
Spring是怎么回事?新手入门就看这篇吧
前言
今天壹哥给大家介绍一套开源的轻量级框架,它就是Spring。在给大家详细讲解Spring框架之前,壹哥先给大家介绍Spring框架的主要内容:
Spring的基本概念
Spring核心思想之ioc
Spring核心思想之aop
Spring框架对事务的支持

在本系列文章的讲解中,壹哥会给大家配备丰富的案例、图片以及对应的学习视频,目的就是让大家更好的理解和运用Spring框架,并给大家带来足够的启发和思考。接下来我们正式学习Spring框架。
一. Spring框架的基本概述
1. 什么是Spring
在Spring官网(https://spring.io/projects/spring-frameworkhttps://Spring.io/projects/Spring-framework)里面,是这样介绍Spring的:

如果大家看不懂英文,壹哥结合官网以及自己的理解,给大家介绍什么是Spring:
Spring是一个全栈的、开源的javaEE轻量级企业框架。以IOC(Inverse Of Control:控制反转)和AOP(Aspect Oriented Programming:面向切面编程)为核心思想提供了基于持久层、业务层和控制层的众多企业级技术解决方案。此外Spring还整合了众多第三方优秀的框架和类库,逐渐成为业界最流行的企业应用框架。
壹哥先给大家画一幅图,让大家更好的理解Spring的概念:

相信通过这幅图,大家对Spring的概念有了清晰的理解。
了解了Spring的基本概念之后,我们再来了解一下Spring的发展历程。
2. Spring的发展历程
在介绍Spring的发展历程之前,壹哥有必要提及一下Spring的开山鼻祖Rod Johnson(罗德·约翰逊),他是Spring框架的缔造者。
其实Spring并不是凭空存在的。早在Spring框架诞生之前,java企业级技术解决方案主要依靠javase和EJB框架。但是EJB框架在企业级开发中存在一些弊端和缺陷。
2002年,Rod Johnson 撰写了一本名为《 Expert One-to-One J2EE Design and Development 》的书。这本书介绍了当时 Java 企业应用程序开发的情况,并系统阐述了 J2EE 使用 EJB 开发设计的优点及解决方案。
同年又推出了《Expert one-on-one J2EE Development without EJB》,对EJB的各种笨重臃肿的结构进行了逐一的分析和否定,并分别以简洁实用的方式替换之,堪称经典。
2003年,推出的《Expert one on one J2EE design and development》中阐述的部分理念,在这本书中,他提出了一个基于普通 Java 类和依赖注入的思想。在书中,他展示了如何在不使用 EJB 的情况下构建高质量,可扩展的系统--这就是Spring的雏形!
2004年,Spring横空出世!Spring1.0版本发布,随后Spring框架迅速发展。
2006年10月Spring 2.0于发布。
经过多年的发展,2017 年 9 月份发布了 Spring具有里程碑意义的版本 Spring 5.0 通用版(GA),并提出了最令人兴奋的响应式编程模型。
现在Spring的最新版本已经更迭到了Spring 6。

