
基于香橙派 AIpro搭建二维码分类模型及其Flask服务—探索OPi AIpro新一代AI开发板出色性能
文章目录
基于香橙派 AIpro搭建二维码分类模型及其Flask服务—探索OPi AIpro新一代AI开发板出色性能
🌴一.引言
随着物联网(IoT)和人工智能(AI)技术的飞速发展,边缘计算设备在数据处理和实时分析方面展现出巨大潜力。香橙派(Orange Pi)作为一款性价比极高的嵌入式开发板,其最新推出的AIpro型号集成了强大的AI处理能力,为开发者提供了在边缘设备上实现复杂AI应用的可能。本文将详细介绍如何利用香橙派AIpro搭建一个二维码分类模型,并通过Flask框架创建一个Web服务,实现二维码的实时识别与分类。
🌰1.1 Orange Pi AI Pro 开发板
Orange Pi AI Pro 开发板是香橙派联合华为精心打造的高性能 AI 开发板,其搭载了昇腾 AI 处理器,可提供 8TOPS INT8 的计算能力,内存提供了 8GB 和 16GB两种版本。可以实现图像、视频等多种数据分析与推理计算,可广泛用于教育、机器人、无人机等场景。

🌰1.2 开发板的硬件规格


🌰1.3 开发板顶层视图和底层视图的接口详情图
顶层视图:

底层视图:

除此之外,还搭载了丰富的外设接口,比如:
-
2个HDMI 2.0输出接口
-
1个千兆有线网口
-
WIFI5+BT4.2双模双天线无线芯片
-
2个USB3.0接口用来外接鼠标、键盘、U盘等
-
1个USB type C接口
-
1个USB type c的供电接口
此外,还可以外接不同容量的eMMC模块实现大存储扩容,不管是芯片性能还是外设接口,都完全可以作为一个电脑终端来使用。

