
YOLOV9论文概述
摘要
今天的深度学习方法侧重于如何设计最合适的目标函数,以便模型的预测结果可以最接近基本事实。同时,必须设计能够促进获取足够信息进行预测的适当架构。现有方法忽略了输入数据经过逐层特征提取和空间变换时的事实,会丢失大量信息。
当数据通过深度网络传输时,本文将深入研究数据丢失的重要问题,即信息瓶颈和可逆函数。
我们提出了可编程梯度信息 (PGI) 的概念来应对深度网络实现多个目标所需的各种变化。PGI可以为目标任务提供完整的输入信息来计算目标函数,从而获得可靠的梯度信息来更新网络权重。
此外,设计了一种基于梯度路径规划的广义高效层聚合网络(GELAN)。GELAN 的架构证实 PGI 在轻量级模型上获得了更好的结果。
我们在基于 MS COCO 数据集的对象检测上验证了所提出的 GELAN 和 PGI。结果表明,GELAN 仅使用传统的卷积算子来实现比基于深度卷积开发的最先进方法更好的参数利用率。PGI 可用于从轻量级到大型的各种模型。它可用于获取完整的信息,以便从头开始训练模型比使用大型数据集预训练的最先进模型获得更好的结果
研究的问题:数据丢失
- 信息瓶颈
- 可逆函数。
过去的大多数方法都忽略了输入数据在前馈过程中可能具有不可忽略的信息丢失量。这种信息丢失会导致有偏差的梯度流,随后用于更新模型。上述问题可能导致深度网络建立目标与输入之间的不正确关联,导致训练模型产生不正确的预测
提出解决问题的方法:
-
可编程梯度信息 (PGI)
-
一种基于梯度路径规划的广义高效层聚合网络(GELAN)

信息瓶颈
在深度网络中,前馈过程中输入数据丢失信息的现象通常被称为信息瓶颈

目前,缓解这一现象的主要方法如下:
-
可逆体系结构的使用。该方法主要使用重复输入数据,以显式的方式维护输入数据的信息;
-
掩码建模的使用。它主要使用重构损失,采用隐式方法最大化提取的特征并保留输入信息;
-
深度监督概念的引入。它使用丢失太多重要信息的浅层特征来预先建立从特征到目标的映射,以确保重要信息可以转移到更深的层。
然而,上述方法在训练过程中和推理过程存在不同的缺点。
- 可逆架构需要额外的层来组合重复输入的输入数据,这将显着增加推理成本。此外,由于输出层的输入数据层不能具有太深的路径,这种限制使得在训练过程中难以对高阶语义信息进行建模。
- 掩码建模,它的重建损失有时会与目标损失相冲突。此外,大多数掩码机制也会产生与数据不正确的关联。
- 对于深度监督机制,它将产生错误累积,如果浅层监督在训练过程中丢失信息,后续层将无法检索所需的信息。上述现象在困难的任务和小模型上会更显着。
为了解决上述问题,我们提出了一个新的概念,即可编程梯度信息 (PGI)
这个概念是通过辅助可逆分支生成可靠的梯度,这样深度特征仍然可以保持执行目标任务的关键特征。辅助可逆分支的设计可以避免由集成多路径特征的传统深度监督过程引起的语义损失。换句话说,我们正在在不同的语义级别上编程梯度信息传播,从而实现最好的训练结果,PGI 建立在辅助分支上,因此没有额外的成本。
由于 PGI 可以自由选择适合目标任务的损失函数,它还克服了掩码建模遇到的问题。所提出的 PGI 机制可以应用于不同大小的深度神经网络,并且比仅适用于非常深的神经网络的深度监督机制更通用。
设计了基于 ELAN的广义 ELAN (GELAN),
GELAN 的设计同时考虑了参数数量、计算复杂度、准确性和推理速度。这种设计允许用户为不同的推理设备任意选择合适的计算块。
保留的重要信息的比例,与训练后可以获得的准确度呈正相关
通常,由于梯度消失或梯度饱和等因素,人们将深度神经网络收敛问题的难度归因于传统深度神经网络确实存在这些现象。然而,现代深度神经网络通过设计各种归一化和激活函数从根本上解决了上述问题。然而,深度神经网络仍然存在收敛速度慢或收敛差的问题。在本文中,我们进一步探讨了上述问题的性质。通过对信息瓶颈的深入分析,我们推断该问题的根本原因是,最初来自非常深的网络的初始梯度在传输目标后立即丢失了大量信息。为了确认这种推理,我们前馈了具有不同架构的深度网络,具有初始权重,然后在图 2 中可视化和说明它们。显然,PlainNet 丢失了深层目标检测所需的大量重要信息。至于 ResNet、CSPNet 和 GELAN 可以保留的重要信息的比例,确实与训练后可以获得的准确度呈正相关。我们进一步设计了可逆基于网络的方法来解决上述问题的原因。在本节中,我们将详细阐述我们对信息瓶颈原理和可逆函数的分析。
可逆函数
随着网络层数的加深,原始数据丢失的可能性也会增大。然而,深度神经网络的参数是基于网络的输出以及给定的目标,然后通过计算损失函数产生新的梯度后更新网络。可以想象,深度神经网络的输出不太能够保留关于预测目标的完整信息。这将使得在网络训练中使用不完全信息成为可能,从而导致梯度不可靠,收敛性差。解决上述问题的一种方法是直接增加模型的大小。当我们使用大量的参数来构建模型时,它更有能力对数据进行更完整的转换。上述方法允许即使在数据前馈过程中丢失信息,仍然有机会保留足够的信息来执行到目标的映射。上述现象解释了为什么在大多数现代模型中,宽度比深度更重要。然而,上述结论并不能从根本上解决极深神经网络中梯度不可靠的问题。
可编程梯度信息 (PGI)
如下图所示。PGI主要包括三个部分,即
(1)主分支
(2)辅助可逆分支,
(3)多级辅助信息。
可以看出,PGI的推理过程只使用了主干分支,因此不需要任何额外的推理成本。至于其他两个组件,它们用于解决或减缓深度学习方法中的几个重要问题。其中,设计了辅助可逆分支来解决神经网络深度化带来的问题。网络深化会造成信息瓶颈,使损失函数无法产生可靠的梯度。对于多级辅助信息,设计用于处理深度监督带来的误差积累问题,特别是针对多预测分支的架构和轻量化模型。

