
超强总结!十大聚类算法!机器学习算法K-means、层次聚类、DBSCAN、谱聚类、高斯混合模型、模糊C-means、K-medoids、Mean Shift、OPTICS、BIRCH
聚类算法是一种无监督学习方法,旨在将数据集中的对象划分为若干个类别或簇,使得同一类别内的对象相似度较高,不同类别之间的相似度较低。聚类分析在多个领域均有广泛应用,如市场细分、生物学研究、图像分析、社交网络分析等。聚类算法的基本步骤包括选择相似度度量方法、选择聚类算法、确定聚类数目和评估聚类分析结果。
聚类算法通常分为层次聚类和划分聚类两大类。层次聚类是一种自下而上的聚类算法,适用于大规模数据集,但不便于指定聚类数目。划分聚类如K均值聚类则是将数据集中的对象划分为K个簇,适用于大规模数据集,但需要预先指定聚类数目。
今天拿出最常见的 10 种聚类算法和大家聊聊~
K-means:这是最常见的聚类算法之一,用于将数据分成预定义数量的簇。
层次聚类:通过构建数据点之间的层次结构来进行聚类,可以是自底向上的凝聚方法或自顶向下的分裂方法。
DBSCAN:一种基于密度的聚类算法,能够识别任意形状的簇,同时对噪声和离群点具有较好的鲁棒性。
谱聚类:使用数据的相似性矩阵来进行聚类,特别适用于复杂形状的数据集。
高斯混合模型:是一种基于概率模型的聚类方法,适用于估计子群体的分布。
模糊C-means:与K-means相似,但允许一个数据点属于多个簇,每个簇都有一定的隶属度或概率。
K-medoids:与K-means类似,但使用数据点(medoids)而不是均值作为簇的中心。
Mean Shift:通过迭代地更新候选簇中心点来寻找数据点密度最高的区域。
OPTICS:一种基于密度的聚类算法,类似于DBSCAN,但对不同密度的数据集表现更好。
BIRCH:专为大型数据集设计的一种层次聚类方法。
这些聚类算法各有优缺点,适用于不同类型的数据和不同的应用场景。选择合适的聚类算法通常取决于具体的需求、数据的特性和计算资源。
一、K-means
K-means 是一种广泛使用的聚类算法,它的目标是将数据点分组到 K 个簇中,以使簇内的点尽可能相似,而簇间的点尽可能不同。它的核心思想是通过迭代优化簇中心的位置,以最小化簇内的平方误差总和。
算法步骤
-
初始化:随机选择 K 个数据点作为初始簇中心。
-
分配:将每个数据点分配给最近的簇中心。
-
更新:重新计算每个簇的中心(即簇内所有点的均值)。
-
迭代:重复步骤 2 和 3 直到簇中心不再发生变化或达到预设的迭代次数。
目标函数
K-means 试图最小化簇内误差平方和,其公式为: 
代码案例
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 创建一个示例数据集
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 使用K均值算法进行聚类
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
# 获取簇中心和簇分配结果
centers = kmeans.cluster_centers_
labels = kmeans.labels_
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], marker='o', s=200, color='red')
plt.show()
K-means 算法简单高效,广泛应用于各种场景,特别是在需要快速、初步的数据分组时。然而,它也有局限性,比如对初始簇中心的选择敏感,可能会陷入局部最优,且假设簇是凸形的,对于复杂形状的数据可能不适用。
二、层次聚类
层次聚类是一种常用的聚类方法,它通过构建数据点之间的层次结构来进行聚类。层次聚类不需要预先指定簇的数量,并且结果可以表示为树状图(称为树状图或层次树),提供了数据点之间关系的丰富视图。
类型
-
凝聚型(Agglomerative):从每个点作为单独的簇开始,逐渐合并最近的簇。
-
分裂型(Divisive):从所有数据作为一个簇开始,逐步分裂为更小的簇。
算法步骤(以凝聚型为例)
-
开始时,将每个数据点视为一个单独的簇。
-
找到最相似(距离最近)的两个簇并将它们合并。
-
重复步骤 2,直到所有数据点都合并到一个簇中或达到预定的簇数量。
距离公式
层次聚类中,簇之间的相似性通常用距离来衡量,常用的距离度量有:

代码案例
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
# 创建示例数据集
X = np.array([[1, 2], [2, 3], [3, 4], [5, 6], [7, 8]])
# 计算链接矩阵
Z = linkage(X, 'ward')
# 绘制树状图
plt.figure(figsize=(10, 5))
dendrogram(Z)
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Data point index')
plt.ylabel('Distance')
plt.show()
上图展示了层次聚类的树状图,也称为树状图。在这个图中:
-
每个点代表一个数据样本。
-
水平线表示簇的合并,其长度代表合并簇之间的距离或不相似度。
-
树状图的垂直轴代表距离或不相似度,可以用来判断簇之间的距离。
通过这个树状图,我们可以观察数据的层次聚类结构,并根据需要选择适当的截断点来确定簇的数量。例如,通过在不同的高度水平切割树状图,可以得到不同数量的簇。
层次聚类特别适用于那些簇的数量不明确或数据具有自然层次结构的场景。与 K-means 等算法相比,它不需要预先指定簇的数量,但计算复杂度通常更高。
三、DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,特别适用于具有噪声的数据集和能够发现任意形状簇的情况。它不需要事先指定簇的数量,能有效处理异常点。

算法步骤
-
标记所有点为核心点、边界点或噪声点。
-
删除噪声点。
-
为剩余的核心点创建簇,如果一个核心点在另一个核心点的邻域内,则将它们放在同一个簇中。
-
将每个边界点分配给与之关联的核心点的簇。
DBSCAN 的参数

代码案例
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 创建示例数据集
X, _ = make_moons(n_samples=200, noise=0.1)
# 使用DBSCAN算法进行聚类
dbscan = DBSCAN(eps=0.2, min_samples=5)
labels = dbscan.fit_predict(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()

DBSCAN 的优势在于它不需要事先指定簇的数量,可以识别任意形状的簇,并且对噪声数据具有良好的鲁棒性。然而,选择合适的 eps 和 min_samples 参数对于获得好的聚类结果至关重要。
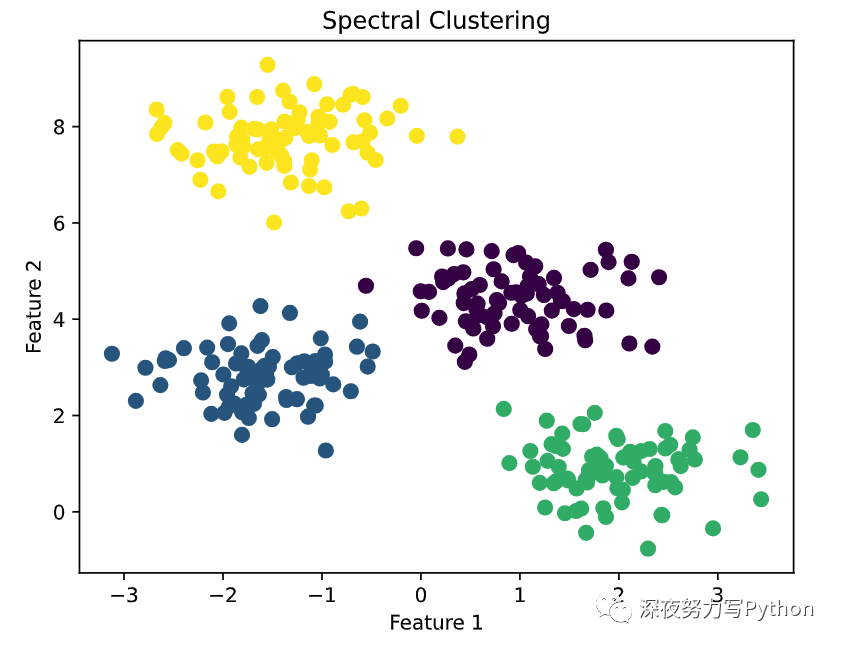
四、谱聚类
谱聚类是一种基于图论的聚类方法,特别适用于发现复杂形状的簇和非球形簇。与传统的聚类算法(如K-means)不同,谱聚类依赖于数据的相似性矩阵,并利用数据的谱(即特征向量)来进行降维,进而在低维空间中应用如K-means的聚类方法。
谱聚类的基本思想是将数据集表示为图的形式,其中数据点对应于图中的节点,而节点之间的相似性对应于图的边。然后,通过对图的拉普拉斯矩阵进行特征分解来实现降维和聚类,具体而言,谱聚类将拉普拉斯矩阵的特征向量作为新的特征表示,并使用K均值等方法对这些特征向量进行聚类。
算法步骤
-
构建相似性矩阵:基于数据点之间的距离或相似度。
-
计算图的拉普拉斯矩阵:常用的是归一化拉普拉斯矩阵。
-
计算拉普拉斯矩阵的特征向量和特征值。
-
基于前k个特征向量的新特征空间,应用传统聚类算法(如K-means)。
相关公式

