
分库分表之Sharding-JDBC
目录
1、Sharding-JDBC概述
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
-
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
与MyCAT区别:
Sharding-JDBC和MyCAT使用不同的理念,Sharding-JDBC目前是基于JDBC驱动,无需额外的Proxy,因此也无需关注Proxy本身的高可用, 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的。----》JDBC Proxy
MyCAT是基于 Proxy,它复写了 MySQL 协议,将 MyCAT Server 伪装成一个 MySQL 数据库,开发人员直接使用逻辑库就跟使用MySQL数据库一样,分库分表和读写分离的工作都交由MyCAT中间件处理(当然,增大了运维的难度)----》DB Server Proxy
2、架构回顾
在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下:

在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。

在数据量继续扩大,这时可以考虑分库分表,将数据存储在不同数据库的不同表中,如下:

3、SpringBoot集成Sharding-JDBC
3.1 准备工作
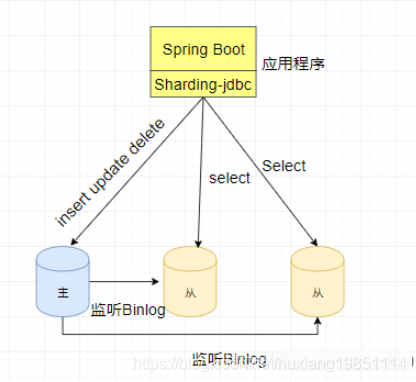
准备6个数据库服务器,两个主库节点,四个从库节点
| 主 | 192.168.223.128 |
|---|---|
| 从 | 192.168.223.129 |
| 从 | 192.168.223.130 |
| 主 | 192.168.223.131 |
| 从 | 192.168.223.132 |
| 从 | 192.168.223.133 |
在6个服务器上执行如下SQL脚本,创建数据库sharding-jdbc并且创建5个表,这5个表分别为user_0、user_1、user_2、user_3、user_4。
CREATE DATABASE
IF NOT EXISTS sharding-jdbc DEFAULT CHARACTER
SET utf8 DEFAULT COLLATE utf8_general_ci;
USE sharding-jdbc;
/*Table structure for table `user_0` */
DROP TABLE IF EXISTS `user_0`;
CREATE TABLE `user_0` (
`id` int(12) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=149 DEFAULT CHARSET=utf8;
/*Table structure for table `user_1` */
DROP TABLE IF EXISTS `user_1`;
CREATE TABLE `user_1` (
`id` int(12) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=150 DEFAULT CHARSET=utf8;
/*Table structure for table `user_2` */
DROP TABLE IF EXISTS `user_2`;
CREATE TABLE `user_2` (
`id` int(12) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=147 DEFAULT CHARSET=utf8;
/*Table structure for table `user_3` */
DROP TABLE IF EXISTS `user_3`;
CREATE TABLE `user_3` (
`id` int(12) NOT NULL AUTO_INCREMENT,
`username` varchar(12) NOT NULL,
`password` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=148 DEFAULT CHARSET=utf8;
/*Table structure for table `user_4` */
DROP TABLE IF EXISTS `user_4`;
CREATE TABLE `user_4` (
`id` INT(12) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(12) NOT NULL,
`password` VARCHAR(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx-username` (`username`)
) ENGINE=INNODB AUTO_INCREMENT=148 DEFAULT CHARSET=utf8;
3.2 配置MySQL主从复制
#1、分别在主节点128和131上面my.cnf配置bin log信息,并且重启服务
server-id = 配置不重复的server-id
log-bin = master-bin
log-bin-index = master-bin.index
#2、分别在从节点129,130,132,133上面my.cnf配置relay log信息,并且重启
server-id = 配置不重复的server-id
relay-log-index = relay-log.index
relay-log = relay-log
slave-skip-errors = all
#3、分别在128和131上创建主从连接账号
#删除原有主从连接账号,你高兴可以不删
delete from mysql.user where user = 'repl';
#创建主从连接账户repl
CREATE USER repl;
#或者执行操作如下创建:从库repl密码123456 跟主库连接,有slave的权限
GRANT replication slave ON *.* TO 'repl'@'192.168.223.%' identified by '123456';
#刷新生效
FLUSH PRIVILEGES;
#4、分别在129,130上建立与128的主从关系,132,133上建立与131的主从关系:
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> reset slave;
Query OK, 0 rows affected (0.28 sec)
mysql> CHANGE MASTER TO
-> master_host='192.168.223.128',#128或者131
-> master_port=3306,
-> master_user='repl',
-> master_password='123456',
-> master_log_file='master-bin.000017',#你知道怎么查
-> master_log_pos=120;#你知道怎么查
Query OK, 0 rows affected, 2 warnings (0.04 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status;#查看是否成功
#PS:注意各节点server_id和server_uuid要不重复3.3 引入依赖坐标
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0.M1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>3.4 application.properties配置
