
MNIST数据集简单介绍
本文对MNIST数据集进行了简单的研究和探索,包括数据集的引入,数据集的格式和数据集的内容等知识点。
一键AI生成摘要,助你高效阅读
问答
·
目录
MINST数据集是机器学习领域一个经典的数据集,其中包括70000个样本,包括60000个训练样本和10000个测试样本
数据集的引入
使用tensorflow框架,通过keras获取MNIST数据集:
mnist = tf.keras.datasets.mnist
通过load_data()方法来加载数据集中的数据
获取到的数据以tuple的格式进行存储,格式为:
(训练样本数据集,训练标签数据集),(测试样本数据集,测试标签数据集)
因此用相应的元组来接收数据:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
数据集的格式
以上四个数据集的格式都为:numpy.ndarray,ndarray是一个N维数组类型的对象,可以打印数据集的相关属性进行查看:
print("训练样本的维度为:",x_train.ndim)
print("训练样本的形状为:",x_train.shape)
print("训练样本的元素数量为:",x_train.size)
print("训练样本的数据类型为:",x_train.dtype)
结果如下:

通过其形状可以看出训练样本数据集存放了60000张28*28像素的数字图像;
数据集的内容
可以通过以下代码打印查看其中存储的图像:
for i in range(0,28):
for j in range(0,28):
print("%.1f" % x_train[0][i][j] , end=" ")
print()
结果如下:
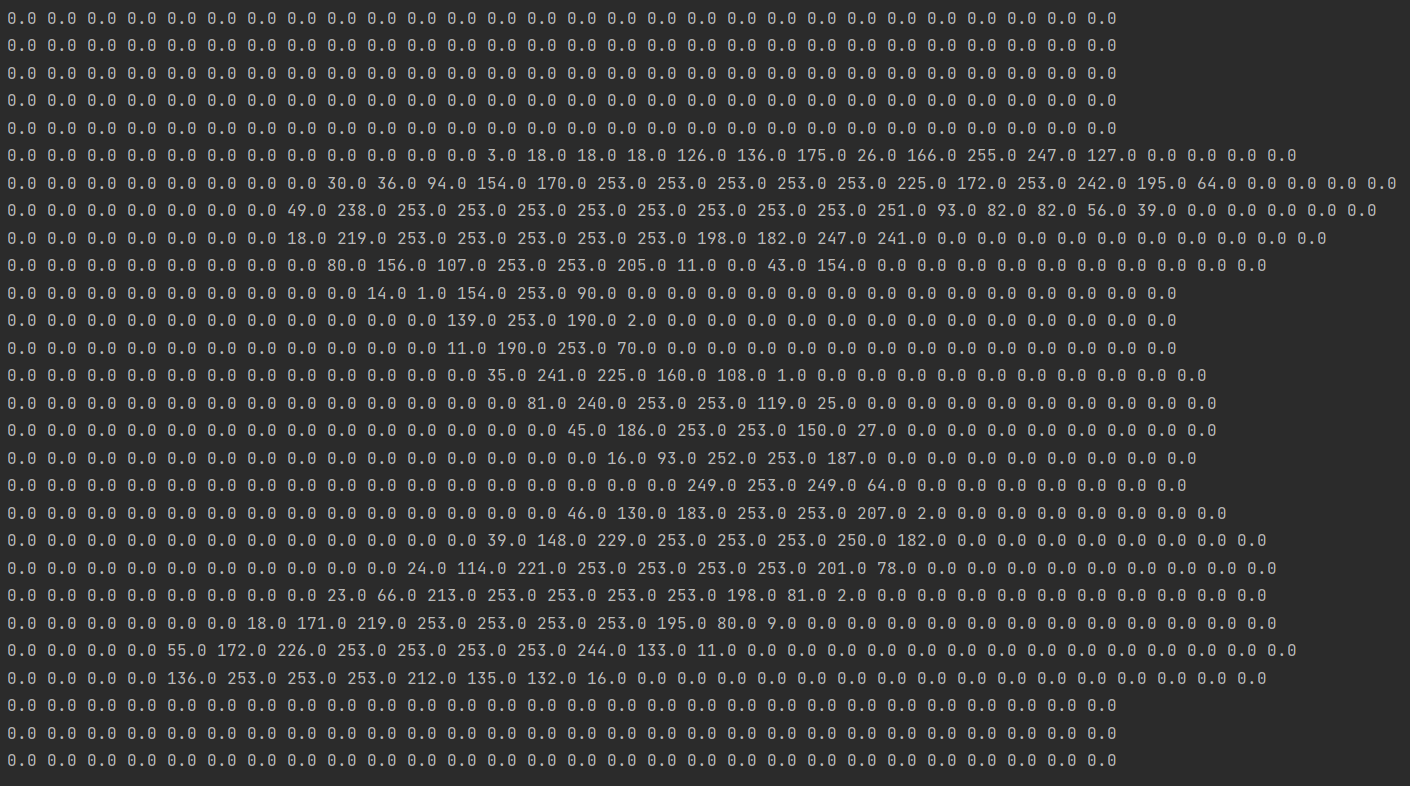
很明显能看出这是一个数字5
由于数据集中每一个像素的值都在0-255范围内,我们对数据进行归一化处理,转化为0-1之间的浮点数:
x_train, x_test = x_train / 255.0, x_test / 255.0
可以看到,处理之后数据类型发生了变化:

再次打印输出存储的图像,依稀也能看出是一个数字5:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)