
MySQL设计架构
·
MySQL常见版本
MySQL Community Server社区版本,开源免费,但不提供官方技术支持MySQL Enterprise Edition企业版本,需付费,可以试用30天MySQL Cluster集群版,开源免费。可将几个MySQL Server封装成一个ServerMySQL Cluster CGE高级集群版,需付费
数据库排名网站
http://db-engines.com/en/ranking
MySQL设计架构
- 共分为
4层:网络连接层、数据库服务层、存储引擎层、系统文件层
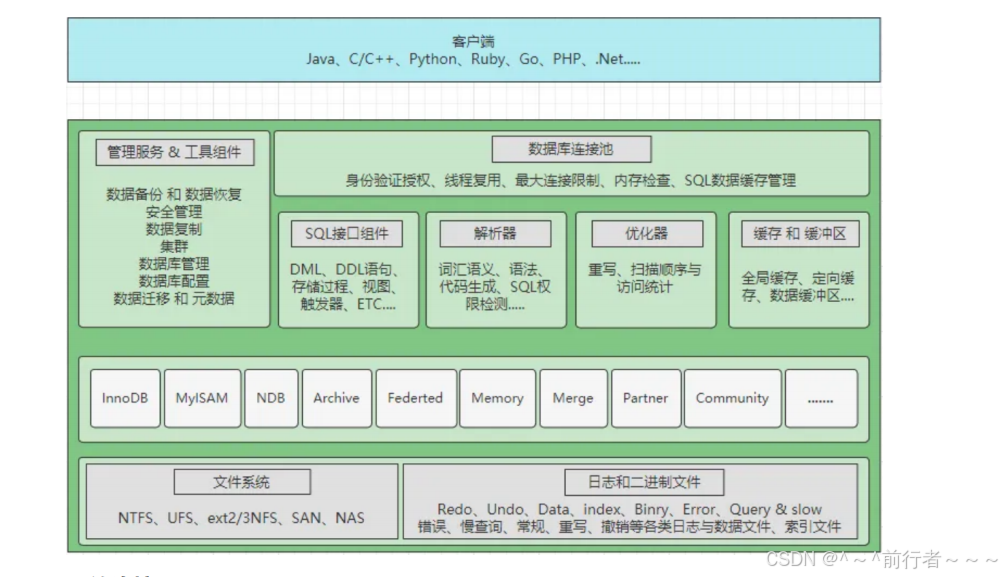
网络连接层

- 综述:
MySQL是一个单进程多线程架构的数据库,通过数据库连接池处理所有客户端接入的工作 如何连接:- 当输入命令
mysql -h 127.0.0.1 -uroot -p123456后MySQL服务端与客户端会基于TCP/IP协议栈建立tcp连接,这之间会检查用户名、密码、权限等 - 数据库连接
建立成功后,MySQL服务端与客户端之间会采用半双工的通讯机制工作 - 同时
MySQL会安排一条线程维护当前客户端的连接,这条线程也会时刻关注着当前连接在干什么工作,可以通过show processlist命令查询所有正在运行的线程
- 当输入命令
#查看正在运行的线程
mysql> show processlist;
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 66608 | Waiting on empty queue | NULL |
| 8 | root | localhost:65030 | NULL | Query | 0 | init | show processlist |
+----+-----------------+-----------------+------+---------+-------+------------------------+------------------+
2 rows in set, 1 warning (0.00 sec)
event_scheduler:事件调度器账户
数据库连接池- 产生原因:所有的
客户端连接都需要一条线程去维护,而线程资源无论在哪里都属于宝贵资源,因此不可能无限量创建,所以这里的连接池就相当于Tomcat中的线程池,主要是为了复用线程、管理线程以及限制最大连接数的 连接池的最大线程数可以通过参数max-connections来控制,如果到来的客户端连接超出该值时,新到来的连接都会被拒绝,关于最大连接数的一些命令主要有两条:show variables like '%max_connections%';查询目前数据库的最大连接数set GLOBAL max_connections = 200;修改数据库的最大连接数为指定值
- 对于
不同的机器配置,可以适当的调整连接池的最大连接数大小,以此可以在一定程度上提升数据库的性能。除了可以查询最大连接数外,MySQL本身还会对客户端的连接数进行统计,对于这点可以通过命令show status like "Threads%";查询
- 产生原因:所有的
#查看线程的状态
mysql> show status like "Threads%";
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 0 |
| Threads_connected | 1 |
| Threads_created | 1 |
| Threads_running | 2 |
+-------------------+-------+
