
深入探讨机器学习中的过拟合现象及其解决方法
真正喜欢的人和事都值得我们去坚持。
一键AI生成摘要,助你高效阅读
问答
·
1. What❓
过拟合(Overfitting)是指在机器学习中,模型在训练集上表现较好,但在测试集或实际应用中表现较差的现象。过拟合发生时,模型过于复杂地学习了训练集中的噪声、异常值或特定模式,从而导致对新样本的泛化能力下降。
过拟合通常是由于模型在训练过程中过于强调训练集上的表现,将训练集中的噪声或特定模式也当作了普遍规律而过度拟合。过拟合可能导致模型过于复杂,过于依赖训练集中的特定样本,从而在面对新样本时无法进行准确的预测,从而降低了模型的泛化性能。
过拟合的表现通常包括训练集上的误差较低,但测试集上的误差较高,模型在训练集上的表现比在测试集上要好,模型对噪声或异常值敏感,对新样本的预测不准确等。
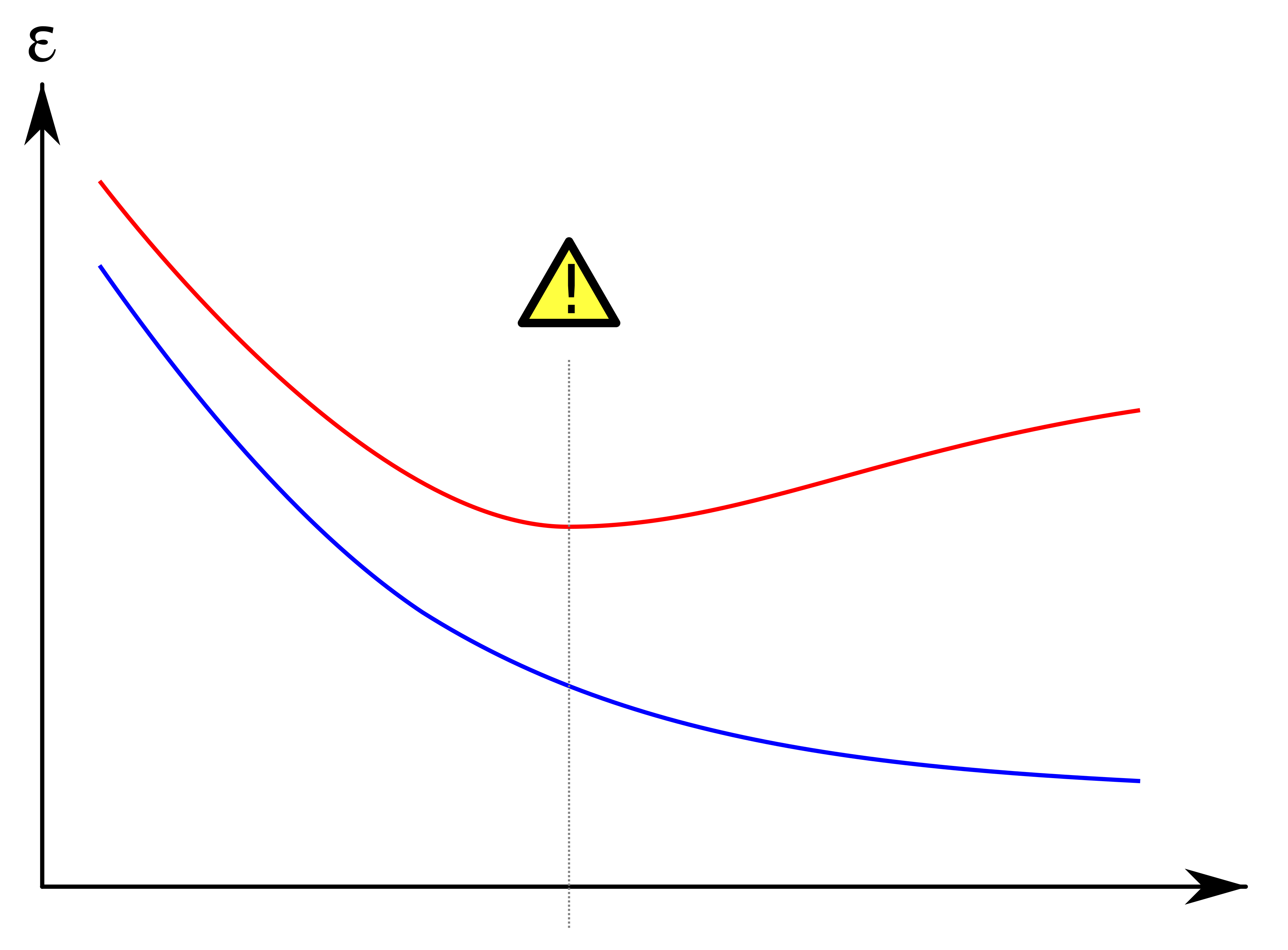
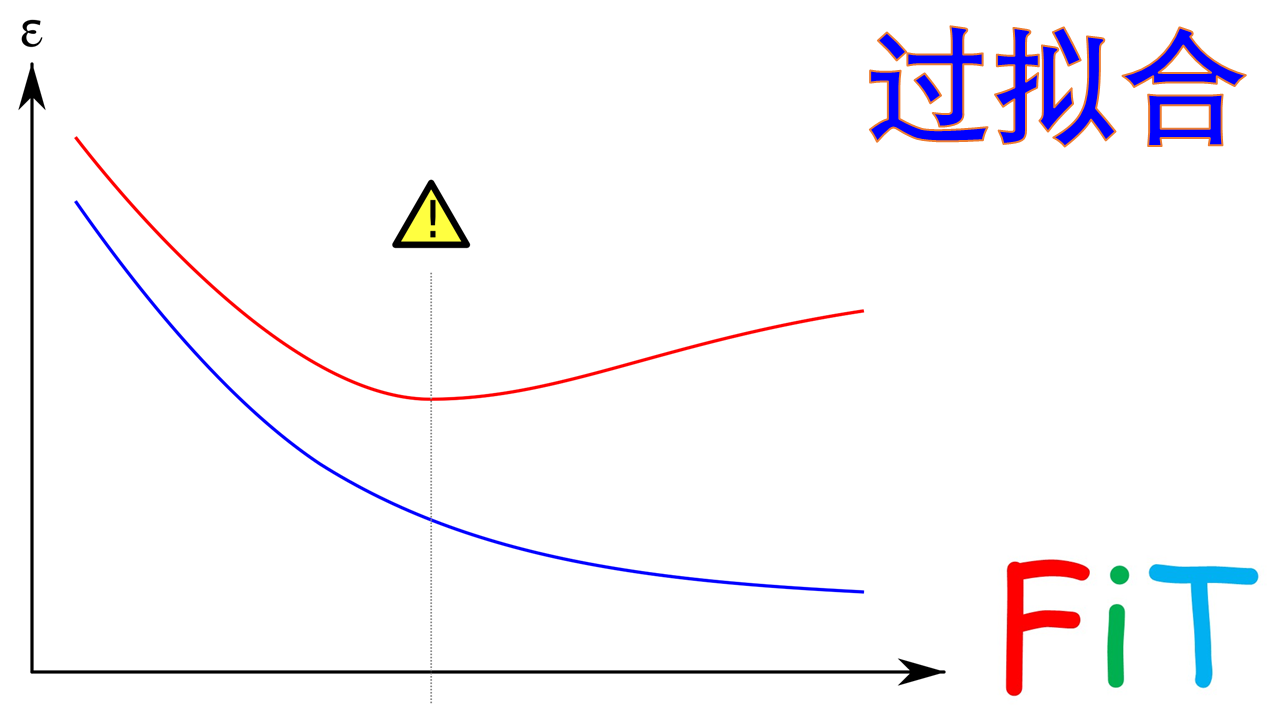
上图中,模型的训练误差以蓝色显示,验证误差以红色显示。随着模型的训练周期增大,验证误差增加(正斜率)而训练误差稳步下降(负斜率),则模型可能发生了过度拟合的情况。 最好的预测和拟合模型将是验证误差具有其全局最小值的地方,也就是图中的虚线位置。

2. Solutions❗️
为了解决或者是缓解过拟合问题,以下是一些常用的方法:
2.1 数据增强
- 数据增强(
Data Augmentation)是一种在机器学习和深度学习中用于增加训练数据量的技术。它通过对原始训练数据进行一系列变换操作,生成新的训练样本,从而扩增了训练数据的规模和多样性。数据增强可以帮助模型更好地学习到数据中的模式和特征,从而提高模型的泛化性能,减少过拟合的风险。 - 数据增强技术可以应用于各种类型的数据,包括图像、文本、语音等。常用的图像数据增强操作包括随机翻转、随机旋转、随机缩放、随机裁剪、色彩变换等,如下图所示。对于文本数据,数据增强可以包括随机删除、随机替换、随机插入等操作。对于语音数据,数据增强可以包括加入噪声、变换语速、变换音调等操作。