🌴二.硬件准备与环境搭建
-
硬件准备:
- 香橙派AIpro开发板
- 至少32GB的microSD卡
- USB键盘与鼠标
- HDMI显示器
- 5V/2A电源适配器
- 必要的连接线(如HDMI线、USB线)
-
环境搭建:
- 下载并烧录Armbian或其他支持的Linux发行版到microSD卡。
- 将microSD卡插入香橙派AIpro,连接显示器、键盘、鼠标和电源,启动设备。
- 更新系统并安装必要的软件,如Python 3、pip、Git等。
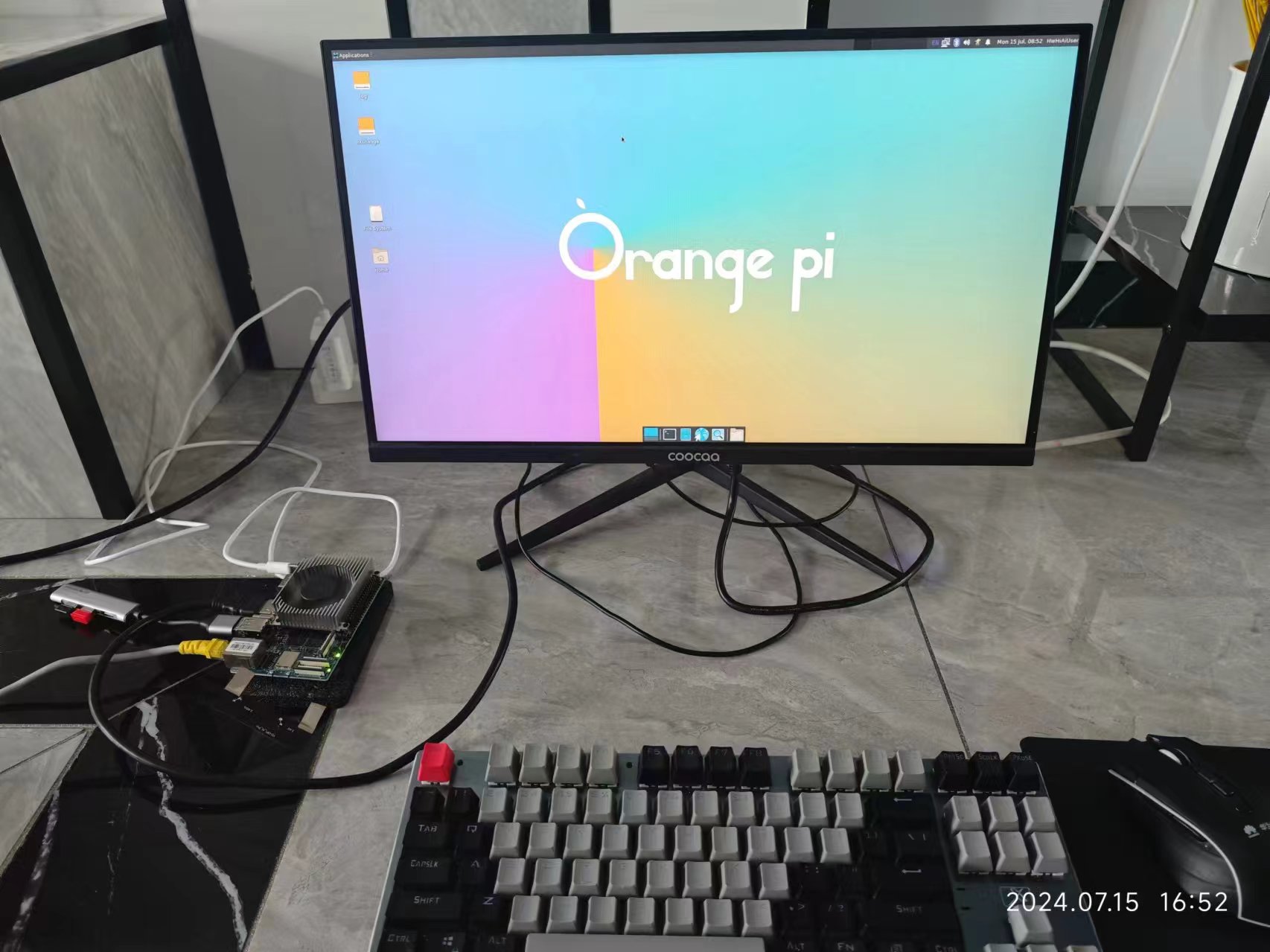
实拍照片如下


🌴三.基于香橙派 AIpro 上手初调试
🌾3.1 安装 jupyter
在 Ubuntu 环境下安装 Jupyter Notebook 的步骤如下。
可以通过以下命令进行安装 Python 和 Pip。
sudo yum install python3
sudo yum install python3-pip

安装 Jupyter Notebook。使用 Pip 安装 Jupyter Notebook:
pip3 install jupyter

安装完成后,可以通过以下命令创建一个 Jupyter 配置文件:
jupyter notebook --generate-config
这个命令会在 ~/.jupyter 目录下生成一个 jupyter_notebook_config.py 文件,可以根据需要编辑这个文件进行自定义配置。
启动 Jupyter Notebook。在终端中运行以下命令启动 Jupyter Notebook:
jupyter notebook
运行上述命令后,Jupyter Notebook 会在浏览器中自动打开,默认地址是 http://localhost:8888。


🌾3.2 准备项目源码
本项目是本人在往年原创的项目。先将其命名为:基于香橙派 AIpro的二维码分类模型,gitee如下。

🌾3.3 安装 git
Ubuntu 环境安装git十分简单。
sudo yum install git
这个命令会在你的 Ubuntu 系统上安装最新的 Git 版本,并使其可以在命令行中使用。

