
Map集合(超详细+源码讲解)
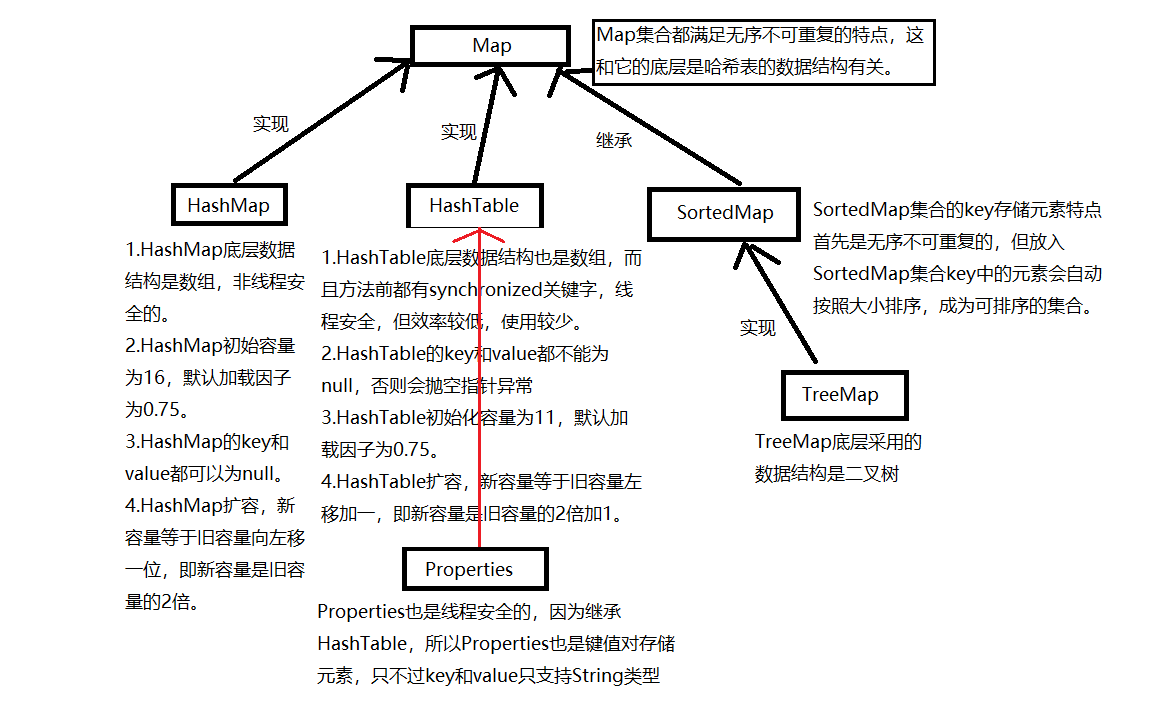
Map目录Map一、Map集合简述1.map集合是什么?2.Map集合常用实现类2.1 HashMap2.2 HashTable2.2.1 Properties2.3 SortedMap2.3.1 TreeMap2.4集合继承图二、Map接口常用方法1.clear2.containsKey3.containsValue4.get5.isEmpty6.keySet7.put8.remove9.siz
Map
一、Map集合简述
1.map集合是什么?
Map集合和Collection集合没有任何关系。Collection集合是以单个方式存储元素的,而Map集合是以键值对的方式存储元素,所有Map集合的Key是无序不可重复的,key和value都是引用数据类型,存的都是内存的地址。
Map集合的实现类主要为HashMap、HashTable。子接口有一个SortedMap,SortedMap有一个TreeMap实现类。
2.Map集合常用实现类
2.1 HashMap
HashMap底层采用哈希表的数据结构,非线程安全的。
2.2 HashTable
HashTable底层采用哈希表的数据结构,线程安全的,效率太低,使用较少,现在控制线程安全有其他的方式。
2.2.1 Properties
Properties是HashTable下的一个实现类,由于继承了HashTable,所以Properties也是线程安全的,Properties的key和value只支持String数据类型。
2.3 SortedMap
SortedMap继承Map,所以SortedMap也有无序不可重复的特点,但SortedMap集合中key的元素可以自动按照大小排列,称为可排列集合。
2.3.1 TreeMap
TreeMap是SortedMap的实现类,底层采用二叉树的数据结构,无序不可重复,但存入key的元素会按照大小排列。
2.4集合继承图

