
多目标跟踪算法原理(Sort&DeepSort&ByteTrack)
多目标跟踪目前主要应用于视频监控、自动驾驶、无人机监测等方面,实现人流量和车流量的统计、行人的轨迹预测等功能。对于跟踪,算法并不知道自己跟踪的目标内容是什么,它只负责跟踪。而想要知道具体的内容,就要通过重识别技术。
目录
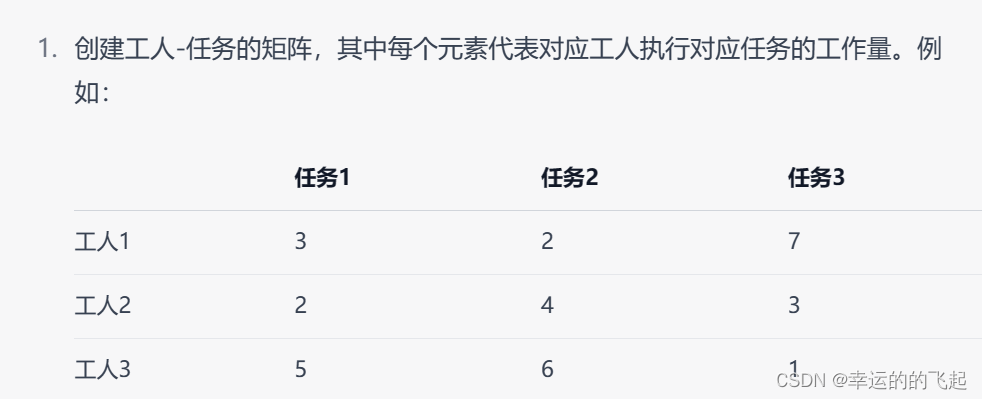
举个实例:假设有3个工人和3个任务,每个工人可以完成每项任务的不同工作量。我们的目标是将工人分配到任务上,使得总工作量最小。
前言:
多目标跟踪目前主要应用于视频监控、自动驾驶、无人机监测等方面,实现人流量和车流量的统计、行人的轨迹预测等功能。
主要步骤:
- 获取原始视频帧
- 利用目标检测器对视频帧中的目标进行检测
- 将检测到的目标的框中的特征提取出来
- 计算前后两帧目标之间的匹配程度
一、Sort算法
流程图:
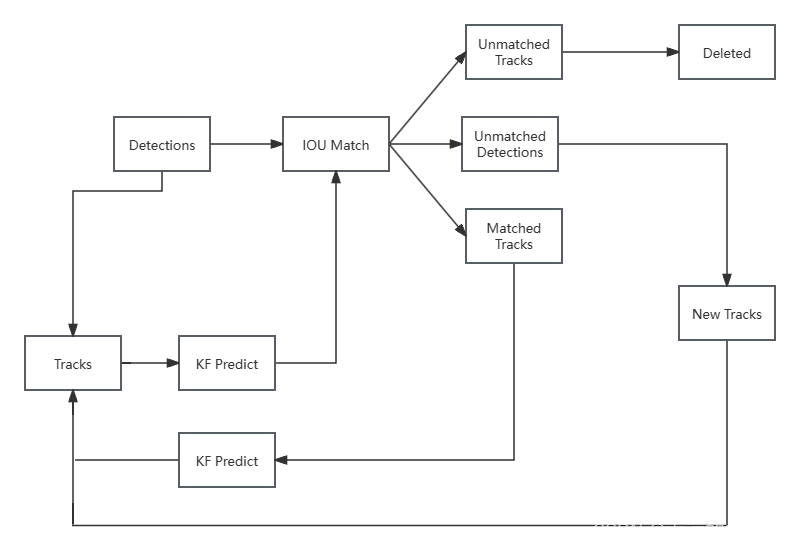
注:Detections:目标检测框;Tracks:轨迹信息(外观特征和运动信息)
算法步骤:
第一帧:检测器(Yolo、faster-rcnn)生成的所有目标框(Detections),所有的目标框将生成新的轨迹(Tracks),通过卡尔曼滤波算法进行下一帧的预测。
