
详细分析Python遇到的各种数据结构Map、Dict、Set、DataFrame、Series、Zip
1、Mapmap()函数map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]如果希望把list的每个元素都作平方,就可以用map()函数:因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这
目录
一、Map
map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x):
return x*x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]
# 提供了两个列表,对相同位置的列表数据进行相加
map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])结果:[3, 7, 11, 15, 19]
二、字典(Dict)
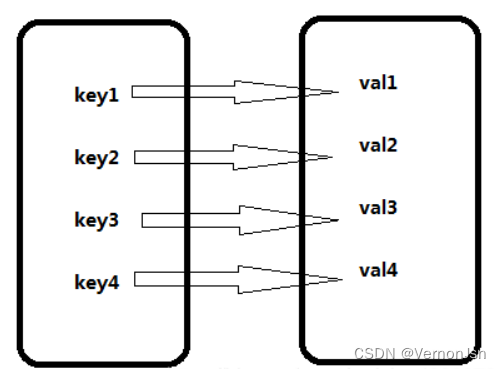
字典是Python提供的一种数据类型,用于存放有映射关系的数据,字典相当于两组数据,其中一组是key,是关键数据(程序对字典的操作都是基于key),另一组数据是value,可以通过key来进行访问。如图:
实例代码:
#!!!!1、创建字典!!!!
# -----使用花括号创建字典-----
a = {'小红':'学霸','小黑':'学渣','老王':'班主任'}
print (a)
# 打印 {'小红': '学霸', '小黑': '学渣', '老王': '班主任'}
#---------------dict()函数创建字典-------
# 创建空字典
e = dict()
print (e)
# 打印 {}
#!!!!2、使用字典!!!!
#- 通过key访问value
a = {'小红':'学霸','小黑':'学渣','老王':'班主任'}
# 通过key访问value
print (a['小红'])
# 打印 学霸
#- 通过key添加键值对
# 创建字典
n = dict(k1 = 1,k2 = 2,k3 = 3)
# 通过key添加key-value对(需要为不存在的key赋值,如果已存在,会被覆盖)
n['k4'] = 4
print (n)
# 打印 {'k1': 1, 'k2': 2, 'k3': 3, 'k4': 4}
#- 通过key修改键值对
m = {'k1': 1, 'k2': 2, 'k3': 3}
# 如果key已存在,则新的value会覆盖原来的value
m['k1'] = '覆盖'
print (m)
# 打印 {'k1': '覆盖', 'k2': 2, 'k3': 3}
#- 通过in或not in运算符判断字典是否包含指定的key
p = {'k1': 1, 'k2': 2, 'k3': 3, 'k4': 4}
# 判断p是否包含名为'k1'的key
print ('k1' in p)
# 打印 True
常见操作:
len(dict)返回长度
dict.keys() 返回包含的key
dict.values()返回包含的values
dict.items()返回元组包含的所有列表
dict.has_key('key') 是否包含key
Python——字典dict()详解 - C、小明 - 博客园
三、集合(Set)
1.set是一个无序不重复的序列
2.可以用 { } 或者 set( ) 函数创建集合
3.集合存放不可变类型(字符串、数字、元组)
注意:创建一个空集合必须用 set( ) 而不是 { } ,因为 { } 是用来创建一个空字典
增删改查
# 1、add(x)将元素x添加到集合里
s = {1,2,3,4,5,}
s.add('5')
print(s)
#结果:{1, 2, 3, 4, 5, '5'}
# 2、update(x),将x添加到集合中,且参数可以是列表、元组、字典等
s = set(('a', 'cc', 'f'))
# 添加字典只能添加不可变的--键
dict_1 = {'name': 'bb', 'age': 'cc', 'f': 11}
s.update(dict_1)
print("添加字典"+str(s))
#结果:添加字典{'name', 'a', 'age', 'f', 'cc'}
s = set(('a', 'cc', 'f'))
tup_1 = (1, 2,)
s.update(tup_1)
print(s)
#结果:{1, 2, 'a', 'f', 'cc'}
# 3、移除集合中元素,如果移除的元素不在集合中将发生错误
s = set(('a', 'cc', 'f'))
s.remove('cc')
print(s)
#结果:{'a', 'f'}
#4、 清空集合
s = set(('a', 'cc', 'f'))
s.clear()
print(s)
#结果:set()差集(-)、交集(&)、并集(|)、对称差集(^)
# difference求差集 或者用 -
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# 两种求差集的方法
print("在s中不在s1中: "+str(s.difference(s1)))
print('在s1中不在s中: '+str(s1-s))