二、Map接口常用方法
1.clear
方法全称为:void clear(),移除map里所有的映射关系,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
map.clear();
}
2.containsKey
方法全称为:boolean containsKey(Object key),containsKey底层调用了equals方法,查询key中是否包含某个元素,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
boolean res = map.containsKey(3);
System.out.println(res);
}
3.containsValue
方法全称为:boolean containsValue(Object value),查询value中是否包含某个元素,containsValue底层用了equals方法,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
boolean res = map.containsValue("张三");
System.out.println(res);
}
4.get
方法全称为:Object get(Object key),查询key对应的value值,返回value值,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Object o = map.get(3);
System.out.println(o);
}
5.isEmpty
方法全称为:boolean isEmpty(),用来判断map集合中是否为空,若为空则返回true,使用方法如下:
public static void main(String[] args)
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
boolean res = map.isEmpty();
System.out.println(res);
}
6.keySet
方法全称为:Set keySet(),用来获取map集合中所有的key,并将所有的key中存入set集合中,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Set set = map.keySet();
for (Object o : set) {
System.out.println(o);
}
}
7.put
方法全称为:put(Object key,Object value),给map集合中添加键值对,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
}
8.remove
方法全称为:remove(),利用key删除map集合中的元素,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
map.remove(3);
}
9.size
方法全称为:int size(),获取map集合中键值对的个数,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
int i = map.size();
System.out.println(i);
}
10.values
方法全称为:Collection values(),获取map集合中所有的value值,并将value值存入Collection集合中返回,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Collection values = map.values();
//Collection遍历也可用迭代和获取下标的方法
for (Object value : values) {
System.out.println(value);
}
}
11.entrySet
方法全称为:Set(Map.Entry<K,V>) entrySet(),将map集合转换为set集合,set集合中元素的类型是Map.entry<K,V>,Map.Entry和String一样,都是一种类型的名字,只不过Map.Entry是静态内部类,是Map中的静态内部类,使用方法如下:
public static void main(String[] args) {
Map map=new HashMap();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Set set = map.entrySet();
for (Object o : set) {
System.out.println(o);
}
}
输出结果如下:

12.map集合的遍历
第一种方式:
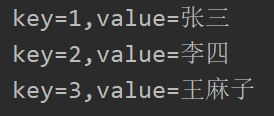
map集合不能迭代,也不能使用foreach,所有只能先获取去所有的key,遍历key然后通过key获取每一个key和value,代码和结果如下:
public static void main(String[] args) {
Map<Integer,String> map=new HashMap<>();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
String value = map.get(key);
System.out.println("key="+key+",value="+value);
}
}
结果:
第二种方式:
把map集合全部转换成set集合,set集合中元素的类型是Map.Entry,取出Map.entry对象之后,可以获取到key和value,代码和结果如下:
public static void main(String[] args) {
Map<Integer,String> map=new HashMap<>();
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
Set<Map.Entry<Integer, String>> entries = map.entrySet();
for (Map.Entry<Integer, String> entry : entries) {
Integer key = entry.getKey();
String value = entry.getValue();
}
}
结果:

三、HashMap源码分析
1.底层数据结构
HashMap的底层数据结构是和哈希表。
数组在查询方面效率很高,随机增删效率很低。单向链表在随机增删方面效率很高,在查询方面效率很低。
哈希表是数组和单向链表的结合体,将以上优势融合在一起。
2.Node结点
HashMap实际上就是Node类型的一个数组,Node是一个静态内部类,Node结点由哈希值、key、value和指向下一个结点的内存地址这四部分组成。
哈希值是HashCode()方法的执行结果,哈希值通过哈希函数(哈希算法)转换成数组的下标。
源码如下:
//静态内部类,类型为HashMap.Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//Node节点结构
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash; //哈希值
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
3.哈希表结构图