- 通过数据增强,可以生成具有多样性的训练样本,从而提高模型的鲁棒性,使其对于新的、未见过的数据更具泛化性能。数据增强也可以减少模型在训练过程中对于少量标注数据的依赖,从而在数据量较小的情况下仍能训练出效果较好的模型。

2.2 正则化
- 正则化(
Regularization):在损失函数中引入正则化项,如L1正则化(Lasso)、L2正则化(Ridge)等,用于限制模型参数的大小,减小模型的复杂度,从而减少过拟合。 L1正则化可以将一些模型参数稀疏化,即将一些参数设为零,从而实现特征选择的效果;而L2正则化会使得模型参数向零的方向收缩,从而减小参数的幅度,降低模型的复杂性。
L 1 : N e w L o s s F u n c t i o n = O r i g i n a l L o s s F u n c t i o n + λ ∗ ∥ w ∥ 1 L1\text{:}NewLossFunction\,\,=\,\,OriginalLossFunction\,\,+\,\,\lambda *\left\| w \right\| _1 L1:NewLossFunction=OriginalLossFunction+λ∗∥w∥1
L 2 : N e w L o s s F u n c t i o n = O r i g i n a l L o s s F u n c t i o n + λ ∗ ∥ w ∥ 2 2 L2\text{:}NewLossFunction\,\,=\,\,OriginalLossFunction\,\,+\,\,\lambda *{\left\| w \right\| _2}^2 L2:NewLossFunction=OriginalLossFunction+λ∗∥w∥22- L1 正则化(Lasso 正则化):Original 是原始的损失函数(例如均方误差、交叉熵等),λ 是正则化参数(用于控制正则化项的权重),w 是模型的参数向量,||w||₁ 是参数向量 w 的 L1 范数(绝对值之和)。
