
python爬虫爬取微博评论--完整版(超详细,大学生不骗大学生)
目录
一、找到页面
首先你需要找到一个你想要爬取的页面
(这里我是随机找的一个微博帖子)

它的评论内容是这样的

然后我们今天的内容就是从这个页面的评论里面提取我们想要的
(其实学会了之后不只可以爬取评论的内容喔!!)
二、学会使用检查元素
2.1 打开检查元素界面
在你打开的页面->单机右键->检查元素(或者是审查元素),然后我们就可以看到这个界面

这里你的上面一行表头可能会是英文嘟没关系(我会把英文界面该点的标在括号里)
我们主要用的是网络(network)这部分
点击网络(network)

如果点击小放大镜后界面和我这个差不多那就大概率是对的
如果你没有这小放大镜可以换个浏览器
(我目前用下来,苹果自带的Safari浏览器是不行的,我用的这个例子里是360浏览器,是OK嘟,大家可以参考一下)
2.2 找到所有评论所在的位置
2.2.1 搜索评论
这里我们在搜索的界面输入我们这个帖子里面随便一条评论的内容,点击搜索

如果你在这里黏贴了评论的内容但是,显示搜索不到结果你可以试一试
不关闭检查元素的界面->退出当前网页或者你随机点一个人的主页->再回到评论界面->搜索评论内容就会出现了!
2.2.2 找到data表
下一步我们 点击搜索出的结果

显示的界面是这样的

然后我们点击这个预览(preview)
再说一次喔,有可能大家的检查元素打开的是全英文的,但是没关系我会把英文该点的标在括号里
(后面的大部分操作都是在这个预览界面的)

点击data旁边的小三角,展开data

展现的结果是这样的

然后这个里面的0-19,就是0-19条评论的数据,包括一些评论内容,评论人的ID,评论被点赞的数量等等,我们一会要爬取的数据就是从这里来的
三、基础部分代码实现
首先我们要知道想要爬取一个网站的数据我们首先需要访问网站
我们的代码需要通过网站的url来找到网站
下面我们先将爬取网站的基础格式写出来
#requets是一个爬虫的第三方库,需要单独安装
import requests
#url是一访问网站的地址(这个不是很了解,但是我们代码是需要通过url来找到你要爬取的网页)
url = ''
#1.发送请求(定义一个response变量用来存储从url所对应的网页得到的信息)
response = requests.get(url=url)
#2.打印请求状态(response有很多属性,比如text等等,但是直接打印response是打印当前请求的状态码,200是成功,404是错误)
print(response)从上面的几行代码我们就能实现对网站的访问,但是,我们该怎么获取一个网站的url呢?
找到我们有data列表的那个检查元素界面->点击标头(headers)

在这里可以看到一个 “请求网址” (URL),这个就是我们的请求头
将这个URL复制到我们代码里面
#requets是一个爬虫的第三方库,需要单独安装
import requests
#url是一访问网站的地址
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291&fetch_level=0&locale=zh-CN'
#1.发送请求
response = requests.get(url=url)
#2.打印请求状态
print(response)这里我用PyCharm运行一下代码

可以看到输出显示 <Response [200]>,代表着我们访问成功了
下一步我们可以试着把网页的数据用 .text的方式拿出来
#requets是一个爬虫的第三方库,需要单独安装
import requests
#url是一访问网站的地址
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291&fetch_level=0&locale=zh-CN'
#1.发送请求
response = requests.get(url=url)
#2.打印网页数据
print(response.text)我们运行一下

但是我们发现这个并不是像我们想的一样,将网页的文本用文字的方式呈现,那么接下来我们要用到一个方法,让我们能够用文字的方式输出网页数据----->定义请求头
import requests
# 请求头
headers = {
# 用户身份信息
'cookie' : '',
# 防盗链
'referer' : '',
# 浏览器基本信息
'user-agent' : ''
}
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291'
# 1.发送请求
response = requests.get(url=url,headers=headers)
#2.打印网页数据
print(response.text)为什么要定义请求头,因为从网站的设置初衷,它是不想服务于我们的爬虫程序的,网站正常只想服务于客户的访问服务,那么我们要将我们的爬虫程序伪装成为正常的服务。
此时我们需要定义一些数据来伪装,通常我们只需要设置 cookie 、referee、user-agent就够了(如果有些特殊的网站可能需要我们有其他的参数)
那么我们cookie这些数据从哪里来呢,我们回到网站的那个请求头(headers)的检查元素界面