#DataSource命名空间
sharding.jdbc.datasource.names=sharding-jdbc1-master,sharding-jdbc1-slave1,sharding-jdbc1-slave2,sharding-jdbc2-master,sharding-jdbc2-slave1,sharding-jdbc2-slave2
#DataSource1
sharding.jdbc.datasource.sharding-jdbc1-master.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc1-master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc1-master.url=jdbc:mysql://192.168.223.128:3306/sharding-jdbc?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc1-master.username=root
sharding.jdbc.datasource.sharding-jdbc1-master.password=root
#DataSource2
sharding.jdbc.datasource.sharding-jdbc1-slave1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc1-slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc1-slave1.url=jdbc:mysql://192.168.223.129:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc1-slave1.username=root
sharding.jdbc.datasource.sharding-jdbc1-slave1.password=root
#DataSource3
sharding.jdbc.datasource.sharding-jdbc1-slave2.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc1-slave2.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc1-slave2.url=jdbc:mysql://192.168.223.130:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc1-slave2.username=root
sharding.jdbc.datasource.sharding-jdbc1-slave2.password=root
#DataSource4
sharding.jdbc.datasource.sharding-jdbc2-master.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc2-master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc2-master.url=jdbc:mysql://192.168.223.131:3306/sharding-jdbc?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc2-master.username=root
sharding.jdbc.datasource.sharding-jdbc2-master.password=root
#DataSource5
sharding.jdbc.datasource.sharding-jdbc2-slave1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc2-slave1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc2-slave1.url=jdbc:mysql://192.168.223.132:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc2-slave1.username=root
sharding.jdbc.datasource.sharding-jdbc2-slave1.password=root
#DataSource6
sharding.jdbc.datasource.sharding-jdbc2-slave2.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.sharding-jdbc2-slave2.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.sharding-jdbc2-slave2.url=jdbc:mysql://192.168.223.133:3306/sharding-jdbc?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT
sharding.jdbc.datasource.sharding-jdbc2-slave2.username=root
sharding.jdbc.datasource.sharding-jdbc2-slave2.password=root
#数据库分片 sharding-column(分片字段) algorithm-expression(分片表达式,奇数,偶数分别入库)
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds_$->{id % 2}
#user表分片
#actual-data-nodes=ds_$->{0..1}.user_$->{0..4} ---》分别入库ds_0,ds_1(数据节点代号) user_0,user_1...表名
sharding.jdbc.config.sharding.tables.user.actual-data-nodes=ds_$->{0..1}.user_$->{0..4}
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=id
#分配到五个表中
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 5}
#自动生成id
sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
#主从库逻辑数据源定义ds_0----》sharding-jdbc1-master,sharding-jdbc1-slave1, sharding-jdbc1-slave2
sharding.jdbc.config.sharding.master-slave-rules.ds_0.master-data-source-name=sharding-jdbc1-master
sharding.jdbc.config.sharding.master-slave-rules.ds_0.slave-data-source-names=sharding-jdbc1-slave1, sharding-jdbc1-slave2
sharding.jdbc.config.sharding.master-slave-rules.ds_1.master-data-source-name=sharding-jdbc2-master
sharding.jdbc.config.sharding.master-slave-rules.ds_1.slave-data-source-names=sharding-jdbc2-slave1, sharding-jdbc2-slave2
