
VIMA: General Robot Manipulation with Multimodal Prompts
·
Paper name
VIMA: General Robot Manipulation with Multimodal Prompts
Paper Reading Note
URL: https://arxiv.org/pdf/2210.03094.pdf
Project URL: https://vimalabs.github.io/
ICLR review URL: https://openreview.net/forum?id=hzjQWjPC04A
TL;DR
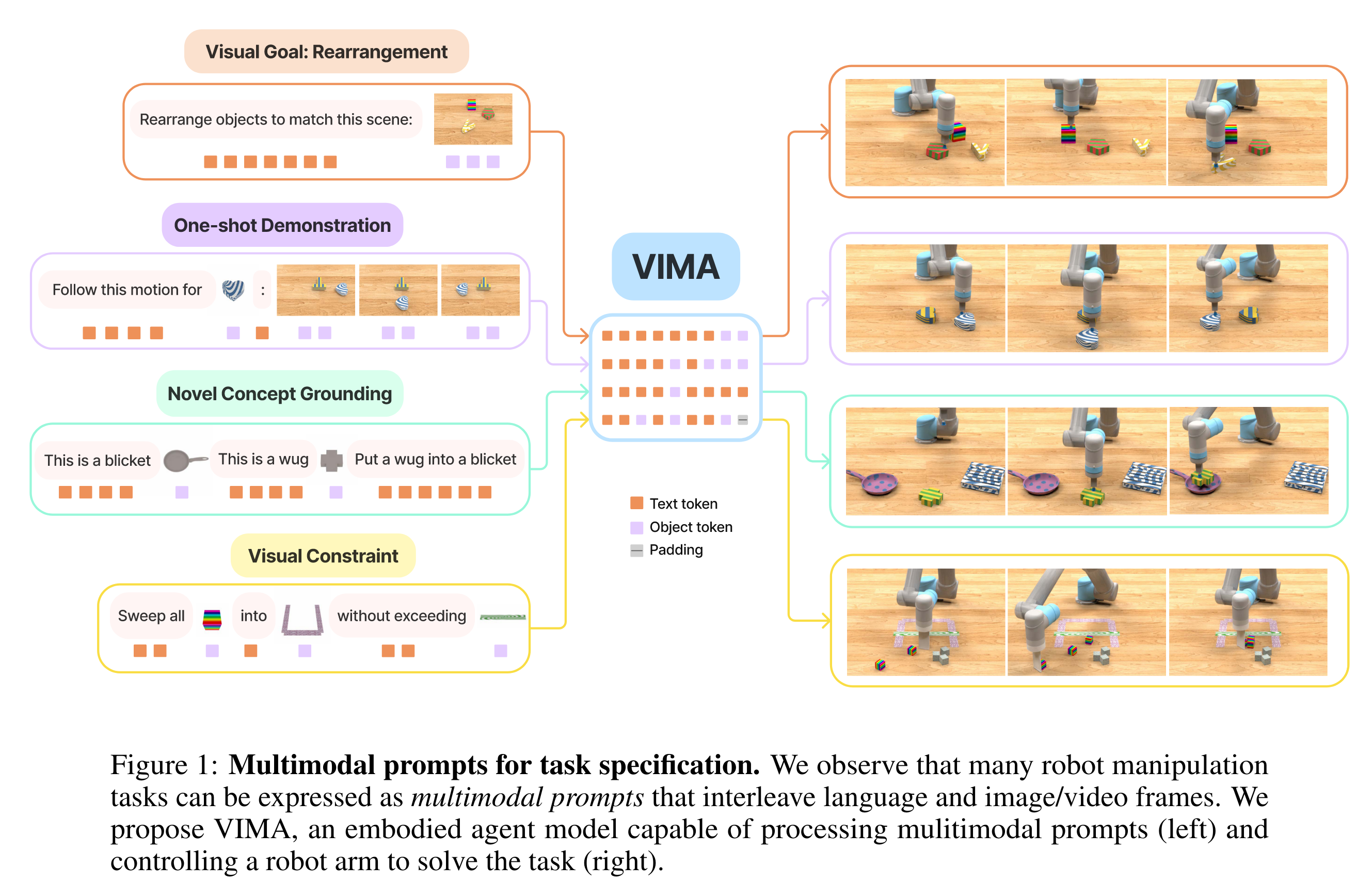
- ICLR 2023 在投论文,斯坦福和 NVIDIA 的工作。允许多模态的 prompts (比如文字+图片/视频),交织文本和视觉 tokens 来进行机器人操作任务,另外提出了一个仿真数据集(VIMA-BENCH),所有实验都在该仿真数据集中进行
Introduction
背景
- 基于提示的学习已经成为自然语言处理中的一种成功范例,其中单个通用语言模型可以被指示执行输入提示所指定的任何任务
- 然而,机器人技术中的任务规范有多种形式,比如模仿一次性演示,遵循语言指令,以及达到视觉目标。它们通常被认为是不同的任务,由专门的模型来处理
- 机器人如果能接受多模态的指令能极大降低交互难度:
- 设想一个负责家务的个人机器人,我们可以通过简单的自然语言指令让机器人给我们送一杯水,如果我们需要更多的特异性,我们可以指示机器人“带给我<杯子的图像>”
- 对于需要新技能的任务,机器人应该能够更好地从一些视频演示中学习任务应该如果进行
- 需要与不熟悉的物体进行交互的任务可以通过一些图像示例来解释,为新概念奠定基础
- 为了确保安全部署,可以进一步指定视觉约束,如“不进入 room”
- 本文工作表明可以用多模态提示,交织文本和视觉标记来表达广泛的机器人操作任务
本文方案
- 本文设计了一个基于 transformer 的通用机器人 agent: VIMA,VIMA 直接接受多模态提示,并自回归输出电机动作来控制机器人
- 为了训练和评估VIMA,开发了一个新的模拟基准,其中包含数千个带有多模态提示的程序生成桌面任务,600K+ 专家轨迹用于模仿学习,以及四个级别的评估协议用于系统泛化性测试
- VIMA 在模型容量和数据大小方面都具有很强的可伸缩性
- 在相同的训练数据下,它在最难的 zero-shot generalization 设置中优于先前的 SOTA 方法,任务成功率高达 2.9 倍。在训练数据减少 10 倍的情况下,VIMA 的性能仍然比顶级竞争方法好 2.7 倍
Dataset/Algorithm/Model/Experiment Detail
实现方式

