
CUDA11.4安装pytorch,亲测有效!
win10 CUDA11.4 NVDIA GeForce MX150安装并使用pyttorch,保姆教程,还有例子使用体验!
如何使用GPU跑pytorch?
首先,我们介绍一下什么是GPU:
GPU(Graphics Processing Unit),中文名称是“图形处理器”,全称“图形处理单元”,它是一种专门用于图形渲染和计算的处理器。在深度学习和机器学习中,GPU也被广泛应用于加速计算,特别是对于大规模数据和复杂模型的训练和推断。
紧接着我们看看电脑是否有GPU:(以Windows10举例)
快捷键:ctrl+Alt+Delect 启动任务管理器

 好,如果你的电脑有GPU,就可以进行下一步了。如果没有,Pytorch也支持cpu版本的,可以去官网下载或者直接pip 官网地址:https://pytorch.org/
好,如果你的电脑有GPU,就可以进行下一步了。如果没有,Pytorch也支持cpu版本的,可以去官网下载或者直接pip 官网地址:https://pytorch.org/

接着我们介绍一下Pytorch

- Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。Torch 是一个经典的对多维矩阵数据进行操作的张量(tensor库,在机器学习和其他数学密集型应用有广泛应用。
- Pytorch的计算图是动态的,可以根据计算需要实时改变计算图。
- 由于Torch语言采用 Lua,导致在国内一直很小众,并逐渐被支持 Python 的 Tensorflow 抢走用户。作为经典机器学习库 Torch 的端口,PyTorch 为 Python 语言使用者提供了舒适的写代码选择。
好,有了以上的基本知识,接下来可以尝试使用一下。
首先打开Terminal 查看nvida的驱动和CUDA的版本:nvidia-smi

我的电脑配置是:win10 NVIDIA GeForce MX150 CUDA11.4
网上找了一圈都没有cuda11.4对应的pytorch版本,后面没办法,想着cuda应该也是向下兼容,于是找了一个wheel,下载了一个cuda11.3+torch-1.10.2+python3.8的
网址:https://download.pytorch.org/whl/torch/


 接下来就可以用上你的GPU啦!
接下来就可以用上你的GPU啦!
以神经网络举个例子:
#创建一个模型
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
import time
"""
@contact: 微信 XQCqazwsx
@time: 2024/3/8 22:30
@author: 瑞翼工人
"""
class Net(nn.Module):
def __init__(self, input_dim, output_dim):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_dim, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 32)
self.fc4 = nn.Linear(32, output_dim)
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.relu(self.fc3(x))
x = self.softmax(self.fc4(x))
return x
# 将数据转换为PyTorch的张量并移到GPU上
X_tensor = torch.tensor(X_scaled, dtype=torch.float32).to('cuda')
y_tensor = torch.tensor(y_encoded, dtype=torch.int64).to('cuda')
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 20
batch_size = 64
for epoch in range(num_epochs):
for i in range(0, len(X_train), batch_size):
inputs = X_train[i:i+batch_size]
labels = y_train[i:i+batch_size]
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印每个epoch的损失
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# 在测试集上评估模型
with torch.no_grad():
outputs = model(X_test)
_, predicted = torch.max(outputs, 1)
accuracy = (predicted == y_test).sum().item() / len(y_test)
print('Test Accuracy: {:.2f}%'.format(accuracy * 100))
"""
@contact: 微信 XQCqazwsx
@time: 2024/3/8 22:30
@author: 瑞翼工人
"""

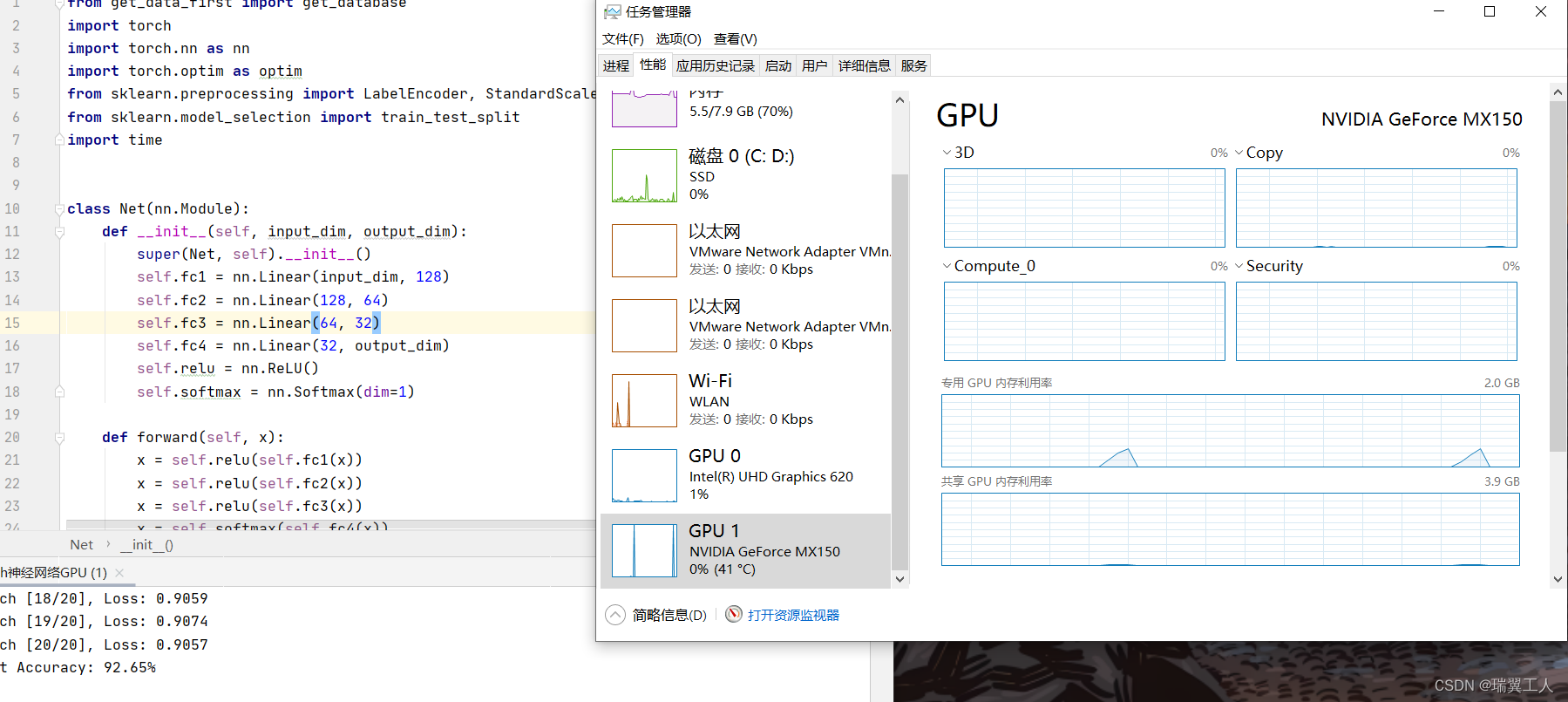
可以从任务管理器中看到GPU的利用率,现在我们的数据还比较小,数据量超过以G为单位的时候,就能看到跟cpu一样的利用,时间上也比cpu块很多!
好了,这篇文章到此结束。如果对你有帮助,请给我点一个免费的赞,谢谢!如果能关注一下就更好了,让我们一起编程改变世界!!!
“”"
@contact: 微信 XQCqazwsx
@time: 2024/2/29 19:30
@author: 瑞翼工人
“”"

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)