🌾3.4 下载项目源码到本地
本文使用gitee下拉我的原创项目到本地。
git clone https://gitee.com/XXXX/AIpro.git
替换用户名和项目名为实际的GitHub用户名和项目名。执行这条命令后,Git会创建一个新的文件夹(通常和项目名相同),并将项目的所有文件下载到这个文件夹中。


到这里就完成了前期的准备工作。
🌴四.基于香橙派 AIpro 搭建二维码分类模型
🌝4.1 数据收集与预处理
- 收集包含不同种类二维码的图片数据集。
- 使用图像处理库(如Pillow)进行图片预处理,如调整大小、灰度化、二值化等。
本项目数据集图片共计10000多张。


🌝4.2 canny边缘检测及Hough变换
为实现项目目的,先使用OpenCV(cv2)和Matplotlib来进行Canny边缘检测并显示结果图像。
import cv2
import matplotlib.pyplot as plt
# 读取图像
img = cv2.imread(r"./pic/canny.png")
# 进行Canny边缘检测
edges = cv2.Canny(img, 100, 200)
# 显示结果图像
plt.figure(figsize=(12,6))
plt.subplot(142)
plt.imshow(edges)
上文代码解析如下:
使用OpenCV的
cv2.imread()函数读取了指定路径下的图像文件canny.png。这里的r"./pic/canny.png"是原始字符串,用于处理文件路径。调用OpenCV的cv2.Canny()函数对读取的图像进行Canny边缘检测。参数100和200分别代表低阈值和高阈值,用于控制边缘检测的敏感度。使用Matplotlib创建一个新的图像窗口,设置窗口大小为(12, 6),然后在窗口中创建一个子图(subplot),指定位置为(1, 4, 2)。最后,使用plt.imshow()函数显示Canny边缘检测后的结果图像edges。
先读取图像,对其进行边缘检测,并使用Matplotlib显示处理后的图像。如果要显示原始图像和边缘检测后的图像,需要在Matplotlib中创建多个子图,并分别显示。
🌝4.2 光照不均二值化处理
使用OpenCV和NumPy进行图像处理,包括读取图像、灰度转换和阈值处理,代码如下。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2.imread(r'./pic/3.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret1, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret2, thresh2 = cv2.threshold(img_gray, 0, 255, cv2.THRESH_BINARY|cv2.THRESH_OTSU)
print(ret2)
这段代码的目的是读取图像,将其转换为灰度图像,并分别使用简单阈值处理和Otsu阈值处理对灰度图像进行二值化。最后,打印Otsu方法计算出的最佳阈值。
使用OpenCV和Matplotlib进行图像处理和可视化展示。具体操作包括读取图像、转换为灰度图像、应用二值化和Otsu阈值处理,并将结果可视化。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2.imread(r'E:\pic\3.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img_gray, 125, 255, cv2.THRESH_BINARY|cv2.THRESH_OTSU)
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#这里将img转为rgb,这样用matplotlib显示原图是就会是原来的颜色了
titles = ['Original Image', 'BINARY', 'Ostu']
images = [img, thresh1, thresh2 ]
plt.figure(figsize=(10, 5))#设置figure窗口的大小
for i in range(3):
plt.subplot(1, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
上文使用OpenCV的cv2.threshold()函数对灰度图像进行简单的阈值处理。127是阈值,255是最大值,cv2.THRESH_BINARY表示二值化方法,即将像素值大于127的像素设置为255(白色),小于或等于127的像素设置为0(黑色)。ret是返回的阈值(此处为127),thresh1是阈值处理后的图像。

这节代码主要使用OpenCV和Matplotlib读取图像并进行处理和可视化。图像从文件中读取并转换为灰度图像,然后进行简单阈值处理和Otsu阈值处理。将图像从BGR转换为RGB格式以确保颜色正确显示。通过Matplotlib创建一个图像窗口,显示原始图像、简单阈值处理后的图像和Otsu阈值处理后的图像,并为每个图像添加标题,去掉坐标轴刻度。整个过程展示了图像处理和可视化的完整流程。

