
最详细最清晰的epoch、batchsize和iteration概念辨析
参考博文和图片来源 : Epoch vs Batch Size vs Iterations
1 前导知识
1.1 梯度下降和学习率
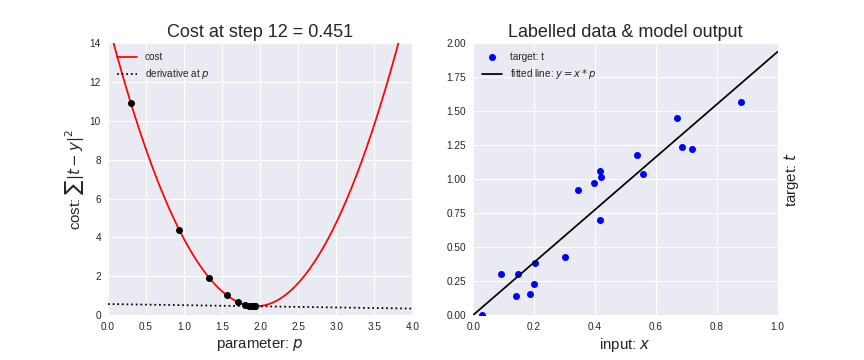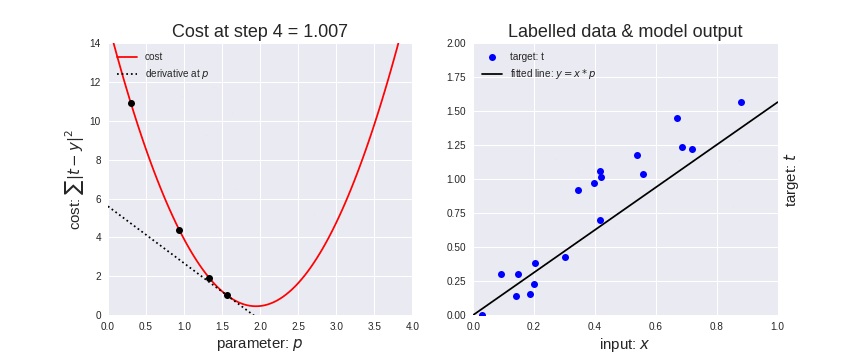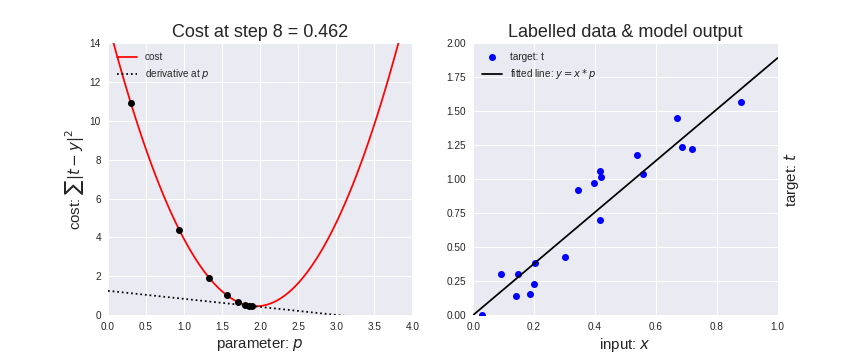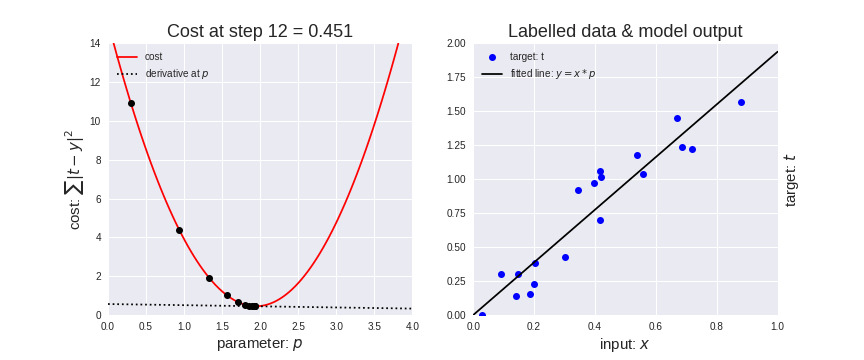
梯度下降算法是一种用于机器学习的迭代优化算法,用于寻找最佳结果(损失函数曲线的最小值)。
- 梯度(坡度)是指斜坡的倾斜度或倾斜度。
- Descent:下降。
该算法是迭代的(iterative),意味着我们需要多次进行多次计算才能得到最优的结果。

梯度下降法有一个参数叫做学习率(learning rate)。
如上图(左所示),一开始成本/损失函数(cost function)上的point下降的较快,说明学习率较大,步长大,随着该point的下降变慢,学习率逐渐减小,步长变慢。
梯度下降算法就是为了找到损失函数的最小值
1.2 为什么需要batchsize/epoch/iteration
当数据太大的时候,我们不能一次把所有的数据传递给计算机。因此我们需要将数据分成更小的大小,并将其一个接一个地交给我们的计算机,并在每一步结束时更新神经网络的权重。
2 Epoch
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE.
