

基于ResNet18网络训练二分类模型
图像二分类是指将图像分为两个类别的任务,通常分为正类和负类。在训练过程中,使用监督学习算法和各种机器学习模型来学习特征差异,并使用精确度、召回率、F1-score等指标进行评估。图像二分类有许多应用,例如人脸识别、疾病检测、文本分类等。本文介绍了基于ResNet18网络的训练蜜蜂和蚂蚁图像的二分类模型的过程。
目录
一、背景介绍
图像二分类是指将图像分成两个类别的任务,通常是将图像分为“正类”和“负类”。其中,正类指需要分类的目标,负类则是其他不需要分类的图像。
图像二分类一般使用监督学习算法,需要先准备带有标签的训练数据集。在训练过程中,算法会从训练数据集中学习到类别之间的特征差异,可以使用各种机器学习模型,如决策树、支持向量机、神经网络等。
对于一个新的待分类图像,算法使用从训练数据集中学到的模型来预测它属于哪一类别。常用的评估指标包括精确度(accuracy)、召回率(recall)、F1-score等。
图像二分类有许多应用,例如人脸识别、疾病检测、文本分类等。同时,图像二分类也是计算机视觉领域的一个重要问题。
本文是基于ResNet18的蜜蜂和蚂蚁的二分类训练,包括数据模块构建、网络构建、模型训练
在分类模型训练过程中,需要注意以下几点:
1. 数据集的质量和数量:数据集的质量和数量对模型的训练效果有很大的影响。如果数据集不够大或者不够丰富,那么模型的泛化能力就会比较差。
数据增强提高数据的多样性:指通过对已有数据添加微小改动或从已有数据新创建合成数据,以增加数据量的方法。数据增强可以分为有监督的数据增强和无监督的数据增强方法。其中有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法,无监督的数据增强分为生成新的数据和学习增强策略两个方向。
常见的有监督数据增强方法包括:旋转、翻转、缩放、裁剪、平移等;常见的无监督数据增强方法包括:随机扰动、颜色抖动、亮度调整等。
2. 数据预处理:数据预处理包括数据清洗、特征选择、特征提取等步骤。这些步骤可以帮助我们更好地理解数据,并且可以提高模型的训练效果。
3. 模型的选择和调参:不同的模型有不同的优缺点,我们需要根据具体的问题来选择合适的模型。在调参方面,我们可以通过交叉验证等方法来找到最优的参数组合。
4. 防止过拟合:过拟合是指模型在训练集上表现良好,但在测试集上表现不佳的情况。为了避免过拟合,我们可以采用一些方法,如增加数据量、使用正则化等。
如果遇到过拟合的情况:过拟合是指模型在训练集上表现良好,但在测试集上表现不佳的情况。为了避免过拟合,我们可以采用一些方法,如增加数据量、使用正则化等。
以下是一些常见的过拟合处理方法:
1. 增加数据量:增加数据量可以减少过拟合的风险,因为更多的数据可以帮助模型更好地学习特征。
2. 使用正则化:正则化是一种常用的防止过拟合的方法,它通过在损失函数中添加一个正则项来惩罚大的权重值。这样可以使模型更加平滑,并且可以减少过拟合的风险。
3. 早停:早停是一种简单而有效的防止过拟合的方法。它通过监控验证集误差来判断模型是否过拟合,并在验证集上的性能不再提高时停止训练。

二、数据构建
数据介绍:train+val(内部分别以ants和bees文件夹命名,对应类别),这个数据在网上可以下载到。
import torch
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import os
# 数据增强
data_transforms = {
'train':transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪然后调整大小
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
'val':transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
# 加载数据:子文件夹中的目录会作为一个类别
data_dir = "./data/hymenoptera_data"
image_datasets = {p:datasets.ImageFolder(os.path.join(data_dir,p),data_transforms[p]) for p in ['train','val']}