# 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志!!!
sharding.jdbc.config.props.sql.show=true
mybatis.config-location=classpath:META-INF/mybatis-config.xml3.5 启动类,pojo service,dao,test
package com.ydt.springboot.shardingjdbc;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
//需要排除springboot中德鲁伊默认自动配置,否则会出现bean定义覆盖问题
@SpringBootApplication(exclude={DruidDataSourceAutoConfigure.class})
public class SpringbootShardingjdbcApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootShardingjdbcApplication.class, args);
}
}
package com.ydt.springboot.shardingjdbc.entity;
import java.io.Serializable;
public class User implements Serializable {
private static final long serialVersionUID = -1205226416664488559L;
private Integer id;
private String username;
private String password;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
'}';
}
}package com.ydt.springboot.shardingjdbc.service;
import com.ydt.springboot.shardingjdbc.entity.User;
import java.util.List;
public interface UserService {
Integer addUser(User user);
List<User> list();
void deleteAll();
}
package com.ydt.springboot.shardingjdbc.service.impl;
import com.ydt.springboot.shardingjdbc.entity.User;
import com.ydt.springboot.shardingjdbc.repository.UserRepository;
import com.ydt.springboot.shardingjdbc.service.UserService;
import io.shardingsphere.api.HintManager;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
@Service
public class UserServiceImpl implements UserService {
@Resource
UserRepository userRepository;
@Override
public Integer addUser(User user) {
return userRepository.addUser(user);
}
@Override
public List<User> list() {
// 强制路由主库
//HintManager.getInstance().setMasterRouteOnly();
return userRepository.list();
}
@Override
public void deleteAll() {
userRepository.deleteAll();
}
}
package com.ydt.springboot.shardingjdbc.repository;
import com.ydt.springboot.shardingjdbc.entity.User;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface UserRepository {
Integer addUser(User user);
List<User> list();
void deleteAll();
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ydt.springboot.shardingjdbc.repository.UserRepository">
<resultMap id="baseResultMap" type="com.ydt.springboot.shardingjdbc.entity.User">
<result column="id" property="id" jdbcType="INTEGER" />
<result column="username" property="username" jdbcType="VARCHAR" />
<result column="password" property="password" jdbcType="VARCHAR" />
</resultMap>
<insert id="addUser">
INSERT INTO user (
id, username, password
)
VALUES (
#{id,jdbcType=INTEGER},
#{username,jdbcType=VARCHAR},
#{password,jdbcType=VARCHAR}
)
</insert>
<select id="list" resultMap="baseResultMap">
SELECT u.* FROM user u order by u.id limit 0,100
</select>
<delete id="deleteAll">
delete from user;
</delete>
</mapper>
package com.ydt.springboot.shardingjdbc;
import com.ydt.springboot.shardingjdbc.entity.User;
import com.ydt.springboot.shardingjdbc.service.UserService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class SpringbootShardingjdbcApplicationTests {
@Autowired
private UserService userService;
@Test
public void testQuery() {
List<User> list = userService.list();
for (User user : list) {
System.out.println(user);
}
}
@Test
public void testAdd() {
for (int i = 1; i < 101; i++) {
User user = new User();
user.setId(i);
user.setUsername("laohu" + (i));
user.setPassword("123456");
