
【计算机视觉 | 实例分割】干货:实例分割常见算法介绍合集
【计算机视觉 | 实例分割】干货:实例分割常见算法介绍合集
文章目录
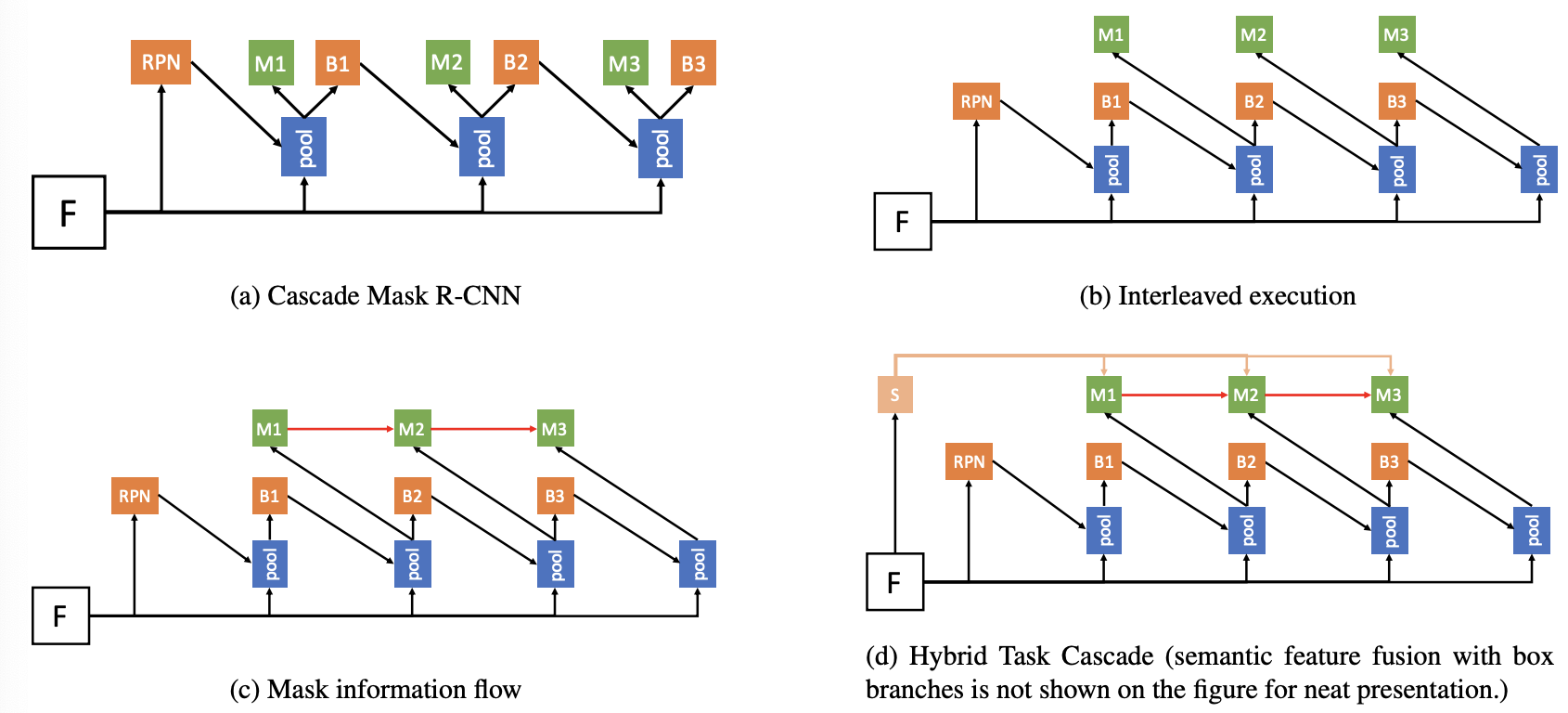
一、Mask R-CNN
Mask R-CNN 扩展了 Faster R-CNN 以解决实例分割任务。 它通过添加一个用于预测对象掩模的分支与用于边界框识别的现有分支并行来实现这一点。 原则上,Mask R-CNN 是 Faster R-CNN 的直观扩展,但正确构建 mask 分支对于获得良好结果至关重要。
最重要的是,Faster R-CNN 并不是为网络输入和输出之间的像素到像素对齐而设计的。 这在 RoIPool(处理实例的事实上的核心操作)如何执行粗空间量化以进行特征提取中显而易见。 为了修复未对齐问题,Mask R-CNN 使用了一个简单的无量化层,称为 RoIAlign,它忠实地保留了精确的空间位置。
其次,Mask R-CNN将掩模和类别预测解耦:它独立地为每个类别预测一个二元掩模,没有类别之间的竞争,并依赖网络的RoI分类分支来预测类别。 相比之下,FCN 通常执行逐像素多类分类,将分割和分类结合起来。
