
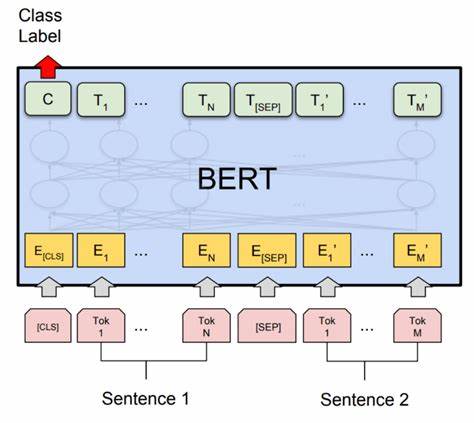
BERT预训练模型的使用
BERT
一键AI生成摘要,助你高效阅读
问答
·
当下NLP中流行的预训练模型
- BERT
- GPT
- GPT-2
- Transformer-XL
- XLNet
- XLM
- RoBERTa
- DistilBERT
- ALBERT
- T5
- XLM-RoBERTa
BERT及其变体
- bert-base-uncased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在小写的英文文本上进行训练而得到.
- bert-large-uncased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在小写的英文文本上进行训练而得到.
- bert-base-cased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在不区分大小写的英文文本上进行训练而得到.
- bert-large-cased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在不区分大小写的英文文本上进行训练而得到.
- bert-base-multilingual-uncased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在小写的102种语言文本上进行训练而得到.
- bert-large-multilingual-uncased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共340M参数量, 在小写的102种语言文本上进行训练而得到.
- bert-base-chinese: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在简体和繁体中文文本上进行训练而得到.
GPT
- openai-gpt: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 由OpenAI在英文语料上进行训练而得到.
- gpt2: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共117M参数量, 在OpenAI GPT-2英文语料上进行训练而得到.
- gpt2-xl: 编码器具有48个隐层, 输出1600维张量, 25个自注意力头, 共1558M参数量, 在大型的OpenAI GPT-2英文语料上进行训练而得到.
Transformer-XL
-transfo-xl-wt103: 编码器具有18个隐层, 输出1024维张量, 16个自注意力头, 共257M参数量, 在wikitext-103英文语料进行训练而得到.
XLNet及其变体
- xlnet-base-cased: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共110M参数量, 在英文语料上进行训练而得到.
- xlnet-large-cased: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共240参数量, 在英文语料上进行训练而得到.
XLM
- xlm-mlm-en-2048: 编码器具有12个隐层, 输出2048维张量, 16个自注意力头, 在英文文本上进行训练而得到.
RoBERTa及其变体
- roberta-base: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到.
- roberta-large: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共355M参数量, 在英文文本上进行训练而得到.
DistilBERT及其变体
- distilbert-base-uncased: 基于bert-base-uncased的蒸馏(压缩)模型, 编码器具有6个隐层, 输出768维张量, 12个自注意力头, 共66M参数量.
- distilbert-base-multilingual-cased: 基于bert-base-multilingual-uncased的蒸馏(压缩)模型, 编码器具有6个隐层, 输出768维张量, 12个自注意力头, 共66M参数量.
ALBERT
- albert-base-v1: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到.
- albert-base-v2: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共125M参数量, 在英文文本上进行训练而得到, 相比v1使用了更多的数据量, 花费更长的训练时间.
T5及其变体
- t5-small: 编码器具有6个隐层, 输出512维张量, 8个自注意力头, 共60M参数量, 在C4语料上进行训练而得到.
- t5-base: 编码器具有12个隐层, 输出768维张量, 12个自注意力头, 共220M参数量, 在C4语料上进行训练而得到.
- t5-large: 编码器具有24个隐层, 输出1024维张量, 16个自注意力头, 共770M参数量, 在C4语料上进行训练而得到.
XLM-RoBERTa及其变体
- xlm-roberta-base: 编码器具有12个隐层, 输出768维张量, 8个自注意力头, 共125M参数量, 在2.5TB的100种语言文本上进行训练而得到.
- xlm-roberta-large: 编码器具有24个隐层, 输出1027维张量, 16个自注意力头, 共355M参数量, 在2.5TB的100种语言文本上进行训练而得到.
预训练模型说明
所有上述预训练模型及其变体都是以transformer为基础,只是在模型结构如神经元连接方式,编码器隐层数,多头注意力的头数等发生改变,这些改变方式的大部分依据都是由在标准数据集上的表现而定,因此,对于我们使用者而言,不需要从理论上深度探究这些预训练模型的结构设计的优劣,只需要在自己处理的目标数据上,尽量遍历所有可用的模型对比得到最优效果即可.
加载和使用预训练模型
加载和使用预训练模型的工具
- 在这里我们使用torch.hub工具进行模型的加载和使用.
- 这些预训练模型由世界先进的NLP研发团队huggingface提供.
加载和使用预训练模型的步骤
第一步: 确定需要加载的预训练模型并安装依赖包.
第二步: 加载预训练模型的映射器tokenizer.
第三步: 加载带/不带头的预训练模型.
第四步: 使用模型获得输出结果.
第一步: 确定需要加载的预训练模型并安装依赖包
这里假设我们处理的是中文文本任务, 需要加载的模型是BERT的中文模型: bert-base-chinese
在使用工具加载模型前需要安装必备的依赖包:
pip install tqdm boto3 requests regex sentencepiece sacremoses
第二步: 加载预训练模型的映射器tokenizer
import torch
# 预训练模型来源
source = 'huggingface/pytorch-transformers'
# 选定加载模型的哪一部分, 这里是模型的映射器
part = 'tokenizer'
# 加载的预训练模型的名字
model_name = 'bert-base-chinese'
tokenizer = torch.hub.load(source, part, model_name)
第三步: 加载带/不带头的预训练模型
- 加载预训练模型时我们可以选择带头或者不带头的模型
- 这里的’头’是指模型的任务输出层, 选择加载不带头的模型, 相当于使用模型对输入文本进行特征表示.