dataset_sizes = {x:len(image_datasets[x]) for x in ["train","val"]}
print(image_datasets["train"].classes) # 查看训练集的类别
dataloaders = {x:torch.utils.data.DataLoader(image_datasets[x],batch_size=4,shuffle=True,num_workers=4) for x in ["train","val"] }
class_names = image_datasets["train"].classes输出:
['ants', 'bees']数据可视化:
Python中常用的加载并展示图像的包有:
1. PIL(Python Imaging Library):PIL是Python的一个图像处理库,支持打开、操作和保存许多不同格式的图像文件。
2. OpenCV:OpenCV是一个开源的计算机视觉库,它包含了许多常用的图像处理功能,如图像读取、显示、保存等。
3. Matplotlib:Matplotlib是一个用于绘制二维图表和图形的库,它可以与PIL或OpenCV结合使用,方便地展示图像。
4. Seaborn:Seaborn是基于Matplotlib的数据可视化库,提供了更高级的统计图形绘制功能,可以方便地展示图像。
前三个在处理图像中用的比较多
注意:PIL和OpenCV读取的图像通道格式不一样。PIL是一个图像处理库,它支持打开、操作和保存许多不同格式的图像文件,包括JPEG、PNG、BMP等。而OpenCV是一个开源的计算机视觉库,它包含了许多常用的图像处理功能,如图像读取、显示、保存等。在使用上,PIL更适合于简单的图像处理任务,如裁剪、缩放、旋转等;而OpenCV则更适合于复杂的图像处理任务,如特征提取、目标检测等 。
在OpenCV中,图像通道顺序为BGR(蓝色、绿色、红色),而在PIL中,图像通道顺序为RGB(红、绿、蓝) 。这里有时候自定义图像加载模块的时候需要根据情况调整通道顺序
可以采用numpy提供的transpose调整通道顺序:
其中参数
axes可以指定新的通道顺序。例如,如果你有一个形状为(height, width, channels)的数组,你可以使用np.transpose(arr, (1, 2, 0))来将第一个通道移到最后,第二个通道移到第一个,第三个通道移到第二个。这里的arr是一个三维数组,其中第一个维度是高度,第二个维度是宽度,第三个维度是通道数。
# 显示图片
import numpy as np
import torchvision
import matplotlib.pyplot as plt
def imshow(img,title=None):
# 可视化一组tensor的图片,调整通道维数
img = img.numpy().transpose([1,2,0])
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
img = std*img + mean
# np.clip(img,0,1)是将图像img中的像素值限制在0到1之间。这个函数可以用于图像处理中,将图像的像素值限制在一个范围内,以便进行后续的处理 。
img = np.clip(img,0,1)
plt.imshow(img)
if title is not None:
plt.title(title)
plt.pause(0.001)
#获取一批训练数据
inputs,classes = next(iter(dataloaders["train"]))
# 批量制作网格
out = torchvision.utils.make_grid(inputs)
imshow(out,title=[class_names[x] for x in classes])
三、模型构建及训练
ResNet18是一种深度卷积神经网络,它由残差块(Residual Block)组成。每个残差块包含两个卷积层和一个跳跃连接(Skip Connection),跳跃连接可以让信息在网络中更快地传递。ResNet18 具有 18 层,其中包括 16 个卷积层和 2 个全连接层。
其中,根据Block类型,可以将这五种ResNet分为两类:(1) 一种基于BasicBlock,浅层网络ResNet18, 34都由BasicBlock搭成;(2) 另一种基于Bottleneck,深层网络ResNet50, 101, 152乃至更深的网络,都由Bottleneck搭成。
