
大模型对齐方法笔记一:DPO及其变种IPO、KTO、CPO
DPO
DPO(Direct Preference Optimization)出自2023年5月的斯坦福大学研究院的论文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》,大概是2023-2024年最广为人知的RLHF的替代对齐方法了。DPO的主要思想是在强化学习的目标函数中建立决策函数与奖励函数之间的关系,以规避奖励建模的过程。
DPO目标函数的推导过程如下:
在RLHF里使用PPO优化的目标函数如下((
r
(
x
,
y
)
r(x,y)
r(x,y)是奖励函数,参考模型为
π
ref
\pi_{\text{ref}}
πref,策略模型为
π
θ
\pi_{\theta}
πθ后面简写为
π
\pi
π):
max
π
θ
E
x
∼
D
,
y
∼
π
θ
(
y
∣
x
)
[
r
(
x
,
y
)
]
−
β
D
K
L
[
π
θ
(
y
∣
x
)
∣
∣
π
ref
(
y
∣
x
)
]
(
1
)
\max_{\pi_{\theta}} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_{\theta}(y|x)} [r(x,y)] - \beta \mathbb{D}_{KL} [\pi_{\theta}(y|x) || \pi_{\text{ref}} (y|x) ] \qquad (1)
πθmaxEx∼D,y∼πθ(y∣x)[r(x,y)]−βDKL[πθ(y∣x)∣∣πref(y∣x)](1)
接下来对上式做推导来得到最优解:
max
π
E
x
∼
D
,
y
∼
π
[
r
(
x
,
y
)
]
−
β
D
K
L
[
π
(
y
∣
x
)
∣
∣
π
ref
(
y
∣
x
)
]
=
max
π
E
x
∼
D
E
y
∼
π
(
y
∣
x
)
[
r
(
x
,
y
)
−
β
log
π
(
y
∣
x
)
π
ref
(
y
∣
x
)
]
=
min
π
E
x
∼
D
E
y
∼
π
(
y
∣
x
)
[
log
π
(
y
∣
x
)
π
ref
(
y
∣
x
)
−
1
β
r
(
x
,
y
)
]
=
min
π
E
x
∼
D
E
y
∼
π
(
y
∣
x
)
[
log
π
(
y
∣
x
)
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
−
log
Z
(
x
)
]
(
2
)
\begin{aligned} \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi} [r(x,y)] - \beta \mathbb{D}_{KL} [\pi(y|x) || \pi_{\text{ref}} (y|x) ] &= \max_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{ y \sim \pi(y|x)} \left[r(x,y) - \beta \log \frac {\pi(y|x)} {\pi_{\text{ref}} (y|x)} \right] \\ &= \min_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{ y \sim \pi(y|x)} \left[\log \frac {\pi(y|x)} {\pi_{\text{ref}} (y|x)}- \frac {1}{\beta} r(x,y) \right] \\ &= \min_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{ y \sim \pi(y|x)} \left[\log \frac {\pi(y|x)} {\frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac {1}{\beta} r(x,y)\right) }- \log Z(x) \right] \qquad (2)\\ \end{aligned}
πmaxEx∼D,y∼π[r(x,y)]−βDKL[π(y∣x)∣∣πref(y∣x)]=πmaxEx∼DEy∼π(y∣x)[r(x,y)−βlogπref(y∣x)π(y∣x)]=πminEx∼DEy∼π(y∣x)[logπref(y∣x)π(y∣x)−β1r(x,y)]=πminEx∼DEy∼π(y∣x)
logZ(x)1πref(y∣x)exp(β1r(x,y))π(y∣x)−logZ(x)
(2)
上面式中的
Z
(
x
)
Z(x)
Z(x)是一个配分函数,具体定义如下:
Z
(
x
)
=
∑
y
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
Z(x) = \sum_y \pi_{\text{ref}}(y|x) \exp\left(\frac {1}{\beta} r(x,y)\right)
Z(x)=y∑πref(y∣x)exp(β1r(x,y))
注意到配分函数只是x和参考模型为
π
ref
\pi_{\text{ref}}
πref的函数,与策略模型
π
\pi
π无关,我们定义下式表示的函数,它是一个有效的概率分布因为满足条件:1.对所有y有
π
∗
(
y
∣
x
)
≥
0
\pi^*(y|x) \ge 0
π∗(y∣x)≥0,2.