- 选择加载带头的模型时, 有三种类型的’头’可供选择, modelWithLMHead(语言模型头), modelForSequenceClassification(分类模型头), modelForQuestionAnswering(问答模型头)
- 不同类型的’头’, 可以使预训练模型输出指定的张量维度. 如使用’分类模型头’, 则输出尺寸为(1,2)的张量, 用于进行分类任务判定结果.
# 加载不带头的预训练模型
part = 'model'
model = torch.hub.load(source, part, model_name)
# 加载带有语言模型头的预训练模型
part = 'modelWithLMHead'
lm_model = torch.hub.load(source, part, model_name)
# 加载带有类模型头的预训练模型
part = 'modelForSequenceClassification'
classification_model = torch.hub.load(source, part, model_name)
# 加载带有问答模型头的预训练模型
part = 'modelForQuestionAnswering'
qa_model = torch.hub.load(source, part, model_name)
第四步: 使用模型获得输出结果
- 使用不带头的模型进行输出:
# 输入的中文文本
input_text = "人生该如何起头"
# 使用tokenizer进行数值映射
indexed_tokens = tokenizer.encode(input_text)
# 打印映射后的结构
print("indexed_tokens:", indexed_tokens)
# 将映射结构转化为张量输送给不带头的预训练模型
tokens_tensor = torch.tensor([indexed_tokens])
# 使用不带头的预训练模型获得结果
with torch.no_grad():
encoded_layers, _ = model(tokens_tensor)
print("不带头的模型输出结果:", encoded_layers)
print("不带头的模型输出结果的尺寸:", encoded_layers.shape)
- 输出效果
# tokenizer映射后的结果, 101和102是起止符,
# 中间的每个数字对应"人生该如何起头"的每个字.
indexed_tokens: [101, 782, 4495, 6421, 1963, 862, 6629, 1928, 102]
不带头的模型输出结果: tensor([[[ 0.5421, 0.4526, -0.0179, ..., 1.0447, -0.1140, 0.0068],
[-0.1343, 0.2785, 0.1602, ..., -0.0345, -0.1646, -0.2186],
[ 0.9960, -0.5121, -0.6229, ..., 1.4173, 0.5533, -0.2681],
...,
[ 0.0115, 0.2150, -0.0163, ..., 0.6445, 0.2452, -0.3749],
[ 0.8649, 0.4337, -0.1867, ..., 0.7397, -0.2636, 0.2144],
[-0.6207, 0.1668, 0.1561, ..., 1.1218, -0.0985, -0.0937]]])
# 输出尺寸为1x9x768, 即每个字已经使用768维的向量进行了表示,
# 我们可以基于此编码结果进行接下来的自定义操作, 如: 编写自己的微调网络进行最终输出.
不带头的模型输出结果的尺寸: torch.Size([1, 9, 768])
- 使用带有语言模型头的模型进行输出:
# 使用带有语言模型头的预训练模型获得结果
with torch.no_grad():
lm_output = lm_model(tokens_tensor)
print("带语言模型头的模型输出结果:", lm_output)
print("带语言模型头的模型输出结果的尺寸:", lm_output[0].shape)
- 输出效果:
带语言模型头的模型输出结果: (tensor([[[ -7.9706, -7.9119, -7.9317, ..., -7.2174, -7.0263, -7.3746],
[ -8.2097, -8.1810, -8.0645, ..., -7.2349, -6.9283, -6.9856],
[-13.7458, -13.5978, -12.6076, ..., -7.6817, -9.5642, -11.9928],
...,
[ -9.0928, -8.6857, -8.4648, ..., -8.2368, -7.5684, -10.2419],
[ -8.9458, -8.5784, -8.6325, ..., -7.0547, -5.3288, -7.8077],
[ -8.4154, -8.5217, -8.5379, ..., -6.7102, -5.9782, -7.6909]]]),)
# 输出尺寸为1x9x21128, 即每个字已经使用21128维的向量进行了表示,
# 同不带头的模型一样, 我们可以基于此编码结果进行接下来的自定义操作, 如: 编写自己的微调网络进行最终输出.
带语言模型头的模型输出结果的尺寸: torch.Size([1, 9, 21128])
- 使用带有分类模型头的模型进行输出:
# 使用带有分类模型头的预训练模型获得结果
with torch.no_grad():
classification_output = classification_model(tokens_tensor)
print("带分类模型头的模型输出结果:", classification_output)
print("带分类模型头的模型输出结果的尺寸:", classification_output[0].shape)
- 输出效果:
带分类模型头的模型输出结果: (tensor([[-0.0649, -0.1593]]),)
# 输出尺寸为1x2, 可直接用于文本二分问题的输出
带分类模型头的模型输出结果的尺寸: torch.Size([1, 2])
- 使用带有问答模型头的模型进行输出:
# 使用带有问答模型头的模型进行输出时, 需要使输入的形式为句子对
# 第一条句子是对客观事物的陈述
# 第二条句子是针对第一条句子提出的问题
# 问答模型最终将得到两个张量,
# 每个张量中最大值对应索引的分别代表答案的在文本中的起始位置和终止位置.
input_text1 = "我家的小狗是黑色的"
input_text2 = "我家的小狗是什么颜色的呢?"
