
【InternLM 实战营第二期笔记1】书生·浦语大模型全链路开源体系+InternLM2技术报告
笔记目录
Intro
本文主要为笔记心得,具体分成两个部分:
- 基于书生·浦语大模型全链路开源开放体系-B站视频做的笔记
- 读InternLM2技术报告做的笔记
- InternLM2技术报告:https://arxiv.org/pdf/2403.17297.pdf
书生·浦语大模型全链路开源开放体系
现在是从专用模型到通用大模型的时代,通往AGI之路!
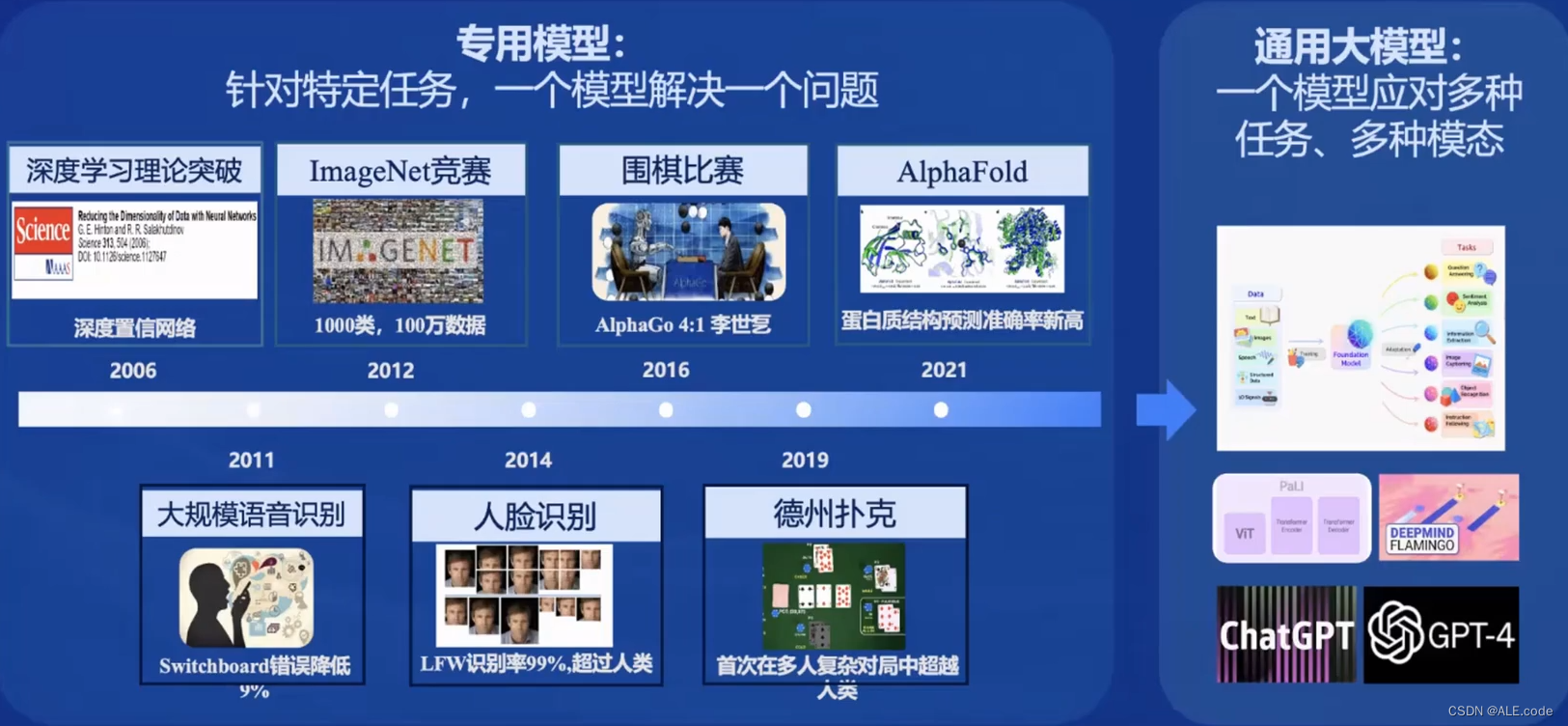
开源历程以及InternLM2
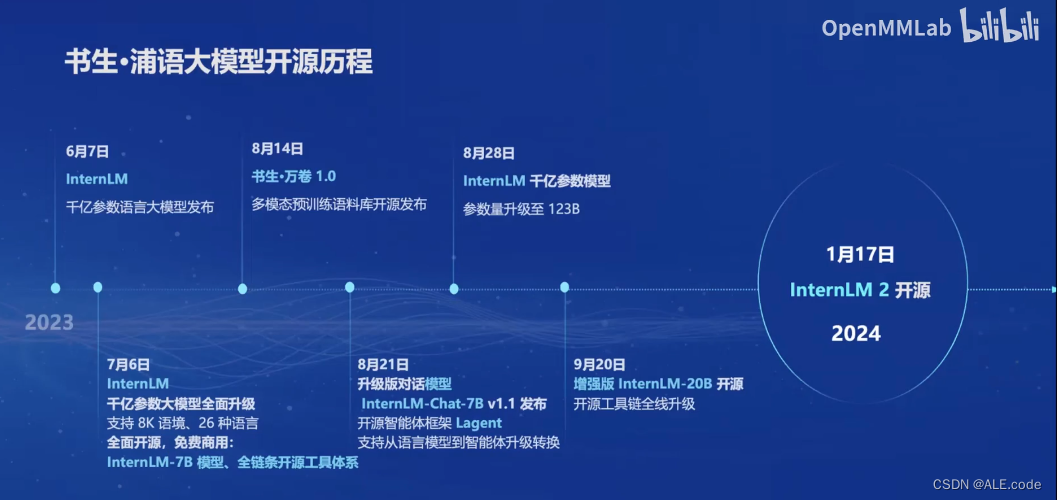
InternLM2(更具体的技术报告,在下面一个版块哟):
- 7b 和 20b
- 三个版本:internlm2,internlm2-base(大部分应用中考虑的优秀基座),internlm2-chat
- InternLM2的数学计算能力已经很强了,在此基础上,再配合代码解释器,可以取得更上一层楼的效果