第二帧:预测框与检测框通过IOU Match(相似度计算)进行匹配。
匹配成功后就会更新目标的轨迹,即将预测框更新为目标框位置的值,更新完后,就会进行下一帧的预测;如果匹配不成功,会出现两种情况,一种是未匹配的轨迹(多出预测框),直接删除(默认为30帧匹配不上);一种是未匹配的目标框(多出检测框,即新的目标出现),会创建出一种新的轨迹,再次进行匹配。
知识掌握:
Sort算法采用IOU进行匹配,核心算法为卡尔曼滤波算法和匈牙利算法。
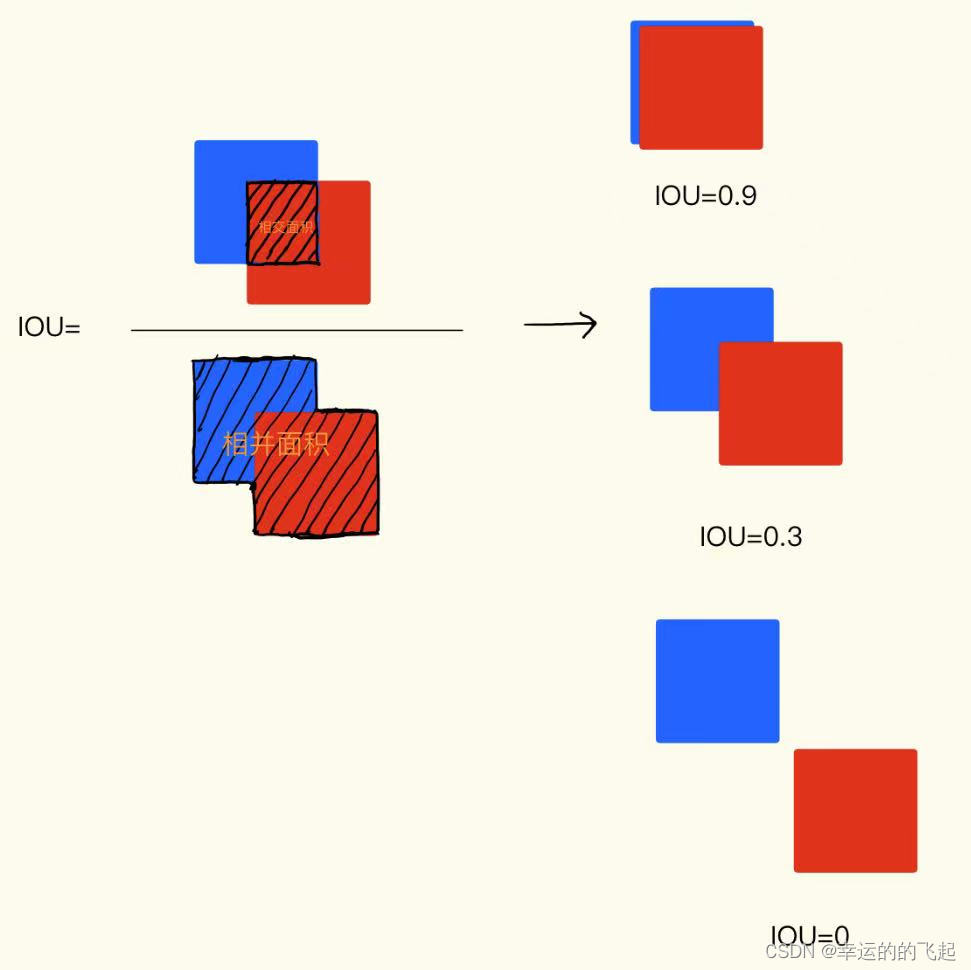
IOU匹配:
简单来说,通过计算两个框的交集区域与并集区域的比值来评估它们的匹配程度。
卡尔曼滤波算法:
主要作用就是目标框的预测。根据当前的目标框去预测下一时刻的目标框的位置(更新均值、协方差矩阵)
匈牙利算法:
解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。IOU Match反馈结果给匈牙利算法,匈牙利算法来进行一一匹配。
具体流程:
假设有N个人和N个任务,每个任务可以任意分配给不同的人,已知每个人完成每个任务要花费的代价不尽相同,那么如何分配可以使得总的代价最小,即实现最优匹配。