在这个界面向下划动,找到 cookie 、referer 、user-agent

我们将 cookie 、referer 、user-agent 的数据分别粘贴在代码里面
import requests
# 请求头
headers = {
# 用户身份信息
'cookie' : 'XSRF-TOKEN=KVMLznKAi1u5t7UavCDVyD0I; _s_tentry=weibo.com; Apache=3869338173200.8403.1711845564842; SINAGLOBAL=3869338173200.8403.1711845564842; ULV=1711845565244:1:1:1:3869338173200.8403.1711845564842:; PC_TOKEN=dcbe0bd978; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; SSOLoginState=1711845601; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-aVUQoUZdu9LfLYmAiNsLqi43OBU2ZJdNYv4zIWorgKZiAz8JGn2kAugZwnStCVYKw==',
# 防盗链
'referer' : 'https://weibo.com/2810373291/O7pPo1Ptb',
# 浏览器基本信息
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291'
# 1.发送请求
response = requests.get(url=url,headers=headers)
#2.打印网页数据
print(response.text)
运行一下

在这里可以看到,我们已经拿到文字式的数据,但是数据过于多和复杂,没办法很好的现实提取评论内容
四、格式化输出
那么接下来,我们想要将这些数据更加规整的输出
4.1 了解存储格式
1.那么我们首先要观察这些数据的存储方式
打开网页 -> 单击右键 -> 审查元素 -> 搜索一条评论 -> 点击预览(preview) -> 点击data旁边的小箭头 -> 点击 0 旁边的小箭头

那么在这林我们可以看到这里存有很多关于评论的数据,例如text_raw是评论的文本内容,source是发表评论人的ip来源地,id是发表评论人的id等等等
4.2 单独取出内容
那么我们先将第一个评论的text_raw用代码取出来试一下
import requests
# 请求头
headers = {
# 用户身份信息
'cookie' : 'XSRF-TOKEN=KVMLznKAi1u5t7UavCDVyD0I; _s_tentry=weibo.com; Apache=3869338173200.8403.1711845564842; SINAGLOBAL=3869338173200.8403.1711845564842; ULV=1711845565244:1:1:1:3869338173200.8403.1711845564842:; PC_TOKEN=dcbe0bd978; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; SSOLoginState=1711845601; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-aVUQoUZdu9LfLYmAiNsLqi43OBU2ZJdNYv4zIWorgKZiAz8JGn2kAugZwnStCVYKw==',
# 防盗链
'referer' : 'https://weibo.com/2810373291/O7pPo1Ptb',
# 浏览器基本信息
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291'
# 1.发送请求
response = requests.get(url=url,headers=headers)
#2.打印网页数据
# .text:获取文本数据
# .json():json字符串数据
# .content:获取二进制数据
# 这里如果我们想要单独取出数据,我们需要用json格式,它是一个格式化的数据
# 用json格式获取数据后我们要找到第一条评论的内容
# 我们把preview界面看作一个文件夹,那么我们首先打开的是 data ,然后是 0 ,然后是 text_raw
# 这里注意 data、text_raw 是字符串要加单引号,但是 0 是整数不用单引号
# 最后用类似于数组的方式访问
print(response.json()['data'][0]['text_raw'])运行一下

可以看到我们顺利取到了第一条评论的内容
4.3 取出所有评论内容
接下来我们将所有的评论内容都取出来,但是我们也不能一条一条写01234,所以,这里我们会用到循环
import requests # 请求头 headers = { # 用户身份信息 'cookie' : 'XSRF-TOKEN=KVMLznKAi1u5t7UavCDVyD0I; _s_tentry=weibo.com; Apache=3869338173200.8403.1711845564842; SINAGLOBAL=3869338173200.8403.1711845564842; ULV=1711845565244:1:1:1:3869338173200.8403.1711845564842:; PC_TOKEN=dcbe0bd978; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; SSOLoginState=1711845601; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-aVUQoUZdu9LfLYmAiNsLqi43OBU2ZJdNYv4zIWorgKZiAz8JGn2kAugZwnStCVYKw==', # 防盗链 'referer' : 'https://weibo.com/2810373291/O7pPo1Ptb', # 浏览器基本信息 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36' } url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291' # 1.发送请求 response = requests.get(url=url,headers=headers) # 2.打印网页数据 # 定义一个json_data来存储 response.json()的数据 json_data = response.json() # 定义一个data_list取出所有data中的数据 data_list = json_data['data'] # 定义一个data数据,让它便利data_list里面的对象 # 这里怎么理解呢,data_list看作一个数组,我让data等于数组的第一个数 # 然后执行操作,执行完之后返回for,我们再另data等于数组的第二个数执行操作 # 循环往复 for data in data_list: # 这里 data 代表着 data_list的第一个数也就是 ['data'][0] text_raw = data['text_raw'] print(text_raw)
运行一下