userService.addUser(user);
}
}
@Test
public void testDel() {
userService.deleteAll();
}
@Test
public void testFindByCondition(){
List<User> list = userService.findByCondition(50);
for (User user : list) {
System.out.println(user);
}
}
}
其他就不多说了,整个目录结构如下:

分别测试/users,/add,/delete接口查看分库分表效果,并且可以测试下使用分片字段和不使用分片字段的区别
3.6 一些需要补充的概念
3.6.1 绑定表
3.6.1.1 建表语句
我们这里只需要验证绑定表的执行性能,所以只需要在第一个集群中创建表即可:
-- ----------------------------
-- Table structure for t_order_0
-- ----------------------------
DROP TABLE IF EXISTS `t_order_0`;
CREATE TABLE `t_order_0` (
`id` int(11) NOT NULL,
`order_id` int(11) DEFAULT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_order_0
-- ----------------------------
INSERT INTO `t_order_0` VALUES ('1', '12', '老胡爱大米');
-- ----------------------------
-- Table structure for t_order_1
-- ----------------------------
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`id` int(11) NOT NULL,
`order_id` int(11) DEFAULT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
-- ----------------------------
-- Records of t_order_1
-- ----------------------------
INSERT INTO `t_order_1` VALUES ('2', '11', '老王也爱大米');
-- ----------------------------
-- Table structure for t_order_item_0
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item_0`;
CREATE TABLE `t_order_item_0` (
`id` int(11) NOT NULL,
`order_id` int(11) DEFAULT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_order_item_0
-- ----------------------------
INSERT INTO `t_order_item_0` VALUES ('1', '12', '老胡爱榻榻米');
-- ----------------------------
-- Table structure for t_order_item_1
-- ----------------------------
DROP TABLE IF EXISTS `t_order_item_1`;
CREATE TABLE `t_order_item_1` (
`id` int(11) NOT NULL,
`order_id` int(11) DEFAULT NULL,
`desc` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
-- ----------------------------
-- Records of t_order_item_1
-- ----------------------------
INSERT INTO `t_order_item_1` VALUES ('2', '11', '老王爱偷女邻居大米');3.6.1.2 绑定表配置
application.properties增加如下配置:
#测试笛卡尔积用
#笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员
sharding.jdbc.config.sharding.tables.t_order.actual-data-nodes=ds_0.t_order_$->{0..1}
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2}
sharding.jdbc.config.sharding.tables.t_order_item.actual-data-nodes=ds_0.t_order_item_$->{0..1}
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.sharding-column=order_id
sharding.jdbc.config.sharding.tables.t_order_item.table-strategy.inline.algorithm-expression=t_order_item_$->{order_id % 2}
#如果t_order和t_order_item分表非常多,而且你的查询条件并不能够减少最终路由到的物理表,
# 那么结果就是这个笛尔卡积算出来的结果会非常的吓人,这也是官方提到的要注意的一个问题点,
# 而为了解决这个问题,sharding-jdbc提供了BindingTable的机制来优化这个问题。
sharding.jdbc.config.sharding.binding-tables[0]=t_order,t_order_item3.6.1.3 测试代码
OrderService
package com.ydt.springboot.shardingjdbc.service;
import com.ydt.springboot.shardingjdbc.entity.OrderItem;
import java.util.List;
public interface OrderService {
List<OrderItem> list();
}
OrderServiceImpl
package com.ydt.springboot.shardingjdbc.service.impl;
import com.ydt.springboot.shardingjdbc.entity.OrderItem;
import com.ydt.springboot.shardingjdbc.repository.OrderRepository;
import com.ydt.springboot.shardingjdbc.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderRepository orderRepository;
@Override
public List<OrderItem> list() {
return orderRepository.list();