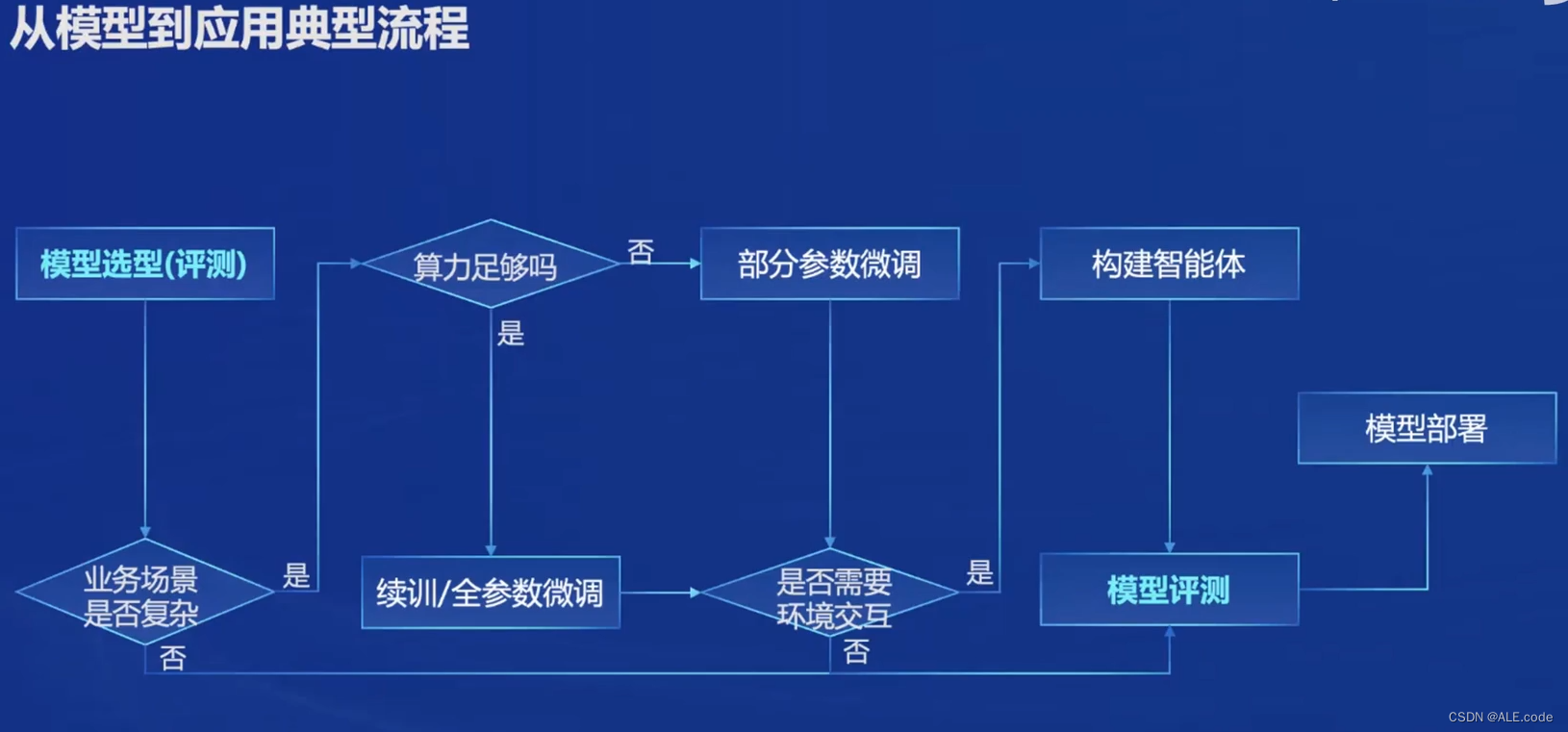
模型到应用的流程
这个流程提供了非常清晰的guideline,主要分成以下几个Steps:
- 根据业务场景和需求进行可以去榜单上面进行模型的选型。
- 如果业务场景复杂--finetune--算力是否足够--如果足够的话--做全参数微调 【不足够的话,可以使用部分参数微调,比如:LoRA(部分参数微调:固定模型的绝大部分参数,然后通过放开或者引入少量的参数,降低tuning的成本)】
- 是否需要环境交互--即是否有一些外部的API需要调用
开源开放体系