∑
y
π
∗
(
y
∣
x
)
=
1
\sum_y \pi^*(y|x)=1
∑yπ∗(y∣x)=1 。
π
∗
(
y
∣
x
)
=
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
\pi^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac {1}{\beta} r(x,y)\right)
π∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))
因为
Z
(
x
)
Z(x)
Z(x)不是关于y的函数,将前面的式(2)重新组织成:
min
π
E
x
∼
D
E
y
∼
π
(
y
∣
x
)
[
log
π
(
y
∣
x
)
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
−
log
Z
(
x
)
]
=
min
π
E
x
∼
D
[
E
y
∼
π
(
y
∣
x
)
[
log
π
(
y
∣
x
)
π
∗
(
y
∣
x
)
]
−
log
Z
(
x
)
]
=
min
π
E
x
∼
D
[
D
K
L
(
π
(
y
∣
x
)
∣
∣
π
∗
(
y
∣
x
)
)
−
log
Z
(
x
)
]
\min_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \mathbb{E}_{ y \sim \pi(y|x)} \left[\log \frac {\pi(y|x)} {\frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac {1}{\beta} r(x,y)\right) }- \log Z(x) \right] = \\ \min_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \left [ \mathbb{E}_{ y \sim \pi(y|x)} \left[\log \frac {\pi(y|x)} {\pi^*(y|x)} \right] - \log Z(x) \right] = \\ \min_{\pi} \mathbb{E}_{x \sim \mathcal{D}} \left [ \mathbb{D}_{KL}(\pi(y|x) ||\pi^*(y|x)) - \log Z(x) \right]
πminEx∼DEy∼π(y∣x)
logZ(x)1πref(y∣x)exp(β1r(x,y))π(y∣x)−logZ(x)
=πminEx∼D[Ey∼π(y∣x)[logπ∗(y∣x)π(y∣x)]−logZ(x)]=πminEx∼D[DKL(π(y∣x)∣∣π∗(y∣x))−logZ(x)]
因为
Z
(
x
)
Z(x)
Z(x)不依赖于策略模型
π
\pi
π,所以上式的最小值只与KL散度项有关,根据Gibbs不等式只有当且仅当两个分布一样时KL散度取得最小值0,所以可得到最优解为:
π
(
y
∣
x
)
=
π
∗
(
y
∣
x
)
=
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
(
3
)
\pi(y|x) = \pi^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac {1}{\beta} r(x,y)\right) \qquad (3)
π(y∣x)=π∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))(3)
此时的解即使可以使用真实奖励函数
r
∗
r^*
r∗的MLE估计
r
ϕ
r_{\phi}
rϕ,但是估计配分函数
Z
(
x
)
Z(x)
Z(x)依然很难,所以DPO作者进一步对式(3)进行重新组织,使得奖励函数可以由相应的最优策略模型
π
r
\pi_r
πr、参考策略模型
π
ref
\pi_{\text{ref}}
πref和
Z
(
x
)
Z(x)
Z(x)来表示。首先对上面式(3)两边取对数,并移项得到奖励的估计值。
π
r
(
y
∣
x
)
=
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
⇒
log
(
π
r
(
y
∣
x
)
)
=
log
(
1
Z
(
x
)
π
ref
(
y
∣
x
)
exp
(
1
β
r
(
x
,
y
)
)
)
⇒
log
(
π
r
(
y
∣
x
)
)
−
log
(
1
Z
(
x
)
)
−
log
(
π
ref
(
y
∣
x
)
)
=
log
(
exp
(
1
β
r
(
x
,
y
)
)
)
⇒
r
(
x
,
y
)
=
β
log
(
π
r
(
y
∣
x
)
π
ref
(
y
∣
x
)
)
+
β
log
(
Z
(
x
)
)
.