N个人完成N项任务所需的代价不同,构成一个N*N的矩阵。
算法步骤(假设矩阵为NxN方阵):
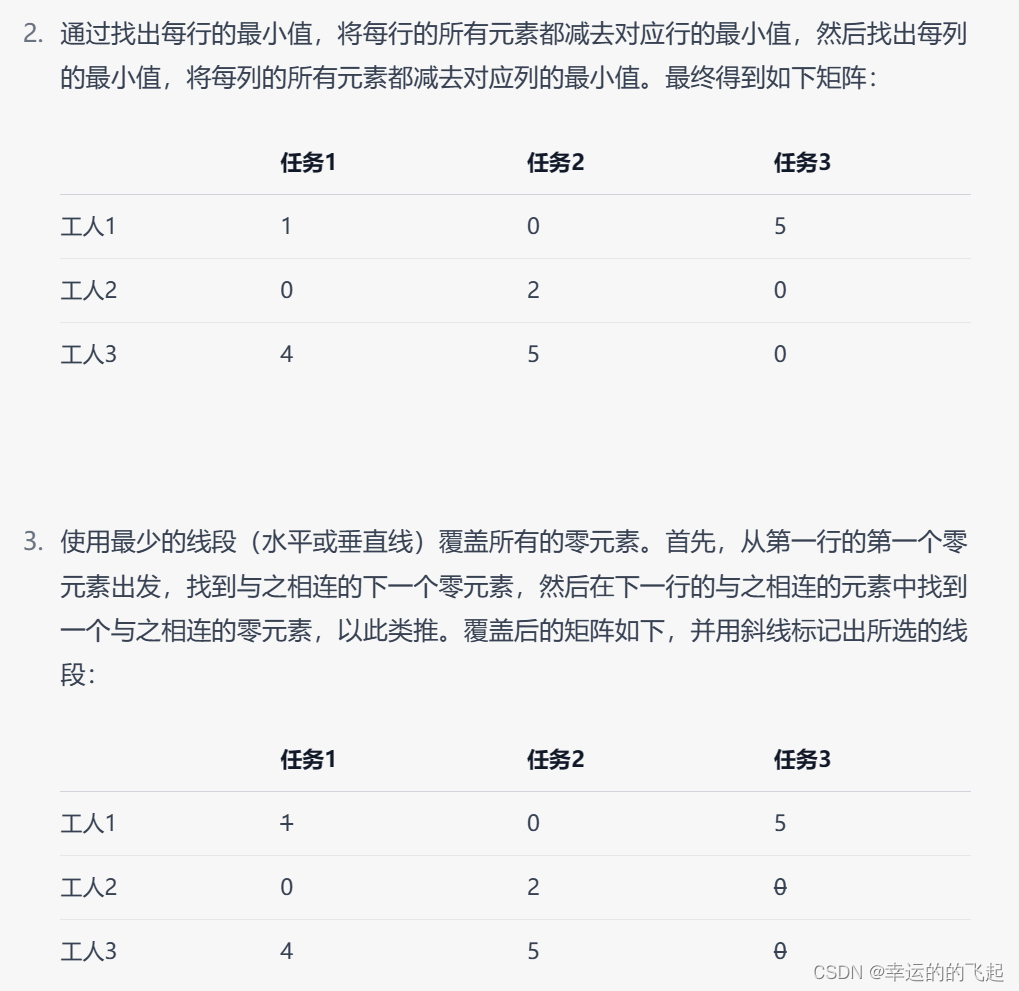
- Subtract row minima(减去行最小值):对于每一行,找到该行的最小值,然后该行的数都减去这个最小值。
- Subtract column minima(减去列最小值):对于每一列,找到该列的最小值,然后该列的数都减去这个最小值。
- Cover all zeros with a minimum number of lines(用最少的线覆盖所有的0):用最少的水平线和垂直线覆盖掉矩阵的所有0元素。
-
如果线的数量等于N,则找到了最优分配,算法结束,否则进入步骤5
- Create additional zeros(创建额外的0元素):找到没有被任何线覆盖的最小元素,所有未覆盖的元素中减去这个数字,并将其添加到所有被覆盖两次的元素中,返回步骤3
举个实例:假设有3个工人和3个任务,每个工人可以完成每项任务的不同工作量。我们的目标是将工人分配到任务上,使得总工作量最小。
4.有三条线段才能覆盖所有的0,即符合=N,算法停止。
5.对应到原始矩阵,得到的匹配为 [工人1-任务2,工人2-任务1,工人3-任务3],工作总量为:2+2+1=5.
