
A*(A-star)算法 定义+特性+原理+公式+Python示例代码(带详细注释)
引言
A*算法由Peter Hart, Nils Nilsson和Bertram Raphael在1968年提出,是解决路径搜索问题的一种启发式算法。它用于在图中找到从起始节点到目标节点的最短路径,并广泛应用于游戏设计、机器人导航等领域。
定义
A*(A-star)算法是一种在图中寻找从初始节点到目标节点最短路径的启发式搜索算法。它结合了Dijkstra算法的确保性(保证找到一条最短路径)和贪心算法的高效性(快速找到目标)。A* 算法通过评估函数 f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n) 来工作,其中 g ( n ) g(n) g(n) 是从起始点到任何顶点 n n n 的实际成本,而 h ( n ) h(n) h(n) 是从顶点 n n n 到目标的估计最低成本,通常用启发式函数来计算,这个函数需要事先设计来反映实际的地形或环境特征。理想情况下, h ( n ) h(n) h(n) 应该不会高估实际的成本,这种情况下,A* 算法保证找到一条最低成本路径。算法的性能和准确性高度依赖于启发式函数的选择。在实际应用中,A* 算法广泛应用于各类路径规划问题,如机器人导航、地图定位服务和游戏中的AI路径寻找等场景。通过适当选择和调整启发式函数,A* 算法能够在复杂的环境中有效地寻找最短路径,同时保持计算上的可行性和效率。
特性
A* 算法具有以下显著特性:
- 最优性:当启发式函数 h ( n ) h(n) h(n) 是可采纳的(即不会高估从任一节点到目标的成本时),A* 算法保证找到最短路径。
- 完备性:只要有解存在,A* 算法总能找到解,前提是节点扩展没有限制且启发式函数不返回无穷大值。
- 高效率:通过启发式函数有效指导搜索方向,A* 算法通常比其他简单的搜索算法如广度优先或深度优先搜索更快地找到最短路径。
- 灵活性:启发式函数的选择可以根据具体的应用场景灵活调整,影响算法的效率和行为。
- 普适性:适用于任何能够用图表示的路径搜索问题,从机器人路径规划到游戏设计中的AI挑战。
- 适应性:能够根据实时反馈调整启发式评估,适应于动态变化的环境中。
基本原理及公式推导
基本原理
A*算法是一种在图中寻找从起始点到目标点最短路径的启发式搜索算法。该算法使用三个主要函数: g ( n ) g(n) g(n), h ( n ) h(n) h(n),和 f ( n ) f(n) f(n) 来评估路径的优劣。
- g ( n ) g(n) g(n):从起始点到任何节点 n n n 的实际路径成本。
- h ( n ) h(n) h(n):从节点 n n n 到目标的预估成本,这是一个启发式估计,通常是从 n n n 到目标的直线距离。
- f ( n ) f(n) f(n):节点 n n n 的总成本估算,计算为 f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n)。
这些评价指标共同帮助算法决定在图中的哪个方向上继续搜索,以期达到最有效的路径搜索。
公式推导
-
启发式函数 h ( n ) h(n) h(n) 的定义
对于网格中的点 ( x , y ) (x, y) (x,y),若目标点是 ( x g o a l , y g o a l ) (x_{goal}, y_{goal}) (xgoal,ygoal),一个常用的启发式是欧几里得距离:
h ( n ) = ( x − x g o a l ) 2 + ( y − y g o a l ) 2 h(n) = \sqrt{(x - x_{goal})^2 + (y - y_{goal})^2} h(n)=(x−xgoal)2+(y−ygoal)2
-
成本函数 g ( n ) g(n) g(n) 的计算
每当我们从起始点通过路径移动到一个新节点, g ( n ) g(n) g(n) 将累加上到达该节点的移动成本。例如,如果每步移动成本为 1,则:
g ( n n e w ) = g ( n c u r r e n t ) + 1 g(n_{new}) = g(n_{current}) + 1 g(nnew)=g(ncurrent)+1
-
总评价函数 f ( n ) f(n) f(n) 的计算
结合上述两个值,我们得到 f ( n ) f(n) f(n) 来评价节点的总成本,以决定哪些节点应该被优先考虑:
f ( n ) = g ( n ) + h ( n ) f(n) = g(n) + h(n) f(n)=g(n)+h(n)
实现步骤与代码实现
实现步骤
-
初始化:
- 创建起始节点和目标节点,初始化 g、h 和 f 值。
- 创建开放列表(使用优先队列)和封闭列表,将起始节点加入开放列表。
-
节点处理:
- 从开放列表中取出 f 值最小的节点作为当前节点。
- 检查当前节点是否为目标节点。如果是,回溯路径并返回。
-
邻接节点探索:
- 计算当前节点的四个方向的邻接节点(上、下、左、右)。
- 对于每个邻接节点,检查是否为有效节点(即在网格范围内且不是障碍物)。
-
更新邻接节点:
- 对于每个有效的邻接节点,如果它不在封闭列表中,则计算它的 g、h 和 f 值。
- 使用
add_to_open函数判断是否将邻接节点添加到开放列表。
-
移动到封闭列表:
- 将当前节点移入封闭列表。
- 如果开放列表为空,说明没有找到路径,返回失败。
-
重复过程:
- 重复步骤 2-5,直到找到目标节点或开放列表为空
Python代码
import heapq
import matplotlib.pyplot as plt
import numpy as np
class Node:
"""节点类表示搜索树中的每一个点。"""
def __init__(self, parent=None, position=None):
self.parent = parent # 该节点的父节点
self.position = position # 节点在迷宫中的坐标位置
self.g = 0 # G值:从起点到当前节点的成本
self.h = 0 # H值:当前节点到目标点的估计成本
self.f = 0 # F值:G值与H值的和,即节点的总评估成本
# 比较两个节点位置是否相同
def __eq__(self, other):
return self.position == other.position
# 定义小于操作,以便在优先队列中进行比较
def __lt__(self, other):
return self.f < other.f
def astar(maze, start, end):
"""A*算法实现,用于在迷宫中找到从起点到终点的最短路径。"""
start_node = Node(None, start) # 创建起始节点
end_node = Node(None, end) # 创建终点节点
open_list = [] # 开放列表用于存储待访问的节点
closed_list = [] # 封闭列表用于存储已访问的节点
heapq.heappush(open_list, (start_node.f, start_node)) # 将起始节点添加到开放列表
print("添加起始节点到开放列表。")
# 当开放列表非空时,循环执行
while open_list:
current_node = heapq.heappop(open_list)[1] # 弹出并返回开放列表中 f 值最小的节点
closed_list.append(current_node) # 将当前节点添加到封闭列表
print(f"当前节点: {current_node.position}")
# 如果当前节点是目标节点,则回溯路径
if current_node == end_node:
path = []
while current_node:
path.append(current_node.position)
current_node = current_node.parent
print("找到目标节点,返回路径。")
return path[::-1] # 返回反向路径,即从起点到终点的路径
# 获取当前节点周围的相邻节点
(x, y) = current_node.position
neighbors = [(x-1, y), (x+1, y), (x, y-1), (x, y+1)]
# 遍历相邻节点
for next in neighbors:
# 确保相邻节点在迷宫范围内,且不是障碍物
if 0 <= next[0] < maze.shape[0] and 0 <= next[1] < maze.shape[1]:
if maze[next[0], next[1]] == 1:
continue
neighbor = Node(current_node, next) # 创建相邻节点
# 如果相邻节点已在封闭列表中,跳过不处理
if neighbor in closed_list:
continue
neighbor.g = current_node.g + 1 # 计算相邻节点的 G 值
neighbor.h = ((end_node.position[0] - next[0]) ** 2) + ((end_node.position[1] - next[1]) ** 2) # 计算 H 值
neighbor.f = neighbor.g + neighbor.h # 计算 F 值
# 如果相邻节点的新 F 值较小,则将其添加到开放列表
if add_to_open(open_list, neighbor):
heapq.heappush(open_list, (neighbor.f, neighbor))
print(f"添加节点 {neighbor.position} 到开放列表。")
else:
print(f"节点 {next} 越界或为障碍。")
return None # 如果没有找到路径,返回 None
def add_to_open(open_list, neighbor):
"""检查并添加节点到开放列表。"""
for node in open_list:
# 如果开放列表中已存在相同位置的节点且 G 值更低,不添加该节点
if neighbor == node[1] and neighbor.g > node[1].g:
return False
return True # 如果不存在,则返回 True 以便添加该节点到开放列表
def visualize_path(maze, path, start, end):
"""将找到的路径可视化在迷宫上。"""
maze_copy = np.array(maze)
for step in path:
maze_copy[step] = 0.5 # 标记路径上的点
plt.figure(figsize=(10, 10))
# 将迷宫中的通道显示为黑色,障碍物为白色
plt.imshow(maze_copy, cmap='hot', interpolation='nearest')
# 提取路径上的x和y坐标
path_x = [p[1] for p in path] # 列坐标
path_y = [p[0] for p in path] # 行坐标
# 绘制路径
plt.plot(path_x, path_y, color='orange', linewidth=2)
# 绘制起点和终点
start_x, start_y = start[1], start[0]
end_x, end_y = end[1], end[0]
plt.scatter([start_x], [start_y], color='green', s=100, label='Start', zorder=5) # 起点为绿色圆点
plt.scatter([end_x], [end_y], color='red', s=100, label='End', zorder=5) # 终点为红色圆点
# 添加图例
plt.legend()
# # 隐藏坐标轴
# plt.axis('off')
# 显示图像
plt.show()
# 设定迷宫的尺寸
maze_size = 100
# 创建一个空的迷宫,全部设置为0(表示可通过)
maze = np.zeros((maze_size, maze_size))
# 定义几个障碍物区块,每个障碍物区块是一个矩形
obstacle_blocks = [
(10, 10, 20, 20), # (y起始, x起始, 高度, 宽度)
(30, 40, 20, 30),
(60, 20, 15, 10),
(80, 50, 10, 45),
]
# 在迷宫中设置障碍物
for y_start, x_start, height, width in obstacle_blocks:
maze[y_start:y_start+height, x_start:x_start+width] = 1
# 设定起始点和终点
start = (0, 0)
end = (92, 93)
# 确保起始点和终点不是障碍物
maze[start] = 0
