
kube-Prometheus安装和使用完全教程
kube-Prometheus安装和使用完全教程
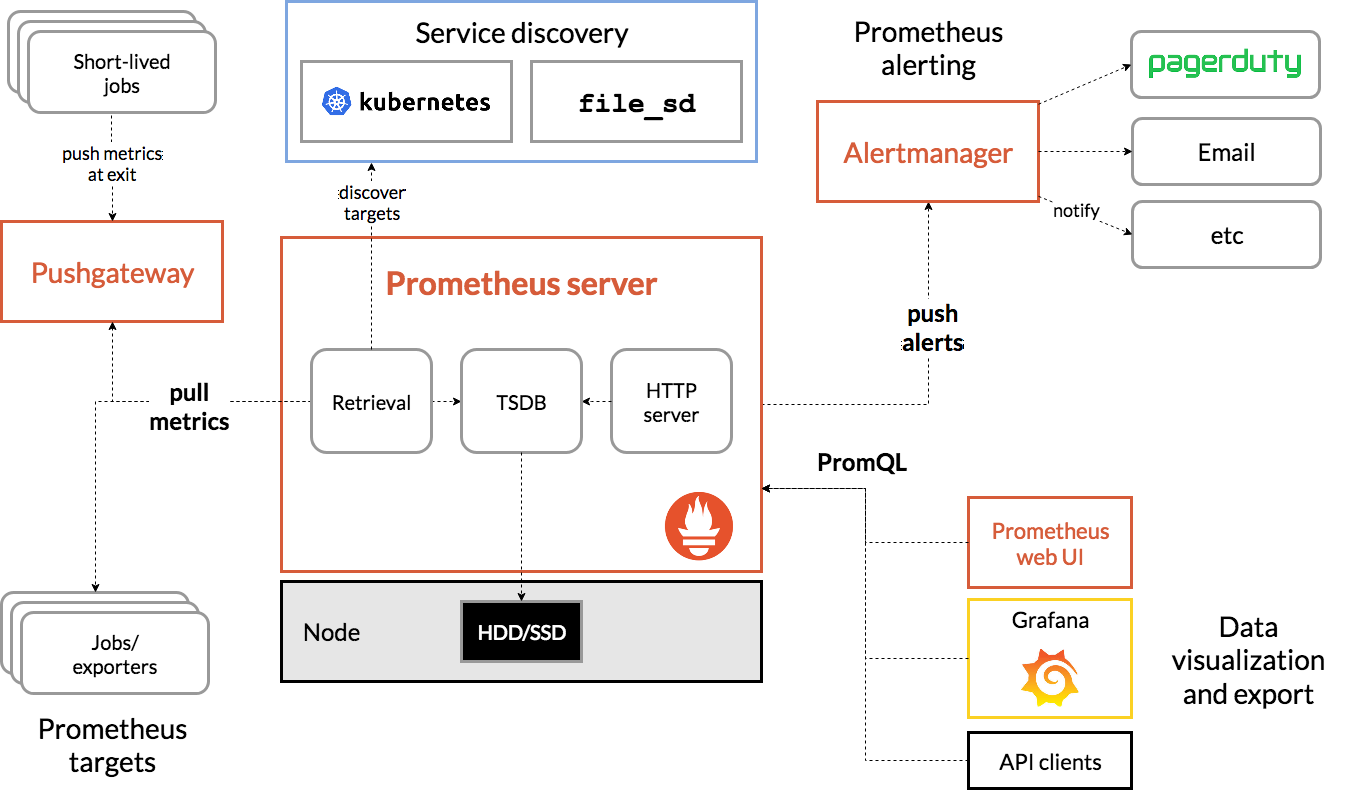
1.是什么
kube-Prometheus是一个全面集成的Kubernetes集群监控解决方案,它将核心的Prometheus组件、Grafana可视化面板以及Prometheus规则等资源精心编排并集成为一个易于部署和管理的整体。该项目通过GitHub仓库提供了详尽的Kubernetes清单文件、Grafana仪表板配置和Prometheus规则,辅以详细的文档和脚本,使得在Kubernetes集群中利用Prometheus进行端到端的监控变得异常便捷高效。更进一步,kube-Prometheus不仅引入了Prometheus Operator模式,还在此基础上进行了增强与拓展,因此可以将其理解为一个经过优化且充分利用operator机制的高级Prometheus部署方案。

