
YOLO改进:轻量级通用上采样算子CARAFE
使用CARAFE算子改进YOLOv5模型,将YOLOv5中的所有上采样操作替换,在保持较少参数增加的同时,提高模型的检测精度。在VisDrone数据集中进行测试。
YOLO改进:轻量级通用上采样算子CARAFE
CARAFE介绍
CARAFE算子的论文地址:[1905.02188] CARAFE: Content-Aware ReAssembly of FEatures (arxiv.org)
代码:Code
CARAFE算子,即内容感知特征重组算子,是一种即插即用的轻量级算子,其具有以下特点:
- 感受野大。能够聚合上下文信息。
- 内容感知。不是对所有样本使用固定的内核(例如反卷积),而是支持特定于实例的内容感知处理,从而动态生成自适应内核。
- 重量轻,计算速度快。CARAFE引入了很少的计算开销,并且可以很容易地集成到现代网络架构中。
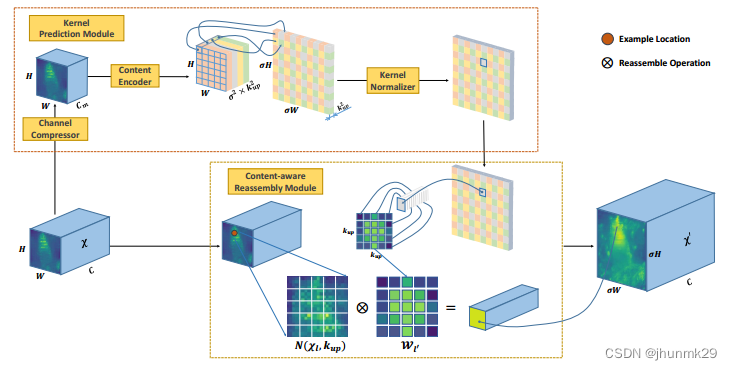
其计算过程包括两个步骤。第一步是根据每个目标位置的内容预测一个重组核,第二步是用预测的核对特征进行重组。主要由两个部分组成:核预测模块和内容感知的重组模块。核预测模块:由通道压缩器、内容编码器和核归一化器三个子模块生成上采样核。具体来说,通道压缩器是一个1 × 1的卷积,将输入特征图的通道进行缩减,以减少后续的计算量。内容编码器是一个尺寸为𝑘𝑢𝑝 × 𝑘𝑢𝑝的上采样核;如果要想在不同位置使用不同的上采样核,那么期望的上采样核的形状就是𝜎𝐻 × 𝜎𝑊 ×
𝑘𝑢𝑝 × 𝑘𝑢𝑝,即对于通道压缩器输出的特征图,使用一个𝑘𝑒𝑛𝑐𝑜𝑑𝑒𝑟 × 𝑘𝑒𝑛𝑐𝑜𝑑𝑒𝑟的卷积层来预测上采样核,这样可以得到更大的上采样核,而越大的上采样核代表着更大的感受野。核归一化器就是对上采样核使用SoftMax进行归一化。内容感知重组模块将输出特征图的每个位置映射回输入特征图,然后将以之为中心的𝑘𝑢𝑝 × 𝑘𝑢𝑝的区域与预测出该点的上采样核做点积操作,得到输出特征图。内容感知重组模块可以使局部区域中相关的特征信息得到更多的关注,重组后的特征图比原有的特征图具有更多的语义信息。
CARAFE代码
'''
https://arxiv.org/abs/1905.02188
c:输入通道数
scale:上采样扩大尺寸倍数,h*w -> (h*scale)*(w*scale)
'''
class CARAFE(nn.Module):
def __init__(self, c, k_enc=3, k_up=5, c_mid=64, scale=2):
""" The unofficial implementation of the CARAFE module.
The details are in "https://arxiv.org/abs/1905.02188".
Args:
c: The channel number of the input and the output.
c_mid: The channel number after compression.
scale: The expected upsample scale.
k_up: The size of the reassembly kernel.
k_enc: The kernel size of the encoder.
Returns:
X: The upsampled feature map.