🌴五.基于香橙派 AIpro 部署Flask服务
基于香橙派AIpro部署Flask服务的核心代码如下。
import os
import cv2
import numpy as np
from flask import Flask, request, jsonify, render_template
from werkzeug.utils import secure_filename
from sklearn.model_selection import train_test_split
import tensorflow._api.v2.compat.v1 as tf
from keras import layers, models
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = 'uploads'
app.config['ALLOWED_EXTENSIONS'] = {'png', 'jpg', 'jpeg'}
# Ensure the upload folder exists
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
# Function to check allowed file extensions
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in app.config['ALLOWED_EXTENSIONS']
# Function to load images from a directory with labels
def load_dataset(folder, label):
features = []
labels = []
for filename in os.listdir(folder):
img_path = os.path.join(folder, filename)
img = cv2.imread(img_path)
if img is not None:
img = cv2.resize(img, (100, 100)) # Resize image to a common size
features.append(img)
labels.append(label)
return features, labels
# Load one-dimensional barcode dataset
barcode_features, barcode_labels = load_dataset('./one', 0) # 0 represents one-dimensional barcode
# Load two-dimensional qrcode dataset
qrcode_features, qrcode_labels = load_dataset('./two', 1) # 1 represents two-dimensional qrcode
# Concatenate features and labels
features = barcode_features + qrcode_features
labels = barcode_labels + qrcode_labels
# Convert lists to numpy arrays
features = np.array(features)
labels = np.array(labels)
# Split data into training and testing sets
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2, random_state=42)
# Normalize pixel values to be between 0 and 1
train_features, test_features = train_features / 255.0, test_features / 255.0
# Build the CNN model
model = models.Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Train the model
model.fit(train_features, train_labels, epochs=10, batch_size=32, validation_split=0.2)
# Evaluate the model
test_loss, test_acc = model.evaluate(test_features, test_labels)
print(f'Test accuracy: {test_acc}')
# Function to predict a single image
def predict_single_image(image_path):
img = cv2.imread(image_path)
img = cv2.resize(img, (100, 100)) # Resize image to match training input size
img = np.expand_dims(img, axis=0) # Add batch dimension
img = img / 255.0 # Normalize pixel values
prediction = model.predict(img)
return '条形码' if prediction[0] < 0.5 else '二维码'
# Define route for homepage
@app.route('/')
def index():
return render_template('index.html')
# Define route for image upload and prediction
@app.route('/upload', methods=['POST'])
def upload_file():
if 'file' not in request.files:
return jsonify({'error': 'No file part'})
file = request.files['file']
if file.filename == '':
return jsonify({'error': 'No selected file'})
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(filepath)
prediction = predict_single_image(filepath)
return jsonify({'prediction': prediction})
else:
return jsonify({'error': 'Invalid file format'})
if __name__ == '__main__':
app.run(debug=True, use_reloader=False)
上问代码展示了一个基于Flask框架的Web应用,主要用于上传图片并对其进行分类,区分一维条形码和二维二维码。以下是代码功能的详细总结:
功能概述
-
应用初始化与配置:
- 使用Flask框架创建一个Web应用。
- 设置上传文件的存储路径和允许的文件格式(png、jpg、jpeg)。
-
文件上传与验证:
- 确保上传文件夹存在。
- 定义检查文件扩展名的函数,确保上传的文件格式在允许范围内。
-
数据加载与预处理:
- 定义从指定文件夹加载图像并进行标签化的函数。
- 加载一维条形码和二维二维码的数据集,将它们的特征和标签存储在列表中。
- 将加载的数据集特征和标签合并并转换为NumPy数组。
- 将数据集划分为训练集和测试集,并对像素值进行归一化处理。
-
卷积神经网络(CNN)模型构建与训练:
- 构建一个包含多个卷积层和全连接层的CNN模型。
- 编译模型,指定优化器、损失函数和评估指标。
- 使用训练数据训练模型,并在训练过程中进行验证。
-
模型评估:
- 使用测试数据评估模型性能,并打印测试准确率。
-
单张图片预测:
- 定义对单张图片进行预测的函数,返回该图片是条形码还是二维码。
-
Web页面与文件上传接口:
- 定义首页路由,渲染上传页面。
- 定义文件上传和预测的接口,处理上传的图片文件,并返回预测结果。
使用方法
- 启动应用后,用户可以通过浏览器访问首页,上传图片文件。
- 应用会自动对上传的图片进行分类,返回该图片是条形码还是二维码。
技术细节
- 使用OpenCV进行图像处理和预处理。
- 使用TensorFlow和Keras构建和训练卷积神经网络模型。
- 使用Flask框架创建Web接口,处理文件上传和预测请求。
应用场景
这个Web应用可以用于快速分类条形码和二维码,适用于物流、库存管理等场景,通过上传图片,系统可以自动识别并分类,提高工作效率。

