
Llama3中文微调模型-Llama3-Chinese-8B-Instruct概述
Llama3模型作为最新的突破,通过引入GQA注意力机制、扩大模型规模、更新分词器、增加词表大小和使用庞大的训练数据集,展现出了强大的语言理解和生成能力。
然而,为了更好地适应中文语境和满足特定领域的需求,Llama3模型需要经过精细的中文微调。本文将详细介绍Llama3模型的中文微调方法,并对比微调前后的效果,以展示微调对于提升模型性能的重要性。
01
Llama3模型概览
模型核心框架更新:
GQA(Group Query Attention,分组查询注意力机制),8B模型和70B模型全系列都采用了GQA,GQA通过将查询分成不同的部分并给予它们不同的重点来理解查询的层次结构,这有助于系统更好地理解复杂问题并找到更相关的信息。

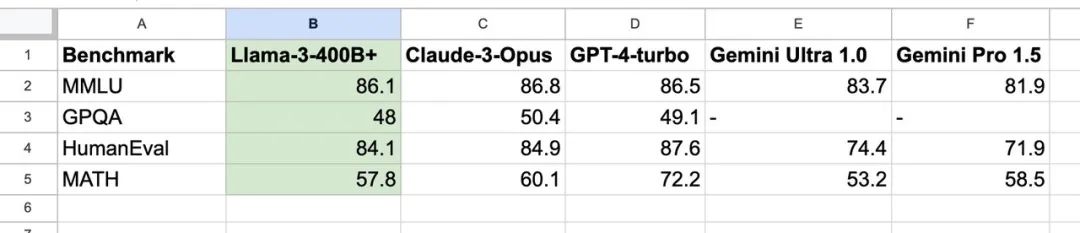
模型参数规模增加:
Llama3的最大模型参数规模达到了惊人的400B。从而提供了更强大的语言理解和生成能力。这一版本的400B模型预计将在未来几个月内发布。(正在训练的 Llama3 400B 模型,测试结果已经和 GPT4-TURBO 以及Claude3-Opus 近似)

数据来源@DrJimFan
分词器更新:
Llama3将分词器从SentencePiece更换为Tiktoken,以与GPT4保持一致。Tiktoken是一种用于分词和编码的工具,有助于更好地处理不同语言和文本数据。
大规模词表:
Llama3的词表大小达到了惊人的128256词,是Llama2的32000词表数量的近4倍。这些额外的词表项提供了更多的词汇覆盖范围,使模型更好地理解和生成多样化的文本。
训练数据规模:
Llama3使用了大约15万亿个标记(tokens)进行模型的训练。这个庞大的数据集有助于模型学习更广泛的语言知识和上下文理解。
开源模型和基座模型:
Llama3提供了两种规模的开源模型,即8B和70B。每个规模都包含基座模型和instruct模型。基座模型是通用的语言模型,而instruct模型是在基座模型的基础上进行的指令微调模型,在数学和代码能力方面远超Llama2的7B chat模型。
这些更新和改进使得Llama3成为一个更加强大和多功能的语言模型,为各种自然语言处理任务提供了更好的性能和能力。
02
Llama3中文微调方法
为显著提升Llama3模型在中文领域的理解和应用能力,我们采用了LoRA(Low-Rank Adaptation)微调方法。
我们精心构建了一个包含190k问答对的高质量标注数据集,这个数据集覆盖了多种语言,尤其注重中文,并且包含了丰富的文本格式,如表格、段落和对话等。它广泛涉及了包括阅读理解、逻辑推理、信息提取在内的多领域内容问题,同时包含了单轮次及多轮次对话场景,全面地为模型提供了多样化的语言学习环境。
通过LoRA微调,我们不仅保留了Llama3模型在预训练阶段获得的知识,还通过针对性的架构调整和参数优化,进一步提升了模型对中文语境的适应性和任务执行的准确性。
这一过程中,我们特别注重了超参数的精细调整,并通过反复的模型评估与迭代,确保了微调后的模型能够在实际应用中稳定地提供高质量的输出。
在此基础上,我们即将推出一个更新版本,该版本将整合PPO(Proximal Policy Optimization)算法,这是一种先进的强化学习技术,它将在现有LoRA微调的基础上,进一步提升模型的决策质量和性能稳定性。我们将通过PPO算法的整合,使Llama3模型能够更加精准地理解和生成中文内容,为用户提供更加流畅和自然的交互体验!
03
微调效果对比
我们选取了242个不同领域的问题,对比了原版Llama3-8B-Instruct模型和经过社区技术人员进行中文微调后的Llama3-Chinese-8B-Instruct的回答效果。
结果显示,Llama3-Chinese-8B-Instruct在中文回答能力上显著优于Llama3-8B-Instruct,其中232个问题,Llama3-8B-Instruct均以英文来回答中文问题,而对于同样的问题,Llama3-Chinese-8B-Instruct则能够继续以同样的语言:中文来回答。这表明社区微调方法极大地改善了Llama3-8B-Instruct的中文理解和生成能力。
然而,在剩余的10个问题中,有2个问题,Llama3-Chinese-8B-Instruct的表现不佳,例如,在编程题和一些需要精确回答的问题上,Llama3-Chinese-8B-Instruct的回答不如原版精确或简洁。此外,还有8个问题的回答质量与原版相当,被评为平局。
在这里,我们展示几个例子:
专业知识-创作能力测试
对于Llama3-8B-Instruct

Llama3-Chinese-8B-Instruct

很明显,Llama3-Chinese-8B-Instruct的回答,以中文形式给出了三个关键要素,更符合我们的需求。
像上述例子这样的情况(提出中文问题,Llama3-8B-Instruct给出了英文回答,Llama3-Chinese-8B-Instruct给出了令人满意的中文回答)还有很多,在这个包含242个问题的数据集中,比例为232/242。这意味着,Llama3-Chinese-8B-Instruct微调操作,极大程度上提高了Llama3-8B-Instruct中文回答能力!
专业知识-代码编程测试
Llama3-8B-Instruct

Llama3-Chinese-8B-Instruct

通用知识-社会人文类测试
Llama3-8B-Instruct

Llama3-Chinese-8B-Instruct

通用知识-自然科学类测试
Llama3-8B-Instruct

Llama3-Chinese-8B-Instruct

逻辑推理-分析能力测试
Llama3-8B-Instruct

Llama3-Chinese-8B-Instruct

04
结论
通过社区微调后的Llama3-Chinese-8B-Instruct在中文领域的应用能力得到了显著提升。诚然,在某些细微之处尚存精进的空间,但总体而言,Llama3-Chinese-8B-Instruct模型已然展现出其更为卓越的中文理解力与创造力。未来的探索之路,必将致力于发掘更为细致入微的微调策略,以持续提升模型在特定领域的卓越表现,并逐一攻克剩余的个别难题。
此次微调探索之旅,我们不仅看到了Llama3模型在中文领域的潜力,也认识到了微调在提升模型性能中的关键作用。展望未来,随着人工智能技术的日新月异,我们坚信Llama3及其经过精心微调的Llama3-Chinese-8B-Instruct版本,将在更广阔的领域中大放异彩。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 3
3 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)