辅助可逆分支
我们分析了图中b)的架构,发现当添加从深层到浅层的额外连接时,推理时间将增加20%。当我们将输入数据反复添加到网络的高分辨率计算层(黄色框)时,推理时间甚至超过了时间的两倍。
我们的目标是使用可逆架构来获得可靠的梯度,因此“可逆”并不是推理阶段的唯一必要条件。鉴于此,我们将可逆分支作为深度监督分支的扩展,然后设计辅助可逆分支,如图(d)所示。对于因信息瓶颈而丢失重要信息的主分支深度特征,将能够从辅助可逆分支接收到可靠的梯度信息。这些梯度信息将驱动参数学习,帮助提取正确的重要信息。
最后,由于在推理阶段可以去除辅助可逆分支,因此可以保留原始网络的推理能力。我们也可以在PGI中选择任意可逆体系结构来充当辅助可逆分支的角色。
多级辅助信息
不同的特征金字塔来执行不同的任务,会导致深层特征金字塔丢失大量预测目标物体所需的信息。对于这个问题,我们认为每个特征金字塔都需要接收到所有目标对象的信息,这样后续的主干分支才能保留完整的信息来学习对各种目标的预测。
duo级辅助信息的概念是在辅助监督的特征金字塔层次层和主分支之间插入一个集成网络,然后利用它来组合来自不同预测头的返回梯度,如图中d)所示。
多级辅助信息就是将包含所有目标对象的梯度信息进行聚合,传递给主分支,然后更新参数。此时,主要分支的特征金字塔层次结构的特征就不会被某些特定对象的信息所支配。因此,该方法可以缓解深度监督中的信息破碎问题。
GELAN
通过结合CSPNet和ELAN这两种采用梯度路径规划设计的神经网络架构,我们设计了兼顾轻量级、推理速度和准确性的广义高效层聚合网络(GELAN)。它的整体架构如图4所示。我们将最初仅使用卷积层堆叠的ELAN的能力推广到可以使用任何计算块的新架构。

实验设计
参数设置
我们提到的所有模型都是使用从头开始训练的策略来训练的,总的训练次数是500次。在学习率的设置上,我们在前三个epoch采用线性预热,之后的时代根据模型尺度设置相应的衰减方式。对于最后15个epoch,我们关闭马赛克数据增强。
实验结论
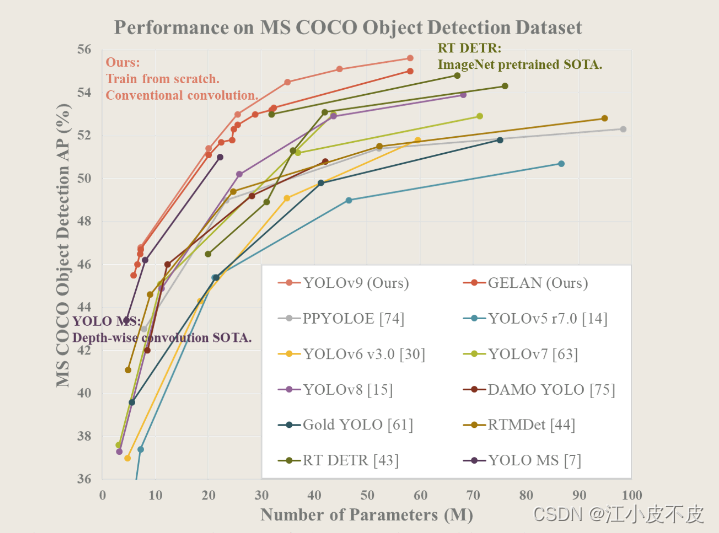
总体而言,在现有方法中,
-
性能最好的方法是用于轻型模型的YOLO MS- S,
-
用于中型模型的YOLO MS,
-
用于一般模型的YOLOv7 AF,
-
用于大型模型的YOLOv8-X。
-
与轻量化和中等型号的YOLO MS相比,YOLOv9的参数减少了约10%,计算量减少了5 ~ 15%,但AP仍提高了0.4 ~ 0.6%。
-
与YOLOv7 AF相比,YOLOv9- c的参数减少了42%,计算量减少了21%,但AP相同(53%)。
-
与YOLOv9- x相比,YOLOv9- x参数减少15%,计算量减少25%,AP显著提高1.7%。
以上对比结果表明,我们提出的YOLOv9与现有方法相比,各方面都有显著提高。