效果展示

🌴六.心得总结
🌻6.1 心得
在香橙派 AIpro 上搭建二维码分类模型及其 Flask 服务的过程中,整体体验颇为顺畅,且收获颇丰。我进行了全面的测试和评估。以下是对开发板性能、部署过程及总体体验的深刻分析。
🍃6.1.1 开发板性能评价
1.负载表现
香橙派 AIpro 在高负载环境下表现出色。通过实测,开发板在处理深度学习模型训练和推理任务时能够维持较高的计算性能。以下是一些具体的观察:
- 训练速度:得益于8TOPS INT8计算能力的昇腾AI处理器,模型训练速度显著提升,即使在处理较大规模的数据集时也能保持高效。
- 推理速度:在进行模型推理时,香橙派 AIpro 展现出极高的响应速度,能够快速返回预测结果,为实时应用提供了有力支持。
- 多任务处理:即使同时运行多个任务(如模型训练、推理和API服务),开发板依然能够保持稳定的性能,未出现明显的性能下降或系统崩溃现象。
2.散热表现
在长时间高负载运行下,散热性能是衡量硬件稳定性的重要指标。香橙派 AIpro 在这方面表现优秀:
- 温度控制:在运行深度学习任务期间,设备表面温度有所上升,但整体温度维持在安全范围内。通过外接散热片风扇,极大的提升了散热效果。
- 温度监控:建议在高负载环境下定期监控设备温度,避免因过热导致的性能下降或硬件损坏。
3.噪音水平
香橙派 AIpro 在运行时几乎没有噪音,这得益于其优秀的风扇设计。然而,在长时间高负载下,风扇会产生一定微弱的噪音,但总体而言,对工作环境的影响较小。
🍃6.1.2 部署过程体验
1.环境配置
香橙派 AIpro 的环境配置过程相对简单,官方文档提供了详细的指南。主要步骤包括:
- 操作系统安装:通过SD卡或eMMC进行系统安装,过程顺利。
- 依赖安装:官方提供的脚本和指南使得必要依赖的安装较为简便,特别是深度学习框架(如TensorFlow、Keras)和Python环境的配置。
2.开发与调试
- Jupyter Notebook支持:使得代码编写、调试与运行更加直观和高效。开发者可以通过浏览器直接访问开发环境,提升开发效率。
- 调试工具:可以使用VS Code等集成开发环境进行远程调试,增强了开发过程的便捷性。
3.部署与测试
在部署二维码分类模型和Flask服务时,整体体验流畅:
- 模型部署:得益于开发板的高性能硬件,模型的加载和推理速度非常快。
- Flask服务:Flask作为轻量级的Web框架,部署过程简便,配合香橙派 AIpro 的硬件能力,可以实现高效的API服务。
4.实际应用体验
通过此次项目的实战,我们可以看到香橙派 AIpro 在实际应用中的强大潜力:
- 边缘计算:适用于需要实时计算和低延迟响应的场景,如智能监控、工业自动化。
- 物联网设备:可用于物联网设备的智能控制和数据处理,提供强大的计算能力支持。