二、DeepSort算法
流程图:
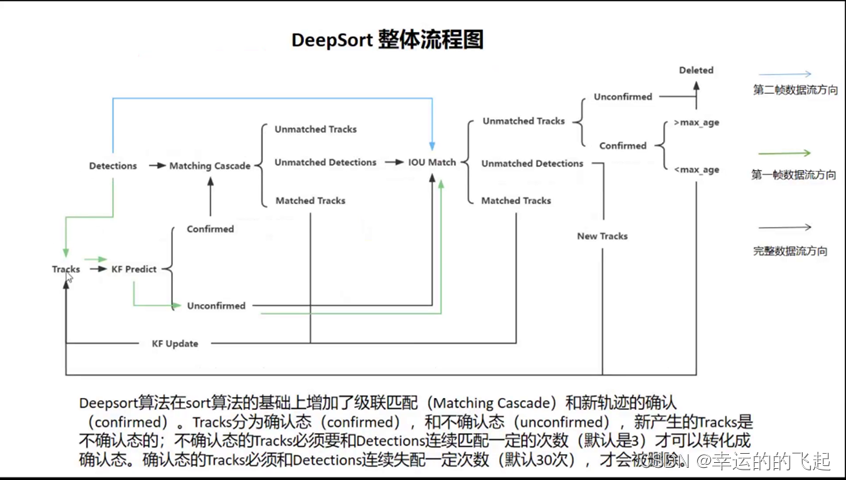
算法步骤:
第一帧:进行初始化,使用目标检测模型检测出当前帧中目标,并进行预测,每个track中包含id、检测框、feature、预测框),并且每个预测框的状态为unconfirmed。
第二帧:目标框与Tracks里的预测框进行IOU匹配,之后进行连续三帧的IOU匹配。匹配成功后,使预测框的状态由unconfirmed转变为confirmed,然后进行级联匹配。如果三次IOU匹配没有成功,有两种可能:一种是Unmatched Tracks(检测器漏检);一种是Unmatched Detections(出现新目标或者是目标被长时间遮挡),更新轨迹。如果是第一种就要先检查状态,状态为Unconfirmed,即超过30次(max_age)匹配都没有成功,就直接删除(默认该目标已经消失)。剩下的帧进行循环操作。
必备知识:
级联匹配:
相比于Sort算法,DeepSort算法还利用了级联匹配,也就是添加了feature 匹配,利用reid模型进行特征提取。主要思想是通过利用目标的特征向量相似度和位置信息,将当前帧中的目标与已跟踪的目标进行匹配,从而实现准确的目标跟踪。
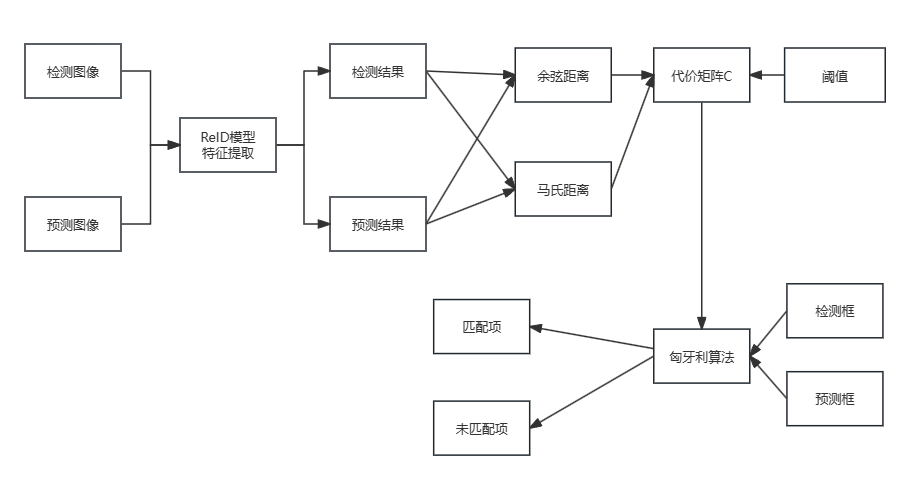
级联匹配流程图里上半部分就是特征提取和相似度估计,也就是算这个分配问题的代价函数。主要由两部分组成:代表外观模型的Re-ID特征和代表运动模型的马氏距离。
级联匹配流程图里下半部分匈牙利算法数据关联作为流程的主体。也就是说,对于没有丢失过的轨迹赋予优先匹配的权利,而丢失的最久的轨迹最后匹配。
- 第一步:使用目标检测器(如YOLO、SSD等)检测当前帧中的目标,并提取其特征向量(如使用卷积神经网络提取的特征向量);使用卡尔曼滤波器对每个已跟踪的目标进行位置预测,将检测框和预测框内的结果对应的图像送到REID网络中,计算当前帧中每个目标的特征向量与已跟踪目标的特征向量之间的相似度,常用的度量方式是余弦相似度或欧氏距离,用于衡量目标之间的相似程度,用代价矩阵来表示,这里记为C。