4 rows in set (0.00 sec)
其中各个字段的释义如下:
Threads_cached:目前空闲的数据库连接数Threads_connected:当前数据库存活的数据库连接数Threads_created:MySQL-Server运行至今,累计创建的连接数Threads_running:目前正在执行的数据库连接数
数据库服务层
MySQL大多数核心功能都位于这一层,包括客户端SQL请求解析、语义分析、查询优化、缓存以及所有的内置函数(例如:日期、时间、统计、加密函数...),所有跨引擎的功能都在这一层实现,譬如存储过程、触发器和视图等一系列服务。
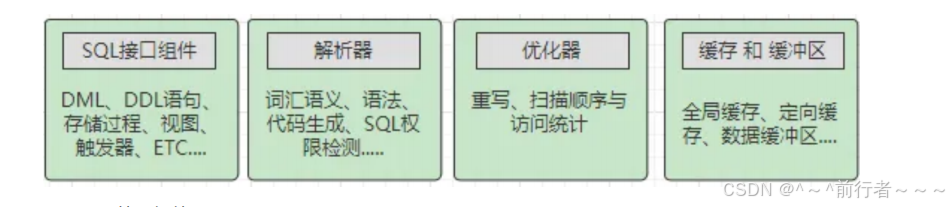
SQL接口组件
作用:接收客户端的SQL命令,比如DML、DDL语句以及存储过程、触发器等,当收到SQL语句时,SQL接口会将其分发给其他组件,然后等待接收执行结果的返回,最后会将其返回给客户端- 简单来说,也就是
SQL接口会作为客户端连接传递SQL语句时的入口,并且作为数据库返回数据时的出口 SQL语句分为五大类:DML:数据库操作语句,比如update、delete、insert等都属于这个分类DDL:数据库定义语句,比如create、alter、drop等都属于这个分类DQL:数据库查询语句,比如最常见的select就属于这个分类DCL:数据库控制语句,比如grant、revoke控制权限的语句都属于这个分类TCL:事务控制语句,例如commit、rollback、setpoint等语句属于这个分类
解析器
- 主要作用是
词法分析、语义分析、语法树生成等等,即验证SQL语句是否正确,以及将SQL语句解析成MySQL能看懂的机器码指令
优化器
- 作用是
生成执行计划,比如选择最合适的索引,选择最合适的join方式等,最终会选择出一套最优的执行计划,维护当前连接的线程会负责根据计划去执行SQL
缓存和缓冲区
读取缓存- 一般指
select语句的数据缓存,当然也会包含一些权限缓存、引擎缓存等信息,但主要还是select语句的数据缓存 作用:MySQL会对于一些经常执行查询的SQL语句,将其结果保存在Cache缓存中,因为这些SQL语句经常执行,因此如果下次再出现相同的SQL时,能从内存缓存中直接命中数据,自然会比走磁盘效率更高注意:高版本的MySQL中,移除了查询缓存区,毕竟命中率不高,而且查询缓存这一步还要带来额外开销,同时一般程序都会使用Redis做一次缓存,因此结合多方面的原因就移除了查询缓存的设计
- 一般指
写入缓冲区缓冲区的设计主要是:为了通过内存的速度来弥补磁盘速度较慢对数据库造成的性能影响数据库进行写操作时,都会先从缓冲区中查询是否有要操作的页,如果有,则直接对内存中的数据页进行操作(例如修改、删除等),对缓冲区中的数据操作完成后,会直接给客户端返回成功的信息,然后MySQL会在后台利用一种名为Checkpoint的机制,将内存中更新的数据写到磁盘MySQL在设计时,通过缓冲区能减少大量的磁盘IO,从而进一步提高数据库整体性能
存储引擎层

存储引擎也可以理解成MySQL最重要的一层,在前面的服务层中,聚集了MySQL所有的核心逻辑操作,而引擎层则负责具体的数据操作以及执行工作Oracle、SQLServer等商用数据库只有一个存储引擎,因为它们是闭源的,所以仅有官方自己提供的一种引擎。而MySQL则因为其开源特性,所以存在很多很多款不同的存储引擎实现,MySQL为了能够正常搭载不同的存储引擎运行,因此引擎层是被设计成可拔插式的,也就是可以根据业务特性,为自己的数据库选择不同的存储引擎MySQL目前有非常多的存储引擎可选择,其中最为常用的则是InnoDB与MyISAM引擎,可以通过show variables like '%storage_engine%'; 命令来查看当前所使用的引擎。
