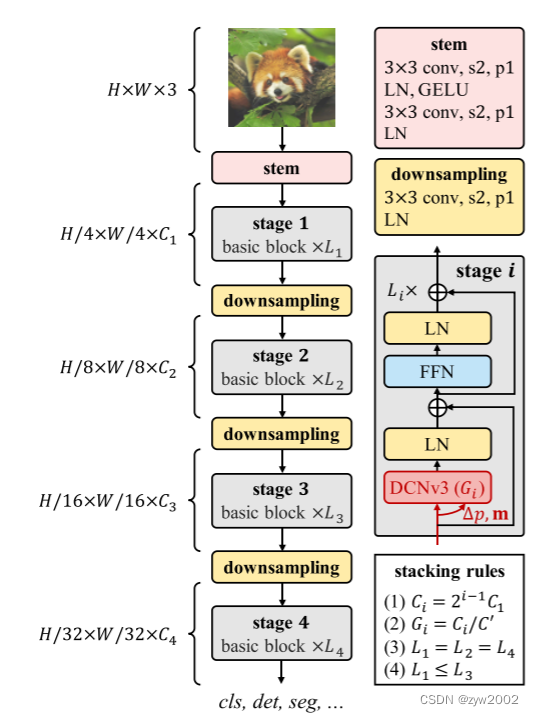
如上图:其中核心算子为DCNv3,基本块由层归一化(LN)[24]和前馈网络(FFN)[1]作为Transformer组成,stem和downsampling遵循传统CNN的设计,其中“s2”和“p1”分别表示stride 2和padding 1。受叠加规则约束,只有4个超参数(C1, C’,L1, L3) 是可以决定模型变量。
- Basic block
与传统cnn[36]中广泛使用的bottleneck不同,我们的基本块设计更接近VIT,它配备了更先进的组件,包括LN[24]、前馈网络(FFN)[1]和GELU[25]。该设计在各种视觉任务中被证明是有效的[2,10,11,21,22]。我们的基本块的细节如图3所示,其中核心算子是DCNv3,sampling offsets和modulation scales是通过将输入特征 x x x通过一个可分离卷积(一个3×3 depth wise convolution,然后是一个linear projection)来预测的。对于其他组件,我们默认使用post-normalization[57],并遵循与普通Transformer相同的设计[1,9]。
- Stem & downsampling layers
为了获得hierarchical feature maps,我们使用convolutional stem和downsampling layers来调整特征映射的大小到不同的尺度。如图3所示,将stem layer置于第一级之前,将输入分辨率降低4倍。它由两个卷积组成,两个LN层,一个GELU层,其中两个卷积的核大小为3,stride为2,padding为1,第一个卷积的输出通道是第二个卷积的一半。类似地,下采样层由一个stride 为2、padding为1的3×3卷积组成,然后是一个LN层。它位于两个阶段之间,用于将输入特征图下采样2倍。
- Stacking rules
为了阐明块叠加的过程,我们首先将InternImage的完整的超参数列示如下:
C i C_i Ci:第 i i i 阶段的通道数;
G i G_i Gi:第 i i i 阶段DCNv3的组号;
L i L_i Li:第 i i i 阶段的基本块数。
由于我们的模型有4个阶段,变量由12个超参数决定,其搜索空间太大,无法详尽地列举并找到最佳变量。为了减少搜索空间,我们将现有技术[2,21,36]的设计经验总结为4个规则
(1)
C
i
=
2
i
−
1
C
1
C_i=2^{i-1}C_1
Ci=2i−1C1
(2)
G
i
=
C
i
/
C
′
G_i=C_i/C'
Gi=Ci/C′
(3)
L
1
=
L
2
=
L
4
L_1=L_2=L_4
L1=L2=L4
(4)
L
1
<
=
L
3
L1<=L_3
L1<=L3
其中第一个规则让后三个阶段的通道号由第一个阶段的通道号
C
1
C1
C1决定。
第二个规则让组号对应阶段的通道号。
对于不同阶段的堆叠块数,我们将堆叠模式简化为“AABA”,即阶段1、2、4的块数相同,且不大于后两条规则中所示的阶段3的块数。
有了这些规则,只需使用4个超参数(C1, C’,L1, L3)就可以定义一个InternImage变量。
选取一个参数为3000万的模型作为origin,将C1离散为{48,64,80},L1离散为{1,2,3,4,5},C’离散为{16,32}。这样可以将原来巨大的搜索空间压缩到30,然后在ImageNet[31]中通过训练和评估,从这30个变量中找到最优的模型。在实践中,我们使用最好的超参数设置(64、16、4、18)来定义原始模型并将其按不同比例缩放。
- Scaling rules
在上述约束条件下的optimal origin model的基础上,我们进一步探讨了[38]启发下的参数标度规则。具体而言,我们考虑两个尺度: 深度D(例如
3
L
1
+
L
3
3L_1+L_3
3L1+L3)和宽度
C
1
C_1
C1,并使用
α
、
β
α、β
α、β和复合因子
φ
φ
φ对两个维度进行尺度变换。
缩放规则可以写成
:
D
′
=
α
φ
D
:D'= α^φD
:D′=αφD,
C
1
′
=
β
φ
C
1
C'_1 = β^φ C_1
C1′=βφC1,其中α≥1,β≥1,
α
β
1.99
≈
2
αβ^{1.99}≈2
αβ1.99≈2。
在这里,1.99特定于InternImage,通过将模型宽度加倍并保持深度不变来计算。实验发现,最佳缩放设置为α = 1.09, β = 1.36。
然后在此基础上构造不同参数尺度的InternImage变量,即InternImage- t /S/B/L/XL,其复杂度与ConvNeXt[21]相似。为了进一步测试该功能,我们构建了一个更大的InternImage-H,具有10亿个参数,为了适应非常大的模型宽度,我们还将组维C’更改为32。表1总结了这些配置。