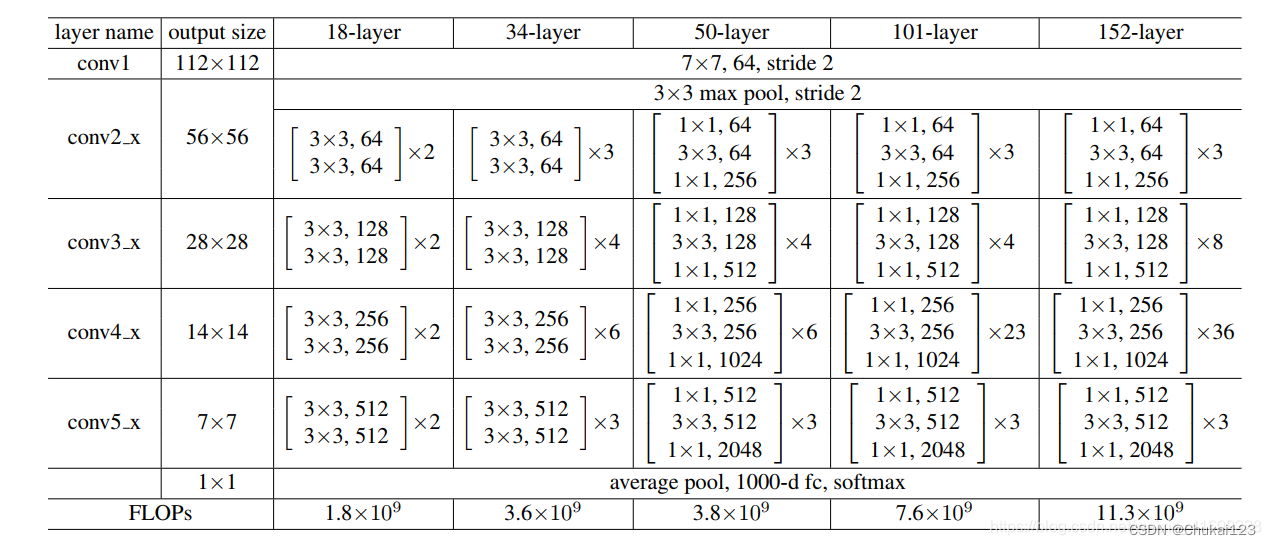
ResNet18的网络结构如下所示

其中的Skip Connection 可以避免梯度消失的问题,因为在 ResNet 中,每个残差块包含两个卷积层和一个跳跃连接(Skip Connection),跳跃连接可以让信息在网络中更快地传递。具体来说,当输入经过第一个卷积层和第一个池化层后,会通过一个全连接层进行特征映射,然后经过第二个卷积层和第二个池化层后,会通过一个全连接层进行特征映射。这两个全连接层的输出会分别与原始输入相加,形成两个新的输出。这样做的好处在于可以增加模型的表达能力和稳定性。
在深度神经网络中,梯度消失问题是一个普遍存在的问题。梯度消失问题指的是在反向传播过程中,梯度会逐层乘以权重矩阵,导致梯度不断缩小,最终消失。而 ResNet 中的跨层连接可以直接将输入的梯度传递到后面的层,从而避免了梯度消失的问题 。下图为skip-connection图
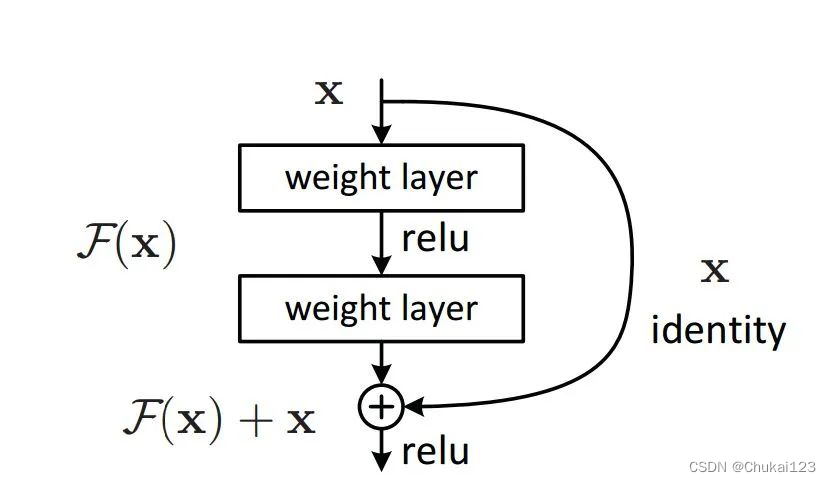
代码实现:
下面为完整的训练模块,这段代码实现了一个训练模型的函数train_model(),使用了预训练的ResNet18模型,并使用交叉熵损失函数和SGD优化器进行训练。在每个epoch结束后,根据验证集上的性能更新最佳模型参数,并将训练过程中的损失值和准确率记录到TensorBoard中。最后,将训练好的模型保存到文件中。
import time
import copy
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.cuda.empty_cache()
# 开始训练
def train_model(model,criterion,optimizer,scheduler,num_epochs=25):
writer = SummaryWriter()
ep_losses,ep_acces = [],[]
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f"Epoch {epoch}/{num_epochs-1}")
print("_"*10)
# 训练和验证交替传播
for phase in ["train","val"]:
if phase == "train":
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs,labels in dataloaders[phase]:
inputs = inputs.to(device=device)
labels = labels.to(device=device)
# 清空梯度,避免累加了上一批次的梯度
optimizer.zero_grad()
with torch.set_grad_enabled(phase=="train"):
# 正向传播
outputs = model(inputs)
_,preds = torch.max(outputs,1)
loss = criterion(outputs,labels)
# 反向传播且仅在训练阶段进行优化
if phase == "train":
loss.backward() # 反向传播
optimizer.step()
# 统计loss和准确率
running_loss += loss.item()*inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == "train":
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
ep_losses.append(epoch_loss)
ep_acces.append(epoch_acc.item())
print(f"{phase} Loss: {epoch_loss:.4f} {phase} Acc:{epoch_acc:.4f}")
# 记录更优的模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
# 打印本次epoch的训练、验证损失值和准确率
writer.add_scalars("loss",{'train':ep_losses[-2],"val":ep_losses[-1]},global_step=epoch)
