
使用YoloV5模型训练自己的数据集(全流程详细记录并附代码)
验证pytorch安装结果的步骤为:1、使用Pycharm打开yolov5项目:点击File→Settings→Project:yolov5-master→Python Interpreter,然后再点击右侧齿轮旁边的下拉箭头,点击Show All,选择刚刚新建的yolov5环境。在制作好自己的数据集之后,下一步就是修改yolov5-master\data目录下的yaml文件,将其中的train和
使用YoloV5模型训练自己的数据集(全流程详细记录并附代码)
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
一、安装环境
默认已安装Pycharm和Conda,相关准备工作都已经做好。如需要安装MiniConda可参考:https://blog.csdn.net/m0_49663564/article/details/125889670
首先下载YoloV5源码,下载解压后的文件夹目录如下所示(记住项目路径,例如D:\PythonPrj\yolov5-master):
打开Anaconda Prompt对话框,输入如下命令展示出当前所有的环境。
conda env list
然后输入以下命令新建一个名字为yolov5的环境。
conda create -n yolov5 python=3.7
在对话框内输入以下命令来激活yolov5环境。
conda activate yolov5
为了下载包的速度更快,需要配置国内镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
首先手动安装pytorch,至于如何选择cuda版本等信息可以去官网参考一下。我是按照B站UP主的推荐安装的版本,详情见此链接https://www.bilibili.com/video/BV1YL4y1J7xz/?p=4&spm_id_from=pageDriver&vd_source=94f79d8adeec4791b8751d7cb539ce55
pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
执行安装pytorch的命令后发现如下报错:
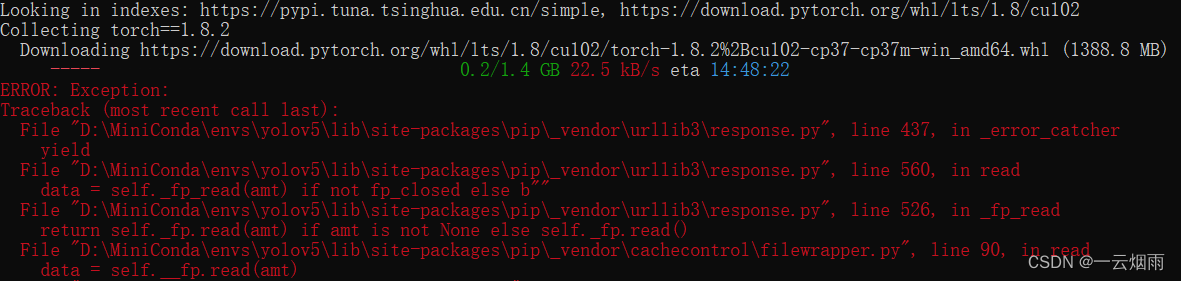
上述错误可以通过更新pip命令解决,执行以下命令即可。
python -m pip install --upgrade pip
随后再次执行安装pytorch的命令就可以顺利安装pytorch。
pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
验证pytorch安装结果的步骤为:1、使用Pycharm打开yolov5项目:点击File→Settings→Project:yolov5-master→Python Interpreter,然后再点击右侧齿轮旁边的下拉箭头,点击Show All,选择刚刚新建的yolov5环境
2、然后新建一个python文件执行以下代码,通过代码的返回结果即可验证pytorch的安装结果。
import torch
if __name__ == '__main__':
print(torch.__version__)
print(torch.cuda.is_available())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("using {} device".format(device))
接下来安装yolov5项目所需要的包,路径为一开始所说的项目路径,requirements.txt中需要将numpy的版本固定改为numpy==1.20.3。
pip install -r D:\PythonPrj\yolov5-master\requirements.txt
稍等片刻,安装完之后可使用以下命令来展示当前环境下所有的包。
pip list
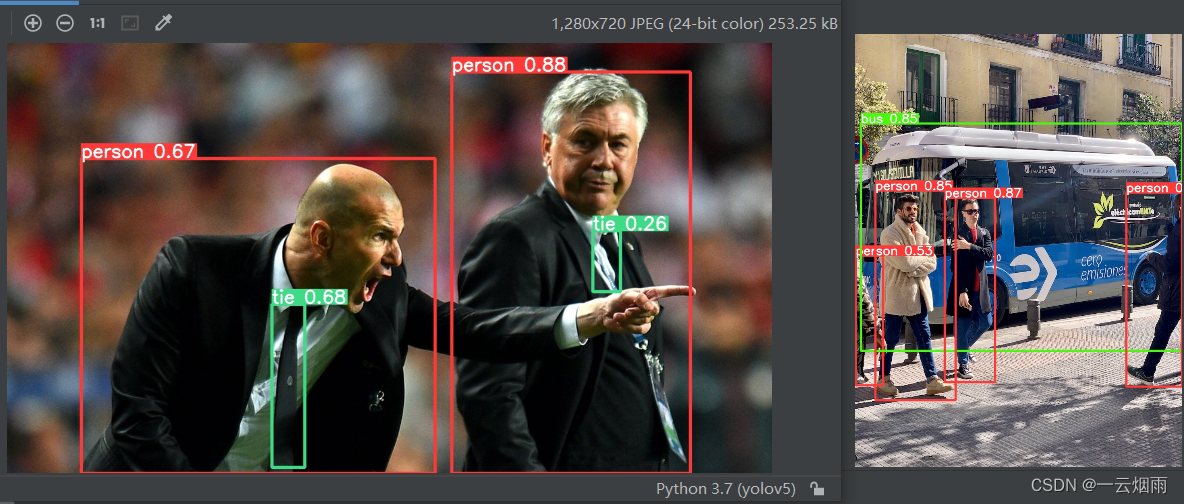
至此,yolov5环境的安装过程已经完成。在pycharm中或者Anaconda Prompt对话框成功运行detect.py文件,得到两张测试图片的检测结果,就表示环境没有问题。