数据
数据,来源OpenData,这个网站OpenDataLab 引领AI大模型时代的开放数据平台有很多数据集可以直接下载(还不戳!)
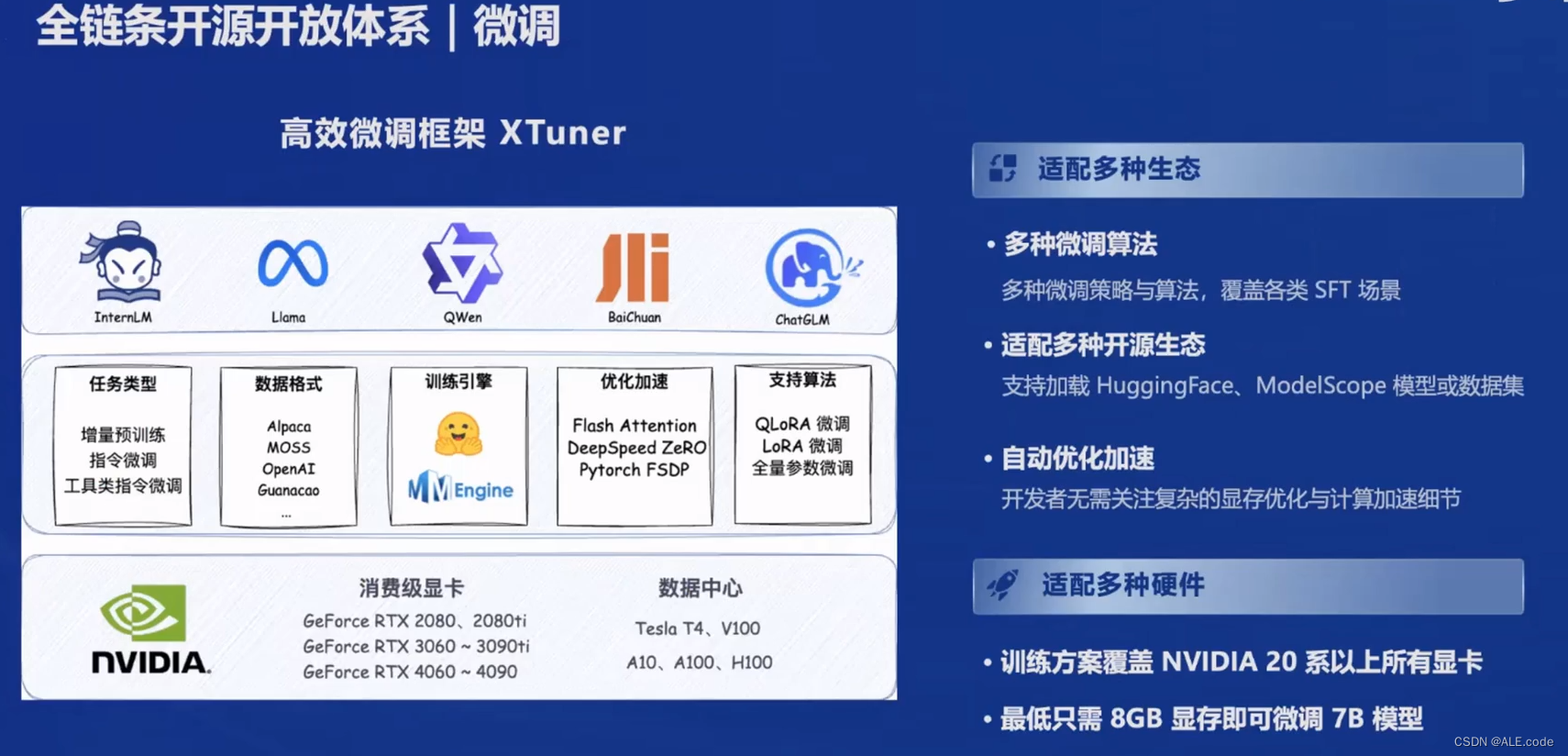
Finetuing
微调 XTuner,感觉这个框架挺好的👍🏻
模型评测
- 评测 CompassKit (OpenCompass这个评测可以可以,这个是链接:OpenCompass)