由于一个epoch太大,不能一次输入到计算机中,我们将它分成几个较小的批次(batches)。
2.1 为什么训练时需要很多个epoch
由于我们所使用的数据集是有限的,而且梯度下降算法是一个迭代过程,神经网络的权值参数更新也需要多次,所以一个epoch是远远不够的。

随着epoch次数的增加,神经网络中权值变化的次数增多,曲线从欠拟合到最优再到过拟合。
2.2 如何设置epoch的合适数量
不同的数据集需要设置的epoch的数量不同,没有标准答案。
3 BatchSize
Total number of training examples present in a single batch. 单个批次中出现的训练样例总数。
注:Batch size批次大小 and number of batches批次数量 are two different things.
batchsize = 8说明一次传入8张图片。
3.1 batchsize的设置技巧
一些经验之谈:
- 一般而言,根据GPU显存,设置为最大,而且一般要求是8的倍数(比如16,32,64),GPU内部的并行计算效率最高。
- 或者选择一部分数据,设置几个8的倍数的Batch_Size,看看loss的下降情况,再选用效果更好的值。
总结:
- batch_size设的大一些,收敛得快,也就是需要训练的次数少,准确率上升的也很稳定,但是实际使用起来精度不高;
- batch_size设的小一些,收敛得慢,可能准确率来回震荡,因此需要把基础学习速率降低一些,但是实际使用起来精度较高。
3.2 batchsize对训练有什么影响
1.训练速度
batch size大小会影响模型的训练速度。 较大的batch size可以更快地处理训练数据,因为在每个epoch中,较大的batch size可以同时处理更多的数据,从而减少了训练时间。相反,较小的batch size需要更多的迭代才能完成一个epoch的训练,因此训练时间更长。但是,较大的batch size也可能导致GPU显存不足,从而导致训练速度下降。
2.训练稳定性
batch size大小还会影响模型的训练稳定性。较小的batch size可以提高模型的训练稳定性,因为在每个epoch中,模型会更新多次,每次更新的权重都会有所不同,这有助于避免局部最优解。 另一方面,较大的batch size可能会导致模型过拟合,因为在每个epoch中,模型只进行一次权重更新,这使得模型更容易陷入局部最优解。
3.内存消耗
batch size大小还会影响内存消耗。较大的batch size需要更多的内存来存储样本和网络权重,因此可能会导致内存不足, 从而影响训练效果。另一方面,较小的batch size需要更少的内存,但也可能会导致训练时间变长。
4.梯度下降
batch size大小还会影响梯度下降。在深度学习中,梯度下降是一种常用的优化算法,用于调整模型的权重。较小的batch size可以使模型更容易收敛,因为每个batch中的样本更接近于独立同分布的分布,使得梯度下降的方向更加一致。另一方面,较大的batch size可能会导致梯度下降方向不一致,从而影响训练效果。
4 Iteration
Iterations is the number of batches needed to complete one epoch. 一个epoch中需要的batch的个数(迭代数)
注:上面提到的一个epoch中的批次数量就是一个epoch中的迭代次数
5 举例分析
一个dataset中有2000张图片,设置batchsize=500,则一个epoch中的iteration = 2000/500 = 4,则一个epoch中跑完一整个dataset需要迭代4个batch。
6 补充(3种梯度下降方法)
批量梯度下降(BGD)、随机梯度下降(SGD)以及小批量梯度下降(MBGD)的理解
6.1 批量梯度下降(Batch Gradient Descent,BGD)
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
即batchsize=数据集样本数
优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。 当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
(1)当样本数目 m很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。从迭代的次数上来看,BGD迭代的次数相对较少。
6.2 随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快。
batchsize = 1
优点:
(1)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛。
(2)可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
(3)不易于并行实现。
6.3 小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
对批量梯度下降以及随机梯度下降的一个折中办法。
其思想是:每次迭代 使用 batch_size 个样本来对参数进行更新。
batchsize = 设定的batchsize
优点:
(1)通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。
(2)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)
(3)可实现并行化。
缺点:
(1)batch_size的不当选择可能会带来一些问题。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 46
46 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)