
ICCV 2023 | DAT:利用双重聚合的Transformer进行图像超分
论文:https://arxiv.org/pdf/2308.03364.pdf代码:https://github.com/zhengchen1999/DATTransformer最近在低级视觉任务中获得了相当大的普及,包括图像超分辨率(SR)。这些网络利用自注意力利用不同维度、空间或通道,并取得了令人印象深刻的性能。这启发我们在Transformer中结合这两个维度,以获得更强大的表示功能。在此基
Dual Aggregation Transformer for Image Super-Resolution
文章目录
2. Dual Aggregation Transformer Block
Spatial-Gate Feed-Forward Network
前言
论文:https://arxiv.org/pdf/2308.03364.pdf
代码:https://github.com/zhengchen1999/DAT
一、Introduction
Transformer最近在低级视觉任务中获得了相当大的普及,包括图像超分辨率(SR)。这些网络利用自注意力利用不同维度、空间或通道,并取得了令人印象深刻的性能。这启发我们在Transformer中结合这两个维度,以获得更强大的表示功能。
在此基础上,我们提出了一种新的变换模型——双聚合变换(Dual Aggregation Transformer, DAT),该模型以块间和块内的双重方式聚合了图像SR的空间和通道特征。具体来说,我们交替地在连续的Transformer块中应用空间和通道自注意。另一种策略使DAT能够捕获全局上下文并实现块间特征聚合。此外,我们提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)来实现块内特征聚合。AIM从相应的维度补充了两种自我注意机制。同时,SGFN在前馈网络中引入了额外的非线性空间信息。大量的实验表明,我们的DAT方法优于现有的方法。
二、Method
空间窗口自注意(Spatial window self-attention, SW-SA)能够对像素之间的细粒度空间关系进行建模。基于通道的自我注意(CW-SA)可以对特征映射之间的关系进行建模,从而利用全局图像信息。通常情况下,空间信息的提取和通道上下文的捕获对Transformer在图像SR中的性能至关重要。
基于上述发现,我们提出了图像SR的双聚合Transformer(Dual Aggregation Transformer, DAT),该Transformer通过块间和块内的双重方式聚合空间和通道特征,从而获得强大的表示能力。
具体来说,我们交替地在连续的双聚合Transformer块(DATBs)中应用空间窗口和通道方面的自注意。通过这种可选策略,我们的DAT可以捕获空间和通道上下文,并实现不同维度之间的块间特征聚合。此外,这两种自我注意机制相互补充。空间窗口自注意丰富了各特征图的空间表达,有助于对通道依赖关系进行建模。通道型自我注意为空间自我注意提供了特征间的全局信息,扩展了窗口注意的接受域。
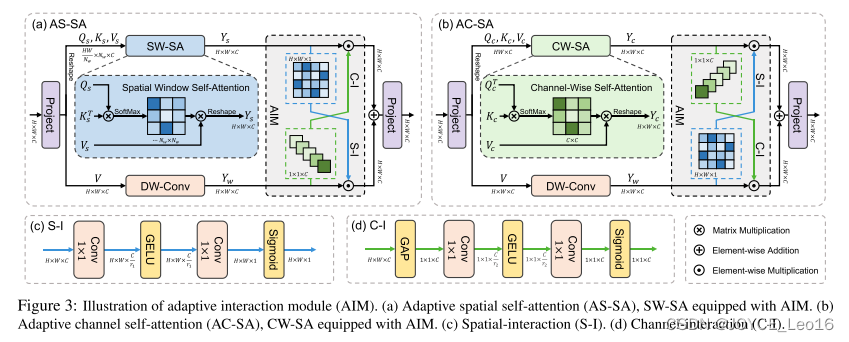
同时,由于自注意机制专注于全局信息的建模,我们将卷积与自注意并行结合,以补充Transformer的局部性。为了增强两个分支的融合,将空间信息和信道信息聚合在一个自注意模块中,我们提出了自适应交互模块(AIM)。它由空间交互(S-I)和通道交互(C-I)两种交互操作组成,在两个分支之间进行信息交换。通过S-I和C-I, AIM根据不同的自注意机制,从空间或通道维度对两个分支的特征映射进行自适应重加权。此外,基于空间窗口和通道层面的自我注意,设计了两种新的自我注意机制:自适应空间自我注意(AS-SA)和自适应通道自我注意(AC-SA)。