Agent框架
- 智能体框架👍🏻 InternLM/lagent: A lightweight framework for building LLM-based agents (github.com)

如果要开发智能体,推荐👇🏻这个工具箱(做了智能体和不同框架的解耦还挺好的)!
Link:GitHub - InternLM/agentlego: Enhance LLM agents with versatile tool APIs
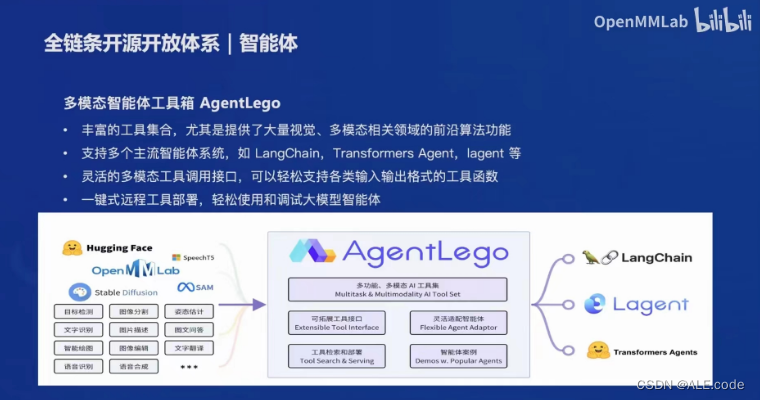
关于每个部分可以在InternLM,下面这个链接中的Tool Chain具体查看

InternLM2 技术报告
arXiv link: https://arxiv.org/abs/2403.17297
这篇技术报告将InternLM2总结的非常详尽,这个为目录(可以根据下面目录直接跳转至感兴趣的内容)
目录