代码案例
from sklearn.cluster import SpectralClustering
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 创建示例数据集
X, _ = make_moons(n_samples=200, noise=0.1)
# 使用谱聚类进行聚类
spectral_clustering = SpectralClustering(n_clusters=2, affinity='nearest_neighbors', random_state=0)
labels = spectral_clustering.fit_predict(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('Spectral Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
谱聚类的一个关键优势是能够发现任意形状的簇,这使得它特别适用于那些传统聚类算法(如K-means)难以处理的数据集。不过,选择合适的相似性度量和参数对于获得好的聚类结果至关重要。此外,谱聚类的计算复杂度比一些其他聚类算法高,特别是在处理大型数据集时。
需要视频学习的可以关注vx工粽号:AI技术星球 回复:211 获取
5. 高斯混合模型
高斯混合模型(GMM)是一种基于概率模型的聚类算法,它假设所有数据点都是从有限个高斯分布的混合生成的。与K-means等硬聚类算法不同,GMM 属于软聚类算法,它为每个数据点提供了属于各个簇的概率。
GMM假设数据是由K个高斯分布组成的,每个高斯分布代表一个聚类簇。每个数据点的生成过程是从这些高斯分布中以一定的概率选择一个分布,然后从选定的分布中生成一个数据点。GMM的目标是通过最大化似然函数来估计模型参数,从而找到最佳的组件数量和每个组件的参数。
核心概念
-
混合模型:假设数据是由 个高斯分布混合而成。
-
高斯分布:每个分布由均值(mean)和协方差(covariance)决定。
-
概率:每个数据点属于各个簇的概率。
算法步骤
-
初始化:随机选择 个高斯分布的参数。
-
期望步骤(E-step):根据当前参数,计算每个数据点属于每个簇的概率。
-
最大化步骤(M-step):更新每个高斯分布的参数以最大化数据的似然。
-
迭代:重复 E-step 和 M-step 直到收敛。
目标函数
GMM 试图最大化数据的似然,即: 
代码案例
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 创建示例数据集
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.6, random_state=0)
# 使用GMM算法进行聚类
gmm = GaussianMixture(n_components=4)
gmm.fit(X)
# 获取聚类结果
labels = gmm.predict(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('Gaussian Mixture Model Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
GMM 的优势在于它是一个基于概率的方法,提供了比 K-means 更丰富的信息,并且可以模拑非球形的簇。它通过期望最大化(EM)算法迭代地优化参数,以最大化数据的似然概率。不过,选择合适的簇数量和协方差类型对于获得好的聚类结果至关重要。此外,GMM 对于初始化参数比较敏感,可能会陷入局部最优。
6. 模糊C-means
模糊 C-means(FCM)算法允许一个数据点属于多个聚类中心。与传统的K-means聚类算法不同,模糊C-means通过为每个数据点分配一个属于各个聚类中心的隶属度,来表示其属于不同聚类的程度。这种方法特别适用于那些不清晰或重叠的数据集。
基本步骤
-
初始化: 选择聚类中心的数量C,并随机初始化每个数据点对每个聚类中心的隶属度。
-
迭代: 在每次迭代中,执行以下步骤:
-
更新聚类中心,根据数据点对聚类中心的隶属度和数据点的位置。
-
更新每个数据点对每个聚类中心的隶属度,基于数据点与聚类中心的距离。
-
-
停止条件: 当聚类中心的变化小于一个阈值或达到预设的迭代次数时,算法停止。
算法公式