到这里,壹哥就给大家详细介绍了Spring的发展历史,希望大家心中有数,以后你在跟别人聊Spring的时候,这也是一种不可或缺的谈资。接下来,壹哥再给大家介绍一下Spring的优势。
3. Spring的优势
对于javaee开发人员来说,基于Spring庞大的生态系统,Spring几乎是每个人离不开的框架,所以Spring的优势不言而喻!在这里壹哥给大家简单罗列Spring的优势都有哪些:
降低程序耦合度,简化开发:通过 Spring 提供的 IoC 核心容器,可以将对象之间的依赖关系交给 Spring帮我我们进行控制,避免因为硬编码所造成的程序高程序耦合。
AOP 面向切面思想的支持:通过 Spring 的 AOP 思想,对传统 OOP 思想进行了延续和扩展。通过面向切面编程,在不侵入源代码的前提下,轻松实现对应用进行更新和扩展。
基于对数据库事务的支持:将我们从单调烦闷的数据库事务管理代码中解脱出来,通过声明式方式和注解式的方式进行灵活的事务管理,将事务代码和业务代码剥离开来。降低业务代码的耦合度,提高开发效率和质量。
方便集成各种第三方优秀框架:Spring降低了各种框架的使用难度,提供了对各种优秀框架( Struts、 Hibernate、 rabbitmq、 elasticsearch、redis...)的无缝支持。
降低 JavaEE API 的使用难度:Spring 对 JavaEE API(如 JDBC、 Redis)进行了薄薄的封装层,提供了模板对象操作这些API,使这些 API 的使用难度大为降低。
Java 源码是经典学习范例:Spring 的源代码博大精深,它设计巧妙、别具风格,处处体现着大师对 Java 设计模式的灵活运用以及对 Java 技术的高深造诣。它的源代码无意是 Java 技术的最佳实践范例。通过对源码的阅读,我们可以更加清晰了解框架的设计逻辑,可以拓宽我们对java知识的认知广度和深度。
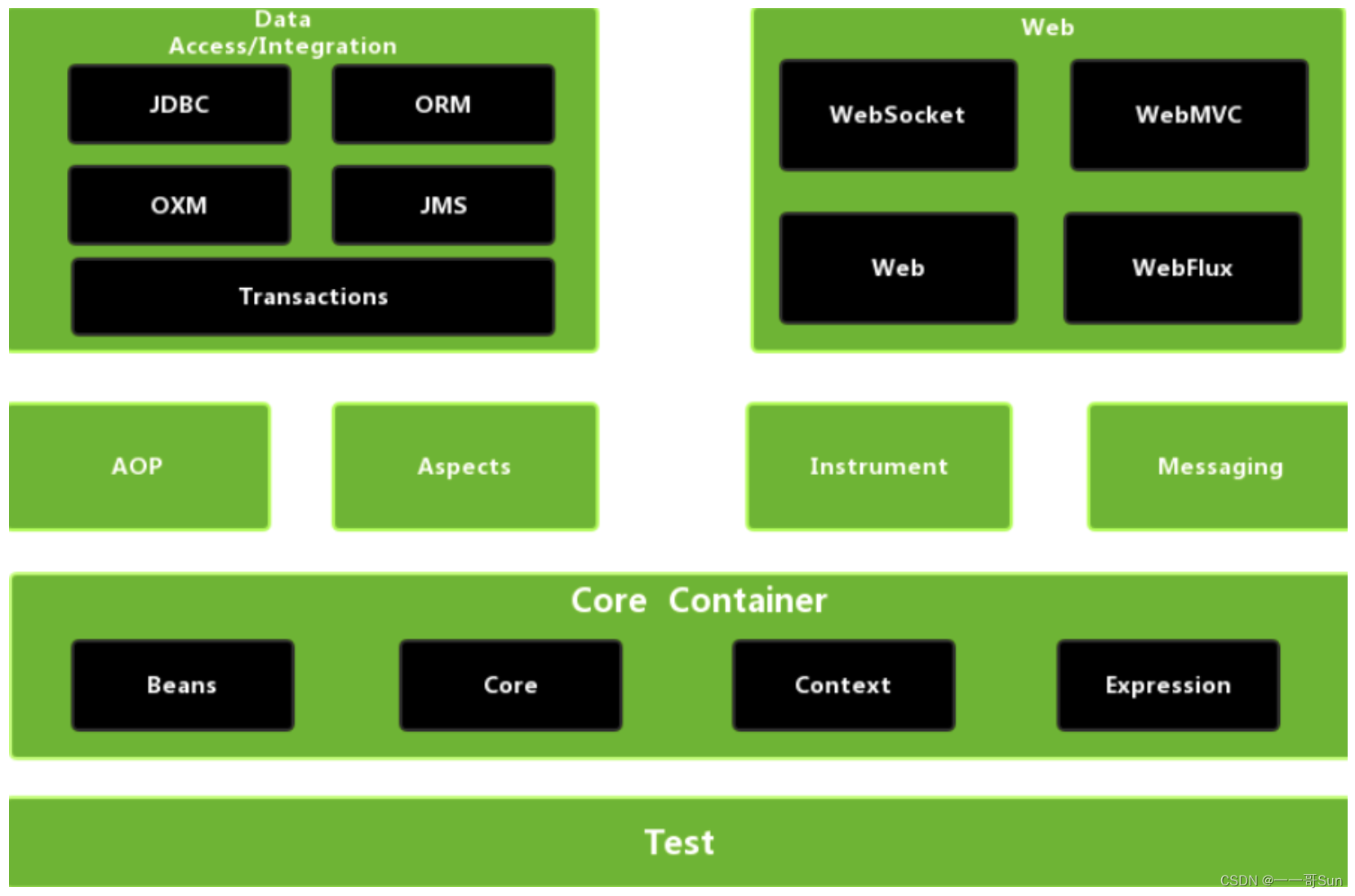
聊完了Spring的优势以后,Spring到底包含哪些内容呢?下面壹哥通过一幅图来描述Spring的体系结构。
4. Spring的体系结构