# 映射两个句子
indexed_tokens = tokenizer.encode(input_text1, input_text2)
print("句子对的indexed_tokens:", indexed_tokens)
# 输出结果: [101, 2769, 2157, 4638, 2207, 4318, 3221, 7946, 5682, 4638, 102, 2769, 2157, 4638, 2207, 4318, 3221, 784, 720, 7582, 5682, 4638, 1450, 136, 102]
# 用0,1来区分第一条和第二条句子
segments_ids = [0]*11 + [1]*14
# 转化张量形式
segments_tensors = torch.tensor([segments_ids])
tokens_tensor = torch.tensor([indexed_tokens])
# 使用带有问答模型头的预训练模型获得结果
with torch.no_grad():
start_logits, end_logits = qa_model(tokens_tensor, token_type_ids=segments_tensors)
print("带问答模型头的模型输出结果:", (start_logits, end_logits))
print("带问答模型头的模型输出结果的尺寸:", (start_logits.shape, end_logits.shape))
- 输出效果:
句子对的indexed_tokens: [101, 2769, 2157, 4638, 2207, 4318, 3221, 7946, 5682, 4638, 102, 2769, 2157, 4638, 2207, 4318, 3221, 784, 720, 7582, 5682, 4638, 1450, 136, 102]
带问答模型头的模型输出结果: (tensor([[ 0.2574, -0.0293, -0.8337, -0.5135, -0.3645, -0.2216, -0.1625, -0.2768,
-0.8368, -0.2581, 0.0131, -0.1736, -0.5908, -0.4104, -0.2155, -0.0307,
-0.1639, -0.2691, -0.4640, -0.1696, -0.4943, -0.0976, -0.6693, 0.2426,
0.0131]]), tensor([[-0.3788, -0.2393, -0.5264, -0.4911, -0.7277, -0.5425, -0.6280, -0.9800,
-0.6109, -0.2379, -0.0042, -0.2309, -0.4894, -0.5438, -0.6717, -0.5371,
-0.1701, 0.0826, 0.1411, -0.1180, -0.4732, -0.1541, 0.2543, 0.2163,
-0.0042]]))
# 输出为两个形状1x25的张量, 他们是两条句子合并长度的概率分布,
# 第一个张量中最大值所在的索引代表答案出现的起始索引,
# 第二个张量中最大值所在的索引代表答案出现的终止索引.
带问答模型头的模型输出结果的尺寸: (torch.Size([1, 25]), torch.Size([1, 25]))
BERT实际使用
指定任务类型的微调脚本:
- huggingface研究机构向我们提供了针对GLUE数据集合任务类型的微调脚本, 这些微调脚本的核心都是微调模型的最后一个全连接层.
- 通过简单的参数配置来指定GLUE中存在任务类型(如: CoLA对应文本二分类, MRPC对应句子对文本二分类, STS-B对应句子对文本多分类), 以及指定需要微调的预训练模型.
指定任务类型的微调脚本使用步骤
第一步: 下载微调脚本文件
第二步: 配置微调脚本参数
第三步: 运行并检验效果
第一步: 下载微调脚本文件
# 克隆huggingface的transfomers文件
git clone https://github.com/huggingface/transformers.git
# 进行transformers文件夹
cd transformers
# 安装python的transformer工具包, 因为微调脚本是py文件.
pip install .
# 当前的版本可能跟我们教学的版本并不相同,你还需要执行:
pip install transformers==2.3.0
# 进入微调脚本所在路径并查看
cd examples
ls
# 其中run_glue.py就是针对GLUE数据集合任务类型的微调脚本
第二步: 配置微调脚本参数
在run_glue.py同级目录下创建run_glue.sh文件, 写入内容如下:
# 定义DATA_DIR: 微调数据所在路径, 这里我们使用glue_data中的数据作为微调数据
export DATA_DIR="../../glue_data"
# 定义SAVE_DIR: 模型的保存路径, 我们将模型保存在当前目录的bert_finetuning_test文件中
export SAVE_DIR="./bert_finetuning_test/"
# 使用python运行微调脚本
# --model_type: 选择需要微调的模型类型, 这里可以选择BERT, XLNET, XLM, roBERTa, distilBERT, ALBERT
# --model_name_or_path: 选择具体的模型或者变体, 这里是在英文语料上微调, 因此选择bert-base-uncased
# --task_name: 它将代表对应的任务类型, 如MRPC代表句子对二分类任务
# --do_train: 使用微调脚本进行训练
# --do_eval: 使用微调脚本进行验证
# --data_dir: 训练集及其验证集所在路径, 将自动寻找该路径下的train.tsv和dev.tsv作为训练集和验证集
# --max_seq_length: 输入句子的最大长度, 超过则截断, 不足则补齐
# --learning_rate: 学习率
# --num_train_epochs: 训练轮数
# --output_dir $SAVE_DIR: 训练后的模型保存路径
# --overwrite_output_dir: 再次训练时将清空之前的保存路径内容重新写入
python run_glue.py \
--model_type BERT \
--model_name_or_path bert-base-uncased \
--task_name MRPC \
--do_train \
--do_eval \
--data_dir $DATA_DIR/MRPC/ \
--max_seq_length 128 \
--learning_rate 2e-5 \
--num_train_epochs 1.0 \
--output_dir $SAVE_DIR \
--overwrite_output_dir
第三步: 运行并检验效果
# 使用sh命令运行
sh run_glue.sh
- 输出效果:
# 最终打印模型的验证结果:
01/05/2020 23:59:53 - INFO - __main__ - Saving features into cached file ../../glue_data/MRPC/cached_dev_bert-base-uncased_128_mrpc
01/05/2020 23:59:53 - INFO - __main__ - ***** Running evaluation *****
01/05/2020 23:59:53 - INFO - __main__ - Num examples = 408
01/05/2020 23:59:53 - INFO - __main__ - Batch size = 8
Evaluating: 100%|█| 51/51 [00:23<00:00, 2.20it/s]
01/06/2020 00:00:16 - INFO - __main__ - ***** Eval results *****
01/06/2020 00:00:16 - INFO - __main__ - acc = 0.7671568627450981