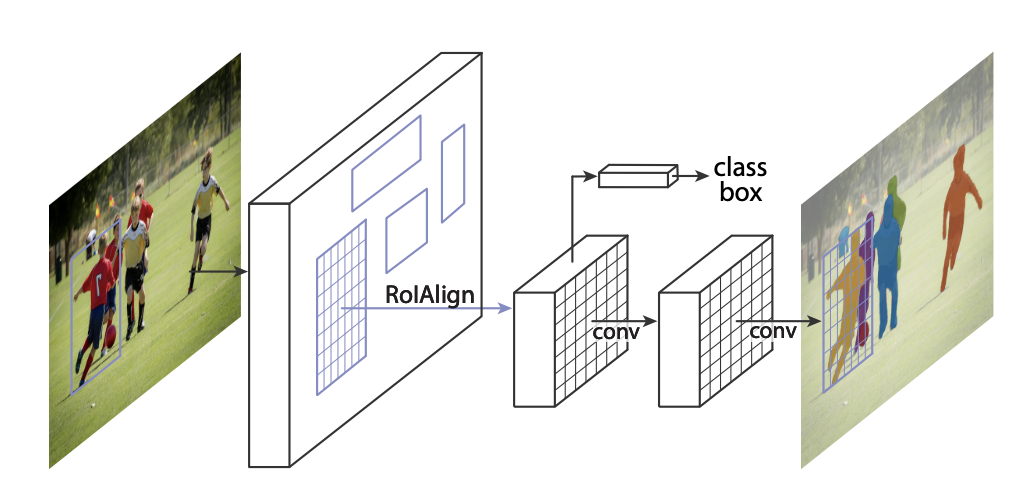
二、Hybrid Task Cascade
混合任务级联(HTC)是实例分割中级联的框架。 它与Cascade Mask R-CNN有两个重要的区别:(1)不是分别对检测和分割两个任务进行级联细化,而是将它们交织在一起进行联合多阶段处理; (2)它采用全卷积分支来提供空间上下文,这可以帮助区分坚硬的前景和杂乱的背景。
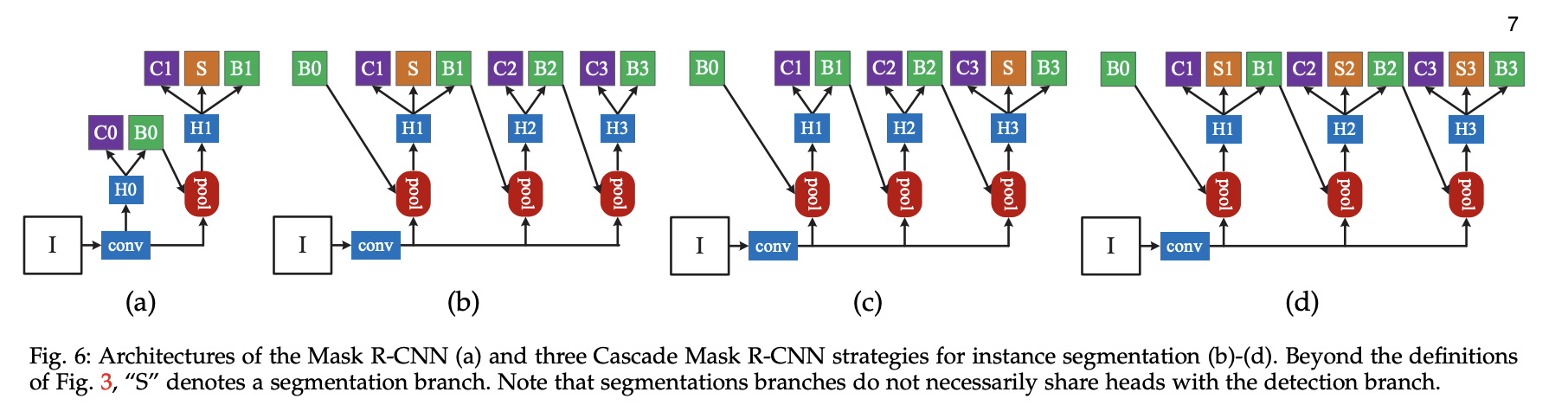
三、Cascade Mask R-CNN
Cascade Mask R-CNN 通过向级联添加 mask head 将 Cascade R-CNN 扩展到实例分割。
在 Mask R-CNN 中,分割分支与检测分支并行插入。 然而,Cascade R-CNN 有多个检测分支。 这就提出了以下问题:1)在哪里添加分段分支;2)要添加多少个分段分支。 作者考虑了 Cascade R-CNN 中掩模预测的三种策略。 