writer.add_scalars("acc",{'train':ep_acces[-2],"val":ep_acces[-1]},global_step=epoch)
writer.close()
time_elapsed = time.time() - since
print(f"training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s")
print(f"best val ACC:{best_acc:.4f}")
# 加载训练的最好的模型
model.load_state_dict(best_model_wts)
torch.save(model.state_dict(),"./model/best_resnet18_model_param.pth")
return model
这里采用torchvision.models提供的ResNet18
3.1 采用预训练的权重进行训练
加载预训练的ResNet18模型,并打印出所有层的参数和最后一个全连接层的特征维度。由于本文使用的数据为两个类别,所以将最后一个全连接层替换为一个线性层,输出维度设置为2。然后将模型移动到指定的设备上(GPU或CPU)。
定义损失函数为交叉熵损失函数,优化器为随机梯度下降(SGD),学习率为0.001,动量为0.9。同时定义了一个学习率调度器StepLR,每7个批次后将学习率乘以0.1。最后调用train_model函数进行模型训练,训练的总轮数为25。
采用预训练模型的权重进行训练模型的好处是可以节省训练新模型的时间和资源,因为预训练权重已经包含了一些通用的图像特征和检测能力,可以捕捉通用的特征和模式,从而帮助网络更快地收敛和更好地泛化到新的数据。此外,预训练权重还可以避免需要从头开始训练一个大型神经网络所需的时间和计算资源 。
预训练模型的权重进行训练新数据的缺点包括:
1、无法适应新的数据集:预训练模型是在特定的数据集上进行训练的,因此它们可能无法很好地适应新的数据集。如果新数据集与预训练模型所使用的数据集不同,那么预训练模型的性能可能会受到影响。
2、需要大量的计算资源:预训练模型通常需要大量的计算资源来进行训练,包括高性能的计算机、存储设备和网络带宽等。这使得在一些资源受限的环境中使用预训练模型变得困难。
import torchvision.models as models
import torch.nn as nn
import pandas as pd
import torch.optim as optim
# 运行前先清空显存占用
torch.cuda.empty_cache()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 预训练模型的所有参数都参与训练
model = models.resnet18(pretrained=True)
print(model.parameters) # 所有层的参数
num_ftrs = model.fc.in_features # 获取低级特征维度
print(num_ftrs) # 512最后一个fc层的特征维度
model.fc = nn.Linear(num_ftrs,2) # 本文使用的数据为两个类别,所以设置为2
model = model.to(device=device)
# 新的model中最后一个fc层的out_feature维数变成2
print(model.parameters)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
# 每个7个批次学习率变为原来的lr*0.1
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=7,gamma=0.1)
model = train_model(model,criterion,optimizer,scheduler,num_epochs=25)输出:
<bound method Module.parameters of ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
...