maze[end] = 0
# 输出迷宫的一部分,以确认障碍物的设置
print("迷宫左上角10x10区域的视图:")
print(maze[:10, :10])
path = astar(maze, start, end)
if path:
print("路径已找到:", path)
visualize_path(maze, path, start, end)
else:
print("没有找到路径。")
代码说明
本代码实现了 A* 算法,它是一种在网格中找到最短路径的启发式搜索算法。我们定义了一个 Node 类来表示搜索中的每个节点,其中包括节点的位置、从起点到该节点的成本(g)、从该节点到终点的估算成本(h)和两者的总和(f)。以下是代码的主要部分解释:
- Node 类:包含父节点、位置、g、h 和 f 值。重载了
__eq__以比较节点位置,__lt__以在优先队列中比较节点。 - astar 函数:实现 A* 搜索算法,维护开放列表和封闭列表,从起始点开始搜索直到达到终点或开放列表为空。
- add_to_open 函数:辅助函数,用于决定是否将一个节点添加到开放列表。
- visualize_path 函数:用于在网格上可视化找到的路径。
代码运行结果

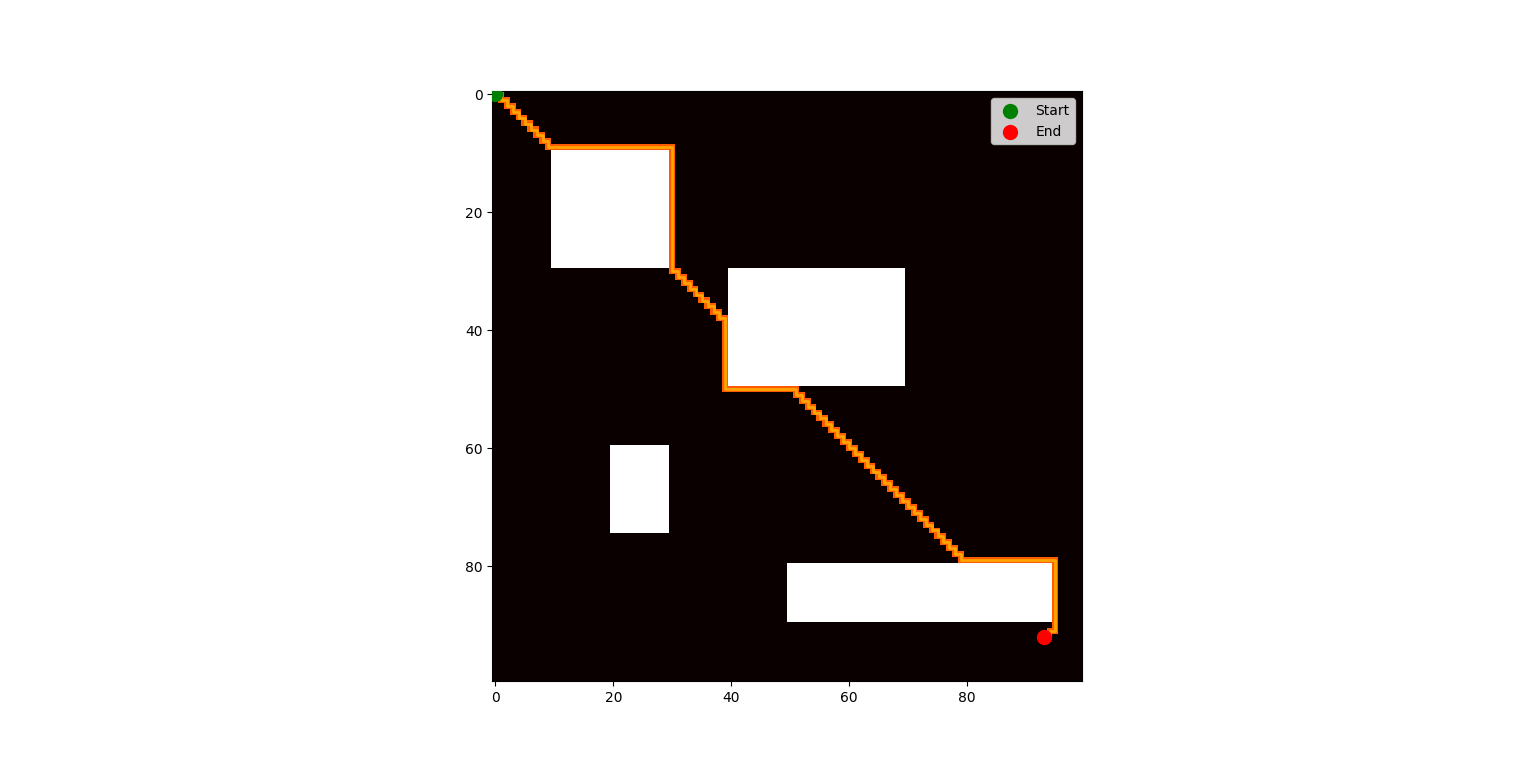
该图展示了使用 A* 算法在一个二维网格迷宫中的路径规划结果。迷宫中白色的矩形区域代表障碍物,黑色背景代表可以通行的空间。路径以橙色线条表示,它从左上角的绿点(起点)开始,穿越迷宫,绕过障碍物,最终到达右下角的红点(终点)。该可视化图像清楚地展示了算法从起始位置到目标位置寻找最短路径的过程,并且成功避开了所有障碍。
应用案例
A* 算法在多种领域中的应用包括:
- 地图导航系统:A* 算法广泛应用于 GPS 和在线地图服务中,用于计算从一个地点到另一个地点的最短路径。
- 视频游戏:在游戏开发中,A* 算法用于控制人工智能(AI)角色的路径寻找,使其能够高效地移动到目标位置。
- 机器人路径规划:机器人利用 A* 算法规划避开障碍物的最优移动路径,确保机器人从起点安全、有效地移动到终点。
- 网络路由:网络技术中使用 A* 算法来优化数据包的传输路径,从而减少延迟和提高传输效率。
- 图形用户界面设计:在图形软件中,A* 可用于自动排线或连接元件,如电路设计和流程图软件中的最佳布线。
- 数据分析:在数据科学中,A* 算法可帮助分析和找到数据点之间的最短路径或最佳连接方式,用于复杂网络分析。
优化和挑战
挑战
- 启发式函数的选择:A* 算法的效率和效果高度依赖于启发式函数 h ( n ) h(n) h(n) 的准确性。选择一个不合适的启发式函数可能导致路径搜索效率低下,或者在最坏的情况下,找不到解。
- 内存消耗:A* 算法需要维护开放列表和封闭列表,存储大量的节点信息,这在处理大规模图或复杂环境时可能会消耗大量内存。
- 动态环境适应性:在动态变化的环境中,如移动障碍物或实时更新的地图数据,A* 算法需要不断重新计算,这可能会影响其实时性能。
- 计算复杂度:在图特别大或特别密集的情况下,即使是 A* 算法也可能因为需要评估的节点过多而导致计算量大和速度慢。
优化
- 改进启发式函数:研究和开发更加准确的启发式评估方法,以更好地预测实际成本,提高算法的搜索效率和减少搜索空间。
- 内存管理优化:实施更高效的数据结构来管理开放和封闭列表,如使用斐波那契堆等优化过的优先队列,以减少内存使用和提高操作效率。
- 增量式搜索:对于动态环境的应用,开发基于 A* 的增量式搜索算法,如 D* Lite,能够在环境变化时快速更新已有路径而不是重新计算整条路径。
- 并行处理:利用现代多核处理器的能力,通过并行化处理来提高 A* 算法的计算效率,尤其是在处理大规模数据集时。
结论
A* 算法是一种强大且灵活的路径搜索算法,适用于各种从点A到点B的最短路径搜索问题。通过合理选择启发式函数,A* 算法不仅能保证找到最短路径,还能在执行过程中保持高效。面对复杂的实际应用场景,适当的优化和算法调整可以进一步提升其性能,满足更广泛的应用需求。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 54
54 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)