01/06/2020 00:00:16 - INFO - __main__ - acc_and_f1 = 0.8073344506341863
01/06/2020 00:00:16 - INFO - __main__ - f1 = 0.8475120385232745
- 查看$SAVE_DIR的文件内容:
added_tokens.json
checkpoint-450
checkpoint-400
checkpoint-350
checkpoint-200
checkpoint-300
checkpoint-250
checkpoint-200
checkpoint-150
checkpoint-100
checkpoint-50
pytorch_model.bin
training_args.bin
config.json
special_tokens_map.json
vocab.txt
eval_results.txt
tokenizer_config.json
文件解释:
- pytorch_model.bin代表模型参数,可以使用torch.load加载查看;
- traning_args.bin代表模型训练时的超参,如batch_size,epoch等,仍可使用torch.load查看;
- config.json是模型配置文件,如多头注意力的头数,编码器的层数等,代表典型的模型结构,如bert,xlnet,一般不更改;
- added_token.json记录在训练时通过代码添加的自定义token对应的数值,即在代码中使用add_token方法添加的自定义词汇;
- special_token_map.json当添加的token具有特殊含义时,如分隔符,该文件存储特殊字符的及其对应的含义,使文本中出现的特殊字符先映射成其含义,之后特殊字符的含义仍然使用add_token方法映射。
- checkpoint: 若干步骤保存的模型参数文件(也叫检测点文件)。
通过微调脚本微调后模型的使用步骤
第一步: 在https://huggingface.co/join上创建一个帐户
第二步: 在服务器终端使用transformers-cli登陆
第三步: 使用transformers-cli上传模型并查看
第四步: 使用pytorch.hub加载模型进行使用
第一步: 在https://huggingface.co/join上创建一个帐户
username:xxxxx
password:xxxxxx
第二步: 在服务器终端使用transformers-cli登陆
# 在微调模型的服务器上登陆
# 使用刚刚注册的用户名和密码
# 默认username: xxxxx
# 默认password: xxxxx
$ transformers-cli login
第三步: 使用transformers-cli上传模型并查看
# 使用transformers-cli upload命令上传模型
# 选择正确的微调模型路径
$ transformers-cli upload ./bert_finetuning_test/
# 查看上传结果
$ transformers-cli ls
Filename LastModified ETag Size
----------------------------------------------------- ------------------------ ---------------------------------- ---------
bert_finetuning_test/added_tokens.json 2020-01-05T17:39:57.000Z "99914b932bd37a50b983c5e7c90ae93b" 2
bert_finetuning_test/checkpoint-400/config.json 2020-01-05T17:26:49.000Z "74d53ea41e5acb6d60496bc195d82a42" 684
bert_finetuning_test/checkpoint-400/training_args.bin 2020-01-05T17:26:47.000Z "b3273519c2b2b1cb2349937279880f50" 1207
bert_finetuning_test/checkpoint-450/config.json 2020-01-05T17:15:42.000Z "74d53ea41e5acb6d60496bc195d82a42" 684
bert_finetuning_test/checkpoint-450/pytorch_model.bin 2020-01-05T17:15:58.000Z "077cc0289c90b90d6b662cce104fe4ef" 437982584
bert_finetuning_test/checkpoint-450/training_args.bin 2020-01-05T17:15:40.000Z "b3273519c2b2b1cb2349937279880f50" 1207
bert_finetuning_test/config.json 2020-01-05T17:28:50.000Z "74d53ea41e5acb6d60496bc195d82a42" 684
bert_finetuning_test/eval_results.txt 2020-01-05T17:28:56.000Z "67d2d49a96afc4308d33bfcddda8a7c5" 81
bert_finetuning_test/pytorch_model.bin 2020-01-05T17:28:59.000Z "d46a8ccfb8f5ba9ecee70cef8306679e" 437982584
bert_finetuning_test/special_tokens_map.json 2020-01-05T17:28:54.000Z "8b3fb1023167bb4ab9d70708eb05f6ec" 112
bert_finetuning_test/tokenizer_config.json 2020-01-05T17:28:52.000Z "0d7f03e00ecb582be52818743b50e6af" 59
bert_finetuning_test/training_args.bin 2020-01-05T17:28:48.000Z "b3273519c2b2b1cb2349937279880f50" 1207
bert_finetuning_test/vocab.txt 2020-01-05T17:39:55.000Z "64800d5d8528ce344256daf115d4965e" 231508
第四步: 使用pytorch.hub加载模型进行使用
# 若之前使用过huggingface的transformers, 请清除~/.cache
import torch
# 如: ItcastAI/bert_finetuning_test
source = 'huggingface/pytorch-transformers'
# 选定加载模型的哪一部分, 这里是模型的映射器
part = 'tokenizer'
#############################################
# 加载的预训练模型的名字
# 使用自己的模型名字"username/model_name"
# 如:'ItcastAI/bert_finetuning_test'
model_name = 'ItcastAI/bert_finetuning_test'
#############################################
tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', model_name)
model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', model_name)
index = tokenizer.encode("Talk is cheap", "Please show me your code!")