train Loss: 0.2849 train Acc:0.8893
val Loss: 0.2365 val Acc:0.9346
training complete in 2m 52s
best val ACC:0.95423.2 固定模型的参数,训练过程中不更新
固定模型参数的目的是为了在训练过程中只更新需要更新的部分,从而提高模型的训练效率。在PyTorch中,可以通过将需要更新的参数的requires_grad属性设置为False来固定这些参数,而将不需要更新的参数的requires_grad属性设置为True来允许它们进行更新。这样,在反向传播过程中,只有需要更新的参数会被计算梯度并更新,而不需要更新的参数则不会受到影响 。
采用这种思路,可以将模型除了输出层之外的所有层看成一个特征提取器,训练的时候,这些层的权重不参与训练,不可优化。
具体实现:
# 固定模型的参数进行训练
import torchvision.models as models
import torch.nn as nn
import pandas as pd
from sklearn.metrics import roc_auc_score
import torch.optim as optim
# 运行前先清空显存占用
torch.cuda.empty_cache()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 固定参数
model = models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
print(model.parameters) # 所有层的参数
num_ftrs = model.fc.in_features # 获取低级特征维度
model.fc = nn.Linear(num_ftrs,2) # 本文使用的数据为两个类别,所以设置为2
model = model.to(device=device)
# 新的model中最后一个fc层的out_feature维数变成2
print(model.parameters)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
# 每个7个批次学习率变为原来的lr*0.1
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=7,gamma=0.1)
model = train_model(model,criterion,optimizer,scheduler,num_epochs=25)输出:
<bound method Module.parameters of ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
...
train Loss: 0.3926 train Acc:0.8197
val Loss: 0.2191 val Acc:0.9150
training complete in 2m 37s
best val ACC:0.9542当前这种方法在的训练效果识别ACC基本没区别
3.3 如何保存训练好的模型?
# 保存模型
model.eval()
# 打印保存前模型的预测值
with torch.no_grad():
print(f"预测前:{model(inputs).reshape(-1)[:5]}")
# 保存模型
torch.save(model.state_dict(),"./model/model.pth")
# 加载模型
state_dict = torch.load("./model/model.pth") # map_location="cpu"
save_model = LeNet()
save_model.to(device)
save_model.eval() # 将dropout,batch normalization层设置为评估状态
# 将状态字典应用到网络模块,并打印加载后模型的预测值
save_model.load_state_dict(state_dict)
with torch.no_grad():
print(f"预测后:{save_model(inputs).reshape(-1)[:5]}")
# 通过state_dict查看某一层的网络信息
print(state_dict["fc1.weight"])输出:
预测前:tensor([ 3.6763, -0.1227, -0.1868, -2.0402, 0.9410], device='cuda:0')
预测后:tensor([ 3.6763, -0.1227, -0.1868, -2.0402, 0.9410], device='cuda:0')
tensor([[-0.0033, -0.0254, 0.0288, ..., 0.0268, -0.0294, -0.0517],
[-0.0442, -0.0100, 0.0328, ..., 0.0184, -0.0362, -0.0142],
[-0.0105, -0.0134, 0.0689, ..., -0.0358, -0.0231, -0.0540],
...,
[ 0.0325, 0.0770, 0.0670, ..., -0.0675, 0.0162, -0.0295],
[-0.0360, -0.0619, 0.0199, ..., 0.0107, -0.0111, -0.0477],
[-0.0561, -0.0438, -0.0452, ..., 0.0059, -0.0030, 0.0999]],
device='cuda:0')3.4 如何查看可视化训练过程?
