
【数据库】GROUP BY 详解、示例、注意事项
一、基本介绍
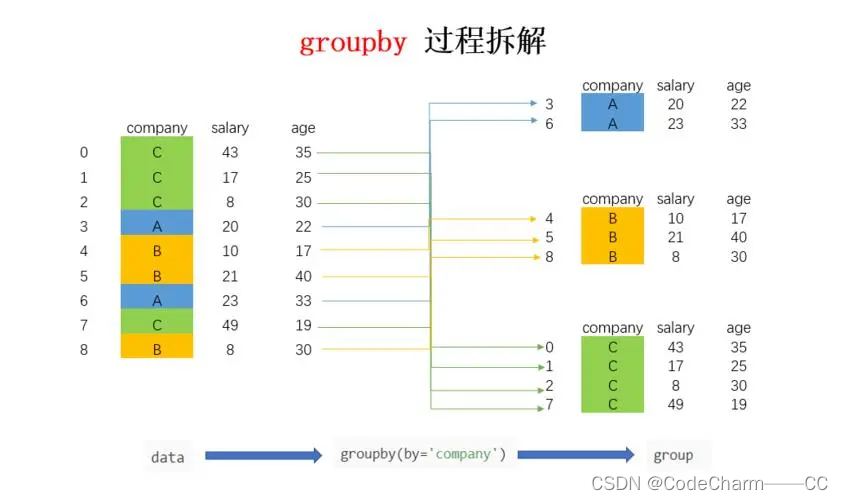
GROUP BY 语句在 SQL 中用于将来自数据库表的记录分组,以便可以对每个组执行聚合函数(如 COUNT(), MAX(), MIN(), SUM(), AVG() 等)。使用 GROUP BY 时,数据库会根据一个或多个列的值将结果集分为多个分组,在每个分组内可以独立地使用聚合函数。GROUP BY 通常与 SELECT 语句一起使用,以汇总每个分组的数据。

二、基本语法
SELECT column_name(s), AGGREGATE_FUNCTION(column_name)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
这个 SQL 模板展示了一个结构化查询语言(SQL)的基本结构,用于从数据库中选择、汇总、分组和排序数据。下面逐步解释每个部分的功能和作用:
-
sql SELECT column_name(s), AGGREGATE_FUNCTION(column_name)
SELECT关键字用于指定要从数据库表中检索的列或字段。column_name(s)是你想从选定表中选择的列的名称。你可以选择一个列、多个列或所有列(使用 *)。
AGGREGATE_FUNCTION(column_name)是应用于某列的聚合函数。聚合函数对数据进行数学运算,如计算平均值(AVG)、总和(SUM)、最大值(MAX)、最小值(MIN)或计数(COUNT)。 -
sql FROM table_nameFROM关键字后面跟着的是表名,指示 SQL 从哪个表中检索数据。 -
WHERE conditionWHERE
子句是可选的,用于指定筛选条件,以限制哪些行应该被包括在你的结果集中。只有满足指定条件的行才会被选中参与后续的GROUP BY或聚合操作。 -
GROUP BY column_name(s)
GROUP BY关键字后面跟着的列名用于指定数据库应该如何将数据分组。在使用聚合函数时,GROUP BY
使你能够将行分组成小的数据块,并对每个组分别计算聚合函数。如果有多个列,数据库将根据这些列的组合值进行分组。 -
ORDER BY column_name(s)
ORDER BY关键字用于指定结果集的排序方式。你可以根据一个或多个列进行排序。默认情况下,ORDER BY会按照升序(ASC)排列数据,但你也可以指定降序(DESC)。
三、关键点
- 分组列:
GROUP BY语句后面跟的是一个或多个列,数据库根据这些列的值将数据分组。同一组内的行在所有指定的列上都有相同的值。 - 聚合函数: 在分组的结果上通常会使用聚合函数来进行计算,如求每组的平均值、最大值、总和等。
- 选择列: SELECT 语句中可以包含分组列和聚合函数,但如果选择的列没有包含在 GROUP BY
中,且没有使用聚合函数处理,那么查询可能会返回错误。
四、示例
-
示例1
假设有一个 orders 表,其中包含 order_date 和 amount 列。如果我们想知道每个日期的总销售额,可以这样写:SELECT order_date, SUM(amount) FROM orders GROUP BY order_date;这个查询会根据 order_date 列的值将 orders 表中的记录分组,并计算每个日期的总销售额。
-
示例2
假设有一个名为 employees 的表,它有 department 和 salary 两列。如果你想知道每个部门的平均薪资,并按部门名排序,你的 SQL 语句可能如下:
SELECT department, AVG(salary) FROM employees WHERE salary > 0 GROUP BY department ORDER BY department;这个查询将:
- 1 、从 employees 表中选择记录(FROM employees)。
- 2、只包括那些 salary 大于 0 的行(WHERE salary > 0)。
- 3、按照 department 列的值将行分组(GROUP BY department)。
- 4、计算每个部门的平均薪资(AVG(salary))。
- 5、按部门名称对结果进行排序(ORDER BY department)。
这样,你就可以得到每个部门的平均薪资,并且结果是按照部门名称排序的。
五、注意事项
- 选择非聚合列:在 SELECT 子句中,除了聚合函数计算的列外,所有列都应该在 GROUP BY 子句中列出。如果你选择了一个没有包含在
GROUP BY 中的列,这通常会导致错误,因为没有聚合函数应用于它,数据库不知道如何为每个组选择一个值。 - NULL 值的分组:在分组时,GROUP BY 会将 NULL 值视为相同的值进行分组。这意味着所有 NULL 值会被归入同一组。
- 聚合函数的使用:在 SELECT 语句中可以使用多种聚合函数来计算每个组的统计信息,如 SUM()、AVG()、MAX()、MIN() 和 COUNT()。每个聚合函数都有其特定用途,选择合适的聚合函数可以帮助你获得需要的信息。
- HAVING 子句:如果你需要对分组后的结果进行过滤,应该使用 HAVING 子句而不是 WHERE 子句。WHERE
子句在数据分组前进行过滤,而 HAVING 子句在数据分组后对分组的结果进行过滤。 - 性能考虑:GROUP BY 操作可能会涉及大量的数据处理,特别是在处理大型数据集时。合理地选择分组列和优化聚合函数的使用可以帮助提高查询的性能。
- 分组顺序:在 GROUP BY 子句中列出多个列时,数据首先按照第一个列的值进行分组,然后是第二个列的值,以此类推。分组顺序可能会影响到输出结果的排序,但不会影响到分组聚合的结果。
- 与ORDER BY共用:虽然 GROUP BY 会对输出结果进行一定的排序(按照分组列排序),但如果你需要特定的排序顺序,应明确使用 ORDER BY 子句。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 53
53 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)