
如何用Python读取Amazon的Review数据
·
Amazon(http://jmcauley.ucsd.edu/data/amazon/)(https://nijianmo.github.io/amazon/index.html)数据集包含来自亚马逊的产品评论和元数据,其中包括1996年5月至2014年7月的1.428亿条评论。
如果我们需要用到Amazon的评论数据,那就要先下载好数据集

下载下来的数据集是json格式的,并且不能直接用python的json库读取,数据字段和格式示例为:
{"overall": 4.0, "verified": true, "reviewTime": "03 11, 2014", "reviewerID": "A240ORQ2LF9LUI", "asin": "0077613252", "style": {"Format:": " Loose Leaf"}, "reviewerName": "Michelle W", "reviewText": "The materials arrived early and were in excellent condition. However for the money spent they really should've come with a binder and not just loose leaf.", "summary": "Material Great", "unixReviewTime": 1394496000}
含义分别是:
"overall": 评论者对产品的评分,
"verified": true,
"reviewTime": 评论的日期,
"reviewerID": 评论者的ID,
"asin": 产品的ID,
"style": 产品的元数据(字典),
"reviewerName": 评论者的名称,
"reviewText": 评论的内容,
"summary": 评论内容的总结,
"unixReviewTime": 评论的时间戳(Unix),
为了方便读取评论数据,我写了一段代码供大家参考:
import pandas as pd
if __name__ == '__main__':
dataset = "All_Beauty" # 以All_Beauty数据集为例
fin = open(dataset +".json", 'r')
review_list = [] # 存储筛选出来的字段,如果数据量过大可以尝试用dict而不是list
for line in fin: # 顺序读取json文件的每一行
d = eval(line, {"true":True,"false":False,"null":None})
if d["overall"] == 5 and "reviewText" in d.keys(): # 筛选出评分为5的数据
review_list.append([d["reviewerID"], d["asin"], d["reviewText"]]) # 将评论者ID、商品ID和评论内容存储到list中
df = pd.DataFrame(review_list, columns =['user_id', 'item_id', 'review_text']) # 转换为dataframe
print(df[:10]) # 预览
# df.to_csv('All_Beauty.csv', index=False) # 存储
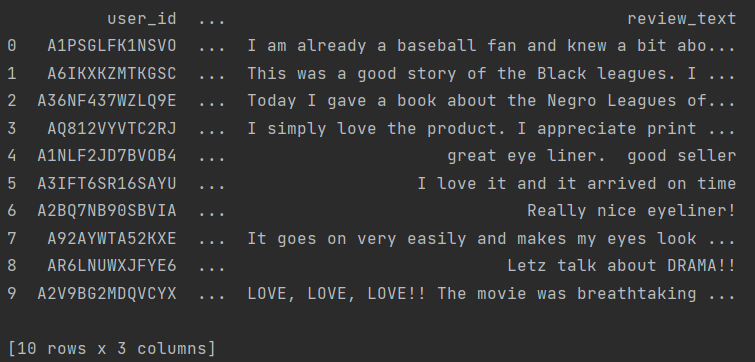
All_Beauty数据集大约7s可以处理完毕,预览效果如下:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)