Python代码
以下是使用Python实现模糊C-means算法的一个简单示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 模糊C-means算法实现
def fuzzy_c_means(X, C, m=2, error=0.005, maxiter=300):
# 初始化隶属度矩阵
n = X.shape[0]
U = np.random.rand(n, C)
U = U / np.sum(U, axis=1, keepdims=True)
for iteration in range(maxiter):
# 更新聚类中心
centers = np.dot(U.T ** m, X) / np.sum(U.T ** m, axis=1, keepdims=True)
# 更新隶属度
distance = np.linalg.norm(X[:, np.newaxis] - centers, axis=2)
U_new = 1.0 / np.sum((distance[:, :, np.newaxis] / distance[:, np.newaxis, :]) ** (2 / (m - 1)), axis=2)
# 检查是否收敛
if np.max(np.abs(U_new - U)) < error:
break
U = U_new
return centers, U
# 使用模糊C-means算法
centers, U = fuzzy_c_means(X, C=4)
# 绘制结果
plt.scatter(X[:, 0], X[:, 1], alpha=0.5)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X')
plt.title('Fuzzy C-means Clustering')
plt.show()
这段代码首先生成一些模拟数据,然后使用模糊C-means算法进行聚类,并最后显示聚类结果。在实际应用中,可能需要根据具体的数据集调整参数,如聚类的数目、模糊
7. K-medoids
K-medoids 用于将数据集中的数据点分成多个簇。这种算法与著名的 K-means 算法相似,但主要区别在于 K-medoids 选择数据点中的实际点作为簇的中心,而 K-means 则使用簇内数据点的均值。
算法简介
-
初始化:随机选择 个数据点作为初始的簇中心。
-
分配:将每个数据点分配给最近的簇中心。
-
更新:计算每个簇的新中心。与 K-means 不同,这里选择簇内最能代表其他点的数据点作为中心。
-
重复:重复分配和更新步骤,直到簇中心不再变化或达到预设的迭代次数。
算法公式

Python 代码
随机生成一些数据点,然后应用一个简单的 K-medoids 算法来聚类这些点,并展示结果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import pairwise_distances
from sklearn.datasets import make_blobs
def simple_kmedoids(data, num_clusters, max_iter=100):
# Randomly initialize medoids
medoids = np.random.choice(len(data), num_clusters, replace=False)
for _ in range(max_iter):
# Compute distances between data points and medoids
distances = pairwise_distances(data, data[medoids, :])
# Assign each point to the closest medoid
clusters = np.argmin(distances, axis=1)
# Update medoids
new_medoids = np.array([np.argmin(np.sum(distances[clusters == k, :], axis=0)) for k in range(num_clusters)])
# Check for convergence
if np.array_equal(medoids, new_medoids):
break
medoids = new_medoids
return clusters, medoids
# Generating synthetic data
data, _ = make_blobs(n_samples=150, centers=3, n_features=2, random_state=42)
# Applying the simple K-medoids algorithm
num_clusters = 3
clusters, medoids = simple_kmedoids(data, num_clusters)
# Plotting the results
plt.figure(figsize=(10, 6))
plt.scatter(data[:, 0], data[:, 1], c=clusters, cmap='viridis', marker='o', label='Data points')
plt.scatter(data[medoids, 0], data[medoids, 1], c='red', marker='X', s=100, label='Medoids')
plt.title('Simple K-medoids Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.grid(True)
# Saving the plot
plot_path_simple = 'simple_kmedoids_clustering.png'
plt.savefig(plot_path_simple)
plot_path_simple 
我已经应用了一个简化版的 K-medoids 算法来进行聚类,并生成了一个可视化图像。在这个图中,不同颜色的点代表不同的簇,而红色的“X”标记表示每个簇的中心点(即medoids)。这个图形展示了如何将数据点根据它们与中心点的距离分配到不同的簇中。
8. Mean Shift
Mean Shift 算法是一种基于密度的非参数聚类算法。其核心思想是通过迭代过程寻找数据点密度的峰值。这个算法不需要预先指定簇的数量,它通过数据本身的分布特性来确定簇的数量。
算法概述
-
选择带宽(Bandwidth):带宽确定了搜索窗口的大小,对算法的结果有显著影响。
-
迭代过程:对每个数据点,计算其在带宽范围内邻近点的均值,然后将数据点移动到这个均值位置。
-
收敛:重复上述过程直到数据点的移动非常小或达到预定的迭代次数。
相关公式