使用tensorboard
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorboard具体代码可以看train_model.py中代码实现,执行训练过程中会生成一个runs的日志文件,接着在runs的同级目录下执行
tensorboard --logdir runs通过浏览器网站:http://localhost:6000即可访问
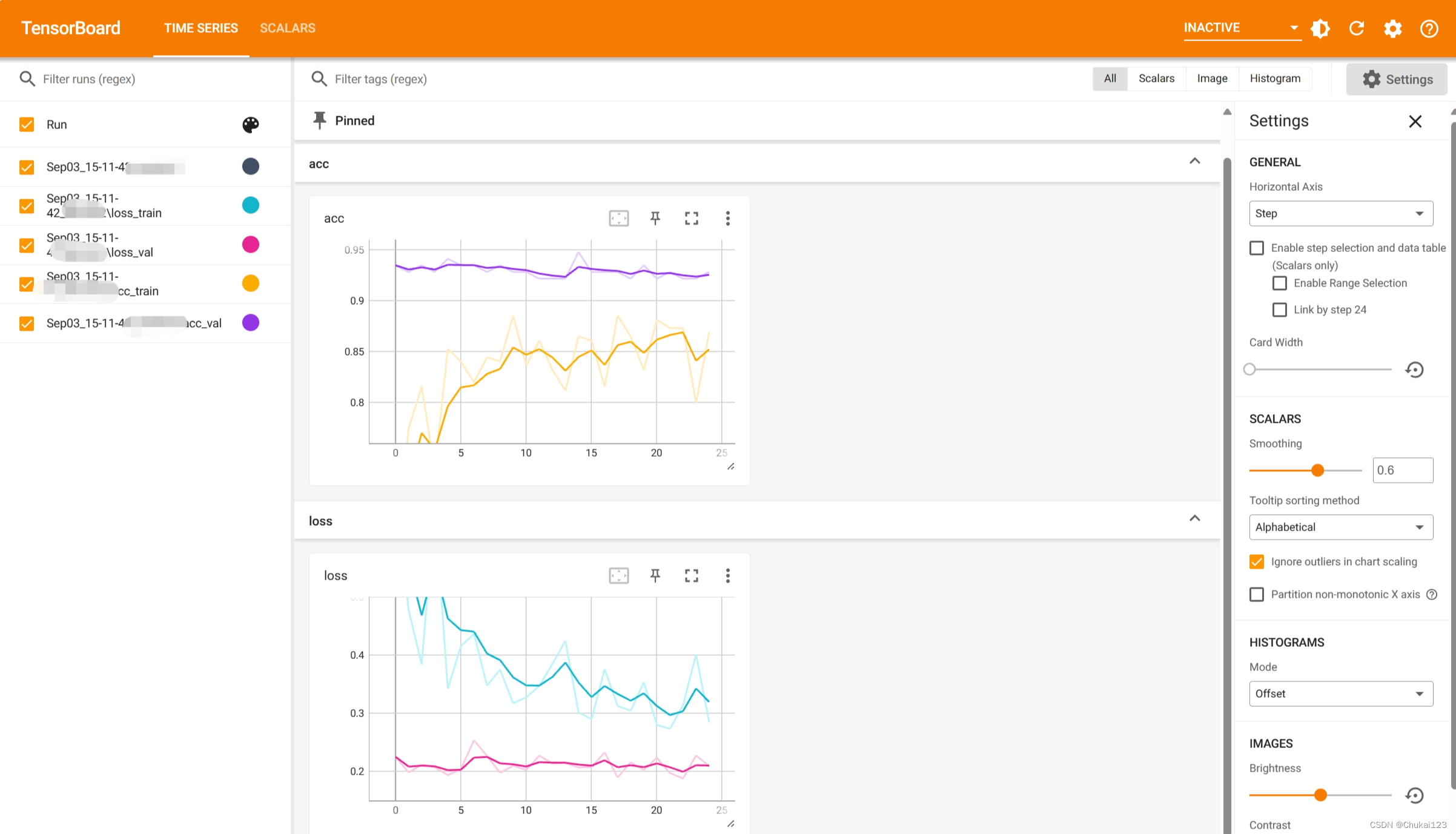
四、模型预测
要使用训练好的模型进行预测,需要执行以下步骤:
- 导入模型和数据。
- 将输入数据传递给模型。
- 从模型中获取预测结果。
这个过程可能会因模型而异,但是大多数模型都有类似的步骤。例如,如果您使用的是Python和PyTorch,则可以按照以下步骤操作:
import torch
from torchvision import models, transforms
# 加载模型
model = models.resnet18(pretrained=True)
# 加载数据
data = ...