此外,Transformer模块的另一个组件,前馈网络(FFN),通过全连接层提取特征。它忽略了对空间信息的建模。此外,通道间的冗余信息阻碍了特征表示学习的进一步发展。为了解决这些问题,我们设计了空间门前馈网络(SGFN),在两个全连接的FFN层之间引入空间门模块。SG模块是一个简单的门控机制(深度卷积和元素乘法)。将SG的输入特性沿信道维数划分为卷积和乘性旁路两段。我们的SG模块可以为FFN补充额外的非线性空间信息,减少信道冗余。一般情况下,DAT可以基于AIM和SGFN实现块内特征聚合。
总的来说,通过以上三种设计,我们的DAT可以通过块间和块内的双重方式聚合空间信息和通道信息,实现强特征表达。

如图1所示,我们的DAT与最新的先进的SR方法相比获得了更好的视觉结果。我们的贡献有三方面:
(1)我们设计了一种新的图像SR模型——双聚合变压器(dual aggregation Transformer, DAT)。我们的DAT以块间和块内的双重方式聚合空间和通道特征,获得强大的表示能力。
(2)我们交替采用空间自注意和通道自注意,实现块间空间和通道特征聚合。此外,我们提出了AIM和SGFN实现块内特征聚合。
(3)我们进行了大量的实验,以证明我们的DAT优于最先进的方法,同时保持较低的复杂性和模型大小。
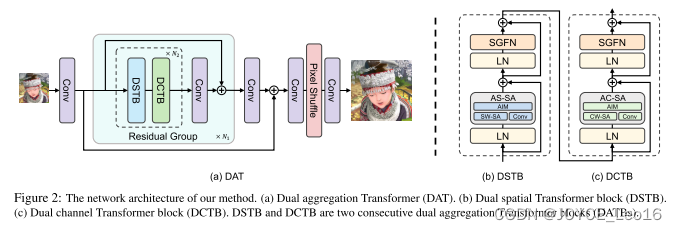
1. Network Architecture
所提出的DAT整体网络包括三个模块:浅特征提取、深特征提取和图像重建,如图2所示。
最初,给定一个低分辨率(LR)输入图像,我们使用卷积层对其进行处理,生成浅层特征
。符号H和W表示输入图像的高度和宽度,C表示特征通道的数量。
随后,将浅层特征FS在深度特征提取模块内进行处理,得到深度特征。模块被多个剩余组(RG)堆叠,总RG数为N1。同时,为了保证训练的稳定性,在模块中采用了残差策略。每个RG包含N2对双聚合Transformer块(DATB)。如图2所示,每个DATB对包含两个Transformer块,分别利用空间和通道自注意。在RG的最后引入卷积层,对Transformer块提取的特征进行细化。此外,对于每个RG,都使用剩余连接。
最后,我们通过重建模块重建高分辨率(HR)输出图像,其中
为输出图像的高度,
为图像宽度。在该模块中,对深度特征
进行像素洗牌方法上采样。并利用卷积层对上采样前后的特征进行聚合。
2. Dual Aggregation Transformer Block
双聚合Transformer块(DATB)是我们提出的方法的核心组件。DATB有两种:双空间Transformer块(DSTB)和双通道Transformer块(DCTB),如图2所示。DSTB和DCTB分别基于空间窗口自注意和通道自注意。通过交替组织DSTB和DCTB, DAT可以实现空间维和信道维之间的块间特征聚合。此外,提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)实现块内特征聚合。
-
Spatial Window Self-Attention
空间窗口自注意(SW-SA)计算窗口内的注意。如图3(a)所示,给定输入,我们通过线性投影生成query、key和value矩阵(分别记为Q、K和V),其中所有矩阵都在
空间中。
-
Channel-Wise Self-Attention
通道自注意(CW-SA)中的自注意机制是沿着通道维度进行的。在之前的作品之后,我们将渠道划分为heads,并分别对每个heads进行注意。如图3(b)所示,给定输入X,我们应用线性投影生成查询矩阵、键矩阵和值矩阵,并将它们重塑为大小为。
-
Adaptive Interaction Module
由于自注意的重点是捕获全局特性,因此我们加入了一个与自注意模块并行的卷积分支,以将局部性引入Transformer。然而,简单地添加卷积分支并不能有效地耦合全局和局部特征。此外,尽管SW-SA和CW-SA交替执行可以同时捕获空间和通道特征,但在单一的自我注意中仍然不能有效地利用不同维度的信息。