(
4
)
\begin{aligned} & \pi_r(y \mid x)=\frac{1}{Z(x)} \pi_{\text {ref }}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right) \\ \Rightarrow & \log \left(\pi_r(y \mid x)\right)=\log \left(\frac{1}{Z(x)} \pi_{\text {ref }}(y \mid x) \exp \left(\frac{1}{\beta} r(x, y)\right)\right) \\ \Rightarrow & \log \left(\pi_r(y \mid x)\right)-\log \left(\frac{1}{Z(x)}\right)-\log \left(\pi_{\text {ref }}(y \mid x)\right)=\log \left(\exp \left(\frac{1}{\beta} r(x, y)\right)\right) \\ \Rightarrow & r(x, y)=\beta \log \left(\frac{\pi_r(y \mid x)}{\pi_{\text {ref }}(y \mid x)}\right)+\beta \log (Z(x)) . \qquad (4) \end{aligned}
⇒⇒⇒πr(y∣x)=Z(x)1πref (y∣x)exp(β1r(x,y))log(πr(y∣x))=log(Z(x)1πref (y∣x)exp(β1r(x,y)))log(πr(y∣x))−log(Z(x)1)−log(πref (y∣x))=log(exp(β1r(x,y)))r(x,y)=βlog(πref (y∣x)πr(y∣x))+βlog(Z(x)).(4)
因为Bradley-Terry (BT)模型规定人类偏好分布
p
∗
p^*
p∗可以表示为下式:
p
∗
(
y
1
≻
y
2
∣
x
)
=
e
x
p
(
r
∗
(
x
,
y
1
)
)
e
x
p
(
r
∗
(
x
,
y
1
)
)
+
e
x
p
(
r
∗
(
x
,
y
2
)
)
=
1
1
+
e
x
p
(
r
∗
(
x
,
y
2
)
)
e
x
p
(
r
∗
(
x
,
y
1
)
)
(
5
)
p^*(y_1 \succ y_2 |x) = \frac{exp(r^*(x, y_1))} {exp(r^*(x, y_1)) + exp(r^*(x, y_2))} \\ = \frac {1} {1+ \frac{exp(r^*(x, y_2))}{exp(r^*(x, y_1))}} \qquad (5)
p∗(y1≻y2∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1))=1+exp(r∗(x,y1))exp(r∗(x,y2))1(5)
将奖励估计值式(4)代入到式(5)中:
p
∗
(
y
1
≻
y
2
∣
x
)
=
1
1
+
e
x
p
(
β
log
(
π
∗
(
y
2
∣
x
)
π
ref
(
y
2
∣
x
)
)
+
β
log
(
Z
(
x
)
)
)
e
x
p
(
β
log
(
π
∗
(
y
1
∣
x
)
π
ref
(
y
1
∣
x
)
)
+
β
log
(
Z
(
x
)
)
)
=
1
1
+
e
x
p
(
β
log
(
π
∗
(
y
2
∣
x
)
π
ref
(
y
2
∣
x
)
)
−
β
log
(
π
∗
(
y
1
∣
x
)
π
ref
(
y
1
∣
x
)
)
)
=
σ
(
β
log
(
π
∗
(
y
1
∣
x
)
π
ref
(
y
1
∣
x
)
)
−
β
log
(
π
∗
(
y
2
∣
x
)
π
ref
(
y
2
∣
x
)
)
)