结果:
在s中不在s1中: {'cc'}
在s1中不在s中: {'ww', 1}
#交集
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# 同时在集合s 和 s1 中的元素
print(s.intersection(s1))
print(s1&s)
结果:
{'a', 'f'}
{'a', 'f'}
#并集
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# 元素在集合 s 中或在集合 s1 中
print(s.union(s1))
print(s1|s)
结果:
{'a', 1, 'f', 'cc', 'ww'}
{'a', 1, 'f', 'cc', 'ww'}
#对称差集
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# 除集合s和集合s1共有的以外的元素
print(s.symmetric_difference(s1))
print(s1^s)
结果:
{1, 'ww', 'cc'}
{1, 'ww', 'cc'}
四、Series和DataFrame
要了解Series和DataFrame,首先要知道pandas
pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析。它提供了大量高级的数据结构和对数据处理的方法。
pandas 有两个主要的数据结构:Series 和 DataFrame。
Series
Series 是一个一维数组对象 ,类似于 NumPy 的一维 array。它除了包含一组数据还包含一组索引,所以可以把它理解为一组带索引的数组。
- 创建
import pandas as pd
s=pd.Series(['a','b','c','d'])
- 运算
s1+s2 #索引相同的元素相加,不同的则补充Nan
s*2 #所有元素*2
s+1 #所有元素+1
- 常用方法
s.index #查看索引
s.values #查看数值
s.isnull() #查看为空的,返回布尔型
s.notnull()
s.sort_index() #按索引排序
s.sort_values() #按数值排序
series还算常见,因为如果查看dataframe的某一列,返回的就是series,所以这个类型还是需要熟悉,不要到时候要用的时候不会用。
DataFrame
DataFrame 是一个表格型的数据结构。它提供有序的列和不同类型的列值。平常用Python处理xlsx、csv文件,读出来的就是dataframe格式。
- 创建
可以单独创建,也可以由别的类型转换过来:列表、series、字典等等。
import pandas as pd
df=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=['a','b','c'])- 索引
查看第a列的第1个元素:
df['a'][0]
df.loc[0]['a']
df.iloc[0][0]

上面loc和iloc的区别,大家可以搜索一下,这里就不多说了。
df[['a' ,'b' ] #查看a、b两列
- 常用方法
df.head( 5 ) #查看前5行
df.tail( 3 ) #查看后3行
df.values #查看数值
df.shape #查看行数、列数
df.fillna(0) #将空值填充0
df.replace( 1, -1) #将1替换成-1
df.isnull() #查找df中出现的空值
df.notnull() #非空值
df.dropna() #删除空值
df.unique() #查看唯一值
df.reset_index() #修改、删除,原有索引
df.columns #查看df的列名
df.index #查看索引
df.sort_values() #排序
pd.merge(df1,df2) #合并
pd.concat([df1,df2]) #合并,与merge的区别,自查
pd.pivot_table( df ) #用df做数据透视表(类似于Excel的数透)
上面是大致的介绍,dataframe中的常用方法,大家可以积累下来,是我平常使用过程中比较常用的。
【数据分析入门】之:dataframe和series - 知乎
五、Zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
zip函数的原型为:zip([iterable, …])
参数iterable为可迭代的对象,并且可以有多个参数。该函数返回一个以元组为元素的列表,其中第 i 个元组包含每个参数序列的第 i 个元素。返回的列表长度被截断为最短的参数序列的长度。只有一个序列参数时,它返回一个1元组的列表。没有参数时,它返回一个空的列表。
import numpy as np
a=[1,2,3,4,5]
b=(1,2,3,4,5)
c=np.arange(5)
d="zhang"
zz=zip(a,b,c,d)
print(zz)
输出:
[(1, 1, 0, 'z'), (2, 2, 1, 'h'), (3, 3, 2, 'a'), (4, 4, 3, 'n'), (5, 5, 4, 'g')]
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)