4. Experiment
我们分析和比较了InternImage与领先的cnn和vit的代表性视觉任务,包括图像分类、目标检测、实例和语义分割。
4.1 Image Classification
表2为不同尺度模型的分类结果。由于具有类似的参数和计算成本,我们的模型可以与最先进的基于变压器和基于cnn的模型相媲美,甚至更好。例如,InternImage-T的top-1准确率达到了83.5%,明显超过了ConvNext-T[21]的1.4个点。InternImage-S/B保持领先地位,并超过hybridViT CoAtNet-2[20] 0.8个百分点。在ImageNet-22K和大规模联合数据集上进行预训练时,InternImage-XL和-H的前一精度分别提高到88.0%和89.6%,优于以往同样使用大规模数据进行训练的cnn[22,67],并将与最先进的大规模vit的差距缩小到约1个点。这种差距可能是由于大规模不可访问的私有数据与上述联合公共数据之间的差异造成的。这些结果表明,我们的InternImage不仅在公共参数尺度和公共训练数据上有良好的性能,而且可以有效地扩展到大规模的参数和数据。


4.2 Object Detection
如表3所示,在使用Mask RCNN进行目标检测时,我们发现在参数数量相当的情况下,我们的模型明显优于其他模型。例如,在1× training schedule中,InternImage-T的box AP (APb)比swi - t[2] (47.2比42.7)高4.5分,比convext - t [21] (47.2比44.2)高3.0分。随着3×多尺度的训练计划,更多的参数,更先进的级联面具R-CNN [71], InternImage-XL实现了56.2的APb,超过了convext - xl 1.0点(56.2比55.2)。实例分割实验也得到了类似的结果。在1×训练计划下,InternImage-T获得42.5掩模AP(即APm),比SwinT和ConvNeXt-T分别高出3.2分(42.5比39.3)和2.4分(42.5比40.1)。使用Cascade Mask R-CNN的InternImage-XL得到的APm最好为48.8,至少比相应的APm高1.1分。
为了进一步推动目标检测的性能边界,我们遵循领先方法[16,17,26,74,78]的高级设置,使用在ImageNet-22K或大规模联合数据集上预先训练的权值初始化骨干,通过复合技术将其参数加倍[78] (见图2中20亿参数的模型)。然后,分别在Objects365[79]和COCO数据集上与DINO[74]探测器进行微调,分别对26个epoch和12个epoch进行微调。如表4所示,我们的方法在COCO val2017和test-dev上获得了65.0 APb和65.4 APb的最佳结果。与之前的最先进的模型相比,我们的模型比FD-SwinV2-G[26]高出1.2个点(65.4比64.2),参数减少27%,且没有复杂的蒸馏过程,这表明我们的模型在检测任务上的有效性。