# 102是bert模型中的间隔(结束)符号的数值映射
mark = 102
# 找到第一个102的索引, 即句子对的间隔符号
k = index.index(mark)
# 句子对分割id列表, 由0,1组成, 0的位置代表第一个句子, 1的位置代表第二个句子
segments_ids = [0]*(k + 1) + [1]*(len(index) - k - 1)
# 转化为tensor
tokens_tensor = torch.tensor([index])
segments_tensors = torch.tensor([segments_ids])
# 使用评估模式
with torch.no_grad():
# 使用模型预测获得结果
result = model(tokens_tensor, token_type_ids=segments_tensors)
# 打印预测结果以及张量尺寸
print(result)
print(result[0].shape)
- 输出效果:
(tensor([[-0.0181, 0.0263]]),)
torch.Size([1, 2])
通过微调方式进行迁移学习的两种类型
- 类型一: 使用指定任务类型的微调脚本微调预训练模型, 后接带有输出头的预定义网络输出结果.
- 类型二: 直接加载预训练模型进行输入文本的特征表示, 后接自定义网络进行微调输出结果.
类型一实战演示
- 使用文本二分类的任务类型SST-2的微调脚本微调中文预训练模型, 后接带有分类输出头的预定义网络输出结果. 目标是判断句子的情感倾向.
- 准备中文酒店评论的情感分析语料, 语料样式与SST-2数据集相同, 标签0代表差评, 标签1好评.
- 语料存放在与glue_data/同级目录cn_data/下, 其中的SST-2目录包含train.tsv和dev.tsv
train.tsv
sentence label
早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好,餐厅不分吸烟区.房间不分有无烟房. 0
去的时候 ,酒店大厅和餐厅在装修,感觉大厅有点挤.由于餐厅装修本来该享受的早饭,也没有享受(他们是8点开始每个房间送,但是我时间来不及了)不过前台服务员态度好! 1
有很长时间没有在西藏大厦住了,以前去北京在这里住的较多。这次住进来发现换了液晶电视,但网络不是很好,他们自己说是收费的原因造成的。其它还好。 1
非常好的地理位置,住的是豪华海景房,打开窗户就可以看见栈桥和海景。记得很早以前也住过,现在重新装修了。总的来说比较满意,以后还会住 1
交通很方便,房间小了一点,但是干净整洁,很有香港的特色,性价比较高,推荐一下哦 1
酒店的装修比较陈旧,房间的隔音,主要是卫生间的隔音非常差,只能算是一般的 0
酒店有点旧,房间比较小,但酒店的位子不错,就在海边,可以直接去游泳。8楼的海景打开窗户就是海。如果想住在热闹的地带,这里不是一个很好的选择,不过威海城市真的比较小,打车还是相当便宜的。晚上酒店门口出租车比较少。 1
位置很好,走路到文庙、清凉寺5分钟都用不了,周边公交车很多很方便,就是出租车不太爱去(老城区路窄爱堵车),因为是老宾馆所以设施要陈旧些, 1
酒店设备一般,套房里卧室的不能上网,要到客厅去。 0
dev.tsv
sentence label
房间里有电脑,虽然房间的条件略显简陋,但环境、服务还有饭菜都还是很不错的。如果下次去无锡,我还是会选择这里的。 1
我们是5月1日通过携程网入住的,条件是太差了,根本达不到四星级的标准,所有的东西都很陈旧,卫生间水龙头用完竟关不上,浴缸的漆面都掉了,估计是十年前的四星级吧,总之下次是不会入住了。 0
离火车站很近很方便。住在东楼标间,相比较在九江住的另一家酒店,房间比较大。卫生间设施略旧。服务还好。10元中式早餐也不错,很丰富,居然还有青菜肉片汤。 1
坐落在香港的老城区,可以体验香港居民生活,门口交通很方便,如果时间不紧,坐叮当车很好呀!周围有很多小餐馆,早餐就在中远后面的南北嚼吃的,东西很不错。我们定的大床房,挺安静的,总体来说不错。前台结账没有银联! 1
酒店前台服务差,对待客人不热情。号称携程没有预定。感觉是客人在求他们,我们一定得住。这样的宾馆下次不会入住! 0
价格确实比较高,而且还没有早餐提供。 1
是一家很实惠的酒店,交通方便,房间也宽敞,晚上没有电话骚扰,住了两次,有一次住501房间,洗澡间排水不畅通,也许是个别问题.服务质量很好,刚入住时没有调好宽带,服务员很快就帮忙解决了. 1
位置非常好,就在西街的街口,但是却闹中取静,环境很清新优雅。 1
房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错. 1
- 在run_glue.py同级目录下创建run_cn.sh文件, 写入内容如下:
# 定义DATA_DIR: 微调数据所在路径
export DATA_DIR="../../cn_data"
# 定义SAVE_DIR: 模型的保存路径, 我们将模型保存在当前目录的bert_finetuning文件中
export SAVE_DIR="./bert_cn_finetuning/"
# 使用python运行微调脚本
# --model_type: 选择BERT
# --model_name_or_path: 选择bert-base-chinese
# --task_name: 句子二分类任务SST-2
# --do_train: 使用微调脚本进行训练
# --do_eval: 使用微调脚本进行验证
# --data_dir: "./cn_data/SST-2/", 将自动寻找该路径下的train.tsv和dev.tsv作为训练集和验证集
# --max_seq_length: 128,输入句子的最大长度
# --output_dir $SAVE_DIR: "./bert_finetuning/", 训练后的模型保存路径
python run_glue.py \
--model_type BERT \
--model_name_or_path bert-base-chinese \
--task_name SST-2 \
--do_train \
--do_eval \
--data_dir $DATA_DIR/SST-2/ \
--max_seq_length 128 \
--learning_rate 2e-5 \
--num_train_epochs 1.0 \
--output_dir $SAVE_DIR \
- 运行并检验效果
# 使用sh命令运行
sh run_cn.sh
- 输出效果:
# 最终打印模型的验证结果, 准确率高达0.88.
01/06/2020 14:22:36 - INFO - __main__ - Saving features into cached file ../../cn_data/SST-2/cached_dev_bert-base-chinese_128_sst-2
01/06/2020 14:22:36 - INFO - __main__ - ***** Running evaluation *****
01/06/2020 14:22:36 - INFO - __main__ - Num examples = 1000
01/06/2020 14:22:36 - INFO - __main__ - Batch size = 8
Evaluating: 100%|████████████| 125/125 [00:56<00:00, 2.20it/s]
01/06/2020 14:23:33 - INFO - __main__ - ***** Eval results *****
01/06/2020 14:23:33 - INFO - __main__ - acc = 0.88
- 查看$SAVE_DIR的文件内容:
added_tokens.json
checkpoint-350
checkpoint-200
checkpoint-300
checkpoint-250
checkpoint-200
checkpoint-150
checkpoint-100
checkpoint-50
pytorch_model.bin
training_args.bin
config.json
special_tokens_map.json
vocab.txt
eval_results.txt
tokenizer_config.json
- 使用transformers-cli上传模型:
# 默认username: xxxxx
# 默认password: xxxxx
$ transformers-cli login
# 使用transformers-cli upload命令上传模型
# 选择正确的微调模型路径
$ transformers-cli upload ./bert_cn_finetuning/
- 通过pytorch.hub加载模型进行使用:
import torch
source = 'huggingface/pytorch-transformers'
# 模型名字为'ItcastAI/bert_cn_finetuning'
model_name = 'ItcastAI/bert_cn_finetuning'
tokenizer = torch.hub.load(source, 'tokenizer', model_name)
model = torch.hub.load(source, 'modelForSequenceClassification', model_name)
def get_label(text):
index = tokenizer.encode(text)
tokens_tensor = torch.tensor([index])
# 使用评估模式
with torch.no_grad():
# 使用模型预测获得结果
result = model(tokens_tensor)
predicted_label = torch.argmax(result[0]).item()
return predicted_label
if __name__ == "__main__":
# text = "早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好"
text = "房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错."
print("输入文本为:", text)
print("预测标签为:", get_label(text))
- 输出效果:
输入文本为: 早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好
预测标签为: 0
输入文本为: 房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错.
预测标签为: 1
类型二实战演示
- 直接加载预训练模型进行输入文本的特征表示, 后接自定义网络进行微调输出结果.
- 使用语料和完成的目标与类型一实战相同.
直接加载预训练模型进行输入文本的特征表示:
import torch
# 进行句子的截断补齐(规范长度)
from keras.preprocessing import sequence
source = 'huggingface/pytorch-transformers'
# 直接使用预训练的bert中文模型
model_name = 'bert-base-chinese'
# 通过torch.hub获得已经训练好的bert-base-chinese模型
model = torch.hub.load(source, 'model', model_name)
# 获得对应的字符映射器, 它将把中文的每个字映射成一个数字
tokenizer = torch.hub.load(source, 'tokenizer', model_name)
# 句子规范长度
cutlen = 32
def get_bert_encode(text):
"""
description: 使用bert-chinese编码中文文本
:param text: 要进行编码的文本
:return: 使用bert编码后的文本张量表示
"""
# 首先使用字符映射器对每个汉字进行映射
# 这里需要注意, bert的tokenizer映射后会为结果前后添加开始和结束标记即101和102
# 这对于多段文本的编码是有意义的, 但在我们这里没有意义, 因此使用[1:-1]对头和尾进行切片
indexed_tokens = tokenizer.encode(text[:cutlen])[1:-1]
# 对映射后的句子进行截断补齐
indexed_tokens = sequence.pad_sequences([indexed_tokens], cutlen)
# 之后将列表结构转化为tensor
tokens_tensor = torch.LongTensor(indexed_tokens)
# 使模型不自动计算梯度
with torch.no_grad():
# 调用模型获得隐层输出
encoded_layers, _ = model(tokens_tensor)
# 输出的隐层是一个三维张量, 最外层一维是1, 我们使用[0]降去它.
encoded_layers = encoded_layers[0]
return encoded_layers
- 调用:
if __name__ == "__main__":
text = "早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好"
encoded_layers = get_bert_encode(text)
print(encoded_layers)
print(encoded_layers.shape)
- 输出效果:
tensor([[-1.2282, 1.0551, -0.7953, ..., 2.3363, -0.6413, 0.4174],
[-0.9769, 0.8361, -0.4328, ..., 2.1668, -0.5845, 0.4836],
[-0.7990, 0.6181, -0.1424, ..., 2.2845, -0.6079, 0.5288],
...,
[ 0.9514, 0.5972, 0.3120, ..., 1.8408, -0.1362, -0.1206],
[ 0.1250, 0.1984, 0.0484, ..., 1.2302, -0.1905, 0.3205],
[ 0.2651, 0.0228, 0.1534, ..., 1.0159, -0.3544, 0.1479]])
torch.Size([32, 768])
自定义单层的全连接网络作为微调网络:
- 根据实际经验, 自定义的微调网络参数总数应大于0.5倍的训练数据量, 小于10倍的训练数据量, 这样有助于模型在合理的时间范围内收敛.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
"""定义微调网络的类"""
def __init__(self, char_size=32, embedding_size=768):
"""
:param char_size: 输入句子中的字符数量, 即输入句子规范后的长度128.