4.4 格式化读取信息
可以看到我们已经取出了所有的评论,那么可能大家还需要爬取这个评论的其他数据,例如发评论人的id,昵称和该条评论的点赞数量
import requests
# 请求头
headers = {
# 用户身份信息
'cookie' : 'XSRF-TOKEN=KVMLznKAi1u5t7UavCDVyD0I; _s_tentry=weibo.com; Apache=3869338173200.8403.1711845564842; SINAGLOBAL=3869338173200.8403.1711845564842; ULV=1711845565244:1:1:1:3869338173200.8403.1711845564842:; PC_TOKEN=dcbe0bd978; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; SSOLoginState=1711845601; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-aVUQoUZdu9LfLYmAiNsLqi43OBU2ZJdNYv4zIWorgKZiAz8JGn2kAugZwnStCVYKw==',
# 防盗链
'referer' : 'https://weibo.com/2810373291/O7pPo1Ptb',
# 浏览器基本信息
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291'
# 1.发送请求
response = requests.get(url=url,headers=headers)
# 2.打印网页数据
json_data = response.json()
data_list = json_data['data']
for data in data_list:
text_raw = data['text_raw']
id = data['id'] # 发表评论人的id
created_at = data['created_at'] # 评论发表在什么时候
like_counts = data['like_counts'] # 该评论的点赞数量
total_number = data['total_number'] # 该条评论被别人回复的数量
screen_name = data['user']['screen_name'] # 发表评论人的昵称
print(id,screen_name,text_raw,like_counts,total_number,created_at)运行一下

可以看现在的输出数据已经很规整了
五、导出成表格形式
我们将输出的数据导出成表格形式,更加方便我们观察与使用
import requests
import csv
f = open('评论.csv',mode='a',encoding='utf-8-sig',newline='')
csv_write = csv.writer((f))
csv_write.writerow(['id','screen_name','text_raw','like_counts','total_number','created_at'])
# 请求头
headers = {
# 用户身份信息
'cookie' : 'XSRF-TOKEN=KVMLznKAi1u5t7UavCDVyD0I; _s_tentry=weibo.com; Apache=3869338173200.8403.1711845564842; SINAGLOBAL=3869338173200.8403.1711845564842; ULV=1711845565244:1:1:1:3869338173200.8403.1711845564842:; PC_TOKEN=dcbe0bd978; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; SSOLoginState=1711845601; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-aVUQoUZdu9LfLYmAiNsLqi43OBU2ZJdNYv4zIWorgKZiAz8JGn2kAugZwnStCVYKw==',
# 防盗链
'referer' : 'https://weibo.com/2810373291/O7pPo1Ptb',
# 浏览器基本信息
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
url = 'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5017675820436181&is_show_bulletin=2&is_mix=0&count=10&uid=2810373291'
# 1.发送请求
response = requests.get(url=url,headers=headers)
# 2.获取数据
# 3.提取数据
json_data = response.json()
data_list = json_data['data']
for data in data_list:
text_raw = data['text_raw']
id = data['id']
created_at = data['created_at']
like_counts = data['like_counts']
total_number = data['total_number']
screen_name = data['user']['screen_name']
print(id,screen_name,text_raw,like_counts,total_number,created_at)
# 4.保存数据
csv_write.writerow([id,screen_name,text_raw,like_counts,total_number,created_at])运行一下