- 不同的机器人可以基于多模态的 prompts 来进行操控,输入的模态可以包括
- 自然语言
- 自然语言 + 图片
- 自然语言 + 视频序列
多模态 prompt 任务规范
- Simple object manipulation:put into
- Visual goal reaching:操作对象以达到目标配置,比如 rearrangement
- Novel concept grounding:提示符包含不熟悉的单词,如“dax”和“blicket”,它们通过提示图像解释,然后立即在指令中使用
- One-shot video imitation:观看视频演示,并学习为特定物体重现相同的运动轨迹
- Visual constraint satisfaction:机器人必须小心操作物体,避免违反(安全)约束
- Visual reasoning:需要推理技能的任务,如外观匹配“将与具有相同纹理的所有对象移动到容器中”,视觉记忆 “将放入容器中,然后恢复到原始位置” 等
评测协议 VIMA-BENCH (BENCHMARK FOR MULTIMODAL ROBOT LEARNING)
- 通过 Ravens robot simulator 构建数据集
- 17 个具有多模态提示模板的代表性元任务
- 每个元任务都属于上面提到的 6 种任务规范方法中的一个或多个。VIMA-BENCH 可以通过脚本
化的 oracle 代理生成大量的模仿学习数据
- 每个元任务都属于上面提到的 6 种任务规范方法中的一个或多个。VIMA-BENCH 可以通过脚本
- 数据集:
- 利用预编程的 oracles 来生成一个大型的离线专家轨迹数据集,用于模仿学习
- 数据集包括每个元任务50K个轨迹,总共650k个成功轨迹
- 17 个任务中有 4 个用于测试 zero-shot generalization
- 以下 4 个层次难度的评估协议