二、制作自己的数据集
首先将图片数据集分为训练集train、验证集val、测试集test三类,然后通过三个txt文件定义三类集合图片的路径(可以是绝对路径也可以是相对路径),如下图所示。
三个label文件夹内存放的是各自集合所对应的标签。
如果下载的数据集或者自己制作的数据集数据量较大,并且未区分训练集验证集测试集的话,可以参考以下代码自行进行拆分(训练集、验证集、测试集的比例为7:2:1):
import os
import random
import shutil
def mkdir(path):
folder = os.path.exists(path)
if not folder: # 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) # makedirs 创建文件时如果路径不存在会创建这个路径
if __name__ == '__main__':
dataset_dir = 'D:/PythonPrj/Dataset/dataset_v0_data/'
label_dir = 'D:/PythonPrj/Dataset/dataset_v0_label/'
ship_dataset_path = 'D:/PythonPrj/yolov5-master/data/'
val_rate = 0.2 # 从全部数据集中选择20%作为验证集
test_rate = 0.1
img_files = os.listdir(dataset_dir)
val_path = random.sample(img_files, k=int(len(img_files) * val_rate))
test_path = random.sample(img_files, k=int(len(img_files) * test_rate))
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
test_images_path = [] # 存储测试集的所有图片路径
test_images_label = [] # 存储测试集图片对应索引信息
for img_name in img_files:
label_name = img_name.split('.')[0] + '.txt'
if img_name in val_path: # 如果该路径在采样的验证集样本中则存入验证集
shutil.move(dataset_dir+img_name, ship_dataset_path+'images/val')
shutil.move(label_dir+label_name, ship_dataset_path+'labels/val')
elif img_name in test_path:
shutil.move(dataset_dir+img_name, ship_dataset_path+'images/test')
shutil.move(label_dir+label_name, ship_dataset_path+'labels/test')
else: # 否则存入训练集
shutil.move(dataset_dir+img_name, ship_dataset_path+'images/train')
shutil.move(label_dir+label_name, ship_dataset_path+'labels/train')
三、开始训练
在制作好自己的数据集之后,下一步就是修改yolov5-master\data目录下的yaml文件,将其中的train和val路径改为自己数据集的路径,将其中的class改为自己数据集包含的数据类型和对应的名称。
然后在train.py文件中将以下几个配置根据自己数据集、电脑配置的实际情况进行修改:
parser.add_argument('--data', type=str, default=ROOT / 'data/mydata.yaml', help='dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch')
然后就可以开始训练了~

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)