

如何根据模型参数量估计需要的显存?
最近大模型发布的很频繁,各种排行榜几乎天天在变化,你方唱罢我登场,好不热闹。我现在有一张老破小的显卡,看到新发布了个模型,如何根据参数量粗略判断能不能运行起来?
最近大模型发布的很频繁,各种排行榜几乎天天在变化,你方唱罢我登场,好不热闹。
我现在有一张老破小的显卡,看到新发布了个模型,如何根据参数量粗略判断能不能运行起来?

只进行推理
如果只是进行推理的话,还是比较容易计算的。
目前模型的参数绝大多数都是float32类型, 占用4个字节。所以一个粗略的计算方法就是,每10亿个参数,占用4G显存(实际应该是10^9*4/1024/1024/1024=3.725G,为了方便可以记为4G)。
比如LLaMA的参数量为7000559616,那么全精度加载这个模型参数需要的显存为:
7000559616 * 4 /1024/1024/1024 = 26.08G
这个数字就有点尴尬,专注游戏的Geforce系列最高只有24G,运行不起来,至少得上Tesla系列了。
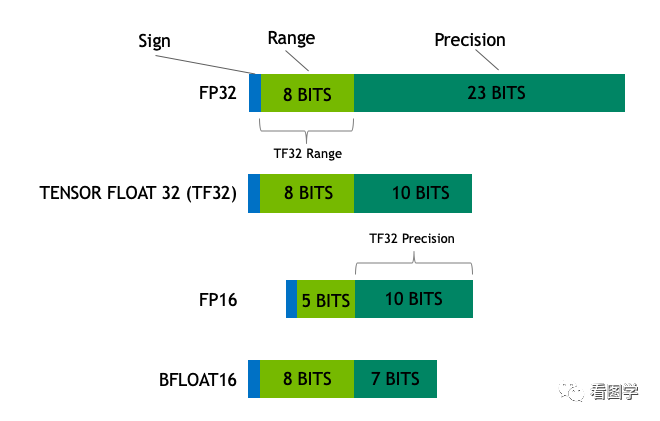
好在我们可以才用半精度的FP16/BF16来加载,这样每个参数只占2个字节,所需显存就降为一半,只需要13.04G。游戏学习两不误。
半精度是个不错的选择,显存少了一半,模型效果因为精度的原因会略微降低,但一般在可接受的范围之内。
如果有个3070显卡,8G显存,还有的玩么?可以玩,采用int8的精度,显存再降一半,仅需6.5G,但是模型效果会更差一些。
我的PC机大概10年前配的,GTX 960 4G,当时最顶配!然而现在只能玩玩int4精度,显存再降一半,仅需3.26G。当年我可是花了千把块买的,虽说只能勉强推理7B的大模型,但是也算是上车了。
目前int4就是最低精度了,再往下效果就很难保证了。比如百川给的量化结果对比如下:

注意上面只是加载模型到显存,模型运算时的一些临时变量也需要申请空间,比如你beam search的时候。所以真正做推理的时候记得留一些Buffer,不然就容易OOM。
如果显存还不够,就只能采用Memery Offload的技术,把部分显存的内容给挪到内存,但是这样会显著降低推理速度。
懒人记法表(粗估,有误差)
| dtype | 每10亿参数需要占用内存 |
|---|---|
| float32 | 4G |
| fp16/bf16 | 2G |
| int8 | 1G |
| int4 | 0.5G |
我还想训练

训练的话就有点复杂了,因为模型训练的时候显存使用包括如下几部分:
-
模型权重,计算方法和上面一样。
-
优化器。
-
如果你采用AdamW,每个参数需要占用8个字节,因为需要维护两个状态。也就说优化器使用显存是全精度(float32)模型权重的2倍。
-
如果采用bitsandbytes优化的AdamW,每个参数需要占用2个字节,也就是全精度(float32)模型权重的一半。
-
如果采用SGD,则优化器占用显存和全精度模型权重一样。
-
-
梯度
-
梯度占用显存和全精度(float32)模型权重一样。
-
-
计算图内部变量(有时候也叫Forward Activations)
-
pytorch/tensorflow等框架采用图结构来计算,图节点在forward和backward的时候需要存储,所以也需要占用显存。
-
比如下面代码
y = self.net_a(x) z = self.net_b(y) -
这里面中间的x, y, z都需要存储,但是如果写成下面这样,y就不用存储了。
z = self.net_b(selt.net_a(x)) -
理论上一个net block可以完全用函数给包裹起来,不使用中间变量。下一代计算框架是函数式编程语言?
-
所以这一部分跟模型具体的实现有关系,而且 正比于batch_size 。batch_size越大,这一部分占用的越多。同样的结论也适用于sequence length。
-
-
一些临时显存占用,先不计算。
所以说,如果模型想要训练,只看前3部分,需要的显存是至少推理的3-4倍。7B的全精度模型加载需要78G ~ 104G。
然后计算图内部变量这一部分只能在运行时候观测了,可以两个不同的batch的占用显存的差值大概估算出来。
以上就是根据模型参数估计显存的大概方法,实际影响显存占用的因素还有很多,所以只能粗略估计个数量级。
剖析完训练时显存占用情况后,优化的思路也就有了,目前市面上主流的一些计算加速的框架如DeepSpeed, Megatron等都在降低显存方面做了很多优化工作,比如量化,模型切分,混合精度计算,Memory Offload等等,大家感兴趣后续可以再给大家分享。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)