VIMA: VISUOMOTOR ATTENTION MODEL

- 具有以对象为中心设计的极简多任务编码器-解码器架构
- 通过一个冻结的预训练语言模型对提示进行编码,并通过交叉注意层对编码提示进行解码
- Tokenization
- 三种原始输入形式:text, image of a single object, image of a full tabletop scene (例如,对视频帧进行重排或模仿)
- text:使用 pre-trained T5 tokenizer 和 word embedding 获取 word tokens
- images of full scenes: Mask R-CNN 提取物体,基于一个 a bounding box encoder 和 ViT 获取 object tokens
- images of single objects:与 images of full scenes 基本一样,只是输入一个覆盖全图的 dummy bounding box
- 通过将生成的 token sequence 传递给 pre-trained T5 tokenizer 模型来产生提示编码。positional embedding 是可学习的和绝对的
- 三种原始输入形式:text, image of a single object, image of a full tabletop scene (例如,对视频帧进行重排或模仿)
- Robot Controller:机器人控制器(译码器)由提示序列P和轨迹历史序列H之间的一系列交叉注意层以提示序列P为条件,该设计优点:
- 加强与提示的联系
- 与原始提示充分交互
- 更好的计算效率
- 参考 Video Pretraining (VPT) 的工作,将预测的动作映射到机械臂的离散姿态
- Training:
- 遵循标准的行为克隆,通过最小化预测动作的 negative log-likelihood 来训练模型
- 为了使VIMA对检测不准确性和故障具有鲁棒性,我们通过随机注入假阳性检测输出来应用对象增强
实验结果
对比 baseline
- Gato:引入了一个仅解码器的模型,该模型通过使用观察和操作子序列提示模型来解决来自多个域的任务,其中任务是通过指定的。为了公平对比,这里直接给 VIMA 计算的 multimodal embedded prompt
- Flamingo:一个视觉语言模型,学习生成文本补全以响应多模态提示。它通过 percepver Resampler 模块将可变数量的提示图像嵌入到固定数量的标记中,并通过交叉注意对已编码的 prompts 进行语言解码。本文将 Flamingo 输出层替换为机器人动作头来支持决策
- Decision Transformer (DT):是最早将RL问题重新解释为 transformer 序列建模的作品之一。在视觉 RL 领域,如 Atari 游戏,DT 会根据期望的奖励值提示,并根据 RGB 观察嵌入自回归地输出动作。本文将 DT 的初始奖励提示替换为 VIMA 的多模式任务提示嵌入,并删除所有后续奖励 tokens
对比结果
- VIMA 小模型精度就能很高,对于数据增加能获得更大精度收益

- Progressive Generalization,在测试更难的数据时掉点更少

消融实验
- Ablation on visual tokenizers:Mask R-CNN 检测相比于 GT 掉点不多, ViT 相比于 Perceiver(Perceiver: General Perception with Iterative Attention,将图片中检测的不同数量的物体转换为固定数目的 tokens) 有较大涨点,而且越难的任务涨点幅度越大
- 重要的是将对象的可变 token 序列直接传递给机器人控制器,而不是向下采样到固定数量的 tokens

- 重要的是将对象的可变 token 序列直接传递给机器人控制器,而不是向下采样到固定数量的 tokens
- Prompt conditioning: 小模型下本文设计的 xattn 精度更高,大模型下基本一致。本文的猜想是,交叉注意有助于控制器在每个交互步骤中更好地专注于提示指令
- gpt-decoder: 将提示符P和交互历史记录H连接到一个大序列中,然后像 GPT 一样应用 decoder-only transformer 来预测 actions

- gpt-decoder: 将提示符P和交互历史记录H连接到一个大序列中,然后像 GPT 一样应用 decoder-only transformer 来预测 actions
Thoughts
- 看了下 ICLR 2023 的 review,基本认可在本文 setting 下的实验结果,但整体看评分并不高,主要有以下质疑点:
- Mask-RCNN 在新场景下不方便 finetune 怎么办?
- 作为机器人任务,只做拾取和放置任务太简单,而且还是仿真环境下做的,对象非常清晰
- 实验的场景和现实场景差异太大:例如,“novel councept grounding” 似乎只是在定义上加上一个标签。“one shot video imitiation” 似乎是对一个精确轨迹的精确再现——这是一个比通常所说的模仿学习要弱得多的定义
- 文章对多模态的优越性解释不到位。比如多模态的 prompts 如何来源?如果需要来源于人的语音指令,人却并不能在语音中插入图片和视频

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)