#查看存储引擎
mysql> show variables like "%storage_engine%";
+---------------------------------+-----------+
| Variable_name | Value |
+---------------------------------+-----------+
| default_storage_engine | InnoDB |
| default_tmp_storage_engine | InnoDB |
| disabled_storage_engines | |
| internal_tmp_mem_storage_engine | TempTable |
+---------------------------------+-----------+
4 rows in set, 1 warning (0.01 sec)
存储引擎是MySQL数据库中与磁盘文件打交道的子系统,不同的引擎底层访问文件的机制也存在些许细微差异,引擎也不仅仅只负责数据的管理,也会负责库表管理、索引管理等,MySQL中所有与磁盘打交道的工作,最终都会交给存储引擎来完成
文件系统层

- 这一层主要分为
两个板块:①日志板块。②数据板块。该层是MySQL数据库的基础,本质上就是基于机器物理磁盘的一个文件系统,其中包含了配置文件、库表结构文件、数据文件、索引文件、日志文件等各类MySQL运行时所需的文件,这一层的功能比较简单,也就是与上层的存储引擎做交互,负责数据的最终存储与持久化工作 日志板块:使用七种常用的日志类型binlog二进制日志,主要记录MySQL数据库的所有写操作(增删改)redo-log重做/重写日志,MySQL崩溃时,对于未落盘的操作会记录在这里面,用于重启时重新落盘(InnoDB专有的)undo-logs撤销/回滚日志:记录事务开始前(修改数据)的备份,用于回滚事务error-log错误日志:记录MySQL启动、运行、停止时的错误信息`general-log常规日志,主要记录MySQL收到的每一个查询或SQL命令slow-log慢查询日志,主要记录执行时间较长的SQL语句relay-log:中继日志,主要用于主从复制做数据拷贝
数据板块:MySQL的所有数据最终都会落盘(写入到磁盘),而不同的数据在磁盘空间中,存储的格式也并不相同,常见的数据文件类型如下db.opt文件:主要记录当前数据库使用的字符集和验证规则等信息.frm文件:存储表结构的元数据信息文件,每张表都会有一个这样的文件.MYD文件:用于存储表中所有数据的文件(MyISAM引擎独有的).MYI文件:用于存储表中索引信息的文件(MyISAM引擎独有的).ibd文件:用于存储表数据和索引信息的文件(InnoDB引擎独有的).ibdata文件:用于存储共享表空间的数据和索引的文件(InnoDB引擎独有).ibdata1文件:这个主要是用于存储MySQL系统(自带)表数据及结构的文件.ib_logfile0/.ib_logfile1文件:用于故障数据恢复时的日志文件.cnf/.ini:MySQL的配置文件,Windows下是.ini,其他系统大多为.cnf
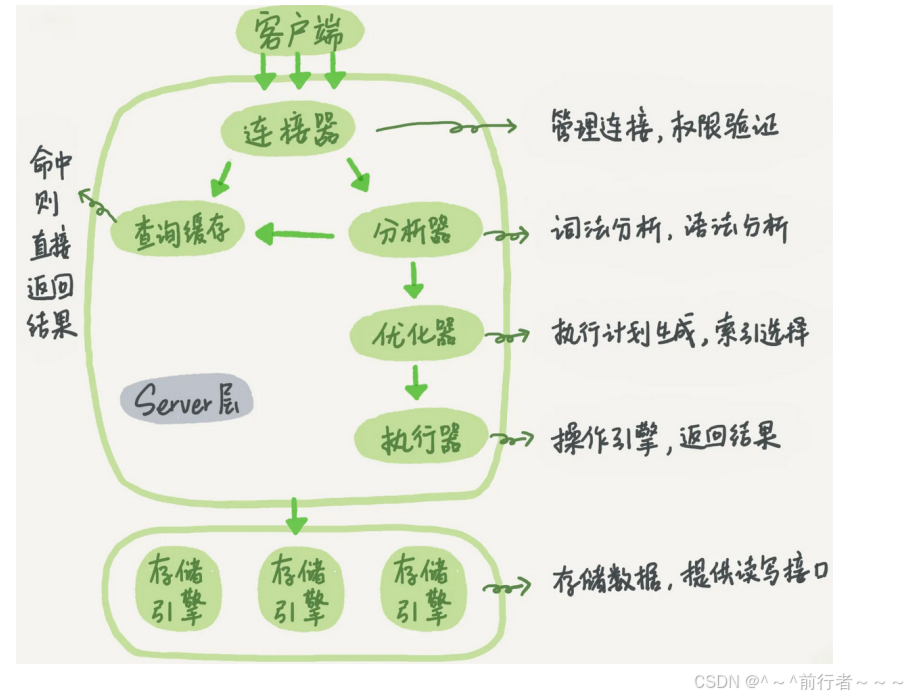
架构小结
查看最大连接数
mysql> show variables like "%max_connections%";
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| max_connections | 151 |