4.无序不可重复
前面写的无序不可重复此时可以解释。
无序:HashMap底层是哈希表,一个元素存进来之后不一定会存到哪个单链表上,因此取出的时候也不一定会以什么顺序取出去。
不可重复:HashMap在存入元素时,会将新存入的k与链表中的每一个key进行equals比对,如果重复则覆盖原先的value值。
5.初始化
HashMap集合初始化的数组容量是16,默认加载因子是0.75。
默认加载因子是当HashMap底层数组的容量占了75%以上,数组会自动扩容。
重点**:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的,这是为了达到散列均匀,提高HashMap集合的存取效率。**
源码如下:
/**
* Constructs an empty {@code HashMap} with the default initial capacity (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
6.自动扩容
HashMap集合底层的数组扩容,新容量是旧容量的二倍,新容量为旧容量左移一位,源码如下:

7.key为null
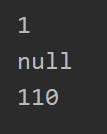
HashMap集合的key是可以为null的,并且重复存储key为null时会覆盖掉原先的value,也可也根据key=null取到value,以下为测试代码和结果:
public static void main(String[] args) {
Map map=new HashMap();
map.put(null,null);
System.out.println(map.size());//1
System.out.println(map.get(null));//null
map.put(null,110);
System.out.println(map.get(null));//110
}
四、hashCode和equals
HahsMap集合使用put方法时,底层会调用hashCode方法将key转换为hash值,然后根据哈希函数/哈希算法将哈希值转换为数组下标,若此下标的数组没有元素,则直接添加,若此下标的数组有链表,则将key与链表中每个节点的key进行equals比对,若都返回false,则将元素添加在链表末尾,若返回true,则将此节点的value覆盖。
1.hashCode方法
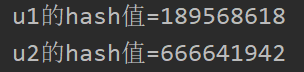
hashCode方法会返回hash值,若一个类未重写hashCode方法,则会使hash值始终不一样,调用的是Object类中的hashCode方法,返回的是内存地址。**重写hashCode方法之后,会根据类的属性进行返回hash值,两个key和value部分内容相同的对象返回的hash值是一样的,key和value部分有任一不相同的对象,返回的hash值是不一样的。**测试代码及结果如下:
1.1 未重写hashCode方法
User类
class User{
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
Objects.equals(name, user.name);
}
}
测试:
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
结果:
1.2 重写hashCode方法
User类
class User{
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
Objects.equals(name, user.name);
}
}
测试类:
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
结果:

当两个key内容不一样时:
测试类:
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"lisi");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
结果:

2.HashMap中hashCode未重写
**如果HashMap集合的key部分类型没有重写hashCode方法时,会给同样内容的key产生不同的hash值,通过哈希函数/哈希算法生成不同的数组下标,进而将同样内容key的HashMap元素添加到不同的数组中,会对不可重复特点造成影响。**以下是这种情况的代码演示及结果:
User类
class User{
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
Objects.equals(name, user.name);
}
}
测试代码:
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println(u1.hashCode());
System.out.println(u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
结果:

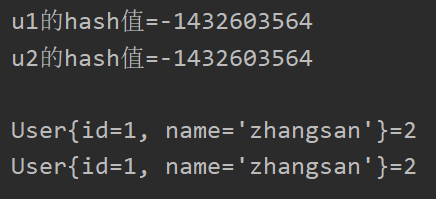
3.HashMap中equals未重写
如果HashMap集合的key部分类型的equals方法未重写而hashCode方法已重写,若添加键值对的key和value均相同,则hash值相同,添加在同一下标的数组中,但由于未重写equals方法,不会被覆盖,以下为代码演示及结果:
User类
class User{
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
测试类
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
结果:
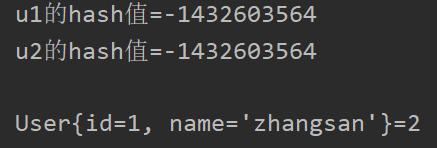
4.HashMap中两方法均重写
当HashMap集合中key部分类型中的hashCode方法和equals方法都重写之后,在添加键值对时,会产生相同的hash值,定位在同一个下标的数组上,但进行equals比对时,后者会将前者覆盖掉,最终只有一个添加成功,以下是代码示例及结果:
User类
class User{
private int id;
private String name;
public User() {
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
测试类
public static void main(String[] args) {
Map<User,Integer> map=new HashMap<>();
User u1=new User(1,"zhangsan");
User u2=new User(1,"zhangsan");
System.out.println("u1的hash值="+u1.hashCode());
System.out.println("u2的hash值="+u2.hashCode());
map.put(u1,2);
map.put(u2,2);
System.out.println();
Set<Map.Entry<User, Integer>> entries = map.entrySet();
for (Map.Entry<User, Integer> entry : entries) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
结果:
四、HashMap重要方法原理
HashMap的底层是哈希表,哈希表其实就是一个Node类型的数组,Node类型中有hash值、key、value和下一个节点的内存四个属性。无论给HashMap中添加还是取出元素,都是对哈希表这个数据结构进行操作,以下是HashMap集合中比较重要的两个方法的原理。
1.put方法
简单介绍在2.7中,这里介绍HashMap在进行添加键值对时的原理,HashMap底层是哈希表,相当于键值对如何向HashMap中添加。
第一步:先将k,v封装在Node对象中。
第二步:底层会调用k的hash()方法得出hash值,然后通过哈希函数/哈希算法将hash值转换为数组的下标,下标位置上如果没有任何元素,那直接将Node添加到这个位置,如果下标位置上有链表,此时就会拿着k和链表上每一个节点进行equals比较,如果所有的equals方法均为false,则此Node添加在这个链表的末尾。如果其中有一个eaquals返回了true,那么就会将此Node的value覆盖掉原先这个节点的value。
2.get方法
简单介绍在2.4中,这里介绍HashMap通过key获取value的原理。
第一步:底层会先通过k的hashCode()方法得出hash值,然后通过哈希函数/哈希算法将hash值转换成数组下标。
第二步:通过数组下标快速定位,如果下标对应的位置没有元素,则直接返回null。如果下标对应的位置有链表,那么会将参数k与链表中每一个节点中的key进行eaquals比对,如果所有的equals方法都返回false,那么get方法返回为null,只要有其中一个方法返回true,那么此时这个节点的value就是要找的value,get方法会返回这个要找的value。
五、HashTable
HashTable集合的所有方法都带有synchronized,是线程安全的,目前线程安全有其他方案,HashTable对线程安全的处理导致效率较低,使用较少。
前面说到HashMap集合的key可以为null,这块的HashTable集合的key和value都不能为null,否则会报空指针异常,value为null会直接抛空指针异常,key要调用hashCode方法,如果为null也会抛空指针异常。

1.初始化
HashTable集合默认初始化数组容量为11,默认加载因子为0.75,源码如下:

2.自动扩容
HashTable集合自动扩容,新容量等于旧容量向左取一位加一,即新容量是旧容量的2倍加1,源码如下:

3.Properties
Properties集合是HashTable集合的子类,也是线程安全的,Properties集合的key和value都是String类型,Properties被成为属性类对象。
3.1常用方法
3.1.1 setProperty
方法全称为:setProperty(String key,String value),其实就相当于HashMap中的put方法,只不过key和value都是String类型的,使用方法如下:
public static void main(String[] args) {
Properties properties=new Properties();
properties.setProperty("url","jdbc:mysql://localhost:3306/mybatis");
properties.setProperty("driver","mysql.cj.jdbc.driver");
properties.setProperty("username","root");
properties.setProperty("password","drldrl521521");
}
3.1.2 getProperty
方法全称为:String getProperty(String key),也是相当于HashMap中的get方法,使用方法如下:
public static void main(String[] args) {
Properties properties=new Properties();
properties.setProperty("url","jdbc:mysql://localhost:3306/mybatis");
properties.setProperty("driver","mysql.cj.jdbc.driver");
properties.setProperty("username","root");
properties.setProperty("password","drldrl521521");
properties.getProperty("url");
properties.getProperty("driver");
properties.getProperty("username");
properties.getProperty("password");
}
六、TreeMap
TreeMap集合继承于SortedMap,特点仍然是无序不重复,并且key部分可以根据大小排序。
自定义类型不能直接存入TreeMap集合中,因为TreeMap集合的put方法底层会强转Compare方法,而自定义类型并没有实现compare方法,所以会报ClassCastException异常,以下为强转源码:

1.比较key的方法
1.1实现comparable接口
由于自定义类型不能直接添加元素,所以需要实现comparable接口,并实现其comparaTo方法,若自定义类中只有int类型属性时,实现代码如下:
class User implements Comparable<User>{
private int id;
public User(int id) {
this.id = id;
}
public User() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id;
}
@Override
public int hashCode() {
return Objects.hash(id);
}
@Override
public String toString() {
return "User{" +
"id=" + id +
'}';
}
@Override
public int compareTo(User o) {
return this.id-o.id;
}
}
若自定义类型中有int和String类型,并且int类型优先,实现代码如下:
class User implements Comparable<User>{
private int id;
private String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
public User() {
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(User o) {
if (this.id==o.id){
return this.name.compareTo(o.name);
}
return this.id-o.id;
}
}
1.2 利用比较器
TreeMap集合添加元素时有两种比较方式,一个上面在类中实现Comparable的conpareTo方法,另外一个是自己写比较器方法并在new的时候传入比较器对象,源码如下:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
//comparator是传入的比较器对象,如果传入比较器对象,则使用此种方式进行比较
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
TreeMap集合底层进行添加元素时,会对key部分进行大小排序,另外一种方式就是自己传比较器,需要实现Comparator接口,并实现其接口下的compare方法,代码如下:
public class Test01 {
public static void main(String[] args) {
TreeSet<User> treeSet=new TreeSet<>(new UserComparator());
treeSet.add(new User(1,"zhangsan"));
treeSet.add(new User(5,"lisi"));
treeSet.add(new User(1,"zhangsi"));
for (User user : treeSet) {
System.out.println(user);
}
}
}
class User {
private int id;
private String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
public User() {
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
//比较器
class UserComparator implements Comparator<User>{
@Override
public int compare(User o1, User o2) {
if(o1.getId()==o2.getId()){
return o1.getName().compareTo(o2.getName());
}
return o1.getId()-o2.getId();
}
}
代码中的比较器也可以换成匿名内部类(这个类没有名字,直接new要实现的接口)来做,代码如下:
public class Test01 {
public static void main(String[] args) {
TreeSet<User> treeSet=new TreeSet<>(new Comparator<User>() {
@Override
//匿名内部类
public int compare(User o1, User o2) {
if (o1.getId()==o2.getId()){
return o1.getName().compareTo(o2.getName());
}
return o1.getId()-o2.getId();
}
});
treeSet.add(new User(1,"zhangsan"));
treeSet.add(new User(5,"lisi"));
treeSet.add(new User(1,"zhangsi"));
for (User user : treeSet) {
System.out.println(user);
}
class i{
}
}
}
class User {
private int id;
private String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
public User() {
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
1.3 如何选择
如果排序方式是一成不变的,是正常的排序方式就使用实现Comparable接口,如果排序规则比较特殊或者有多个时,建议实现Comparator接口。
2.比较原理
TreeMap集合底层会对key部分元素进行大小排序,是因为源码中会对存进来的元素进行Comparable强制类型转换,然后调用compareTo方法返回小于0或者大于0,若小于0则到二叉树的左子树中进行排序,若大于0则到二叉树的右子树中进行排序。
二叉树上遍历是左根右大小顺序的,即左子树>根>右子树
3.自平衡二叉树
自平衡二叉树其实就是二叉树的前序遍历(根、左、右),源码如下:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)