
通俗易懂的NCE Loss
NCE loss : Noise Contrastive Estimation他的直观想法:把多分类问题转化成二分类。之前计算softmax的时候class数量太大,NCE索性就把分类缩减为二分类问题。之前的问题是计算某个类的归一化概率是多少,二分类的问题是input和label正确匹配的概率是多少。问题:通常训练例如word2vec的时候,我们最后用full softmax预...
NCE loss : Noise Contrastive Estimation
他的直观想法:把多分类问题转化成二分类。
之前计算softmax的时候class数量太大,NCE索性就把分类缩减为二分类问题。
之前的问题是计算某个类的归一化概率是多少,二分类的问题是input和label正确匹配的概率是多少。
问题:
通常训练例如word2vec的时候,我们最后用full softmax预测出下一个词,真实的值通常是一小部分context words,也就是一小部分target classes,在非常大的语料库中(通常维度为百万),softmax需要对每一个class预测出probability,那么类别总数非常大的时候,这个计算量就非常大。
优化:
我们可不可以针对这么昂贵的计算 进行优化,不计算所有class的probability,但同时给我们一个合理的loss? 这里就引入了NCE(Noise-contrastive estimation):
对于每一个训练样本(x, T),我们训练binary classification,而不是multiclass classification。具体一点,我们对于每个样本,拆分成一个真实的(x,y)pair,另外我们随机产生k个Noise的(x,y)pair,这样我们就可以用来训练处这样的binary classifier。
(from Stephan Gouws' PhD Dissertation)
用概率来表示,这个问题由之前的P(y|x) 通过x预测所有y,换成了P(x,y),计算x,y同时存在的概率。
具体到Tensorflow
nce_loss里面有一个参数:
num_sampled: Anint. The number of negative classes to randomly sample per batch. This single sample of negative classes is evaluated for each element in the batch.
这一个参数就是用来控制我这里说到的k的hyperparameter.
另外training和testing的时候,还不一样,在于:
training的时候我们使用nce loss,可以减少计算量,但testing的时候,我们通常使用sigmoid cross entropy,因为我们还是要衡量所有可能class的probability,在所有可能结果中做选择。
更深入的拓展:
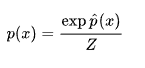
我们求和的其实也是下面的分母,也就是一个归一化常数
NCE解决了归一化项(中积分,或太多项和)无法计算的问题。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)