| mysqlx_max_connections | 100 |
+------------------------+-------+
2 rows in set, 1 warning (0.00 sec)
查询缓存配置情况
mysql> show variables like "%query_cache%";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | NO |
+------------------+-------+
1 row in set, 1 warning (0.00 sec)
一条SQL语句执行流程
连接层
(1)提供连接协议:TCP/IP 、SOCKET
(2)提供验证:用户、密码,IP,SOCKET
(3)提供专用连接线程:接收用户SQL,返回结果
通过以下语句可以查看到连接线程基本情况
mysql> show processlist;
SQL层
(1)接收上层传送的SQL语句
(2)语法验证模块:验证语句语法,是否满足SQL_MODE
(3)语义检查:判断SQL语句的类型
DDL :数据定义语言
DCL :数据控制语言
DML :数据操作语言
DQL: 数据查询语言
...
(4)权限检查:用户对库表有没有权限
(5)解析器:对语句执行前,进行预处理,生成解析树(执行计划),说白了就是生成多种执行方案.
(6)优化器:根据解析器得出的多种执行计划,进行判断,选择最优的执行计划
代价模型:资源(CPU IO MEM)的耗损评估性能好坏
(7)执行器:根据最优执行计划,执行SQL语句,产生执行结果
执行结果:在磁盘的xxxx位置上
(8)提供查询缓存(默认是没开启的),会使用redis tair替代查询缓存功能
(9)提供日志记录(日志管理章节):binlog,默认是没开启的。
存储引擎层(类似于Linux中的文件系统)
负责根据SQL层执行的结果,从磁盘上拿数据。
将16进制的磁盘数据,交由SQL结构化化成表,
连接层的专用线程返回给用户。
一条 SQL 语句在 MySQL 中的执行流程通常包括以下步骤:
1. **客户端发送 SQL 查询**:
客户端通过网络连接发送 SQL 查询到 MySQL 服务器。
2. **连接建立**:
MySQL 服务器接收到客户端发送的 SQL 查询,并建立与客户端的连接。
3. **解析器解析 SQL 查询**:
MySQL 服务器中的解析器解析客户端发送的 SQL 查询,分析语法和语义,并将其转换为内部的执行计划。
4. **优化器优化执行计划**:
优化器对解析后的 SQL 查询进行优化,选择最佳的执行计划以提高执行效率。
5. **存储引擎执行查询**:
MySQL 服务器根据优化后的执行计划,调用相应的存储引擎执行查询操作。
6. **锁管理器处理并发访问**:
如果查询涉及到数据的读写操作,锁管理器负责处理并发访问,确保事务的隔离性和一致性。
7. **数据读取或修改**:
存储引擎根据执行计划从磁盘或缓存中读取数据,或者进行数据的修改操作。
8. **日志管理器记录事务日志**:
如果查询涉及到事务的修改操作,日志管理器负责记录事务日志,以实现事务的持久性和恢复能力。
9. **返回结果给客户端**:
存储引擎将查询结果返回给 MySQL 服务器,MySQL 服务器再将结果返回给客户端。
10. **连接关闭**:
客户端完成对查询结果的处理后,关闭与 MySQL 服务器的连接。
这是一条 SQL 查询在 MySQL 中的基本执行流程。在执行过程中,MySQL 会根据查询的具体情况进行优化和调整,以提高执行效率和性能。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)