:param embedding_size: 字嵌入的维度, 因为使用的bert中文模型嵌入维度是768, 因此embedding_size为768
"""
super(Net, self).__init__()
# 将char_size和embedding_size传入其中
self.char_size = char_size
self.embedding_size = embedding_size
# 实例化一个全连接层
self.fc1 = nn.Linear(char_size*embedding_size, 2)
def forward(self, x):
# 对输入的张量形状进行变换, 以满足接下来层的输入要求
x = x.view(-1, self.char_size*self.embedding_size)
# 使用一个全连接层
x = self.fc1(x)
return x
- 调用:
if __name__ == "__main__":
# 随机初始化一个输入参数
x = torch.randn(1, 32, 768)
# 实例化网络结构, 所有参数使用默认值
net = Net()
nr = net(x)
print(nr)
- 输出效果:
tensor([[0.3279, 0.2519]], grad_fn=<ReluBackward0>)
- 构建训练与验证数据批次生成器:
import pandas as pd
from collections import Counter
from functools import reduce
from sklearn.utils import shuffle
def data_loader(train_data_path, valid_data_path, batch_size):
"""
description: 从持久化文件中加载数据
:param train_data_path: 训练数据路径
:param valid_data_path: 验证数据路径
:param batch_size: 训练和验证数据集的批次大小
:return: 训练数据生成器, 验证数据生成器, 训练数据数量, 验证数据数量
"""
# 使用pd进行csv数据的读取, 并去除第一行的列名
train_data = pd.read_csv(train_data_path, header=None, sep="\t").drop([0])
valid_data = pd.read_csv(valid_data_path, header=None, sep="\t").drop([0])
# 打印训练集和验证集上的正负样本数量
print("训练数据集的正负样本数量:")
print(dict(Counter(train_data[1].values)))
print("验证数据集的正负样本数量:")
print(dict(Counter(valid_data[1].values)))
# 验证数据集中的数据总数至少能够满足一个批次
if len(valid_data) < batch_size:
raise("Batch size or split not match!")
def _loader_generator(data):
"""
description: 获得训练集/验证集的每个批次数据的生成器
:param data: 训练数据或验证数据
:return: 一个批次的训练数据或验证数据的生成器
"""
# 以每个批次的间隔遍历数据集
for batch in range(0, len(data), batch_size):
# 定义batch数据的张量列表
batch_encoded = []
batch_labels = []
# 将一个bitch_size大小的数据转换成列表形式, 并进行逐条遍历
for item in shuffle(data.values.tolist())[batch: batch+batch_size]:
# 使用bert中文模型进行编码
encoded = get_bert_encode(item[0])
# 将编码后的每条数据装进预先定义好的列表中
batch_encoded.append(encoded)
# 同样将对应的该batch的标签装进labels列表中
batch_labels.append([int(item[1])])
# 使用reduce高阶函数将列表中的数据转换成模型需要的张量形式
# encoded的形状是(batch_size*max_len, embedding_size)
encoded = reduce(lambda x, y: torch.cat((x, y), dim=0), batch_encoded)
labels = torch.tensor(reduce(lambda x, y: x + y, batch_labels))
# 以生成器的方式返回数据和标签
yield (encoded, labels)
# 对训练集和验证集分别使用_loader_generator函数, 返回对应的生成器
# 最后还要返回训练集和验证集的样本数量
return _loader_generator(train_data), _loader_generator(valid_data), len(train_data), len(valid_data)
- 调用:
if __name__ == "__main__":
train_data_path = "./cn_data/SST-2/train.tsv"
valid_data_path = "./cn_data/SST-2/dev.tsv"
batch_size = 16
train_data_labels, valid_data_labels, \
train_data_len, valid_data_len = data_loader(train_data_path, valid_data_path, batch_size)
print(next(train_data_labels))
print(next(valid_data_labels))
print("train_data_len:", train_data_len)
print("valid_data_len:", valid_data_len)
- 输出效果:
训练数据集的正负样本数量:
{'0': 1518, '1': 1442}
验证数据集的正负样本数量:
{'1': 518, '0': 482}
(tensor([[[-0.8328, 0.9376, -1.2489, ..., 1.8594, -0.4636, -0.1682],
[-0.9798, 0.5113, -0.9868, ..., 1.5500, -0.1934, 0.2521],
[-0.7574, 0.3086, -0.6031, ..., 1.8467, -0.2507, 0.3916],
...,
[ 0.0064, 0.2321, 0.3785, ..., 0.3376, 0.4748, -0.1272],
[-0.3175, 0.4018, -0.0377, ..., 0.6030, 0.2916, -0.4172],
[-0.6154, 1.0439, 0.2921, ..., 0.5048, -0.0983, 0.0061]]]), tensor([0, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0,
1, 0, 1, 1, 1, 1, 0, 0]))
(tensor([[[-0.1611, 0.9182, -0.3419, ..., 0.6323, -0.2013, 0.0184],
[-0.1224, 0.7706, -0.2386, ..., 0.7925, 0.0444, 0.2160],
[-0.0301, 0.6867, -0.1510, ..., 0.9140, 0.0308, 0.2611],
...,
[ 0.3662, -0.4925, 1.2332, ..., 0.7741, -0.1007, -0.3099],
[-0.0932, -0.8494, 0.6586, ..., 0.1235, -0.3152, -0.1635],
[ 0.5306, -0.5510, 0.3105, ..., 1.2631, -0.5882, -0.1133]]]), tensor([1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 1, 1, 0, 0]))
train_data_len: 2960
valid_data_len: 1000
- 编写训练和验证函数:
import torch.optim as optim
def train(train_data_labels):
"""
description: 训练函数, 在这个过程中将更新模型参数, 并收集准确率和损失