Python 实现
以下是 Mean Shift 算法的一个基本 Python 实现,使用了 scikit-learn 库:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import MeanShift
from sklearn.datasets import make_blobs
# 生成样本数据
centers = [[1, 1], [5, 5], [3, 10]]
X, _ = make_blobs(n_samples=300, centers=centers, cluster_std=0.7)
# 应用 Mean Shift 算法
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, marker='o')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], c='red', marker='x')
plt.title('Mean Shift Clustering')
plt.show()这段代码首先生成一些样本数据,然后应用 Mean Shift 算法对数据进行聚类,并将结果可视化。每个聚类的中心用红色的 'x' 标记。
9. OPTICS
OPTICS(Ordering Points To Identify the Clustering Structure)算法是一种用于数据聚类的算法,与DBSCAN算法类似,但在处理可变密度的数据集时更为有效。其核心思想是通过分析数据点的密度-可达性来识别聚类结构。
OPTICS算法通过计算每个数据点的局部密度和距离最近的高密度点来确定聚类结构。它使用一个特殊的数据结构(可达距离图)来表示数据点之间的可达关系,然后根据这个结构构建一个有序的聚类结构。通过调整参数,OPTICS可以发现不同密度和形状的聚类。
简单介绍
-
核心概念:OPTICS算法主要关注两个概念,即核心距离和可达距离。
-
核心距离:对于给定点,其核心距离是使其成为核心对象的最小半径。
-
可达距离:是一个对象到一个核心对象的最小距离。
-
-
算法流程:OPTICS算法首先根据核心距离和可达距离为数据点创建一个排序,然后基于这个排序来识别聚类。
相关公式

代码案例
由于OPTICS算法在Python中没有标准的库函数可以直接调用,以下是一个使用第三方库scikit-learn中的OPTICS实现的简化示例:
from sklearn.cluster import OPTICS
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 创建示例数据集
X, _ = make_moons(n_samples=200, noise=0.1)
# 使用OPTICS进行聚类
optics = OPTICS(min_samples=5)
optics.fit(X)
# 获取聚类结果
labels = optics.labels_
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('OPTICS Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()

10. BIRCH
BIRCH(平衡迭代式规约和聚类使用层次方法)是一种用于大数据集的聚类算法,特别适用于具有噪声的大规模数据集。BIRCH算法的核心思想是通过构建一个名为CF Tree(聚类特征树)的内存中的数据结构来压缩数据,该数据结构以一种方式保存数据,使得聚类可以高效地进行。
关键概念 
算法步骤
-
构建CF Tree:读取数据点,更新CF Tree。如果新数据点可以合并到现有聚类中而不违反树的定义,则进行合并;否则,创建新的叶子节点。
-
凝聚步骤:可选步骤,用于进一步压缩CF Tree,通过删除距离较近的子聚类并重新平衡树。
-
全局聚类:使用其他聚类方法(如K-Means)对叶子节点中的聚类特征进行聚类。
相关公式
聚类特征(CF)的计算公式:

Python代码
接下来,使用Python演示BIRCH算法的基本使用,并生成相关的图形。我们将使用scikit-learn库中的BIRCH实现。
from sklearn.cluster import Birch
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据
X, _ = make_blobs(n_samples=1000, centers=4, cluster_std=0.5, random_state=0)
# 应用BIRCH算法
brc = Birch(n_clusters=4)
brc.fit(X)
# 预测聚类标签
labels = brc.predict(X)
# 绘制结果
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', marker='o')
plt.title("BIRCH Clustering")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.colorbar(label='Cluster Label')
plt.show()
上图展示了使用BIRCH算法对模拟数据进行聚类的结果。在这个例子中,我们生成了1000个数据点,分布在4个中心点周围。使用BIRCH算法,我们能够有效地将这些点分成四个不同的聚类,如不同颜色所示。
在实际应用中,BIRCH算法特别适合于处理大规模数据集,并且当数据集中存在噪声时,它通常也能表现良好。通过调整算法参数,例如树的深度和分支因子,可以优化聚类的性能和准确性。
需要视频学习的可以关注vx工粽号:AI技术星球 回复:211 获取
需要论文指导发刊的 【AI交叉学科、SCI、CCF-ABC、期刊、会议、本硕博论文、在职论文指导、Kaggle比赛指导、 润色发刊等 】
白嫖100G入门到进阶AI资源包+kaggle竞赛+就业指导+技术问题答疑
1、超详细的人工智能学习路
2、OpenCV、Pytorch、YOLO等教程
3、人工智能快速入门教程(Python基础、数学基础、NLP)附源码课件数据
4、机器学习算法+深度学习神经网络基础教程
5、人工智能必看书籍(花书、西瓜书、蜥蜴书等)
6、顶刊论文及行业报告
7、SCI论文攻略 及润色等


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 42
42 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)