

【机器学习】解释你的机器学习模型!以力导向图可视化随机森林分类器的SHAP值为例
在机器学习领域,理解模型是至关重要的一环。SHAP(SHapley Additive exPlanations)是一个强大的工具,可用于解释模型的预测结果。本文将介绍如何使用SHAP库解释随机森林分类器的预测结果。
一键AI生成摘要,助你高效阅读
问答
·
解析随机森林分类器的SHAP值
前言
关于SHAP库的介绍
SHAP(SHapley Additive exPlanations)是一个流行的Python库,用于解释机器学习模型的预测。它基于博弈论中的沙普利值,为模型预测提供直观的解释。以下是一些常见的使用案例:
-
特征重要性解释:
- SHAP可以用来识别对模型预测最有影响的特征。
- 它提供了一种方法来计算每个特征对每个预测的贡献,并将这些贡献可视化。
- 模型诊断:
- 通过分析特征对模型预测的贡献,SHAP有助于识别模型中的潜在偏见或错误。
- 例如,如果模型过于依赖某个不太相关的特征,SHAP可以帮助揭示这一点。
- 结果解释:
- 对于给定的预测,SHAP能够展示每个特征是如何推动模型预测向正面或负面方向发展的。
- 这对于解释复杂模型的单个预测非常有用,例如在医疗或金融领域。
-
模型比较:
- SHAP可以用来比较不同模型的特征重要性,这有助于选择最佳模型或进行模型融合。
-
可视化工具:
- SHAP提供了多种可视化工具,如
力导向图(force plots)、总结图(summary plots)和依赖图(dependence plots),这些工具有助于更好地理解模型的行为。
- SHAP提供了多种可视化工具,如
- 交互式探索:
- SHAP还支持创建交互式可视化,这对于更深入地探索和理解模型特别有用。
- 自定义模型支持:
- 虽然SHAP支持许多常用的机器学习模型,但它也允许用户为自定义模型创建解释器。
- 在使用SHAP时,需要注意的一点是计算成本。对于大型模型或数据集,SHAP分析可能会非常耗时。因此,实际应用中可能需要考虑适当的抽样或优化技术。
关于本文
在机器学习领域,理解模型是至关重要的一环。SHAP(SHapley Additive exPlanations)是一个强大的工具,可用于解释模型的预测结果。本文将介绍如何使用SHAP库解释随机森林分类器的在鸢尾花数据集上的预测结果。
步骤一:准备工作
首先,安装依赖库:
pip install shap
pip install scikit-learn
pip install pandas
pip install numpy
pip install matplotlib
导入所需的库:
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
步骤二:加载数据
使用鸢尾花数据集进行演示:
data = load_iris()
X, y = data.data, data.target
feature_names = data.feature_names
target_names = data.target_names
# 下面将特征值转为DataFrame是为了在可视化的时候能够直接绘制出特征名称。
X = pd.DataFrame(X, columns=feature_names)
步骤三:拆分数据集
将数据集分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
步骤四:训练模型
使用随机森林分类器进行模型训练:
model = RandomForestClassifier()
model.fit(X_train, y_train)
步骤五:SHAP值解释
创建SHAP解释器并计算测试集的SHAP值:
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