}
}
dao
package com.ydt.springboot.shardingjdbc.repository;
import com.ydt.springboot.shardingjdbc.entity.OrderItem;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface OrderRepository {
List<OrderItem> list();
}
mapper映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ydt.springboot.shardingjdbc.repository.OrderRepository">
<select id="list" resultType="com.ydt.springboot.shardingjdbc.entity.OrderItem">
SELECT i.* FROM t_order o left JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (11, 12)
</select>
</mapper>
3.6.1.4 测试结果
业务执行SQL:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);在不配置绑定表关系时,假设分片键order_id将数值11路由至第1片,将数值12路由至第0片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (11, 12);其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
3.6.2 广播表
3.6.2.1 建表语句
-- ----------------------------
-- Table structure for t_dict
-- ----------------------------
DROP TABLE IF EXISTS `t_dict`;
CREATE TABLE `t_dict` (
`code` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;3.6.2.2 广播表配置
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。如果不配置,会找不到数据源,配置后会对所有可写数据源进行数据的更新操作
application.properties增加如下配置:
# 广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。
# 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
sharding.jdbc.config.sharding.broadcast-tables=t_dict3.6.2.3 测试代码
DictService
package com.ydt.springboot.shardingjdbc.service;
import com.ydt.springboot.shardingjdbc.entity.Dict;
import java.util.List;
public interface DictService {
List<Dict> listDict();
void addDict();
}
DictServiceImpl
package com.ydt.springboot.shardingjdbc.service.impl;
import com.ydt.springboot.shardingjdbc.entity.Dict;
import com.ydt.springboot.shardingjdbc.repository.DictRepository;
import com.ydt.springboot.shardingjdbc.service.DictService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DictServiceImpl implements DictService {
@Autowired
private DictRepository dictRepository;
public List<Dict> listDict() {
return dictRepository.listDict();
}
public void addDict() {
dictRepository.addDict();
}
}
DictRepository
package com.ydt.springboot.shardingjdbc.repository;
import com.ydt.springboot.shardingjdbc.entity.Dict;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface DictRepository {
List<Dict> listDict();
void addDict();
}DictRepository.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ydt.springboot.shardingjdbc.repository.DictRepository">
<insert id="addDict">
insert into t_dict values(2,"湖南")
</insert>
<select id="listDict" resultType="com.ydt.springboot.shardingjdbc.entity.Dict">
select d.* from t_dict d
</select>
</mapper>3.6.2.4测试结果
新增后所有数据库中该表都有相同的数据
查询时查询的数据跟普通数据库没有任何区别
整个过程不需要使用到分片机制
4、Sharding-JDBC原理

5、分库分表带来的问题
5.1 垂直分库带来的问题和解决思路
在拆分之前,系统中很多列表和详情页所需的数据是可以通过sql join来完成的。而拆分后,数据库可能是分布式在不同实例和不同的主机上,join将变得非常麻烦。而且基于架构规范,性能,安全性等方面考虑,一般是禁止跨库join的。那该怎么办呢?首先要考虑下垂直分库的设计问题,如果可以调整,那就优先调整。如果无法调整的情况,下面将结合以往的实际经验,总结几种常见的解决思路,并分析其适用场景。
跨库join的问题解决思路:
1、全局表
所谓全局表,就是有可能系统中所有模块都可能会依赖到的一些表。比较类似我们理解的“数据字典”。为了避免跨库join查询,我们可以将这类表在其他每个数据库中均保存一份。同时,这类数据通常也很少发生修改(甚至几乎不会),所以也不用太担心“一致性”问题。
2、字段冗余
这是一种典型的反范式设计,在互联网行业中比较常见,通常是为了性能来避免join查询。
举个电商业务中很简单的场景:
“订单表”中保存“卖家Id”的同时,将卖家的“Name”字段也冗余,这样查询订单详情的时候就不需要再去查询“卖家用户表”。
字段冗余能带来便利,是一种“空间换时间”的体现。但其适用场景也比较有限,比较适合依赖字段较少的情况。最复杂的还是数据一致性问题,这点很难保证,可以借助数据库中的触发器或者在业务代码层面去保证。当然,也需要结合实际业务场景来看一致性的要求。就像上面例子,如果卖家修改了Name之后,是否需要在订单信息中同步更新呢?