前两种策略解决了第一个问题,在 Cascade R-CNN 的第一级或最后一级添加单个掩模预测头。 由于用于训练分割分支的实例是检测分支的正例,因此它们的数量在这两种策略中有所不同。 将分割头放在级联的后面会产生更多的例子。 然而,由于分割是逐像素操作,因此大量高度重叠的实例不一定像对象检测那样有帮助,对象检测是基于补丁的操作。 第三种策略解决了第二个问题,为每个级联阶段添加了一个分段分支。 这最大化了用于学习掩模预测任务的样本的多样性。
在推理时,所有三种策略都会预测最终对象检测阶段生成的补丁上的分割掩模,而不管实现分割掩模的级联阶段以及有多少个分割分支。
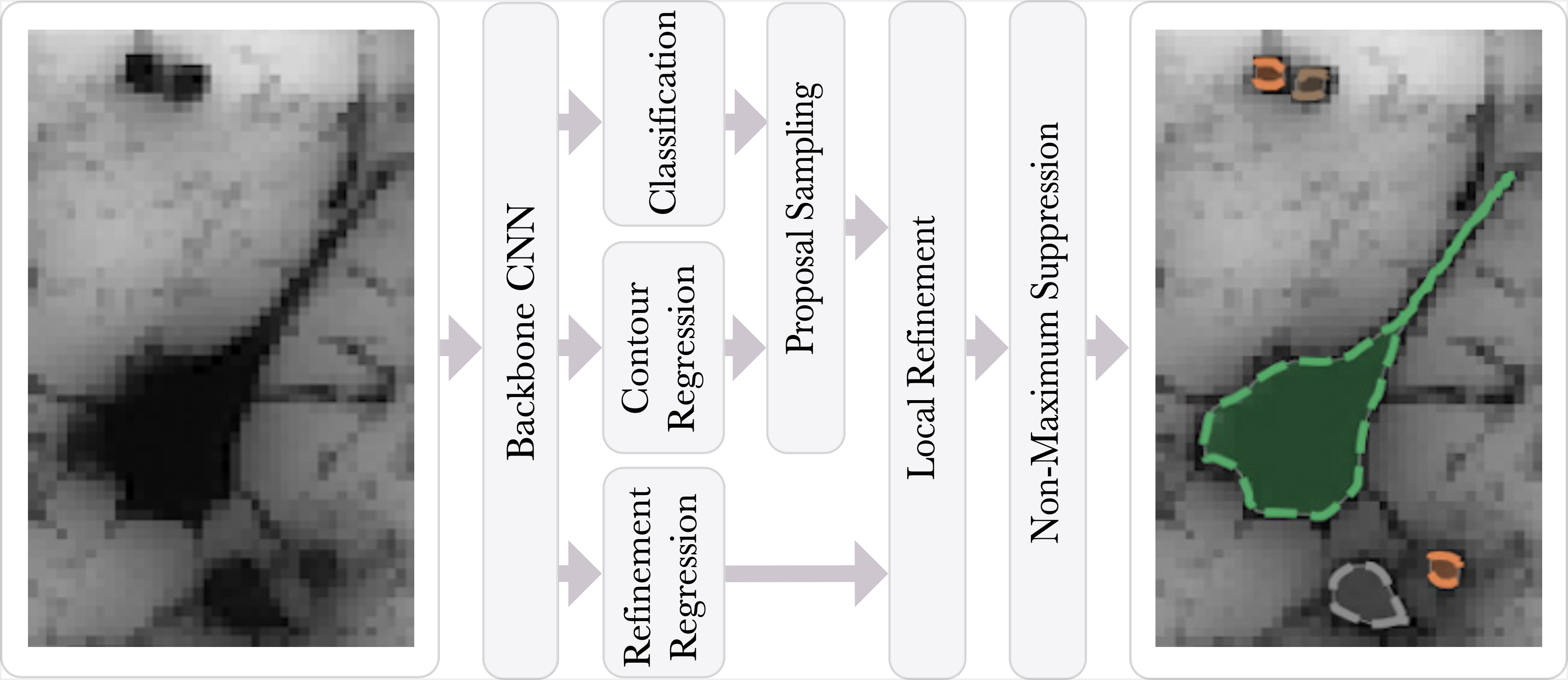
四、Contour Proposal Network
轮廓提议网络 (CPN) 检测图像中可能重叠的对象,同时拟合像素精确的闭合对象轮廓。 CPN 可以将最先进的对象检测架构作为骨干网络合并到可以进行端到端训练的快速单阶段实例分割模型中。
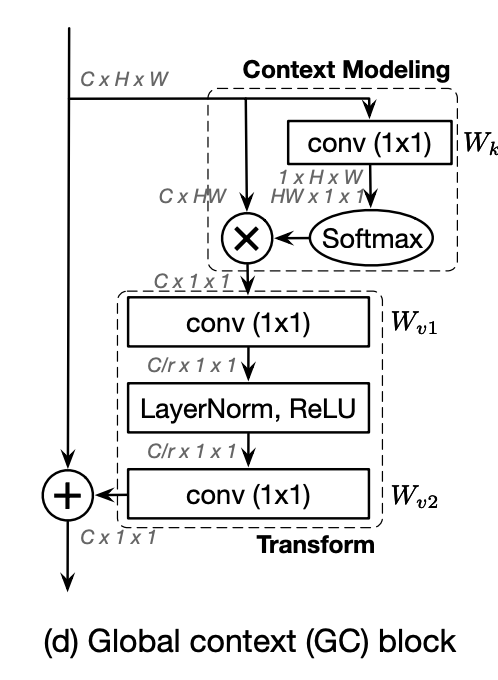
五、GCNet