下面壹哥就这幅图给大家做详细的介绍:
4.1 核心容器(Core Container)
Spring的核心容器是Spring其他功能正常运行的基础,它包含了Spring-core、Spring-beans、Spring-context和Spring-expression(Spring表达式语言)等模块。
Spring-core模块:Spring框架的核心部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)的核心功能。
Spring-beans模块:提供了BeanFactory,我们俗称bean工厂。Spring将管理的对象称为Bean。Spring容器就是通过这个bean工厂来帮助我们管理bean。
Spring-context模块:我们称为Spring 上下文环境,基于Spring-core和Spring-beans模块的基础之上,提供了通过XML和注解的方式来管理bean对象。ApplicationContext接口是Spring-context模块的核心。也是我们在后续学习中需要关注的焦点。
Spring-expression模块:提供了强大的表达式语言去支持对bean进行查询和设置。Spring表达式语言支持设置和获取备案的属性值、以及进行逻辑和算术运算等操作。
4.2 数据访问/集成(Data Access/Integration)层
数据访问/集成层由JDBC、ORM、OXM、JMS和Transactions(事务)模块组成。
Spring-jdbc模块:Spring对原生的jdbc技术进行了封装,提供了jdbc Template来进行数据库操作。是Spring基于对数据持久层的解决方案之一。
Spring-orm模块:Spring 框架提供了对若干个 ORM 框架的集成层,比如Hibernate等。
Spring-oxm模块:是Spring3.0版本中的一个新特性,它提供了一个支持o(对象)/XML映射的抽象层实现,例如JAXB、Castor、JiBX和XStream。
Spring-jms模块(Java Messaging Service):指Java消息传递服务,提供了对消息的生产和发送功能,通过对jms的封装,简化了对jms api的使用难度。
Spring-tx模块:事务模块支持使用编程式事务、声明式事务和注解式事务对事务进行管理。
4.3 Web层
Web层由Spring-web、Spring-webmvc、Spring-websocket和Portlet模块组成。
Spring-web模块:提供了基本的Web开发功能,比如通过监听的机制初始化Spring的上下文环境。
Spring-webmvc模块:提供了对Spring MVC的实现。
Spring-websocket模块:Spring4.0以后新增的模块,它提供了WebSocket和SocketJS的实现。
Portlet模块:提供了Portlet环境下的MVC实现。
4.4 AOP(Aspect Oriented Programming)模块
Spring-aop模块:提出了AOP思想的面向切面编程的实现,允许我们定义通知方法对切点方法进行增强,对代码进行解耦合。
Spring-aspects模块:提供了对第三方AOP框架AspectJ的集成功能,AspectJ是一个功能强大且易于上手的的AOP框架。我们在后面也会对AspectJ框架进行详细学习。
4.5 植入(Instrumentation)模块
Spring-instrument模块:在特定的应用服务器中,提供了类植入(instrumentation)支持和类加载器的实现,比如Spring-instrument-tomcat 模块支持对Tomcat服务器的植入代理。
4.6 消息传输(Messaging)
这是Spring4.0以后新增了消息(Spring-messaging)模块,集成了消息api,对消息协议也提供了支持。
4.7 测试(Test)模块
Spring-test模块:支持使用JUnit对Spring组件进行单元测试。Spring提供了对junit的整合,提供了一个带有Spring环境的标准测试模板,后续我们也会学习Spring对junit单元测试框架的整合。
二. 程序中的耦合
前面壹哥给大家介绍Spring优势的时候,给大家描述了Spring框架可以降低代码的耦合度。那到底什么是程序的耦合,现在壹哥用几个例子给大家介绍清楚。
1. 耦合案例1
1.1 代码示例
我们来看一段代码,这段代码相信大家都很熟悉,就是使用jdbc技术进行数据表的查询操作。首先我们新建一个maven工程,并导入相关依赖。
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
</dependencies>注意:壹哥友情提示,这个依赖适配的mysql数据库版本是5.x哦。
我们在这里编写一段jdbc代码。
public class TestMySql {
@Test
public void test01() throws Exception{
//注册驱动,此时我们不要Class.Name()的方式进行驱动加载,为什么?请看下文分解~
DriverManager.registerDriver(new com.mysql.jdbc.Driver());
String url = "jdbc:mysql://192.168.10.137:3306/spring";
//获取连接对象
Connection connection = DriverManager.getConnection(url, "root", "Admin123!");
PreparedStatement statement = connection.prepareStatement("select * from account");
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()){
Integer id = resultSet.getInt("id");
String name = resultSet.getString("name");
Double money = resultSet.getDouble("money");
System.out.println(id + " " + name + " " + money);
}
resultSet.close();
statement.close();
connection.close();
}
}我们运行程序,查看效果是没有问题的。但是如果我们把POM文件中的依赖注释掉呢?
<!--
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
-->这个时候,可能有小伙伴要问了,老师,你为什么要把这个依赖注释掉呢?其实壹哥是用来模拟在项目中,如果资源缺失,对程序带来的影响是什么。
此时我们在重新编译程序(Ctrl+F9)。我们发现程序报错,程序编译不通过!