技术报告 Section4 Alignment
在本笔记中,由于比较感兴趣 4 Alignment部分,所以在这里做一个小总结:
Alignment一般有两个阶段
- Supervised fine-tuning(SFT) and reinforcement learning from human feedback (RLHF).
Phase 1 : SFT
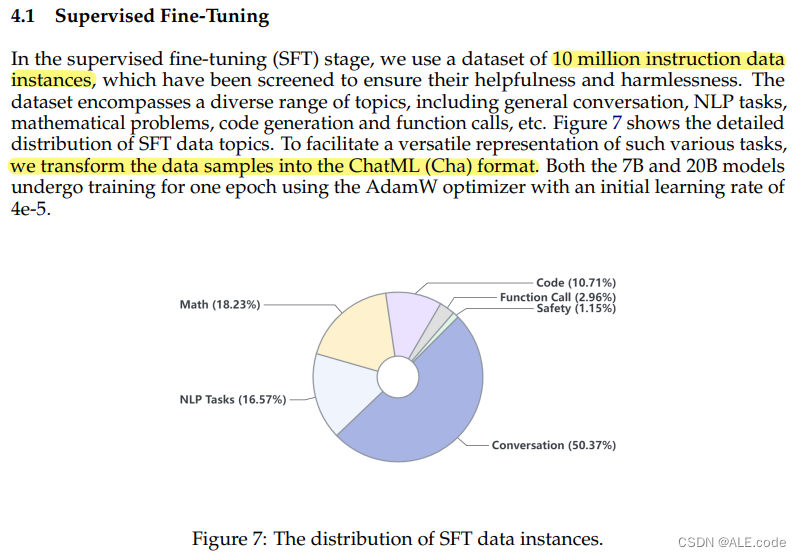
During SFT, we fine-tunethe model to follow diverse human instructions by high-quality instruction data.
ChatML format refers to:
azure-docs/articles/ai-services/openai/includes/chat-markup-language.md at main · MicrosoftDocs/azure-docs · GitHubOpen source documentation of Microsoft Azure. Contribute to MicrosoftDocs/azure-docs development by creating an account on GitHub.
https://github.com/MicrosoftDocs/azure-docs/blob/main/articles/ai-services/openai/includes/chat-markup-language.md可以结合上面Azure-docs来transform the data samples format.
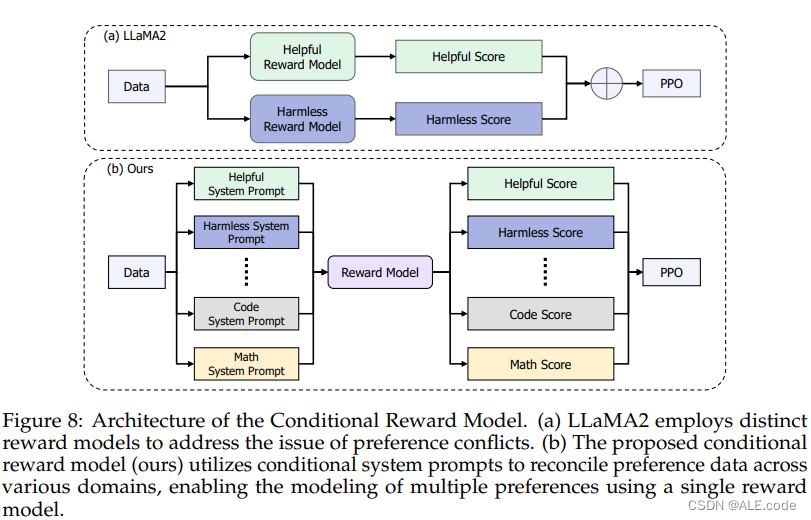
Phase 2 : COOL RLHF
Then we propose COnditionalOnLine RLHF, which applies a novel conditional reward model that can reconcile different kinds of human preferences (e.g., multi-step reasoningaccuracy, helpfulness, harmlessness), and conducts three-round online RLHF to reduce reward hacking.
Training Details Highlight:
- Initialization of the reward models using the SFT model weights
modify the output layer to a one-dimensional linear mapping layer.
- A special token is appened to each sequence's end, with its output value used as the reward score.


RL alignment phase-PPO

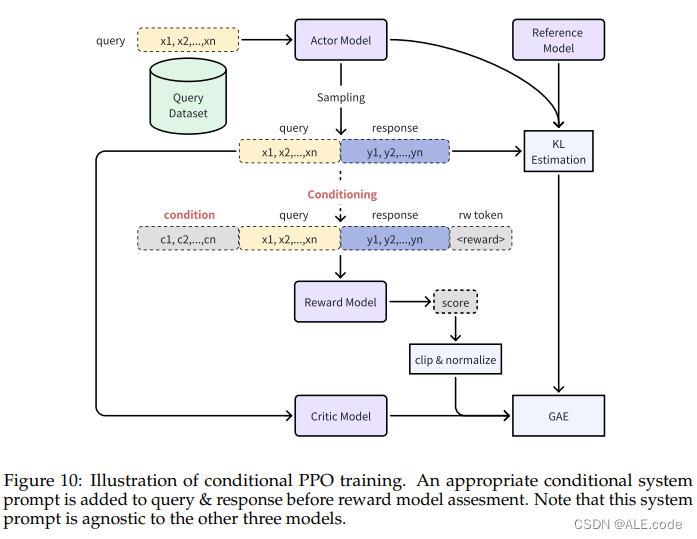
- 训练的时候: reference model and reward model are frozen,只训 actor model and critic model.
- Four models are of the same size.
- Initialization of the reference model and the actor model from the SFT model weights.
- The critic model is initialized from the reward model (excluding the linear head) and undergoes a 50-iteration pre-training phase, during which the actor model is frozen.
这篇知乎关于InternLM2的预训练数据部分(分成文本数据、代码数据、超长上下文数据)总结得还挺全面的,可以参考:【InternLM 实战营第二期笔记01】书生·浦语大模型全链路开源体系+InternLM2技术报告 - 知乎 (zhihu.com)
其他资料
往期课程
实战营第一期课程
实战营第二期课程目录
GitHub:InternLM/Tutorial at camp2 (github.com)https://github.com/InternLM/Tutorial/tree/camp2


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)