4.3 Semantic Segmentation

如表5所示,在使用UperNet[81]进行语义分割时,我们的InternImage始终优于现有技术[2,21,22,29]。例如,在几乎相同的参数数和FLOPs下,我们的InternImage-B报告了ADE20K val上的50.8 mIoU,这是出色的强同行,如convext - b (50.8 vs. 49.1)和RepLKNet-31B (50.8 vs. 49.9)。此外,我们的InternImage-H获得了60.3 MS mIoU,这比SwinV2-G[16]更好,但参数数量要小得多(1.12B vs. 3.00B)。值得注意的是,在使用Mask2Former[80]和多尺度测试时,我们的InternImage-H达到了62.9的最佳mIoU,高于当前在ADE20K基准上的最佳BEiT-3[17]。这些结果表明,基于cnn的基础模型也可以享受到海量数据的好处,并挑战基于Transformer的模型的领先地位。
4.4 Ablation Study
-
Sharing weights among convolution neurons matters
由于硬件的限制,大规模模型对核心操作员的参数和内存开销非常敏感。为了解决这个问题,我们在DCNv3的卷积神经元之间共享权值。如图4所示,我们比较了基于DCNv3的权重共享和非共享的模型的参数和内存开销。我们可以看到,非共享权值模型的参数和内存成本远高于共享权值模型,特别是在-H尺度下,节省的参数和GPU内存的比例分别为42.0%和84.2%。如表6所示,我们还检验了在-T尺度下的两个模型在ImageNet (83.5 vs. 83.6)和在COCO上的APb (47.2 vs. 47.4)具有相似的top-1精度,即使没有共享权值的模型也多了66.1%的参数。

-
Multi-group spatial aggregation brings stronger features
我们引入聚合组来允许我们的模型从不同的表示子空间学习信息,比如Transformer[9]。如图5所示,对于相同的查询像素,不同组的偏移量集中在不同的区域,从而产生层次化的语义特征。

我们还比较了有和没有多组的模型的性能。如表6所示,模型在ImageNet上显著下降1.2分,在COCO val2017上显著下降3.4分。此外,我们还发现,在前两个阶段,学习到的有效接受域(ERF)相对较小,随着模型的深入(即阶段3和阶段4),ERF增加到全局。这种现象不同于ViTs [9,10,83], ViTs的ERF通常是全局的。

5. Conclusion & Limitations
我们引入了一种新的基于cnn的大规模基础模型InternImage,它可以为各种各样的视觉任务(如图像分类、目标检测和语义分割)提供强大的表示。我们对灵活的DCNv2算子进行了调优,以满足基础模型的需求,并以核心算子为核心开发了一系列的块规则、叠加规则和缩放规则。在对象检测和语义分割基准上的大量实验验证了我们的InternImage能够获得与精心设计的大规模视觉变压器相当或更好的性能,这表明CNN也是大规模视觉基础模型研究的一个相当大的选择。尽管如此,延迟仍然是基于dcn的运营商适应下游高速任务的一个问题。此外,大型cnn仍处于发展的早期阶段,我们希望InternImage可以作为一个良好的起点。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)