"""
super(CARAFE, self).__init__()
self.scale = scale
self.comp = Conv(c, c_mid)
self.enc = Conv(c_mid, (scale * k_up) ** 2, k=k_enc, act=False)
self.pix_shf = nn.PixelShuffle(scale)
self.upsmp = nn.Upsample(scale_factor=scale, mode='nearest')
self.unfold = nn.Unfold(kernel_size=k_up, dilation=scale,
padding=k_up // 2 * scale)
def forward(self, X):
b, c, h, w = X.size()
h_, w_ = h * self.scale, w * self.scale
W = self.comp(X) # b * m * h * w
W = self.enc(W) # b * 100 * h * w
W = self.pix_shf(W) # b * 25 * h_ * w_
W = torch.softmax(W, dim=1) # b * 25 * h_ * w_
X = self.upsmp(X) # b * c * h_ * w_
X = self.unfold(X) # b * 25c * h_ * w_
X = X.view(b, c, -1, h_, w_) # b * 25 * c * h_ * w_
X = torch.einsum('bkhw,bckhw->bchw', [W, X]) # b * c * h_ * w_
return X
引入YOLOv5中
在common.py中添加上面的class CARAFE
在yolo.py的parse_model()函数中添加如下代码
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif m is CARAFE:
c2 = ch[f]
args = [c2, *args]
将YOLOv5的上采样全部换成该算子:
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, CARAFE, [3, 5]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, CARAFE, [3, 5]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
注意:参数3、5是可以修改的,在原论文中有以下参数可以选择,其中3、5是论文中认为最好的参数,可以根据自己的数据集测试和调整。

VisDrone实验
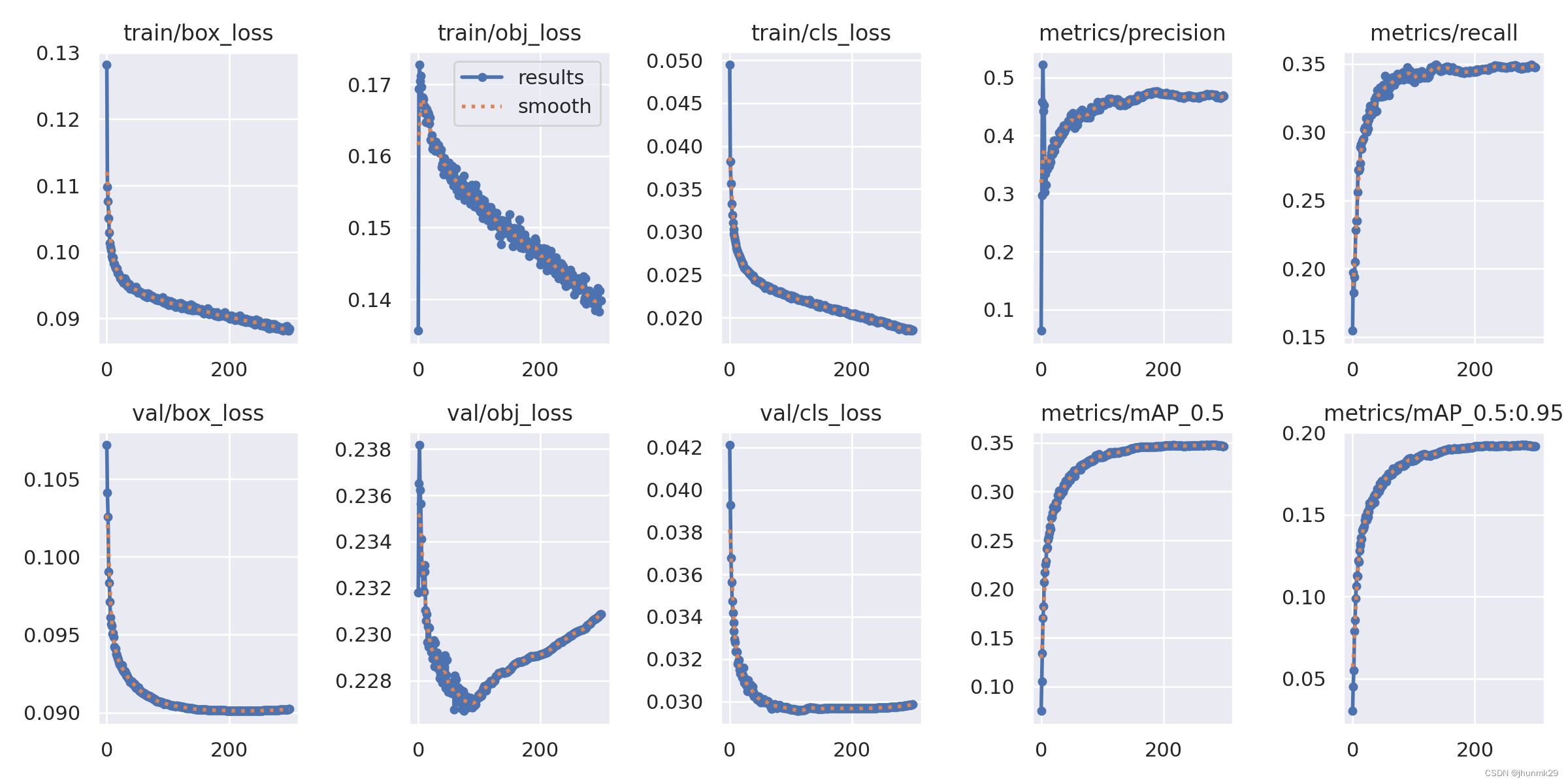
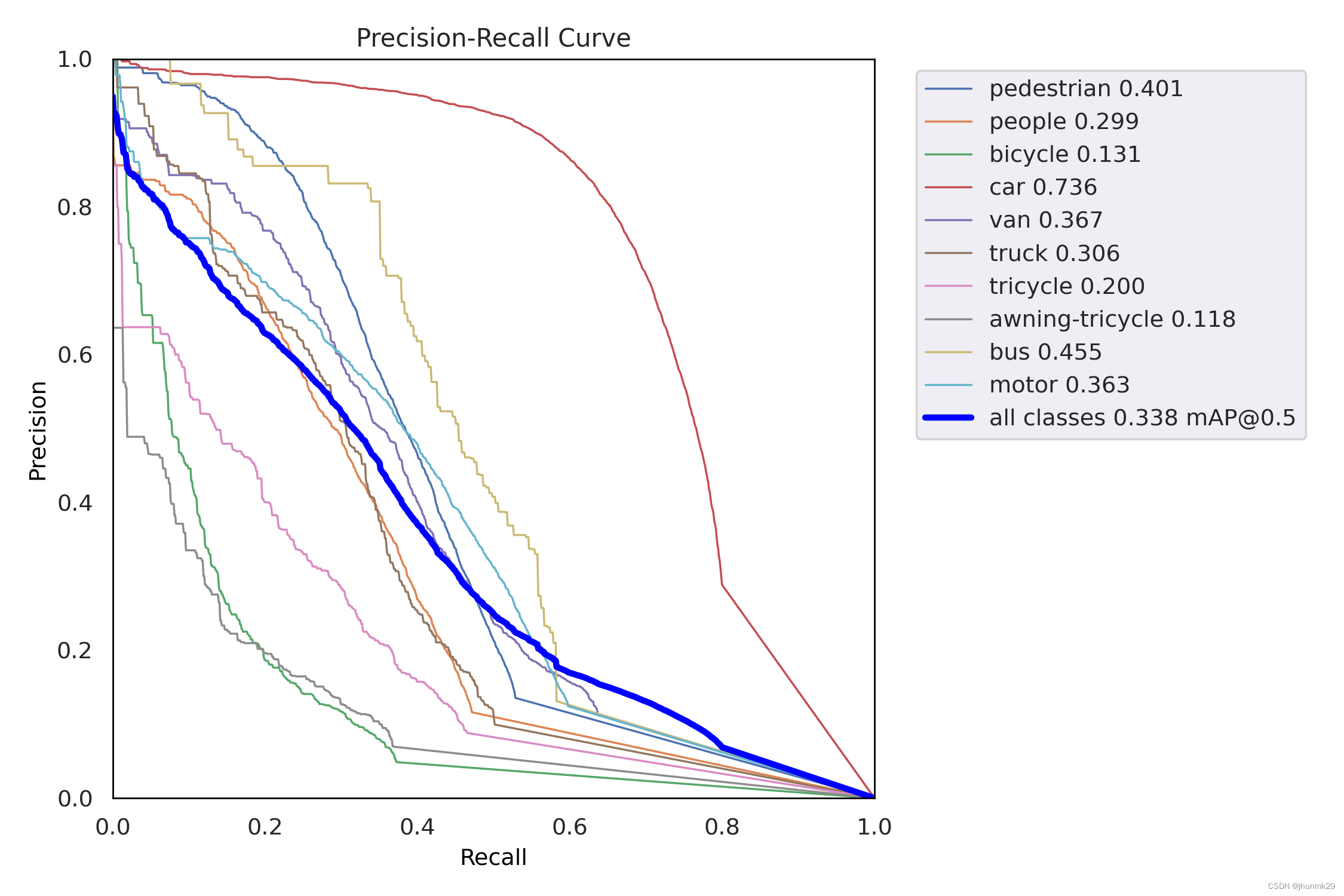
在VisDrone数据集进行测试,使用YOLOv5s模型作为基准模型,VisDrone数据集在YOLOv5s中的mAP为32.9%。将上采样换位CARAFE算子,其余超参数保持一致,改进后的YOLOv5s模型的mAP为33.8%,提高了将近1%的mAP,说明该算子具有比好的效果。


实验模型下载链接
百度云
提取码:j7zw

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)