全局上下文网络(GCNet)利用全局上下文块对图像中的远程依赖性进行建模。 它基于非本地网络,但它修改了架构,因此需要更少的计算。 全局上下文块应用于骨干网络中的多个层来构建 GCNet。
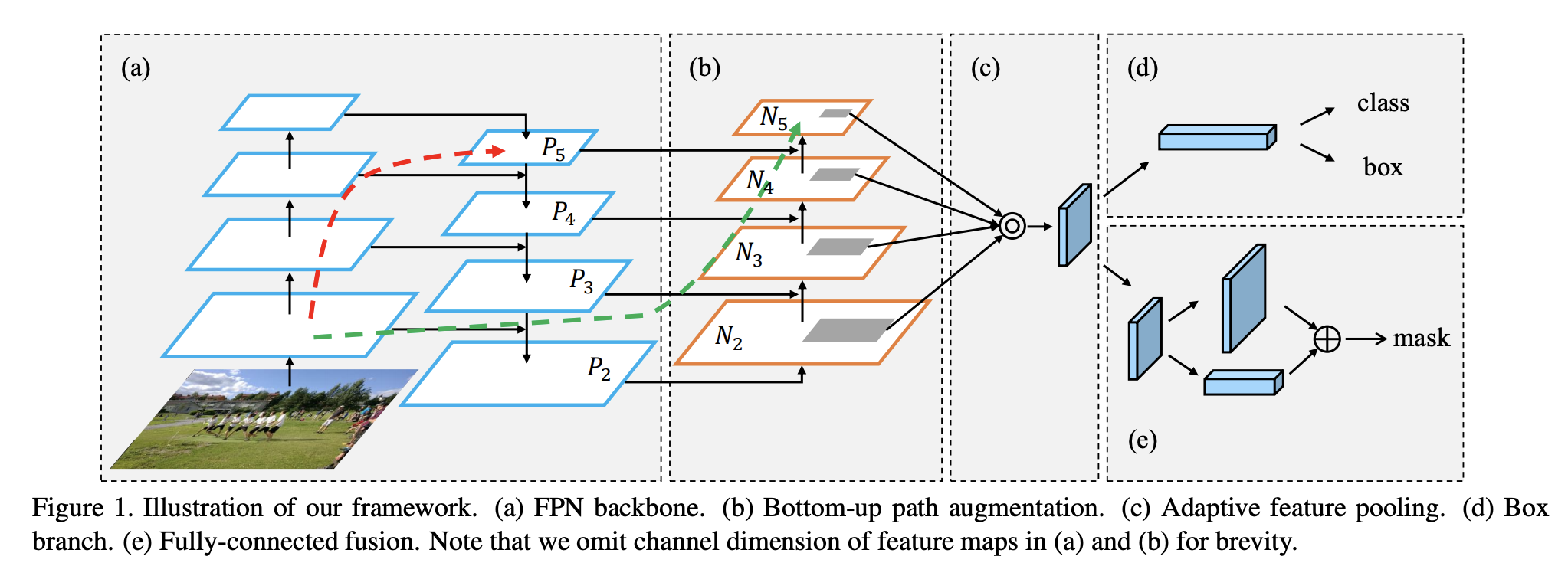
六、PANet
路径聚合网络(PANet)旨在促进基于提议的实例分割框架中的信息流。 具体来说,通过自下而上的路径增强,利用较低层中的准确定位信号来增强特征层次,从而缩短了较低层和最顶层特征之间的信息路径。 此外,还采用了自适应特征池,它将特征网格和所有特征级别链接起来,使每个特征级别中的有用信息直接传播到后续的提议子网络。 创建一个互补分支,捕获每个提案的不同视图,以进一步改进掩模预测。
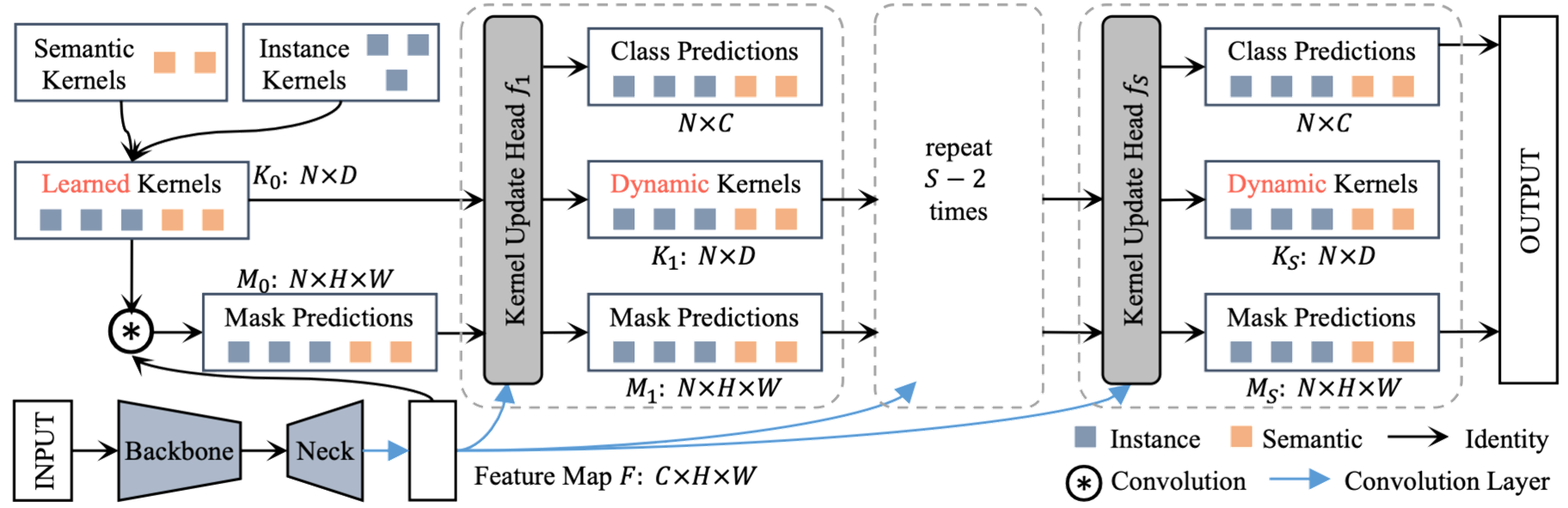
七、K-Net
K-Net 是一个统一语义和实例分割的框架,它通过一组可学习的内核来一致地分割实例和语义类别,其中每个内核负责为潜在实例或填充类生成掩码。 它从一组随机初始化的内核开始,并根据手头的分割目标学习内核,即语义类别的语义内核和实例身份的实例内核。 语义内核和实例内核的简单组合可以自然地实现全景分割。 在前向传递中,内核对图像特征进行卷积以获得相应的分割预测。