将SHAP值转换为NumPy数组:
# 因为在博主所用的版本中,shap_values()返回的是一个list,
# 想要享受numpy的便利就必须转为ndarray。
# 吐槽:这很神奇......因为印象中的机器学习库都会返回ndarray或者DataFrame。
shap_values = np.array(shap_values)
步骤六:选择一个实例进行解释
选择一个实例,并获取其预测类别和类别名称:
instance_index = 0
instance = X_test.iloc[[instance_index]]
predicted_class = model.predict(instance)[0]
predicted_class_name = target_names[predicted_class]
步骤七:可视化解释
使用force plot可视化第一个预测的解释:
# 一个简单的函数,为了减少代码量而生,功能是快速绘制出带有特征名称及类别名称的各个力导向图。
def plot_force_with_names(predicted_class, predicted_class_name, instance_index, instance):
"""
:param predicted_class: 模型输出的类型,用数值表示
:param predicted_class_name: 预测出的类型的名称
:param instance_index: 实例所对应的位置索引,用于获取对应的shap_value。
:param instance: 包含该实例的各个特征名称以及特征值的DataFrame
:return:
"""
shap.initjs()
shap.force_plot(explainer.expected_value[predicted_class], shap_values[predicted_class, instance_index], instance, show=False, matplotlib=True)
# 显示带有目标名称的force plot标题
plt.title(f'Force plot for prediction: {predicted_class_name}')
plt.show()
for clss_index in range(len(target_names)):
class_name = target_names[clss_index]
plot_force_with_names(clss_index, class_name, instance_index, instance)
可视化结果
山鸢尾(setosa)
可以看到该样本的特征不断将随机森林的决策远离山鸢尾。

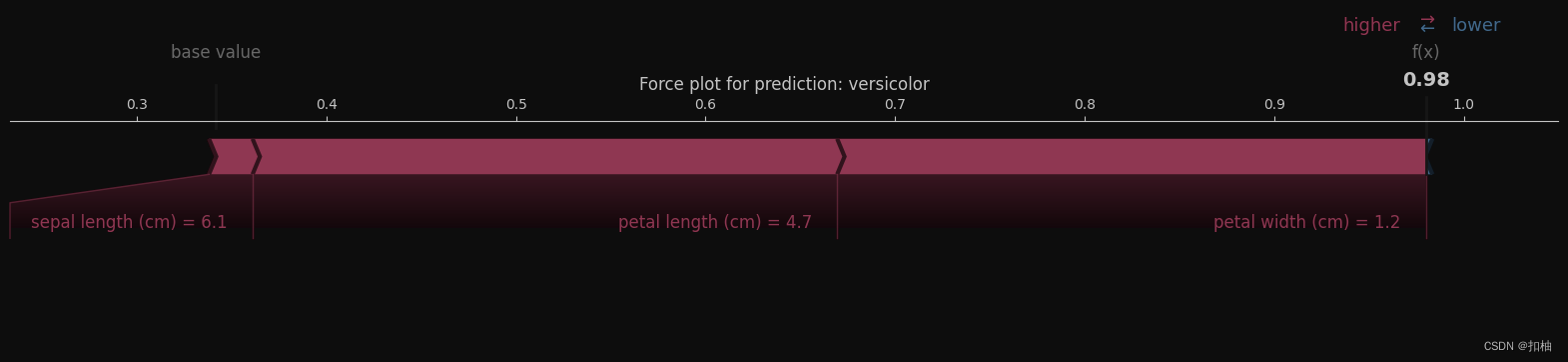
变色鸢尾(versicolor)
可以看到该样本的特征不断将随机森林的决策推向变色鸢尾。
维吉尼亚鸢尾(virginica)
可以看到该样本的特征不断将随机森林的决策远离维吉尼亚鸢尾。
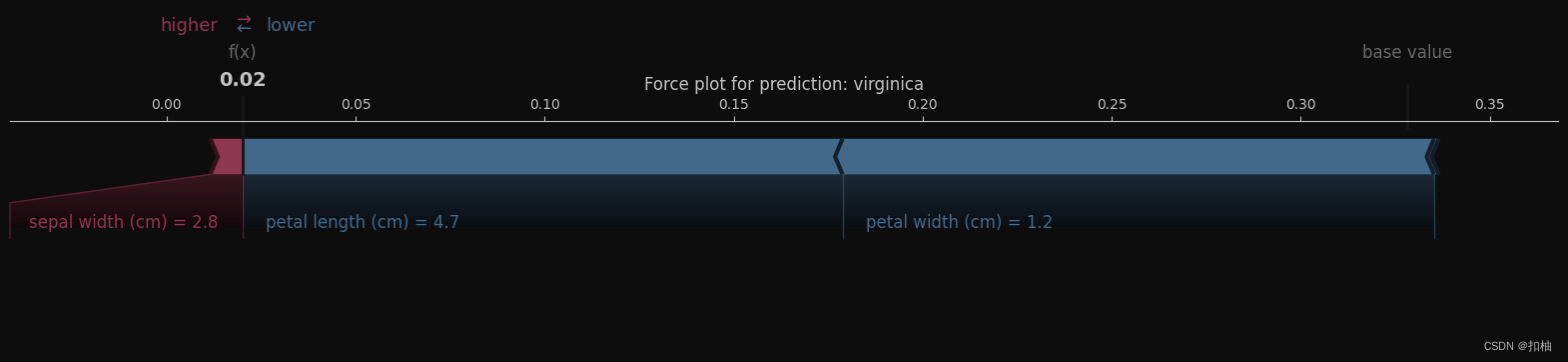
这三个图展示了该随机森林模型的四个特征(花萼的长度、宽度,以及花瓣的长度、宽度)对决策的影响方向。
Force plot(力导向图)的相关概念解释
- 基线值(base value):表示在没有任何特征影响的情况下,模型的平均预测值。
- 箭头:每个特征的贡献,指向预测结果的方向,长度表示贡献的重要性。
- 输出值(f(x)):模型对这个特定实例的实际预测结果。
结论
通过以上步骤,我们成功地使用SHAP库解释了随机森林分类器的预测结果。这种解释有助于深入了解模型如何进行预测,增强模型的可解释性,从而提高对模型的信任度。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)