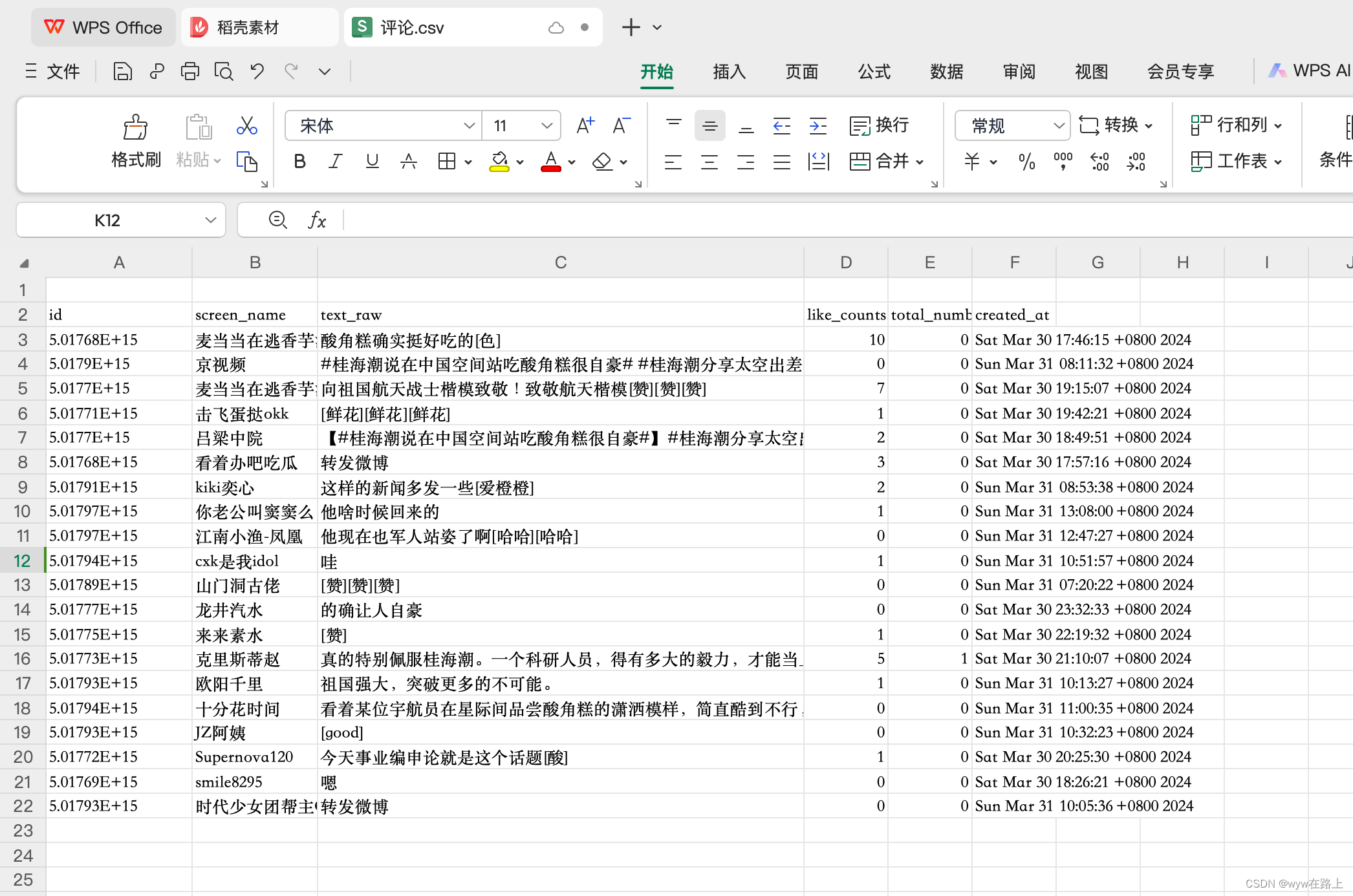
我们可以看到,有一个格式是 .csv 的文件生成了,我们可以在访问中打开它

打开表格


太棒啦能看到这里!!!!!!!(加油加油加油)
六、了解分页
6.1 查看分页
这里为了方便演示多页的评论,我寻找了一个评论在两千条左右的帖子
找到页面 -> 单机右键 -> 检查元素(审查元素) -> 点击网络(network) -> 点击小的放大镜(搜索)-> 复制一条评论 -> 进行搜索 -> 点击标头(headers)
PS:之前的文章里有详细的一步一步的操作演示,如果有遇到问题的可以去看一下

我们能看到这个界面,这是你复制的那条评论所对应的分页的一个URL
在这里我们可以看到这个“buildComments”,这是对应的整篇帖子的评论的包,我们复制这一小部分

注意不要复制多了真正需要复制的其实只有buildComments,也可以自己打,但是为了避免手打出现错误我是比较推荐复制
将这一小部分粘贴至过滤(filter) -> 回车

此时我们会看到,立即出现一个分页的搜索结果
然后不关闭检查元素的界面 -> 我们将鼠标移到帖子的部分,向下划动贴子中的评论,此时我们会发现,随着我们不断向下划动,会逐渐出现更多的搜索结果

6.2 寻找分页的规律
首先我们观察一下第一个分页的URL
点击第一个搜索的结果(就是名称下面的那四行,我们先点击第一行)

在这里我们可以看到第一个页面的URL是这样的
然后我们查看第二个页面的URL

我们观察一下这两个URL的区别

我们发现绿色框住的是第一个分页的,它是“count=10”没有max_id,二粉色框住的URL是有max_id的,不知道大家之前有没有印象,在我们预览(preview)界面中,我们是见到过max_id的,所以我们观察一下第一个分页的max_id
打开第一个分页的预览(preview)界面