\begin{aligned} p^*(y_1 \succ y_2 |x) &= \frac {1} {1+ \frac{exp( \beta \log \left(\frac{\pi_*(y_2 \mid x)}{\pi_{\text {ref }}(y_2 \mid x)}\right)+\beta \log (Z(x)))}{exp(\beta \log \left(\frac{\pi_*(y_1 \mid x)}{\pi_{\text {ref }}(y_1 \mid x)}\right)+\beta \log (Z(x)))}} \\ &= \frac {1}{1 + exp(\beta \log \left(\frac{\pi_*(y_2 \mid x)}{\pi_{\text {ref }}(y_2 \mid x)}\right) - \beta \log \left(\frac{\pi_*(y_1 \mid x)}{\pi_{\text {ref }}(y_1 \mid x)}\right) )} \\ &= \sigma \left( \beta \log \left(\frac{\pi_*(y_1 \mid x)}{\pi_{\text {ref }}(y_1 \mid x)}\right) - \beta \log \left(\frac{\pi_*(y_2 \mid x)}{\pi_{\text {ref }}(y_2 \mid x)}\right) \right) \end{aligned}
p∗(y1≻y2∣x)=1+exp(βlog(πref (y1∣x)π∗(y1∣x))+βlog(Z(x)))exp(βlog(πref (y2∣x)π∗(y2∣x))+βlog(Z(x)))1=1+exp(βlog(πref (y2∣x)π∗(y2∣x))−βlog(πref (y1∣x)π∗(y1∣x)))1=σ(βlog(πref (y1∣x)π∗(y1∣x))−βlog(πref (y2∣x)π∗(y2∣x)))
于是通过建模人类偏好数据,DPO的最终优化目标如下式:
L
(
θ
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
β
log
(
π
θ
(
y
w
∣
x
)
π
ref
(
y
w
∣
x
)
)
−
β
log
(
π
θ
(
y
l
∣
x
)
π
ref
(
y
l
∣
x
)
)
)
]
(
6
)
L(\theta) = - \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \sigma \left( \beta \log \left(\frac{\pi_{\theta}(y_w \mid x)}{\pi_{\text {ref }}(y_w \mid x)}\right) - \beta \log \left(\frac{\pi_{\theta}(y_l \mid x)}{\pi_{\text {ref }}(y_l \mid x)}\right) \right) \right] \qquad (6)
L(θ)=−E(x,yw,yl)∼D[σ(βlog(πref (yw∣x)πθ(yw∣x))−βlog(πref (yl∣x)πθ(yl∣x)))](6)
DPO算法分析:
尝试分析DPO的目标函数的导数来理解DPO算法如何对LLM的参数进行优化,先设
u
=
β
log
(
π
θ
(
y
w
∣
x
)
π
ref
(
y
w
∣
x
)
)
−
β
log
(
π
θ
(
y
l
∣
x
)
π
ref
(
y
l
∣
x
)
)
u=\beta \log \left(\frac{\pi_{\theta}(y_w \mid x)}{\pi_{\text {ref }}(y_w \mid x)}\right) - \beta \log \left(\frac{\pi_{\theta}(y_l \mid x)}{\pi_{\text {ref }}(y_l \mid x)}\right)
u=βlog(πref (yw∣x)πθ(yw∣x))−βlog(πref (yl∣x)πθ(yl∣x)), 则上面DPO的目标函数式(6)的导数可以化简为:
∇
L
(
θ
)
=
−
∇
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
u
)
]
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
∇
σ
(
u
)
σ
(
u
)
∇
u
]
(
7
)