3、数据同步
A库中的tab_a表和B库中tab_b有关联,那么将两个表干脆全局冗余,定时将指定的表做同步。当然,同步本来会对数据库带来一定的影响,需要性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询。
4、系统层组装
在系统层面,通过调用不同模块的组件或者服务,获取到数据并进行字段拼装。说起来很容易,但实践起来可真没有这么简单,尤其是数据库设计上存在问题但又无法轻易调整的时候。具体情况通常会比较复杂。组装的时候要避免循环调用服务,循环RPC,循环查询数据库,最好一次性返回所有信息,在代码里做组装。
5.2 水平分库带来的问题和解决思路
1、分布式全局唯一ID
我们往往直接使用数据库自增特性来生成主键ID,这样确实比较简单。而在分库分表的环境中,数据分布在不同的分片上,不能再借助数据库自增长特性直接生成,否则会造成不同分片上的数据表主键会重复。简单介绍几种ID生成算法。
-
Twitter的Snowflake(又名“雪花算法”)
-
UUID(一般应用程序和数据库均支持)
-
其他一些开源项目,如美团Leaf等
其中,Twitter 的Snowflake算法生成的是64位唯一Id(由41位的timestamp+ 10位自定义的机器码+ 13位累加计数器组成)。
2、分片字段该如何选择
在开始分片之前,我们首先要确定分片字段(也可称为“片键”)。很多常见的例子和场景中是采用ID或者时间字段进行拆分。这也并不绝对的,我的建议是结合实际业务,通过对系统中执行的sql语句进行统计分析,选择出需要分片的那个表中最频繁被使用,或者最重要的字段来作为分片字段。
3、常见分片规则
常见的分片策略有随机分片和连续分片这两种:
当需要使用分片字段进行范围查找时,连续分片可以快速定位分片进行高效查询,大多数情况下可以有效避免跨分片查询的问题。后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移。但是,连续分片也有可能存在数据热点的问题,有些节点可能会被频繁查询压力较大,热数据节点就成为了整个集群的瓶颈。而有些节点可能存的是历史数据,很少需要被查询到。
随机分片其实并不是随机的,也遵循一定规则。通常,我们会采用Hash取模的方式进行分片拆分,所以有些时候也被称为离散分片。随机分片的数据相对比较均匀,不容易出现热点和并发访问的瓶颈。但是,后期分片集群扩容起来需要迁移旧的数据。使用一致性Hash算法能够很大程度的避免这个问题,所以很多中间件的分片集群都会采用一致性Hash算法。但是不管怎样,离散分片也很容易面临跨分片查询的复杂问题。
4、数据迁移,容量规划,扩容等问题
很少有项目会在初期就开始考虑分片设计的,一般都是在业务高速发展面临性能和存储的瓶颈时才会提前准备。因此,不可避免的就需要考虑历史数据迁移的问题。一般做法就是通过程序先读出历史数据,然后按照指定的分片规则再将数据写入到各个分片节点中。此外,我们需要根据当前的数据量和QPS等进行容量规划,综合成本因素,推算出大概需要多少分片(一般建议单个分片上的单表数据量不要超过1000W)。如果是采用随机分片,则需要考虑后期的扩容问题,相对会比较麻烦。如果是采用的连续分片,只需要添加节点就可以自动扩容。
5、跨分片的排序分页
分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复杂了。为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最后再返回给用户。
6、跨分片的函数处理
在使用Max、Min、Sum、Count之类的函数进行统计和计算的时候,需要先在每个分片数据源上执行相应的函数处理,然后再将各个结果集进行二次处理,最终再将处理结果返回。
7、跨分片join
Join是关系型数据库中最常用的特性,但是在分片集群中,join也变得非常复杂。应该尽量避免跨分片的join查询(这种场景,比上面的跨分片排序,函数处理更加复杂,而且对性能的影响很大)。通常有以下几种方式来避免:
-
全局表
全局表的概念之前在“垂直分库”时提过。基本思想一致,就是把一些类似数据字典又可能会产生join查询的表信息放到各分片中,从而避免跨分片的join。
-
ER分片
在关系型数据库中,表之间往往存在一些关联的关系。如果我们可以先确定好关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能很好的避免跨分片join问题。在一对多关系的情况下,我们通常会选择按照数据较多的那一方进行拆分。
-
内存计算
随着spark内存计算的兴起,理论上来讲,很多跨数据源的操作问题看起来似乎都能够得到解决。可以将数据丢给spark集群进行内存计算,最后将计算结果返回,这已经涉及大数据概念了,非常复杂。
5.3 我们的系统真的需要分库分表吗?