我们发现第一个分页的max_id和第二个分页URL中的max_id是完全一样的,我们可以多观察几组(例如第二个分页的max_id和第三个分页URL中的max_id)
然后我们就发现了不同分页之间的规律
七、多页实现
在前面的代码中我们已经实现了单页的评论爬取,在这里我们是需要对URL进行修改就可
(下面演示的代码是不完全,只写出来新加的代码)
headers = {
# 之前的headers的值
}
# 定义一个get_next宏函数,在函数立里面定一个next变量,它的初值是 count=10
def get_next(next='count=10’):
# 然后我们把URL这里的 count=10 替换成 next 变量的值
url = f'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5003170104741808&is_show_bulletin=2&is_mix=0&{next}&uid=7190522839&fetch_level=0&locale=zh-CN’
response = requests.get(url=url,headers=headers)
json_data = response.json()
data_list = json_data['data']
max_id = json_data['max_id’] # 这里是单独获取这个分页的max_id
#这里是正常的格式化获取数据代码,为了方便观察新代码的结构我没写上
# 这里把单纯的 max_id 的数字加上 max_id=
max_str = 'max_id='+str(max_id)
# 调用get_next,且更行next的值
get_next(max_str)
# 调用方法
get_next()八、完整代码
我们把之前的代码加上
import requests
import csv
f = open('评论.csv',mode='a',encoding='utf-8-sig',newline='')
csv_write = csv.writer(f)
csv_write.writerow(['id','screen_name','text_raw','like_counts','total_number','created_at'])
# 请求头
headers = {
# 用户身份信息
'cookie': 'SINAGLOBAL=3869338173200.8403.1711845564842; SUB=_2A25LDMCxDeRhGeFJ71sS8CvLzTmIHXVoYFx5rDV8PUNbmtB-LVD9kW9Nf6JZvhCZ3PGanwgbD1yc6zGrHhnf6wrq; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W586R5s7_p1VykF21DkOu3L5JpX5o275NHD95QNS0B4e05fS0qfWs4DqcjAMJv09CH8SE-4BC-RSFH8SCHFxb-ReEH8SFHFBC-RBbH8Sb-4SEHWSCH81FHWxCHFeFH8Sb-4BEHWB7tt; ALF=1712450401; ULV=1711898034864:2:2:2:7503967975067.276.1711898034641:1711845565244; XSRF-TOKEN=aCKBvTY69V5X8kKbW1jSLjdj; WBPSESS=7dB0l9FjbY-Rzc9u1r7G0AeIukWsnj2u9VSmMssaP8z8nNdVQm3MrakDKiijTO3Y_iL6pEDJ8mgGw5Ql6jIh-fzvfDRMIeuWHMU2fJkIgYlwx20EQfKsyJ2pPS9worRswHbmrN7qQifEsHMJ5esrgA==',
# 防盗链
'referer': 'https://weibo.com/7190522839/O1kt4jTyM',
# 浏览器基本信息
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36'
}
def get_next( next = 'count=10'):
url = f'https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5003170104741808&is_show_bulletin=2&is_mix=0&{next}&uid=7190522839&fetch_level=0&locale=zh-CN'
response = requests.get(url=url,headers=headers)
json_data = response.json()
data_list = json_data['data']
max_id = json_data['max_id']
for data in data_list:
text_raw = data['text_raw']
id = data['id']
created_at = data['created_at']
like_counts = data['like_counts']
total_number = data['total_number']
screen_name = data['user']['screen_name']
print(id,screen_name,text_raw,like_counts,total_number,created_at)
csv_write.writerow([id,screen_name,text_raw,like_counts,total_number,created_at])
max_str = 'max_id='+str(max_id)
get_next(max_str)
get_next()
但是我每次爬的话最多是爬五百条左右,就感觉进度不怎么动了
到这第一步就彻底成功喽!!!!!!
打开生成的表格之前的文章里面有!
九、大多数报错原因
我的电脑是苹果的,它的user-agent可能和大家的电脑不一样,如果报json或者data的错误,可以尝试:
referer是网址,你打开网址检查元素,看一下url和cookie还有user-agent是不是一样的,然后修改一下,再看看能不能运行
有任何问题或者写的有错误,都可以在评论区和我说,虽然我不一定会,因为我也是刚入门!!
就是之前这篇文章是分上中下写的,后面怕大家感觉麻烦我就把上中下合成一个了
欢迎大家给我指出错误或者和我交流!!!!!!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 253
253 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)