\nabla L(\theta) = -\nabla \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \sigma(u) \right] = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \frac{\nabla\sigma(u)}{\sigma(u)} \nabla u \right] \qquad (7)
∇L(θ)=−∇E(x,yw,yl)∼D[σ(u)]=−E(x,yw,yl)∼D[σ(u)∇σ(u)∇u](7)
sigmoid函数有性质
∇
σ
(
u
)
=
σ
(
u
)
(
1
−
σ
(
u
)
)
=
σ
(
u
)
σ
(
−
u
)
\nabla \sigma(u)=\sigma(u)(1-\sigma(u))=\sigma(u)\sigma(-u)
∇σ(u)=σ(u)(1−σ(u))=σ(u)σ(−u),我们设奖励的估计值为
r
^
θ
(
x
,
y
)
=
β
log
(
π
θ
(
y
∣
x
)
π
ref
(
y
∣
x
)
)
\hat{r}_{\theta}(x,y)=\beta \log \left(\frac{\pi_{\theta}(y \mid x)}{\pi_{\text {ref }}(y \mid x)}\right)
r^θ(x,y)=βlog(πref (y∣x)πθ(y∣x)),则上式(7)可以变成:
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
∇
σ
(
u
)
σ
(
u
)
∇
u
]
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
−
u
)
∇
u
]
=
−
β
E
(
x
,
y
w
,
y
l
)
∼
D
[
σ
(
r
^
θ
(
x
,
y
l
)
−
r
^
θ
(
x
,
y
w
)
)
⏟
higher weight when reward estimate is wrong
[
∇
θ
log
π
(
y
w
∣
x
)
⏟
increase likelihood of
y
w
−
∇
θ
log
π
(
y
l
∣
x
)
⏟
decrease likelihood of
y
l
]
]
,
\begin{aligned} &-\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \frac{\nabla\sigma(u)}{\sigma(u)} \nabla u \right] \\ &=-\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \sigma(-u)\nabla u \right] \\ &= -\beta \mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}[\underbrace{\sigma\left(\hat{r}_\theta\left(x, y_l\right)-\hat{r}_\theta\left(x, y_w\right)\right)}_{\text {higher weight when reward estimate is wrong }}[\underbrace{\nabla_\theta \log \pi\left(y_w \mid x\right)}_{\text {increase likelihood of } y_w}-\underbrace{\nabla_\theta \log \pi\left(y_l \mid x\right)}_{\text {decrease likelihood of } y_l}]], \end{aligned}
−E(x,yw,yl)∼D[σ(u)∇σ(u)∇u]=−E(x,yw,yl)∼D[σ(−u)∇u]=−βE(x,yw,yl)∼D[higher weight when reward estimate is wrong
σ(r^θ(x,yl)−r^θ(x,yw))[increase likelihood of yw
∇θlogπ(yw∣x)−decrease likelihood of yl
∇θlogπ(yl∣x)]],
所以DPO的损失函数的梯度会增加偏好内容
y
w
y_w
yw的似然、降低非偏好内容
y
l
y_l
yl的似然。前半部分
σ
(
r
^
θ
(
x
,
y
l
)