K-Net 的设计可以动态更新内核,使其以图像上的激活为条件。 这种内容感知机制对于确保每个内核(尤其是实例内核)准确响应图像中的变化对象至关重要。 通过迭代应用这种自适应内核更新策略,K-Net 显着提高了内核的判别能力并提高了最终的分割性能。 值得注意的是,该策略普遍适用于所有分割任务的内核。
它还利用二分匹配策略为每个内核分配学习目标。 这种训练方法比传统的训练策略更有优势,因为它在图像中的内核和实例之间建立了一对一的映射。 因此,它解决了处理图像中不同数量实例的问题。 另外,它是纯粹的mask驱动,不涉及box。 因此,K-Net 天然是无 NMS 和无盒子的,这对实时应用程序很有吸引力。
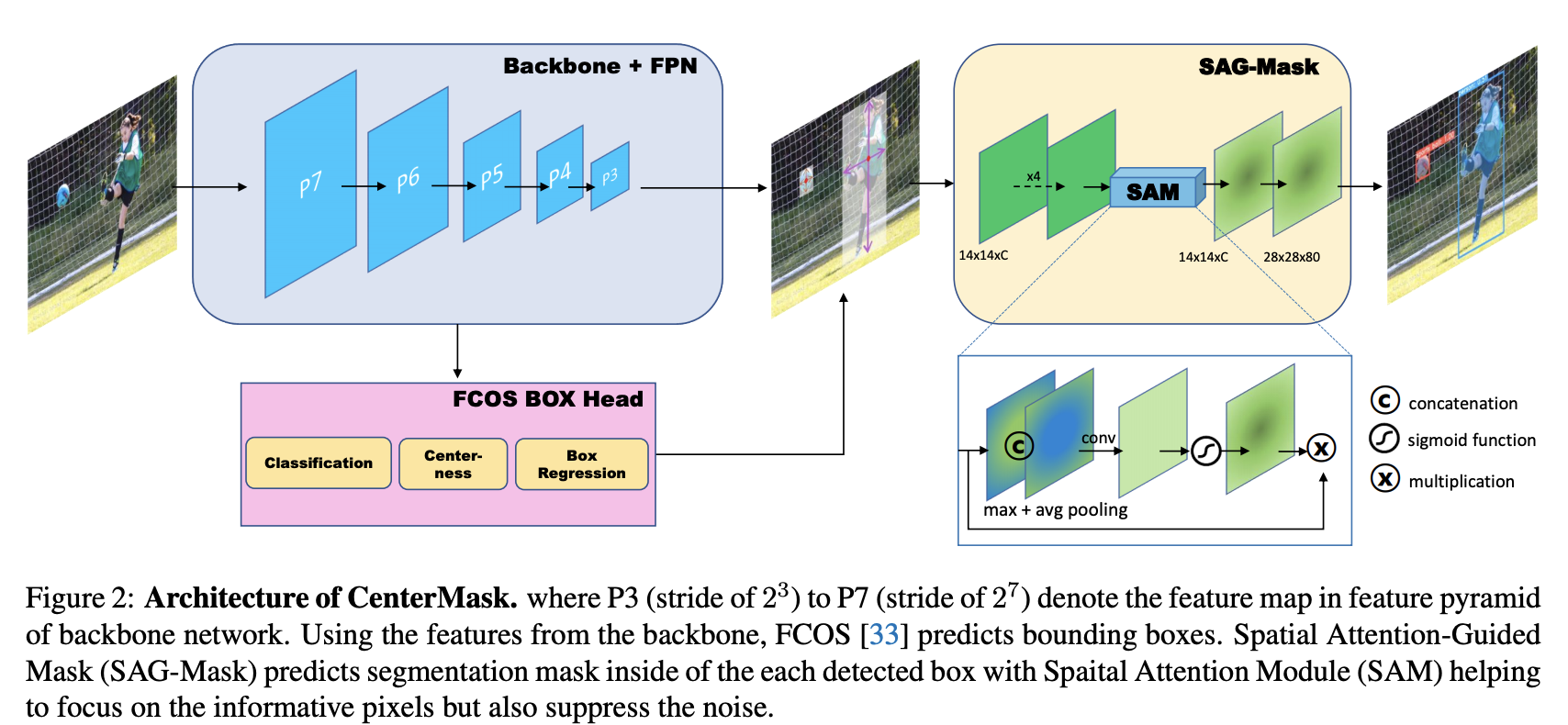
八、CenterMask