小伙伴们想一下:程序编译不通过意味着什么呢?壹哥给大家解释一下:
一个企业级的项目,里面的业务功能肯定有很多,假设一个业务功能出现了问题,但是其他业务功能是正常的。如果一个业务功能出现了问题,导致程序编译不通过的后果是什么?是不是其他正常的业务功能也无法正常运行了,这实在是我们不想看到的情况。
大家想想,如果出现了这种情况,理想的解决方案是什么?当然最好的解决方案是修复当前程序的bug,让程序正常编译通过。但是假设一时半会解决不了这个问题呢?
即使这个业务功能出现了问题,我们也要期望其他能功能也应该正常执行,换句话说,就是一定要让程序编译通过!!!而之所以会出现这种编译不通过的情况,就是因为我们的代码出现了高耦合!
1.2 耦合的分析以及对应的解决方案
什么是耦合?
耦合指的是程序之间的依赖关系。这种依赖关系包括类与类之间存在依赖关系,类与方法之间存在依赖关系。
注意:壹哥说重点,我们所说的降低耦合,就是降低程序的依赖关系,但是依赖关系只能尽量降低,不能彻底消除!
上面的案例,其实就是类与类之间存在高耦合的体现。在TestMySql这个类里面使用了Driver这个驱动类,说明TestMySql依赖于Driver驱动类。
由于我们注释了驱动类,导致Driver这个类不存在,最后导致TestMySql这个类编译不通过。
如何解耦?我们解耦的最终目的要达到一个效果,就是即使依赖缺失了。程序也应该正常编译通过,这就叫编译时不依赖,也就是在编译期不检查程序间的依赖关系。所以我们需要对原来的代码进行改造,如何改造?基于反射的技术降低代码的耦合度。
@Test
public void test01() throws Exception{
//注册驱动
//DriverManager.registerDriver(new com.mysql.jdbc.Driver());
//使用反射的机制加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://192.168.10.137:3306/spring";
//获取连接对象
Connection connection = DriverManager.getConnection(url, "root", "Admin123!");
PreparedStatement statement = connection.prepareStatement("select * from account");
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()){
Integer id = resultSet.getInt("id");
String name = resultSet.getString("name");
Double money = resultSet.getDouble("money");
System.out.println(id + " " + name + " " + money);
}
resultSet.close();
statement.close();
connection.close();
}此时重新编译代码,这个时候就不会报错。我们运行试试(此时pom.xml的坐标被注释了,在运行时会报异常)。