−
r
^
θ
(
x
,
y
w
)
)
\sigma\left(\hat{r}_\theta\left(x, y_l\right)-\hat{r}_\theta\left(x, y_w\right)\right)
σ(r^θ(x,yl)−r^θ(x,yw)) 和
β
\beta
β一起动态地控制梯度下降的步长;当策略模型更倾向于生成非偏好内容
y
l
y^l
yl时,
r
^
θ
(
x
,
y
l
)
\hat{r}_\theta\left(x, y_l\right)
r^θ(x,yl)和
r
^
θ
(
x
,
y
w
)
\hat{r}_\theta\left(x, y_w\right)
r^θ(x,yw)之间的差值变大,导致梯度下降的步长变大,从而进行更为激进的参数更新来避免生成
y
l
y_l
yl;而当策略模型倾向于生成符合人类偏好的内容
y
w
y_w
yw时,说明策略模型当前具有较好的参数,此时梯度的系数变小(即
σ
(
r
^
θ
(
x
,
y
l
)
−
r
^
θ
(
x
,
y
w
)
)
\sigma\left(\hat{r}_\theta\left(x, y_l\right)-\hat{r}_\theta\left(x, y_w\right)\right)
σ(r^θ(x,yl)−r^θ(x,yw)) 的值变小), 使得策略模型的参数的更新幅度降低,防止更新步长过大使得策略模型的性能出现震荡,增加训练的稳定性。
DPO的改进算法
IPO
IPO出自2023年10月的deepmind研究院的论文《A General Theoretical Paradigm to Understand Learning from Human Preferences》,论文定义了DPO的通用形式并调整其形式来解决过拟合问题。IPO相当于 在DPO的损失函数上添加了一个正则项,从而可以使得不使用early stopping技巧就可以使模型收敛。
其损失函数定义如下式(
τ
\tau
τ与DPO里的
β
\beta
β类似)
L
I
P
O
(
π
)
=
E
(
x
,
y
w
,
y
l
)
∼
D
(
h
π
(
y
w
,
y
l
,
x
)
−
τ
−
1
2
)
2
h
π
(
y
,
y
′
,
x
)
=
log
(
π
(
y
∣
x
)
π
ref
(
y
′
∣
x
)
π
(
y
′
∣
x
)
π
ref
(
y
∣
x
)
)
\mathcal{L}_{IPO}(\pi) = \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left( h_{\pi}(y_w, y_l, x) - \frac{\tau^{-1}}{2} \right)^2 \\ h_{\pi}(y, y^{\prime}, x) = \log \left( \frac{\pi(y|x)\pi_{\text{ref}}(y^{\prime}|x) }{ \pi(y^{\prime}|x)\pi_{\text{ref}}(y|x) } \right)
LIPO(π)=E(x,yw,yl)∼D(hπ(yw,yl,x)−2τ−1)2hπ(y,y′,x)=log(π(y′∣x)πref(y∣x)π(y∣x)πref(y′∣x))
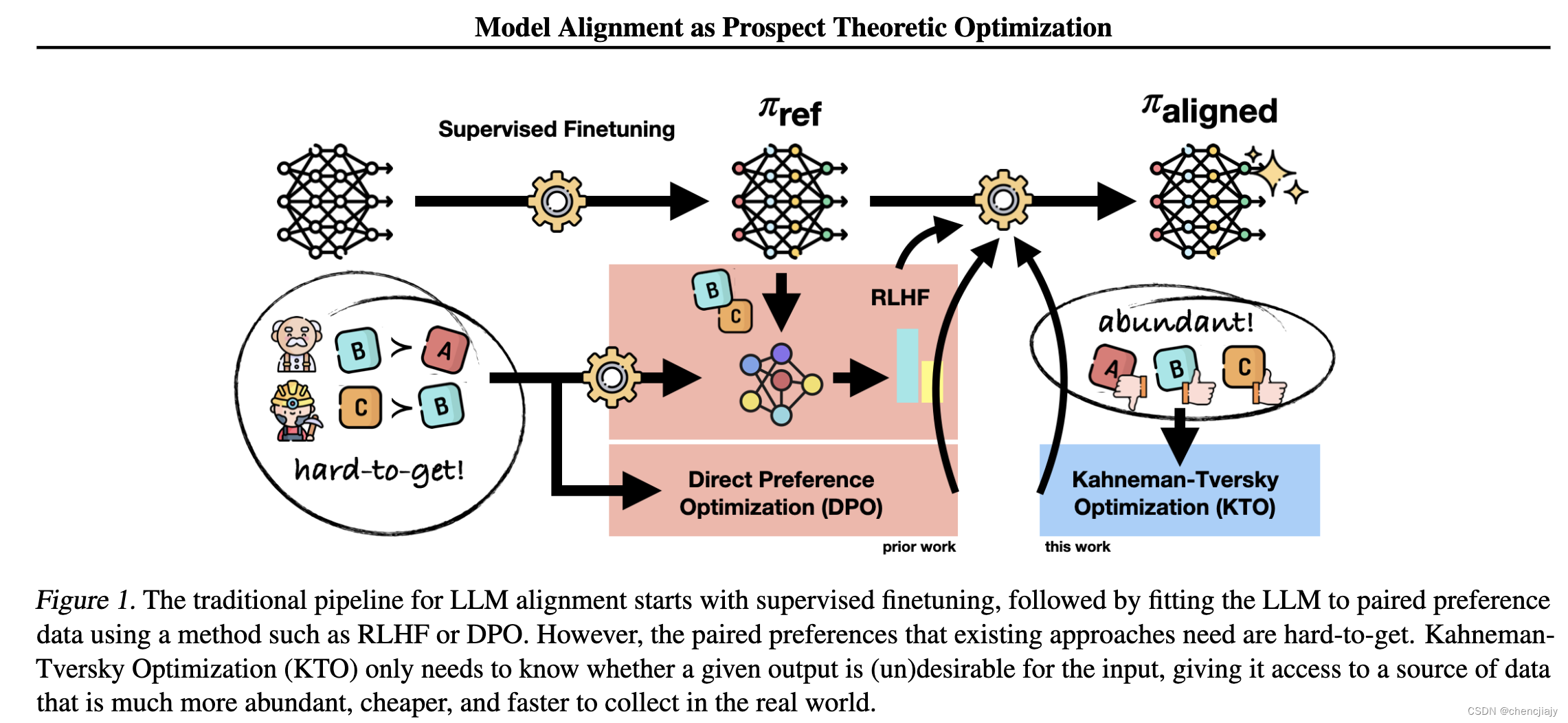
KTO
KTO(Kahneman-Tversky Optimization)出自2024年02月的论文《KTO: Model Alignment as Prospect Theoretic Optimization》

DPO等对齐方法训练时针对一个prompt需要一对偏好数据即 { x , y w , w l } \{x, y_w, w_l\} {x,yw,wl},这个数据标注过程耗时且费力,而KTO定义的损失函数只需要将样本标注为"好(good)“或"坏(bad)”,从而使得获取标注样本的成本更低。KTO还受到Kahneman & Tversky’s prospect theory的启发,即人类倾向于用有偏但明确定义的行为来对待随机变量,比如人类有损失厌恶。
KTO的损失函数如下:
L
K
T
O
(
π
θ
,
π
ref
)
=
E
x
,
y
∼
D
[
w
(
y
)
(
1
−
v
KTO
(
x
,
y
;
β
)
)
]
r
K
T
O