CenterMask 是一种无锚实例分割方法,它与 Mask R-CNN 一样,在无锚单级目标检测器 (FCOS) 中添加了一种新颖的空间注意力引导掩模 (SAG-Mask) 分支。 插入 FCOS 对象检测器后,SAG-Mask 分支使用空间注意力图预测每个检测到的框上的分割掩模,这有助于关注信息丰富的像素并抑制噪声。
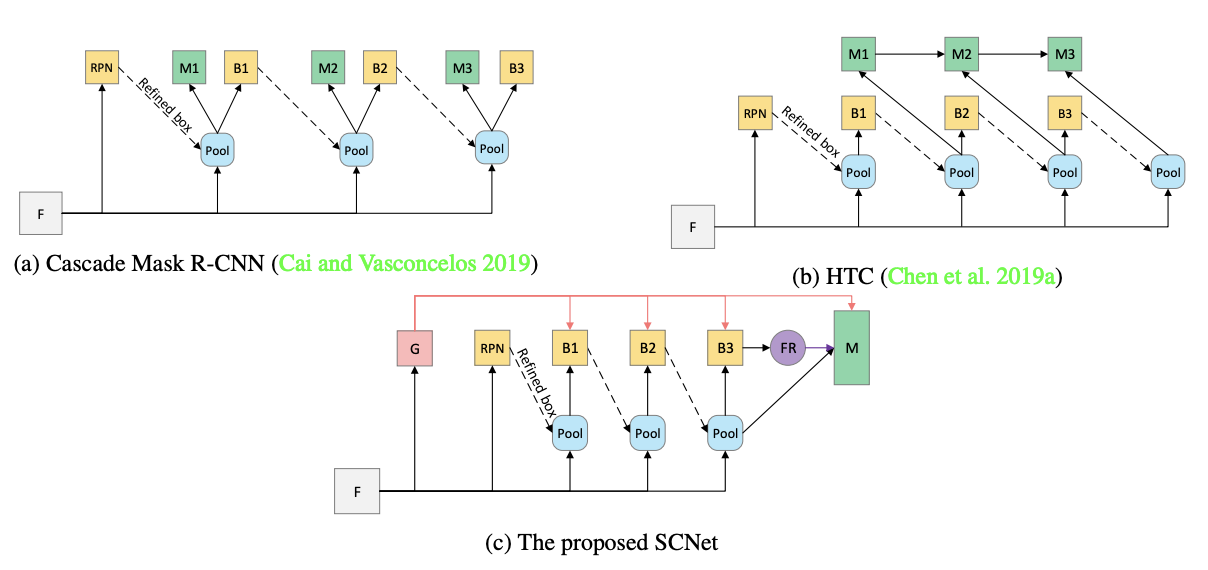
九、SCNet
样本一致性网络(SCNet)是一种实例分割方法,可确保训练时样本的 IoU 分布与推理时的 IoU 分布尽可能接近。 为此,只有最后一个框阶段的输出用于训练和推理时的掩模预测。 该图显示了训练时进入 mask 分支的样本在有/无样本一致性的情况下与推理时的 IoU 分布。
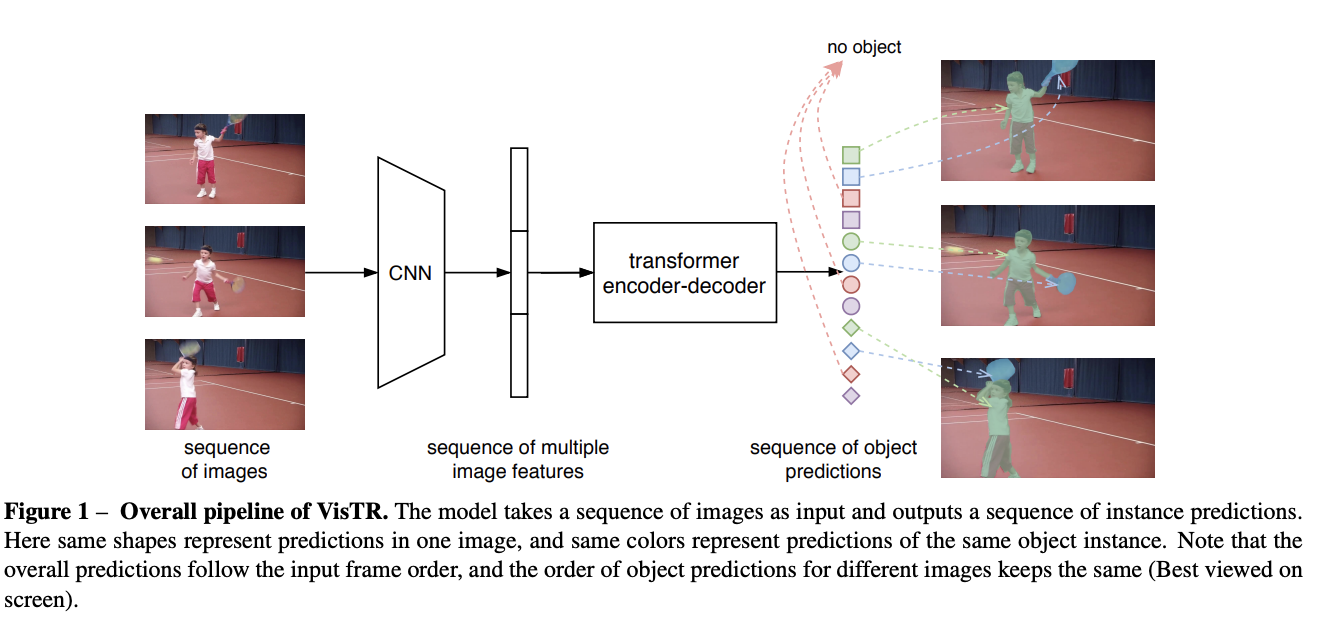
十、VisTR
VisTR 是一个基于 Transformer 的视频实例分割模型。 它将视频实例分割视为直接的端到端并行序列解码/预测问题。 给定由多个图像帧组成的视频剪辑作为输入,VisTR 直接按顺序输出视频中每个实例的掩码序列。 其核心是一种新的、有效的实例序列匹配和分割策略,它在序列级别作为一个整体来监督和分割实例。 VisTR 从相似性学习的相同角度构建实例分割和跟踪,从而大大简化了整个流程,并且与现有方法显着不同。
