python Pandas_TEXT实验(读取以下4位同学的成绩并用一个数据框变量pd保存,其中成绩保存在一个TXT文件中...)
·
目录
1.(1)读取以下4位同学的成绩并用一个数据框变量pd保存,其中成绩保存在一个TXT文件中,如图所示。
(2)对数据框变量pd进行切片操作,分别获得小红、张明、小江、小李的各科成绩,它们是4个数据框变量,分别记为pd1、pd2、pd3、pd4。
(3)利用数据框中自身的聚合计算方法,计算并获得每个同学各科成绩的平均分,记为M1、M2、M3、M4。
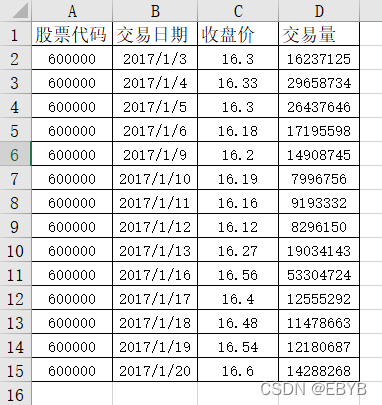
2.(1)读取以下Excel表格的数据并用一个数据框变量df保存,数据内容如下所示。
(2)对df第3列、第4列进行切片,切片后得到一个新的数据框记为df1,并对df1利用自身的方法转换为Numpy数组Nt。
(3)基于df第2列,构造一个逻辑数组TF,即满足交易日期小于等于2017-01-16且大于等于2017-01-05为真,否则为假。
(4)以逻辑数组TF为索引,取数组Nt中的第2列交易量数据并求和,记为S。
1.(1)读取以下4位同学的成绩并用一个数据框变量pd保存,其中成绩保存在一个TXT文件中,如图所示。
文件下载链接 https://pan.baidu.com/s/1kNJ6Vwo5kat52tO7ttDHmA?pwd=sh6r
https://pan.baidu.com/s/1kNJ6Vwo5kat52tO7ttDHmA?pwd=sh6r
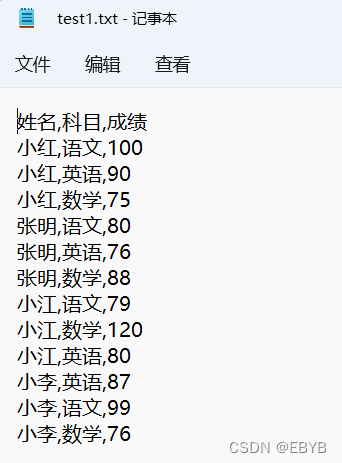
In:import pandas as pd
import numpy as np
pd=pd.read_table('test1.txt',sep=',')
pd
Out: 姓名 科目 成绩
0 小红 语文 100
1 小红 英语 90
2 小红 数学 75
3 张明 语文 80
4 张明 英语 76
5 张明 数学 88
6 小江 语文 79
7 小江 数学 120
8 小江 英语 80
9 小李 英语 87
10 小李 语文 99
11 小李 数学 76
(2)对数据框变量pd进行切片操作,分别获得小红、张明、小江、小李的各科成绩,它们是4个数据框变量,分别记为pd1、pd2、pd3、pd4。
In:pd1=pd.iloc[0:3]
pd1
Out: 姓名 科目 成绩
0 小红 语文 100
1 小红 英语 90
2 小红 数学 75
In:pd2=pd.iloc[3:6]
pd2
Out: 姓名 科目 成绩
3 张明 语文 80
4 张明 英语 76
5 张明 数学 88
In:pd3=pd.iloc[6:9]
pd3
Out: 姓名 科目 成绩
6 小江 语文 79
7 小江 数学 120
8 小江 英语 80
In:pd4=pd.iloc[9:12]
pd4
Out: 姓名 科目 成绩
9 小李 英语 87
10 小李 语文 99
11 小李 数学 76(3)利用数据框中自身的聚合计算方法,计算并获得每个同学各科成绩的平均分,记为M1、M2、M3、M4。
In:M1=pd1.mean()
M1
Out:成绩 88.333333
dtype: float64
In:M2=pd2.mean()
M3=pd3.mean()
M4=pd4.mean()
In:M2
Out:成绩 81.333333
dtype: float64
In:M3
Out:成绩 93.0
dtype: float64
In:M4
Out:成绩 87.333333
dtype: float642.(1)读取以下Excel表格的数据并用一个数据框变量df保存,数据内容如下所示。
文件下载链接https://pan.baidu.com/s/1F59EdzN3X9BQCN53N5R_xw?pwd=73rm
In:df=pd.read_excel('test2.xlsx')
df
Out:
股票代码 交易日期 收盘价 交易量
0 600000 2017-01-03 16.30 16237125
1 600000 2017-01-04 16.33 29658734
2 600000 2017-01-05 16.30 26437646
3 600000 2017-01-06 16.18 17195598
4 600000 2017-01-09 16.20 14908745
5 600000 2017-01-10 16.19 7996756
6 600000 2017-01-11 16.16 9193332
7 600000 2017-01-12 16.12 8296150
8 600000 2017-01-13 16.27 19034143
9 600000 2017-01-16 16.56 53304724
10 600000 2017-01-17 16.40 12555292
11 600000 2017-01-18 16.48 11478663
12 600000 2017-01-19 16.54 12180687
13 600000 2017-01-20 16.60 14288268
(2)对df第3列、第4列进行切片,切片后得到一个新的数据框记为df1,并对df1利用自身的方法转换为Numpy数组Nt。
In:df1=df.iloc[[0,1,2,3,4,5,6,7,8,9,10,11,12,13],[2,3]]
df1
Out:
收盘价 交易量
0 16.30 16237125
1 16.33 29658734
2 16.30 26437646
3 16.18 17195598
4 16.20 14908745
5 16.19 7996756
6 16.16 9193332
7 16.12 8296150
8 16.27 19034143
9 16.56 53304724
10 16.40 12555292
11 16.48 11478663
12 16.54 12180687
13 16.60 14288268
In:Nt=np.array(df1)
Nt
Out:
array([[1.6300000e+01, 1.6237125e+07],
[1.6330000e+01, 2.9658734e+07],
[1.6300000e+01, 2.6437646e+07],
[1.6180000e+01, 1.7195598e+07],
[1.6200000e+01, 1.4908745e+07],
[1.6190000e+01, 7.9967560e+06],
[1.6160000e+01, 9.1933320e+06],
[1.6120000e+01, 8.2961500e+06],
[1.6270000e+01, 1.9034143e+07],
[1.6560000e+01, 5.3304724e+07],
[1.6400000e+01, 1.2555292e+07],
[1.6480000e+01, 1.1478663e+07],
[1.6540000e+01, 1.2180687e+07],
[1.6600000e+01, 1.4288268e+07]])
(3)基于df第2列,构造一个逻辑数组TF,即满足交易日期小于等于2017-01-16且大于等于2017-01-05为真,否则为假。
In:df2=pd.read_excel('test2.xlsx',dtype=str)
index1=df2['交易日期'].values>='2017-01-05'
index2=df2['交易日期'].values<='2017-01-16'
TF=index1&index2
TF
Out:array([False, False, True, True, True, True, True, True, True,
False, False, False, False, False])(4)以逻辑数组TF为索引,取数组Nt中的第2列交易量数据并求和,记为S。
In:S=sum(Nt[TF, 1])
S
Out:103062370.0

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 54
54 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)