(
x
,
y
)
=
β
log
π
θ
(
y
∣
x
)
π
ref
(
y
∣
x
)
z
ref
=
E
x
′
∼
D
[
β
KL
(
π
θ
(
y
′
∣
x
′
)
∣
∣
π
ref
(
y
′
∣
x
′
)
)
]
v
KTO
(
x
,
y
;
β
)
=
{
σ
(
r
KTO
(
x
,
y
)
−
z
ref
)
if
y
∼
y
desirable
∣
x
σ
(
z
ref
−
r
KTO
(
x
,
y
)
)
if
y
∼
y
undesirable
∣
x
w
(
y
)
=
{
λ
D
if
y
∼
y
desirable
∣
x
λ
U
if
y
∼
y
undesirable
∣
x
L_{KTO}(\pi_{\theta}, \pi_{\text{ref}}) = \mathbb{E}_{x,y \sim D}[w(y)(1-v_{\text{KTO}}(x,y;\beta))] \\ r_{KTO}(x, y) = \beta \log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref}}(y|x)} \\ z_{\text{ref}} = \mathbb{E}_{x^{\prime} \sim D} [\beta\ \text{KL}(\pi_{\theta}(y^{\prime}|x^{\prime}) || \pi_{\text{ref}}(y^{\prime}|x^{\prime}))] \\ v_{\text{KTO}}(x,y;\beta) = \begin{cases} \sigma(r_{\text{KTO}}(x,y) - z_{\text{ref}}) \ \text{if} \ y \sim y_{\text{desirable}}|x \\ \sigma(z_{\text{ref}} -r_{\text{KTO}}(x,y) ) \ \text{if} \ y \sim y_{\text{undesirable}}|x \end{cases} \\ w(y) = \begin{cases} \lambda_D \ \text{if} \ y \sim y_{\text{desirable}}|x \\ \lambda_U \text{if} \ y \sim y_{\text{undesirable}}|x \end{cases}
LKTO(πθ,πref)=Ex,y∼D[w(y)(1−vKTO(x,y;β))]rKTO(x,y)=βlogπref(y∣x)πθ(y∣x)zref=Ex′∼D[β KL(πθ(y′∣x′)∣∣πref(y′∣x′))]vKTO(x,y;β)={σ(rKTO(x,y)−zref) if y∼ydesirable∣xσ(zref−rKTO(x,y)) if y∼yundesirable∣xw(y)={λD if y∼ydesirable∣xλUif y∼yundesirable∣x
-
直觉上KTO有效是因为如果模型增加偏好样本的奖励时,KL散度惩罚也会增加,则损失不会增加。这将使得模型去学习如何使输出是被偏好的,使得奖励增加但是保持KL惩罚项平稳甚至降低。
-
论文中里提到实现上通过在m大小的batch上匹配输入 x ′ x^{\prime} x′的不相关输出 y U ′ y^{\prime}_U yU′后在整个batch上计算 max ( 0 , 1 m ∑ log π θ ( y U ′ ∣ x ′ π ref ( y U ′ ∣ x ′ ) \max \left(0, \frac{1}{m}\sum\log\frac{\pi_{\theta}(y^{\prime}_U|x^{\prime}}{\pi_{\text{ref}}(y^{\prime}_U|x^{\prime}}\right) max(0,m1∑logπref(yU′∣x′πθ(yU′∣x′)得到,并且对于KL惩罚项不进行反向传播使得训练更稳定,这也意味着KL惩罚项只是来控制损失的饱和程度。
-
β \beta β与DPO中的含义一样,越小给模型 π θ \pi_{\theta} πθ偏离参考模型 π ref \pi_{\text{ref}} πref的惩罚就小。作者发现 β = 0.1 \beta=0.1 β=0.1在大多数数据上表现较好。
-