其实这点没有明确的判断标准,比较依赖实际业务情况和经验判断。一般MySQL单表1000W左右的数据是没有问题的(前提是应用系统和数据库等层面设计和优化的比较好)。
当然,除了考虑当前的数据量和性能情况时,作为架构师,我们需要提前考虑系统半年到一年左右的业务增长情况,对数据库服务器的QPS、连接数、容量等做合理评估和规划,并提前做好相应的准备工作。如果单机无法满足,且很难再从其他方面优化,那么说明是需要考虑分片的。这种情况可以先去掉数据库中自增ID,为分片和后面的数据迁移工作提前做准备。
很多人觉得“分库分表”是宜早不宜迟,应该尽早进行,因为担心越往后公司业务发展越快、系统越来越复杂、系统重构和扩展越困难…这种话听起来是有那么一点道理,但我的观点恰好相反,对于关系型数据库来讲,我认为“能不分片就别分片”,除非是系统真正需要,因为数据库分片并非低成本或者免费的。这里推荐一个比较靠谱的过渡技术–“表分区”。主流的关系型数据库中基本都支持。不同的分区在逻辑上仍是一张表,但是物理上却是分开的,能在一定程度上提高查询性能,而且对应用程序透明,无需修改任何代码。
PS:表分区就是把一张表分开,对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成。实现分区的代码实际上是对一组底层表的句柄对象的封装。对分区表的请求,都会通过句柄对象转化成对存储引擎的接口调用。分区表的每一个分区都是有索引的独立表。

具体参考:百度安全验证
5.4 小结
当前主要有两类解决方案:
-
基于应用程序层面的DDAL(分布式数据库访问层)
比较典型的就是淘宝半开源的TDDL,当当网开源的Sharding-JDBC等。分布式数据访问层无需硬件投入,技术能力较强的大公司通常会选择自研或参照开源框架进行二次开发和定制。对应用程序的侵入性一般较大,会增加技术成本和复杂度。通常仅支持特定编程语言平台(Java平台的居多),或者仅支持特定的数据库和特定数据访问框架技术(一般支持MySQL数据库,JDBC、MyBatis、Hibernate等框架技术)。
数据库中间件,比较典型的像mycat(在阿里开源的cobar基础上做了很多优化和改进,属于后起之秀,也支持很多新特性),基于Go语言实现kingSharding,比较老牌的Atlas(由360开源)等。这些中间件在互联网企业中大量被使用。另外,MySQL 5.x企业版中官方提供的Fabric组件也号称支持分片技术,不过国内使用的企业较少。
-
中间件也可以称为“透明网关”,大名鼎鼎的mysql_proxy大概是该领域的鼻祖(由MySQL官方提供,仅限于实现“读写分离”)。中间件一般实现了特定数据库的网络通信协议,模拟一个真实的数据库服务,屏蔽了后端真实的Server,应用程序通常直接连接中间件即可。而在执行SQL操作时,中间件会按照预先定义分片规则,对SQL语句进行解析、路由,并对结果集做二次计算再最终返回,我们之前使用的MyCat也是基于这个理论开发的。
引入数据库中间件的技术成本更低,对应用程序来讲侵入性几乎没有,可以满足大部分的业务。增加了额外的硬件投入和运维成本,同时,中间件自身也存在性能瓶颈和单点故障问题,需要能够保证中间件自身的高可用、可扩展。
总之,不管是使用分布式数据访问层还是数据库中间件,都会带来一定的成本和复杂度,也会有一定的性能影响。所以,还需读者根据实际情况和业务发展需要慎重考虑和选择。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)