- L2 正则化(Ridge 正则化):其中,损失函数、λ 和 w 的定义与 L1 正则化相同,但是这里的正则化项是参数向量 w 的 L2 范数的平方(参数的平方和)。
- 需要注意的是,正则化参数 λ 的选择对于正则化技术的效果非常关键,λ 越大,正则化项对模型的惩罚越强,模型的复杂性越低;而 λ 越小,正则化项对模型的惩罚越弱,模型的复杂性越高。因此,在实际应用中,需要根据具体问题和数据集的情况,合理选择正则化参数的取值。
2.3 早停策略
- 早停策略(
Early Stopping):在训练过程中,根据验证集的性能表现,在验证集上性能不再提升时提前停止训练,从而防止模型在训练集上过拟合。

- 如上图所示,我们通常在验证集的误差曲线或者准确率曲线的拐点处停止训练,从而防止模型的过拟合。
2.4 随机丢弃
- 随机丢弃(
Dropout):在训练过程中,随机丢弃一些神经元的输出来减少神经元之间的依赖性,也就是输出置为零,如下图所示,这样可以强制网络在训练时学习多个独立的子网络,从而增加模型的泛化能力。
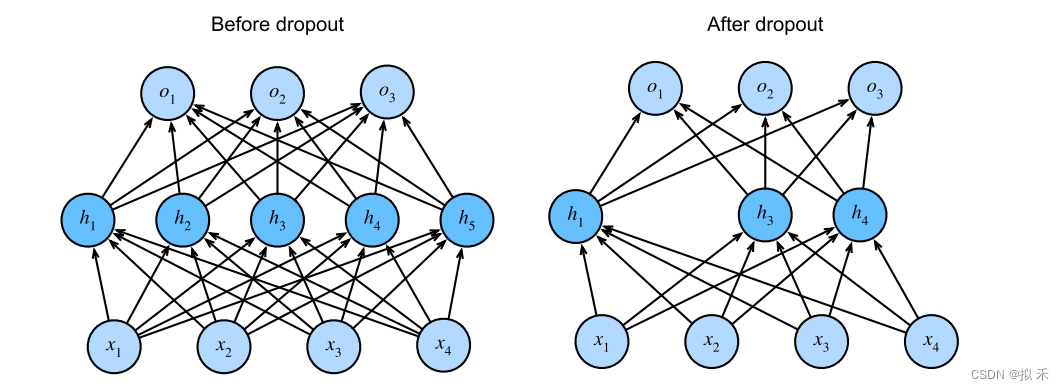
Dropout的设置大小通常是一个超参数,需要在训练过程中进行调优。一般情况下,随机丢弃的大小在 0.1 到 0.5 之间比较常见,但最佳的设置大小取决于具体的问题和模型架构。- 在实践中,可以通过尝试不同的丢弃率进行模型训练,然后使用验证集上的性能指标来选择最佳的丢弃率。通常情况下,较大的丢弃率可以提供更强的正则化效果,但可能会降低模型的训练速度和预测性能,而较小的丢弃率则可能不足以减少过拟合。因此,建议从较小的丢弃率开始,例如 0.1 或 0.2,然后逐渐增加丢弃率,直到在验证集上达到最佳性能为止。
2.5 增加训练数据量
- 通过增加训练数据量,从而减少模型在训练集上的过拟合风险,提高模型的泛化能力。

- 给模型来一点大数据(
Big Data)的调教。😆😆😆