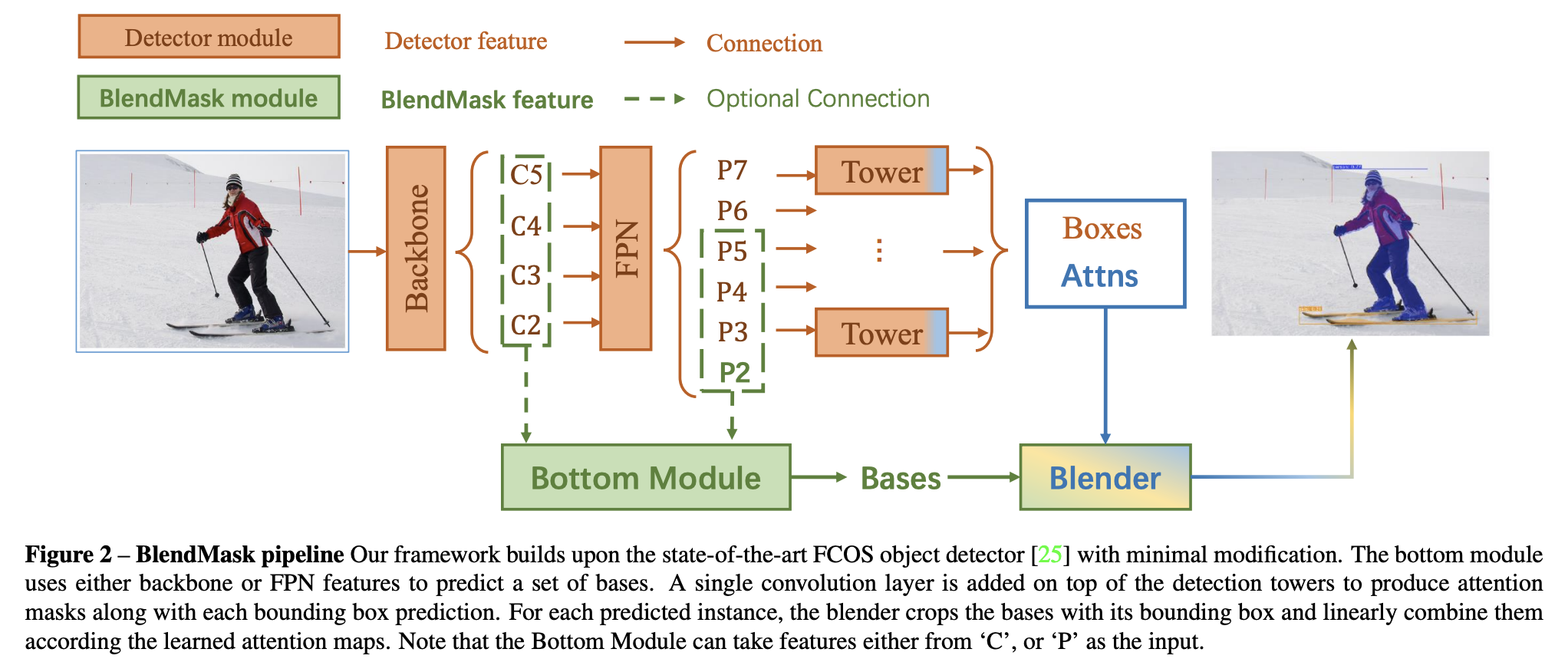
十一、BlendMask
BlendMask 是一个构建在 FCOS 对象检测器之上的实例分割框架。 底部模块使用主干或 FPN 特征来预测一组碱基。 在检测塔顶部添加单个卷积层,以生成注意掩模以及每个边界框预测。 对于每个预测实例,混合器用其边界框裁剪碱基,并根据学习到的注意力图将它们线性组合。 请注意,底部模块可以采用“C”或“P”中的特征作为输入。
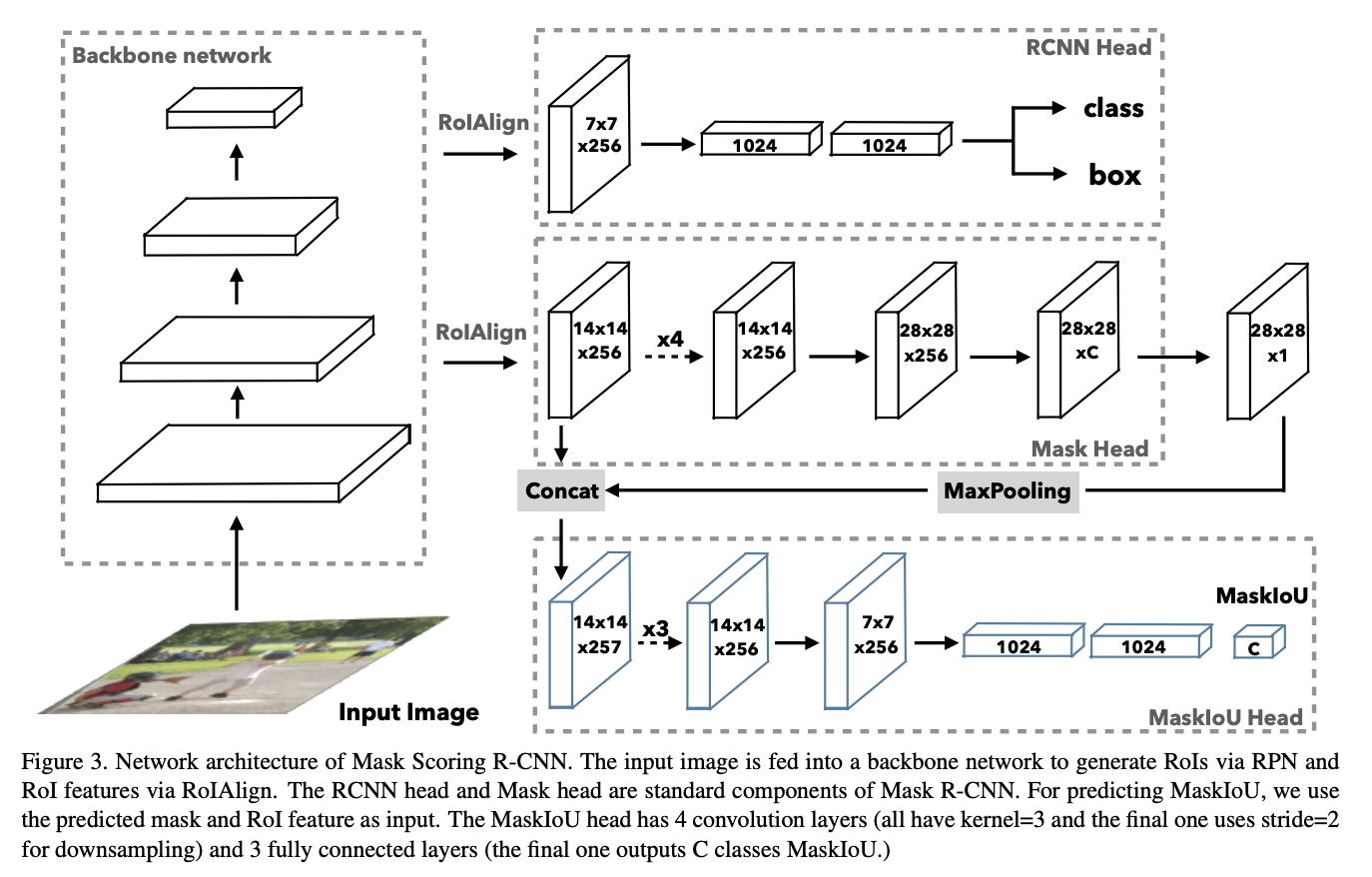
十二、Mask Scoring R-CNN
Mask Scoring R-CNN是带有MaskIoU Head的Mask RCNN,它将实例特征和预测掩模一起作为输入,并预测输入掩模和groundtruth掩模之间的IoU。
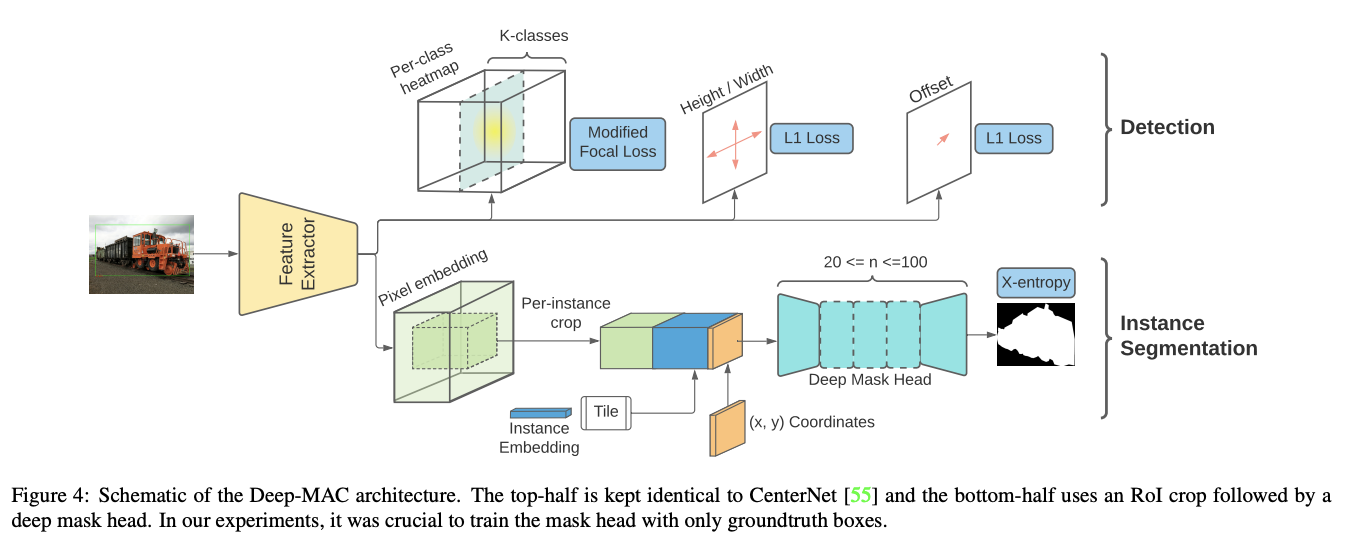
十三、Deep-MAC
Deep-MAC,即 CenterNet 之上的 Deep Mask-heads,是一种基于 CenterNet 的无锚实例分割模型。 这种新架构的动机是框的注释比掩码便宜得多,因此作者解决了“部分监督”实例分割问题,其中所有类都具有边界框注释,但只有类的子集具有掩码注释。
为了预测边界框,CenterNet 输出 3 个张量:(1) 特定于类的热图,指示边界框中心出现在每个位置的概率;(2) 与类无关的 2 通道张量,指示高度和 每个中心像素处的边界框宽度,以及 (3) 由于输出特征图通常小于图像(步长 4 或 8),CenterNet 还预测 x 和 y 方向偏移以恢复每个中心像素处的离散化误差 。

十四、Affordance Correspondence
对象部分的一次性视觉搜索/一次性语义部分对应的方法。 给定带有注释可供性区域的对象的单个参考图像,它会在目标场景中分割语义上对应的部分。 AffCorrs 用于查找类内和类间一次性部分分割的相应可供性。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)