:param train_data_labels: 训练数据和标签的生成器对象
:return: 整个训练过程的平均损失之和以及正确标签的累加数
"""
# 定义训练过程的初始损失和准确率累加数
train_running_loss = 0.0
train_running_acc = 0.0
# 循环遍历训练数据和标签生成器, 每个批次更新一次模型参数
for train_tensor, train_labels in train_data_labels:
# 初始化该批次的优化器
optimizer.zero_grad()
# 使用微调网络获得输出
train_outputs = net(train_tensor)
# 得到该批次下的平均损失
train_loss = criterion(train_outputs, train_labels)
# 将该批次的平均损失加到train_running_loss中
train_running_loss += train_loss.item()
# 损失反向传播
train_loss.backward()
# 优化器更新模型参数
optimizer.step()
# 将该批次中正确的标签数量进行累加, 以便之后计算准确率
train_running_acc += (train_outputs.argmax(1) == train_labels).sum().item()
return train_running_loss, train_running_acc
def valid(valid_data_labels):
"""
description: 验证函数, 在这个过程中将验证模型的在新数据集上的标签, 收集损失和准确率
:param valid_data_labels: 验证数据和标签的生成器对象
:return: 整个验证过程的平均损失之和以及正确标签的累加数
"""
# 定义训练过程的初始损失和准确率累加数
valid_running_loss = 0.0
valid_running_acc = 0.0
# 循环遍历验证数据和标签生成器
for valid_tensor, valid_labels in valid_data_labels:
# 不自动更新梯度
with torch.no_grad():
# 使用微调网络获得输出
valid_outputs = net(valid_tensor)
# 得到该批次下的平均损失
valid_loss = criterion(valid_outputs, valid_labels)
# 将该批次的平均损失加到valid_running_loss中
valid_running_loss += valid_loss.item()
# 将该批次中正确的标签数量进行累加, 以便之后计算准确率
valid_running_acc += (valid_outputs.argmax(1) == valid_labels).sum().item()
return valid_running_loss, valid_running_acc
- 调用并保存模型:
if __name__ == "__main__":
# 设定数据路径
train_data_path = "./cn_data/SST-2/train.tsv"
valid_data_path = "./cn_data/SST-2/dev.tsv"
# 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义SGD优化方法
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 定义训练轮数
epochs = 4
# 定义批次样本数量
batch_size = 16
# 进行指定轮次的训练
for epoch in range(epochs):
# 打印轮次
print("Epoch:", epoch + 1)
# 通过数据加载器获得训练数据和验证数据生成器, 以及对应的样本数量
train_data_labels, valid_data_labels, train_data_len, \
valid_data_len = data_loader(train_data_path, valid_data_path, batch_size)
# 调用训练函数进行训练
train_running_loss, train_running_acc = train(train_data_labels)
# 调用验证函数进行验证
valid_running_loss, valid_running_acc = valid(valid_data_labels)
# 计算每一轮的平均损失, train_running_loss和valid_running_loss是每个批次的平均损失之和
# 因此将它们乘以batch_size就得到了该轮的总损失, 除以样本数即该轮次的平均损失
train_average_loss = train_running_loss * batch_size / train_data_len
valid_average_loss = valid_running_loss * batch_size / valid_data_len
# train_running_acc和valid_running_acc是每个批次的正确标签累加和,
# 因此只需除以对应样本总数即是该轮次的准确率
train_average_acc = train_running_acc / train_data_len
valid_average_acc = valid_running_acc / valid_data_len
# 打印该轮次下的训练损失和准确率以及验证损失和准确率
print("Train Loss:", train_average_loss, "|", "Train Acc:", train_average_acc)
print("Valid Loss:", valid_average_loss, "|", "Valid Acc:", valid_average_acc)
print('Finished Training')
# 保存路径
MODEL_PATH = './BERT_net.pth'
# 保存模型参数
torch.save(net.state_dict(), MODEL_PATH)
print('Finished Saving')
- 输出效果:
Epoch: 1
Train Loss: 2.144986984236597 | Train Acc: 0.7347972972972973
Valid Loss: 2.1898122818128902 | Valid Acc: 0.704
Epoch: 2
Train Loss: 1.3592962406135032 | Train Acc: 0.8435810810810811
Valid Loss: 1.8816152956699324 | Valid Acc: 0.784
Epoch: 3
Train Loss: 1.5507876996199943 | Train Acc: 0.8439189189189189
Valid Loss: 1.8626576719331536 | Valid Acc: 0.795
Epoch: 4
Train Loss: 0.7825378059198299 | Train Acc: 0.9081081081081082
Valid Loss: 2.121698483480899 | Valid Acc: 0.803
Finished Training
Finished Saving
- 加载模型进行使用:
if __name__ == "__main__":
MODEL_PATH = './BERT_net.pth'
# 加载模型参数
net.load_state_dict(torch.load(MODEL_PATH))
# text = "酒店设备一般,套房里卧室的不能上网,要到客厅去。"
text = "房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错."
print("输入文本为:", text)
with torch.no_grad():
output = net(get_bert_encode(text))
# 从output中取出最大值对应的索引
print("预测标签为:", torch.argmax(output).item())
- 输出效果:
输入文本为: 房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错.
预测标签为: 1
输入文本为: 酒店设备一般,套房里卧室的不能上网,要到客厅去。
预测标签为: 0

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)