2.6 其他
- 模型复杂度控制:通过减少模型的层数、节点数或卷积核的个数等方式降低模型的复杂度,从而减小过拟合的风险。
- 批标准化(
Batch Normalization):在网络的每一层输入进行归一化,从而加速网络的收敛速度,降低模型在训练数据上的过拟合风险。 - 模型集成(
Model Ensemble):通过组合多个不同的模型,如集成学习、模型融合等方式,从而提高模型的泛化能力。 - 超参数调优(
Hyperparameter Tuning):调整模型的超参数,如学习率、批大小、正则化强度等,通过搜索最佳的超参数组合,从而改善模型的性能。 - 异常检测(
Anomaly Detection):通过识别和过滤掉异常或噪声样本,从而减少对异常样本的拟合,提高模型的泛化能力。 - 迁移学习(
Transfer Learning):将在一个领域或任务上训练好的模型迁移到另一个领域或任务上,并进行微调,从而利用 已有的知识来提高模型的泛化能力。
以上方法可以单独或者组合使用,具体的选择和调参需要根据具体的问题和数据集来定,以获得最佳的效果。

3. Supplement💘
测试集上的准确率比训练集上的稍微差一点,是不是过拟合了?
- 如果您的模型在测试集上的准确率略低于在训练集上的准确率,这并不能直接说明模型存在过拟合。在实际应用中,测试集上的性能可能会略低于训练集,这是比较常见的现象。
- 因为测试集和训练集之间可能存在一定的差异,例如数据分布、噪声等。模型在训练集上学到的特征在测试集上可能不一定能够完全泛化。
我的模型训练了10个 epoch,最后一个 epoch 的验证集准确率不是最高的,是过拟合了吗?
- 如果最后一个 epoch 的准确率不是最高的,这并不一定意味着过拟合。过拟合通常表现为训练集上的准确率很高,但在验证集或测试集上的准确率较低。你可以检查一下模型在验证集或测试集上的表现,以确定是否出现过拟合。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)