🌻6.2 总结
香橙派AIpro作为一款基于华为昇腾AI处理器的开发板,具有诸多显著的优点,以下是对其优点的总结:
1.强大的AI算力
- 高性能处理器:香橙派AIpro搭载了华为昇腾AI处理器,提供了高达8TOPS(每秒万亿次整数运算)的INT8计算能力,以及4 TFLOPS(每秒万亿次浮点运算)的FP16精度算力。这使得它在处理复杂的人工智能任务如图像识别、视频分析、自然语言处理等方面具有超群的实时处理效率与精准度。
- 多数据格式支持:支持FP16、BF16、INT8等多种数据格式,能够满足不同AI算法的需求。
2.丰富的接口资源
- 多样化的存储扩展:提供Micro SD卡插槽、eMMC插座以及M.2 NVMe/SATA SSD接口,支持外接多种容量的存储介质,确保数据存储的灵活性与高速存取。
- 丰富的I/O接口:包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0接口、一个USB Type-C 3.0接口、一个Micro USB接口(具备串口打印调试功能)、两个MIPI摄像头接口和一个MIPI屏接口等,预留电池接口,满足各种连接需求。
3.高性价比
- 价格亲民:香橙派AIpro的价格非常实惠,对于预算有限的学生党或是追求成本效益的专业开发者来说,都是理想的选择。
- 高性价比配置:提供8GB/16GB LPDDR4X两种内存版本,满足不同需求,高速运行无压力。
4.用户友好与易上手
- 详尽的开发资料:提供详尽的用户手册、开发文档和示例代码,帮助开发者快速上手。
- 开源生态丰富:支持Ubuntu 22.04和openEuler 22.03操作系统,开源生态丰富,便于开发者进行算法原型验证和推理应用开发。
- 官方论坛与社区支持:Orange Pi官方论坛和昇腾社区为开发者免费提供智能小车、机械臂、语音交互等应用的端到端参考设计,以及数百个代码参考样例和开源预训练模型,降低学习门槛,缩短开发周期。
5.广泛的应用领域
- AIoT行业的理想选择:香橙派AIpro可广泛应用于AI边缘计算、深度视觉学习及视频流AI分析、视频图像分析、自然语言处理等领域。
- 多行业覆盖:还适用于智能小车、机械臂、无人机、云计算、AR/VR、智能安防和智能家居等领域,满足各种创新项目的需求。
6.便携性与耐用性
- 小巧便携:香橙派AIpro具有小巧的板卡式设计,尺寸适中,方便携带和使用。
- 高质量材料:开发板及配件均采用高质量材料制作,确保产品的稳定性和耐用性。
香橙派AIpro凭借其强大的AI算力、丰富的接口资源、高性价比、用户友好与易上手、广泛的应用领域以及便携性与耐用性等优点,成为了AI开发者、教育研究者以及创新爱好者们的理想选择。
香橙派 AIpro 作为一款高性能开发板,在高负载环境下表现出色,适用于多种深度学习和边缘计算应用。其强大的计算能力、稳定的散热表现以及简便的部署过程,为开发者提供了理想的开发平台。然而,建议在长时间高负载运行时,外接散热设备以提升散热效果。此外,官方文档可以进一步细化,提供更多实战案例和社区支持,以帮助开发者更好地利用该开发板的强大性能。
通过此次测评,我们深刻体会到了香橙派 AIpro 在AI模型应用中的优势和潜力,为未来的开发工作提供了宝贵的经验和参考。期待香橙派能够持续优化,推出更多创新性的产品,为开发者提供更优质的开发体验。

🌴附录
香橙派官网:http://www.orangepi.cn/index.html
Orange Pi OS:http://www.orangepi.cn/html/softWare/index.html

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 41
41 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)