消融实验
模块
对于GELAN,我们首先对计算块进行消融研究。我们分别使用Res块、Dark块和CSP块进行实验。
从表可以看出,用不同的计算块替换ELAN中的卷积层后,系统仍能保持良好的性能。用户确实可以自由替换计算块,并在各自的推理设备上使用它们。
在不同的计算块替换中,CSP块执行得特别好。它们不仅减少了参数和计算量,而且使AP提高了0.7%。因此,我们选择CSPELAN作为YOLOv9中GELAN的组成单元。

深度
我们对不同尺寸的GELAN进行ELAN block-depth和CSP blockdepth实验,结果如表所示。我们可以看到,当ELAN的深度从1增加到2时,精度明显提高。
但当深度大于等于2时,无论是提高ELAN深度还是CSP深度,参数数量、计算量和精度始终呈现线性关系。这意味着GELAN对深度不敏感。
换句话说,用户可以任意组合GELAN中的组件来设计网络架构,无需特别设计就能得到性能稳定的模型。

辅助可逆分支和多层辅助信息
对于多层辅助信息,我们使用FPN和PAN进行消融研究,PFH的作用相当于传统的深度监督。所有实验结果列于表。从表可以看出,PFH仅在深度模型中有效,而我们提出的PGI在不同组合下都可以提高精度。特别是在使用ICN时,我们得到了稳定和更好的结果。我们也尝试将YOLOv7中提出的铅头引导分配应用到PGI的辅助监督中,取得了更好的效果

PGI
引入深度监督会导致浅层模型的准确性损失。对于一般模型,引入深度监督会导致性能不稳定,深度监督的设计理念只能在极深的模型中带来收益。
所提出的PGI能够有效处理信息瓶颈、信息破碎等问题,全面提高不同尺寸模型的精度。
PGI的概念带来了两个有价值的贡献。一是使辅助监督方法适用于浅层模型,二是使深层模型训练过程获得更可靠的梯度。这些梯度使深度模型能够使用更准确的信息来建立数据和目标之间的正确相关性。

综合
从基线YOLOv7到YOLOv9-E逐渐增加成分的结果。

可视化结果
展示了在不同架构下使用随机初始权重作为前馈得到的特征图的可视化结果。
我们可以看到,随着层数的增加,所有架构的原始信息逐渐减少。
在PlainNet的第50层,很难看到物体的位置,而在第100层,所有可区分的特征都将丢失。对于ResNet,虽然在第50层仍然可以看到物体的位置,但是已经丢失了边界信息。当深度达到第100层时,整个图像变得模糊。
CSPNet和所提出的GELAN都表现得非常好,并且它们都可以保持支持清晰识别目标的特征,直到第200层。在比较中,GELAN的结果更稳定,边界信息更清晰。

下图为PAN偏置预热时GELAN和YOLOv9 (GELAN + PGI)特征图的可视化结果。从图(b)和©的对比中,我们可以清楚地看到,PGI准确、简洁地捕获了包含物体的区域。对于不使用PGI的GELAN,我们发现它在检测物体边界时存在发散,并且在一些背景区域也会产生意想不到的响应。本实验证实了PGI确实可以提供更好的梯度来更新参数,使主分支的前馈阶段保留更重要的特征。

结论
在本文中,我们提出使用PGI来解决信息瓶颈问题和深度监督机制不适合轻量级神经网络的问题。我们设计了一种高效、轻量级的神经网络GELAN。在目标检测方面,在不同的计算块和深度设置下,GELAN具有强大而稳定的性能。它确实可以广泛地扩展成适用于各种推理装置的模型。对于上述两个问题,PGI的引入使轻量级模型和深度模型都能在精度上取得显著提高。由PGI和GELAN联合设计的YOLOv9表现出了很强的竞争力。与YOLOv8相比,其出色的设计使深度模型的参数数量减少了49%,计算量减少了43%,但在MS COCO数据集上仍有0.6%的AP改进。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 14
14 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)