2.为什么
使用Prometheus Operator的理由
- Operator模式的优势:Prometheus Operator采用了Operator模式,该模式致力于解决复杂有状态应用在Kubernetes环境中的管理和运维难题。通过Operator,能够自动化的创建、配置和管理Prometheus实例及其相关的服务发现(ServiceMonitor, PodMonitor等),从而极大地简化了操作流程,并确保了系统的稳定性和一致性。
- 对比传统Prometheus.yaml的服务发现方式:相较于传统的基于Prometheus配置文件(
Prometheus.yaml)的手动配置服务发现方式,kube-Prometheus借助于CRD(自定义资源定义)实现了动态服务发现机制。例如,ServiceMonitor和PodMonitor作为CRDs,可以通过标签选择器自动发现并监控符合特定条件的Kubernetes服务或Pod,大大提升了监控覆盖范围的灵活性和准确性。
使用kube-Prometheus的理由
- 一站式解决方案:kube-Prometheus提供了一个完整且兼容性强的环境,其中包含了Prometheus Operator所需的所有依赖关系,用户无需单独寻找和安装这些组件,降低了部署难度和出错概率。
- CRD和Operator管理模式:kube-Prometheus利用CRDs和Operator模式对监控组件进行全面的声明式管理,使整个监控系统架构可编程化,提高了资源配置和变更的效率,同时也更加贴合云原生应用的理念和实践。用户只需专注于编写和更新CRD资源对象,即可轻松实现对监控目标和服务的增删改查及扩缩容操作。
强力的社区支持
Prometheus项目在github截至2024/1/23 star 51.5k,Prometheus operator 8.5k,kube-Prometheus 6k,Prometheus是当前metrics的事实标准,Prometheus operator也是当前K8S operator生态中的标杆,kube-Prometheus作为Prometheus operator的子项目同样非常火热。
3.安装
K8S manifest获取
到github上下载
kube-prometheus/manifests at main · prometheus-operator/kube-prometheus · GitHub
首先根据官方支持矩阵和自己的K8S集群版本进行分支选择

切换选择合适自己集群的分支后下载zip包

进入manifest文件夹,执行
kubectl apply --server-side -f manifests/setup
主要是创建了monitoring命名空间和一些需要的CRD模板,通常会很快

kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f manifests/
然后进行kube-prometheus的安装
官方尚未提供helm模板,所以只能是这样的安装方式了,等待一段时间之后正常是可以正常启动的,国内可能存在一些镜像不好拉的状况而导致部分组件启动失败,建议读者自行解决网络问题
4.提权
默认的RBAC权限,即这一部分,请读者自行查阅

仅对部分(默认是monitoring,default,kube-system)命名空间可以使用servicemonitor等CRD,对一些operator和helm安装的应用会创建exporter或者servicemonitor不友好,可能提示权限错误或者,笔者直接给Prometheus给到最高的权限
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.44.0
name: prometheus-k8s-cluster-wide
rules:
- apiGroups: [""]
resources:
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.44.0
name: prometheus-k8s-cluster-wide-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus-k8s-cluster-wide
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: monitoring
RBAC role和clusterrole绑定后的权限是合集,所以不用担心冲突,具体他会用于servicemonitor/podmonitor的扫描,否则在不合适的命名空间会提示权限错误
因为笔者做了提权,和官方默认操作不同,这虽然会更方便,如果在生产环境,读者也需要考虑安全的问题。读者也可以像官方示例一般做精细的权限管控,以满足最小权限原则
虽然使用CR时通过加上命名空间选择器,也可以满足抓取其他命名空间的metrics端点的需要,但可能同时管理特别多的CR资源的时候,还是很容易混乱,所以建议是和应用放在一起。
5.持久化
默认的Prometheus CR是不带持久化的,这里我们根据官方文档给它声明一个存储类,如果需要调整副本数,也可以在这里进行操作
另外由CRD创建出来的Prometheus的自动清理天数是1d,如图,生产需要进行调整

kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.44.0
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.44.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.44.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
## 注意这里,如果没有上面的RBAC设置,其他命名空间的sevicemonitor可能不会被扫描
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.44.0
## 主要增加了这里
storage:
## retention默认1d,改为30d,按需更新
retention: 30d
volumeClaimTemplate:
spec:
storageClassName: longhorn
resoures:
requests:
storage: 200Gi
6.访问
官方的默认manifest创建了网络策略,限制是只能通过ingress进入,所以进行测试时,简单的kubectl proxy和改nodeport服务都是不能访问的.
这里粘贴一条
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.26.0
name: alertmanager-main
namespace: monitoring
spec:
egress:
- {}
ingress:
- from:
- podSelector:
matchLabels:
app.kubernetes.io/name: prometheus
ports:
- port: 9093
protocol: TCP
- port: 8080
protocol: TCP
- from:
- podSelector:
matchLabels:
app.kubernetes.io/name: alertmanager
ports:
- port: 9094
protocol: TCP
- port: 9094
protocol: UDP
podSelector:
matchLabels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
policyTypes:
- Egress
- Ingress
如果只是进行试用,建议可以把networkpolicy全部删掉。
如果是生产可能要给ingress控制器的pod加上合适的标签并使其匹配networkpolicy规则,这里暂不做展开。
7.自定义CR资源
7.1 ServiceMonitor
常用这个
最简单的
选择器选择当前命名空间含app.kubernetes.io/name: hubble-relay的K8S服务,具名端口(服务的,不能直接写端口号)是metrics,路径是 /metrics,间隔30秒
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: hubble-relay-service-monitor
namespace: kube-system
labels:
app.kubernetes.io/name: hubble-relay
spec:
selector:
matchLabels:
app.kubernetes.io/name: hubble-relay
endpoints:
- port: metrics
interval: 30s
path: /metrics
跨命名空间的
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: jmx-service-monitor
namespace: monitoring
labels:
app: jmx-monitor
spec:
endpoints:
- port: jmx
interval: 30s
##多了一个选择器筛选命名空间
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
metrics: jmx
exporter/mertics端点导入须知
具体的使用细节是,要给exporter的服务加上给ServiceMonitor发现的标签如metrics: jmx,或者pod monitor的方式给pod加合适的标签。主要就是要通过标签服务发现
而Exporter如何接入和使用,不在本文的范畴
7.2 PodMonitor
语法类似,这次要求是pod有具名端口http-metrics和路径/metrics,选择器是 同时包含app.kubernetes.io/instance: promtail ,app.kubernetes.io/name: promtail标签
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: promtail-pod-monitor
namespace: loki
labels:
app.kubernetes.io/instance: promtail
spec:
selector:
matchLabels:
app.kubernetes.io/instance: promtail
app.kubernetes.io/name: promtail
podMetricsEndpoints:
- path: /metrics
port: http-metrics
interval: 30s
7.3 PrometheusRule
和原本的直接Prometheus rule类似,但可以专门放出来让operator来做聚合和分组,好管理一些
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node-context-switching-high-rule
namespace: monitoring # 根据实际情况指定namespace
spec:
groups:
- name: node-performance-rules
rules:
- alert: NodeContextSwitchingHigh
expr: rate(node_context_switches_total[5m])/count without(mode,cpu) (node_cpu_seconds_total{mode="idle"}) > 2000
for: 0m
labels:
severity: warning
annotations:
description: "5分钟内平均每核心的上下文切换数超过阈值,value: {{ $value }}"
summary: " 节点CPU上下文切换高 (Instance: {{ $labels.instance }})"
以上三种CR在官方的示例中manifest文件夹中有用到一些,可以参考
7.4 alertmanagerconfig
alertmanager的路由抑制等配置在这个CRD资源进行配置,但是我感觉区别和本来的不大,当然要用它的CR只能这样来做
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: config-example
labels:
alertmanagerConfig: example
spec:
route:
groupBy: ['job']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhookConfigs:
- url: 'http://example.com/'
7.5 alertmanager
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.25.0
name: main
namespace: monitoring
spec:
image: quay.io/prometheus/alertmanager:v0.25.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.25.0
replicas: 3
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 4m
memory: 100Mi
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: 0.25.0
7.6 grafana
grafana虽然在kube-operator中有安装,但是没有任何的CRD,但kube-Prometheus也提供了一定的简化配置的方式
7.6.1 数据源
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.5.2
name: grafana-datasources
namespace: monitoring
stringData:
datasources.yaml: |-
{
"apiVersion": 1,
"datasources": [
{
"access": "proxy",
"editable": false,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-k8s.monitoring.svc:9090",
"version": 1
}
],
}
type: Opaque
除了默认的Prometheus,也可以按需预配置数据源,如loki,或者考虑在grafana安装客户端后,链接mysql,redis等
7.6.2 dashboard相关
这三个资源结合也可以配置预置的grafana dashboard