但此时报的是运行时异常,而不是编译时异常,换句话说就是整个应用编译通过,其他正常功能可以运行,但是有问题的功能会抛出运行时异常。虽然有异常,但至少没有拖后腿,影响其他正常功能的执行!
在这里壹哥给大家总结一下,如何降低代码的耦合性:
使用反射的机制,避免使用new关键字。
2. 耦合案例2
接下来我们再看一个案例,进一步理解耦合的概念,以及解决耦合的方案。
2.1 代码示例
现在我们定义一段代码,模拟新增用户的功能。
dao部分:
我们定义一个模拟用户新增的dao接口。
public interface UserDao {
//模拟新增user的方法
public void addUser();
}接下来,我们对接口进行实现,假设我们现在对持久层的实现技术是基于jdbc技术实现的。我们现在就在接口实现类里面输出一句话,模拟我们完成了对数据库的新增操作。
public class UserDaoImpl implements UserDao{
//模拟新增user的dao
public void addUser() {
System.out.println("基于jdbc技术实现了对新增用户的操作.....");
}
}service部分:
接下来我们再定义一个新增用户的业务接口。
public interface UserService {
//模拟新增user的业务
public void add();
}我们定义业务实现类:
public class UserServiceImpl implements UserService {
//实现新增用户的业务方法
public void add() {
UserDao dao = new UserDaoImpl();
dao.add();
}
}2.2 耦合的分析以及对应的解决方案
在这里壹哥做一个假设。假设现在因为客户需求的变更,我们需要对持久层的技术进行变化,我们需要对原来jdbc技术实现接口的方法变成使用mybatis框架实现。所以我们需要重新定义一个接口实现类:
public class UserDaoImpl2 implements UserDao{
//模拟新增user的dao
public void addUser() {
System.out.println("基于mybatis技术实现了对新增用户的操作.....");
}
}然后我们需要修改业务实现类的源代码,更改接口的调用方式:
public class UserServiceImpl implements UserService {
//实现新增用户的业务方法
public void add() {
//UserDao dao = new UserDaoImpl();
UserDao dao = new UserDaoImpl2();
dao.addUser();
}
}这样修改会有什么问题呢?
这会造成源代码的改动!
做过开发的小伙伴们都知道,如果我们的应用要进行更新迭代,或者需要扩展一些新功能,必须在不修改原来功能代码的基础上完成,因为一旦修改源代码,很有可能会导致其他正常的功能代码也出现问题。上面出现修改源代码的原因其实也是高耦合的一种体现!究其原因还是UserServiceImpl这个类依赖了UserDao的实现类。
那么又该如何解决这个问题呢?
在解决这个问题之前,壹哥先要明确一个概念,什么是javabean?
javaBean就是在java程序中,可以重用的一些组件,比如实体类、dao和service接口实现类的对象。解决方案如下:
1.需要一个配置文件来配置我们的service和dao。配置的内容:唯一标志=全限定类名(key=value)。
2.在一个工厂类里面,通过读取配置文件中配置的内容,反射创建对象。也就是通过工厂来管理我们的bean。
我们选取什么样的配置文件最合适?我们就选取大家最熟悉的properties配置文件。
定义配置文件,管理我们的service和dao:
#key=value key bean的名称 value:类的全限定名
userDao=com.qf.dao.impl.UserDaoImpl
userDao2=com.qf.dao.impl.UserDaoImpl2
userService=com.qf.service.impl.UserServiceImpl定义的配置文件,效果如下:

定义一个工厂类,通过工厂来获取bean
public class BeanFactory {
static Properties properties;
static{
//通过类加载器读取properties配置文件
InputStream inputStream = BeanFactory.class.getClassLoader().getResourceAsStream("bean.properties");
properties = new Properties();
try {
properties.load(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//定义一个获取bean的方法
public static Object getBean(String name){
String value = properties.getProperty(name);
try {
//基于反射的机制实例化bean对象
Object o = Class.forName(value).newInstance();
return o;
} catch (Exception e) {
throw new RuntimeException();
}
}
}改造业务实现类的代码:
public class UserServiceImpl implements UserService {
//实现新增用户的业务方法
public void add() {
//UserDao dao = new UserDaoImpl();
//UserDao dao = new UserDaoImpl2();
UserDao userDao = (UserDao) BeanFactory.getBean("userDao");
userDao.addUser();
}
}如果我们想要切换使用mybatis的技术实现dao接口的话,我们只需要把getBean方法里面的bean的名称修改即可。
UserDao userDao = (UserDao) BeanFactory.getBean("userDao2");现在我们通过工厂模式解决了代码出现的耦合度问题。接下来,大家再思考一下,目前我们的代码有没有出现问题。如果我们循环调用5次service,会出现什么结果?
我们进一步改造代码:
public class UserServiceImpl implements UserService {
public void add() {
UserDao accountDao = (UserDao) BeanFactory.getBean("accountDao2");
//输出accountDao实例对象
System.out.println(accountDao);
accountDao.addUser();
}
}定义测试类:
@Test
public void test02(){
for(int i = 0;i<5;i++){
UserService accountService = new UserServiceImpl();
accountService.add();
}
}查看输出结果:

结论:该业务实现类调用的dao实现类对象是多例的。
我们的”工厂类”生产的bean之所以是多例模式,是因为下面这句代码:

在单线程的场景下面,我们期望工厂生产的bean的单例的。因为单例bean带来的优势也比较明显:
可以减少JVM垃圾回收的次数。
提高了获取bean的速度。
降低了实例化bean带来的性能消耗。
接下来,我们就来改造我们的工厂代码。
2.3 优化工厂代码,生产单例bean
改造工厂类:
public class BeanFactory {
static Properties properties = null;
//用来存储实例对象的 key是bean的名称 value是实例对象
static Map<String,Object> map = new HashMap<String, Object>();
static {
try {
properties = new Properties();
//通过类加载器加载properties配置文件
InputStream in = BeanFactory.class.getClassLoader().getResourceAsStream("bean.properties");
properties.load(in);
//获取properties配置文件中的所有key值
Enumeration<Object> keys = properties.keys();
while(keys.hasMoreElements()){
String name = keys.nextElement().toString();
String value = properties.get(name).toString();
//通过key的名称获取对应的value值
Class<?> clazz = Class.forName(value);
Object o = clazz.newInstance();
map.put(name,o);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//根据key获取对应的value
public static Object getBean(String name){
return map.get(name);
}
}测试:
查看控制台输出效果:

现在我们终于使用第二种方案降低了代码的耦合性,在这里壹哥再次总结一下:
可以使用工厂+反射的机制降低代码的耦合度!
但是我们每次都自己通过工厂+配置的方式创建对象的过程过于繁琐,其实Spring已经帮助我们做了这些事情,spring如何帮助我们管理bean的?在下期文章,壹哥再给大家细细道来。
三. 结语
通过这篇文章的介绍,壹哥带领大家一步步剖析了什么是耦合,以及解耦合对应的具体方案,希望大家能够理解为什么要使用这种思想帮助我们管理bean。也希望大家理解为什么我们要手动基于反射+工厂的方式去管理bean的用意。那么Spring到底如何使用ioc管理bean的?请大家继续关注壹哥的后续文章,谢谢大家的支持和鼓励!
四. 今日作业
1. 什么是程序的耦合,在评论区给出你们的答案。
2. 如何自定义容器管理bean? 在评论区说出你们的解决方案。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)