# 定义预处理步骤
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 对数据进行预处理
input_tensor = transform(data)
# 添加一个批次维度
input_batch = input_tensor.unsqueeze(0)
# 传递数据并进行预测
with torch.no_grad():
output = model(input_batch)
# 获取预测结果
_, predicted = torch.max(output, 1)
按照上述流程完整本文的评估模型预测模块如下:
这段代码定义了一个名为evaluate的函数,用于评估一个训练好的模型。该函数接受两个参数:model表示要评估的模型对象,num_images表示要在图表中显示的图片数量,默认为6。
在函数内部,首先将模型的训练状态保存在train_flag变量中,并将`model`设置为评估模式(即关闭Dropout和BatchNorm层)。然后,使用torch.no_grad()上下文管理器来禁用梯度计算,以提高评估速度。
接下来,函数遍历验证数据集的数据加载器dataloaders["val"],对每个输入图像进行预测,并显示前num_images个预测结果。具体来说,对于每个输入图像,将其转移到设备上(如GPU),并通过模型获取输出。然后,使用torch.max()函数找到具有最高概率的类别作为预测结果。最后,使用Matplotlib库中的imshow()函数显示输入图像及其对应的预测结果。
如果已经显示了num_images个图像,则将模型恢复为训练模式,并退出函数。否则,继续遍历剩余的图像。
最后,调用evaluate(model)函数来评估模型。
# 评估模型
def evaluate(model,num_images=6):
train_flag = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i,(inputs,labels) in enumerate(dataloaders["val"]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs,1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2,2,images_so_far)
ax.axis("off")
ax.set_title("pred->{},label->{}".format(class_names[preds[j]],class_names[labels[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=train_flag)
return
model.train(mode=train_flag)
evaluate(model)





五、查看网络各层的参数
import torchvision.models as models
from torchinfo import summary
# 查看模型的参数
summary(model,(1,3,224,224))输出:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [1, 2] --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
...
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================六、可视化激活特征图
# 定义钩子函数,获取指定层名称的特征
activation = {} # 保存获取的输出
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
model = models.resnet18(pretrained=True)
# 从测试集中读取一张图片,并显示出来
from PIL import Image
img_path = './train/ants/0013035.jpg'
img = Image.open(img_path)
# 归一化到0-1之间
imgarray = np.array(img) / 255.0
plt.figure(figsize=(8,8))
plt.imshow(imgarray)
plt.axis('off')
plt.show()
transform = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 增加批次维度
input_img = transform(img).unsqueeze(0)
print(input_img.shape)
model.eval()
# 获取layer1里面的bn3层的结果,浅层特征
model.layer1[1].register_forward_hook(get_activation('bn1')) # 为layer1中第2个模块的bn3注册钩子
_ = model(input_img)
bn1 = activation['bn1'] # 结果将保存在activation字典中
print(bn1.shape)
# 可视化结果,显示前16张
plt.figure(figsize=(12,12))
for i in range(16):
plt.subplot(4,4,i+1)
plt.imshow(bn1[0,i,:,:], cmap='gray')
plt.axis('off')
plt.show()

torch.Size([1, 3, 224, 224])
torch.Size([1, 64, 56, 56])


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)