由于文件都比较 长,这里不贴了
讲解以下具体怎么做。具体的流程如下
grafana-dashboardDefinitions.yaml
主要放dashboard的json定义,根据原本就有的参考一下放进去即可,就是需要注意缩进,可以参考的步骤是
kubectl create configmap 名字 -n monitor然后拿着生成的configmap放到这里面


因为最后面是根据configmap的名字做后面的引用的

至于json模板的来源,可以从grafana dashboard下,也可以是自己的模板,能在grafana导入的这里肯定也能用。
grafana-dashboardSources.yaml
增加一个文件夹和默认的区分开,当然,这里的orgID:1也对应了前面数据源1号的kube-Prometheus中的Prometheus定义
apiVersion: v1
data:
dashboards.yaml: |-
{
"apiVersion": 1,
"providers": [
{
"folder": "Default",
"folderUid": "",
"name": "0",
"options": {
"path": "/grafana-dashboard-definitions/0"
},
"orgId": 1,
"type": "file"
},
{
"folder": "depends",
"folderUid": "",
"name": "1",
"options": {
"path": "/grafana-dashboard-definitions/1"
},
"orgId": 1,
"type": "file"
}
]
}
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 9.5.2
name: grafana-dashboards
namespace: monitoring
grafana-deployment.yaml
新增挂载,跟着原本就有的就好,这里的区别是上面的0/1
- mountPath: /grafana-dashboard-definitions/0/scheduler
name: grafana-dashboard-scheduler
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/workload-total
name: grafana-dashboard-workload-total
readOnly: false
- mountPath: /grafana-dashboard-definitions/1/jmx
name: grafana-dashboard-jmx
readOnly: false
- mountPath: /grafana-dashboard-definitions/1/minio
name: grafana-dashboard-minio
readOnly: false
同样也是参考原本就有的进行configmap的挂载声明
- configMap:
name: grafana-dashboard-workload-total
name: grafana-dashboard-workload-total
- configMap:
name: grafana-dashboard-mysql
name: grafana-dashboard-mysql
- configMap:
name: grafana-dashboard-redis
name: grafana-dashboard-redis
最后apply所有资源,grafana的预设就好了
7.6.3 坑
很多从dashboard商店下载下来的会要求在导入时选择数据源,而这可能存在问题,因为直接按照上面的方式导入的这个是不存在的
mysql-overview.json: |-
{
"__inputs": [
{
"name": "DS_PROMETHEUS",
"label": "prometheus",
"description": "",
"type": "datasource",
"pluginId": "prometheus",
"pluginName": "Prometheus"
}
],
笔者的解决办法是手动增加变量后重新save as后用这些新的dashboard json模板导入前面的步骤

此时后面新的json模板可以有一个默认的数据源Prometheus,可以正常使用
7.6.4 持久化sqllite
如果觉得上面的步骤比较繁杂,也可以考虑给grafana pod挂载pv以持久化默认的sqlite以复用导入的仪表盘和数据源等,grafana容器的对应路径是/var/lib/grafana读者可以自行尝试
还有几个CRD资源没有用到,读者可以参考官方文档
下面给出官方的CR列表,大多都已经提到了
Prometheus, which defines a desired Prometheus deployment.PrometheusAgent, which defines a desired Prometheus deployment, but running in Agent mode.Alertmanager, which defines a desired Alertmanager deployment.ThanosRuler, which defines a desired Thanos Ruler deployment.ServiceMonitor, which declaratively specifies how groups of Kubernetes services should be monitored. The Operator automatically generates Prometheus scrape configuration based on the current state of the objects in the API server.PodMonitor, which declaratively specifies how group of pods should be monitored. The Operator automatically generates Prometheus scrape configuration based on the current state of the objects in the API server.Probe, which declaratively specifies how groups of ingresses or static targets should be monitored. The Operator automatically generates Prometheus scrape configuration based on the definition.ScrapeConfig, which declaratively specifies scrape configurations to be added to Prometheus. This CustomResourceDefinition helps with scraping resources outside the Kubernetes cluster.PrometheusRule, which defines a desired set of Prometheus alerting and/or recording rules. The Operator generates a rule file, which can be used by Prometheus instances.AlertmanagerConfig, which declaratively specifies subsections of the Alertmanager configuration, allowing routing of alerts to custom receivers, and setting inhibit rules.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)