- 再去计算检测和预测结果的马氏距离,然后根据统计学和实验所得的阈值,去除掉不符合马氏距离和余弦距离阈值的匹配项。(这里马氏距离仅仅作为去除不符合的匹配项而已)
- 第二步:根据矩阵C的结果使用匈牙利算法进行检测框和预测框的匹配,目标是找到使总相似度最大化的最佳匹配。
- 进行更新。
三、 ByteTrack算法
主要思想:
ByteTrack算法与DeepSort算法相比,没有了级联匹配(feature匹配),只有IOU匹配,并保留所有的检测框(因遮挡存在的低分的目标框也会保留并作匹配)。目的是利用低分框和未匹配上的框进行再次匹配,来减缓遮挡导致目标丢失的问题。同样也是使用卡尔曼滤波算法进行预测。
该算法主要分为两个阶段:检测阶段与跟踪阶段。在检测阶段,使用一个特殊的CNN模型来识别图像中的目标,该模型可以同时输出目标的类别和位置信息。在跟踪阶段,提出了一种名为BYTE的数据关联方法,利用每个检测框与轨迹的相似性来恢复真实目标并过滤掉背景检测,并且将目标框分为低分框和高分框,利用低分框和跟踪轨迹之间的相似性,从低分框中挖掘出真正的物体,过滤掉背景。
BYTE流程图:
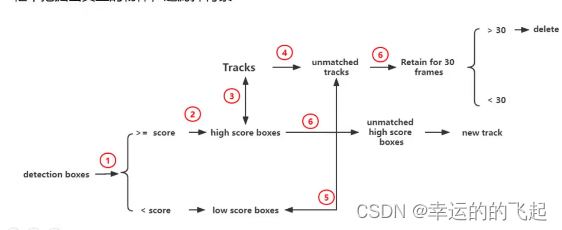
BYTE步骤:
-
初始化:首先,对第一帧进行目标检测,使用目标检测器得到检测框。
-
数据关联:利用BYTE数据关联方法,将每个检测框与已有的轨迹进行匹配。
-
首先将每个检测框根据阈值分成两类:高分框和低分框,然后进行两次匹配(先用IOU计算代价矩阵,再用匈牙利算法分配)。
-
第一次匹配:高分框和之前的跟踪轨迹(Tracks)进行匹配;
-
第二次匹配:低分框和第一次没有匹配上高分框的轨迹进行匹配;
-
对于没有匹配上轨迹的高分框,建立一个新的轨迹;对于两次匹配都没有匹配上轨迹的框,保留30帧,30帧之内还是没有匹配上就删除。
总结:
对于跟踪,算法并不知道自己跟踪的目标内容是什么,它只负责跟踪。而想要知道具体的内容,就要通过重识别技术。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)