为了克服这些问题,我们提出了自适应交互模块(AIM),其作用于两个支路之间,如图3所示。该算法根据自注意机制的类型,从空间维度或通道维度对两个分支的特征进行自适应加权。因此,这两个分支特征可以更好地融合。同时,空间信息和通道信息可以聚合在一个单一的注意模块中。在此基础上,我们设计了两种新的自我注意机制,即自适应空间自我注意(AS-SA)和自适应通道自我注意(AC-SA)。
-
Spatial-Gate Feed-Forward Network
前馈网络(FFN)具有非线性激活和两个线性投影层提取特征。然而,它忽略了对空间信息的建模。此外,通道中的冗余信息阻碍了特征的表达能力。为了克服上述局限性,我们提出了空间门前馈网络(spatial-gate前馈网络,SGFN),将空间门(spatial-gate, SG)引入到FFN中。如图4所示,我们的SG模块是一个简单的门机制,由深度卷积和元素乘法组成。在通道维度上,我们将特征图分为卷积旁路和乘法旁路两部分。总的来说,给定输入, SGFN计算为:
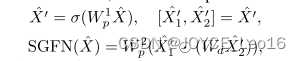
其中w1p和w2p表示线性投影,σ表示GELU函数,Wd是深度卷积的可学习参数。Xˆ' 1和Xˆ' 2都在RH×W×{C '/ 2}空间中,其中C '表示SGFN中的隐藏维数。与FFN相比,我们的SGFN能够捕获非线性空间信息,减轻全连通层的信道冗余。此外,与以往的工作不同,我们的SG模块利用深度卷积来保持计算效率。
-
Dual Aggregation Transformer Block
我们的双聚合变压器块(DATB)配备了自适应自注意(A-SA)和空间门前馈网络(SGFN)。给定第l块的输入,此块定义为:
![]()
其中为输出特征,LN(·)为LayerNorm层。由于A-SA包括AS-SA和AC-SA,因此DATB有两种类型,即双空间变压器块(DSTB)和双通道变压器块(DCTB)。DSTB采用AS-SA, DCTB采用AC-SA。
3. Dual Feature Aggregation
我们的DAT能够通过块间和块内的双重方式聚合空间和通道特征,获得强大的特征表示。
-
Inter-block Aggregation(块间聚合)
DAT交替采用DSTB和DCTB来捕获两个维度的特征,并利用二者的互补优势。具体来说,DSTB模拟了长程空间背景,增强了每个特征图的空间表达。同时,DCTB可以更好地构建通道依赖关系。DCTB模拟全局信道上下文,进而帮助DSTB捕捉空间特征,并扩大接收域。因此,空间和通道信息在连续的Transformer块之间流动,从而可以聚合。
-
Intra-block Aggregation(块内聚合)
AIM可以用通道知识补充空间窗口的自我注意,从空间维度上增强通道的自我注意。此外,SGFN能够引入额外的非线性空间信息到只模拟信道关系的FFN中。因此,DAT可以在每个Transformer块中聚合空间和通道特性。
三、Experiments
我们将DAT- s模型和DAT模型与目前的11种图像SR方法(EDSR、RCAN、SAN、RFANet、HAN、CSNLN、NLSA、ELAN、DFSA、SwinIR和CAT-A)进行了比较。与之前的研究一致,我们在测试过程中采用了自集成策略,用符号“+”表示。表2为定量比较,图6为视觉比较。


四、Conclusion
本文提出了一种新的图像SR模型——双聚合Transformer(DAT)。该模型以块间和块内的双重方式聚合空间和通道特征,以增强图像SR的表达能力。
具体来说,连续的Transformer块交替地应用空间窗口和通道自注意。通过这种策略,DAT可以对全局依赖关系进行建模,实现空间维度和通道维度之间的块间特征聚合。此外,我们提出了自适应交互模块(AIM)和空间门前馈网络(SGFN)来增强每个块,实现两个维度之间的块内特征聚合。AIM从相应的维度增强了两种自注意机制的建模能力。同时SGFN用非线性空间信息补充前馈网络。大量实验表明,DAT方法优于以往的方法。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)