设 n D n_D nD和 n U n_U nU分别代表偏好和非偏好样本的个数,使用公式 λ D n D λ U n U ∈ [ 1 , 4 3 ] \frac{\lambda_Dn_D}{\lambda_U n_U} \in [1, \frac{4}{3}] λUnUλDnD∈[1,34]来设置 λ D \lambda_D λD和 λ U \lambda_U λU。
-
如果预训练模型足够好,作者们发现可以省略掉SFT过程直接进行KTO对齐微调在泛化质量上不会有损失。
CPO
CPO(Contrastive Preference Optimization)出自2024年1月的论文《Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation》。
CPO算法认为DPO因为有参考模型在内存使用上不够高效,并且意在缓解两个SFT在模型翻译场景应用下的缺点:1.SFT通过减少模型输出和金标准参考输出的差异使得模型性能受限于训练集的质量。2.SFT缺乏阻止模型拒绝翻译错误的机制。
CPO的损失函数由两部分组成,负对数似然损失(negative log-likelihood loss)
L
NLL
\mathcal{L}_{\text{NLL}}
LNLL和偏好损失
L
prefer
\mathcal{L}_{\text{prefer}}
Lprefer。
L
NLL
=
−
E
(
x
,
y
w
)
∼
D
[
log
π
θ
(
y
w
∣
x
)
]
L
prefer
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
σ
(
β
log
π
θ
(
y
w
∣
x
)
−
β
log
π
θ
(
y
l
∣
x
)
)
)
]
L
CPO
=
L
NLL
+
L
prefer
\mathcal{L}_{\text{NLL}} = - \mathbb{E}_{(x,y_w) \sim \mathcal{D}} [\log \pi_{\theta}(y_w|x)] \\ \mathcal{L}_{\text{prefer}} = - \mathbb{E}_{(x,y_w, y_l) \sim \mathcal{D}} [\log \sigma( \beta \log \pi_{\theta}(y_w|x)-\beta \log \pi_{\theta}(y_l|x)))] \\ \mathcal{L}_{\text{CPO}} = \mathcal{L}_{\text{NLL}} + \mathcal{L}_{\text{prefer}}
LNLL=−E(x,yw)∼D[logπθ(yw∣x)]Lprefer=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)−βlogπθ(yl∣x)))]LCPO=LNLL+Lprefer
几种方法的比较
β \beta β是这些算法共有的超参,并且对这些超参非常敏感。huggingface的一篇blog比较了DPO、KTO、IPO效果与其超参之间的关系,其结论是DPO和IPO效果差不多,相比KTO效果略好一点。
2024年4月的论文《Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks》评估了DPO及其几种变体算法。在三种场景:1. 保留SFT过程;2.略过SFT过程;3.略过SFT过程且使用指令微调模型;以及探索了不同训练集大小对它们的影响。结论是KTO在大多数基准上比其他几种方法效果好,但是这几种方法在对齐过程中都没有显著提升模型的推理和问答能力,但是提升了数学问题解决能力。并且研究表明对齐方法对于训练数据集的大小很敏感,在小数据集上表现更好。另外对于KTO和CPO方法可以略过SFT过程。
DPO与RLHF的比较
《Policy Optimization in RLHF: The Impact of Out-of-preference Data》结论是DPO用起来方便但是泛化能力弱于RLHF,性能损失可接近一倍。(来源知乎)
《Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study》 结论是PPO略好一点

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)