
大模型推理常见采样策略:Top-k, Top-p, Temperature, Beam Search
大模型推理采样策略,举例通俗易懂汇总介绍
一键AI生成摘要,助你高效阅读
问答
·
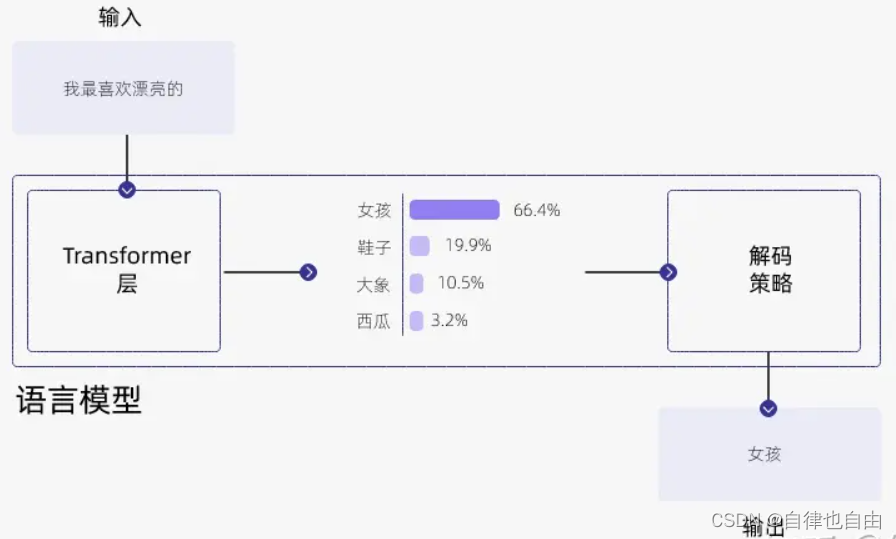
在大模型训练好之后,如何对训练好的模型进行解码(decode)是一个重要问题。
大模型输出过程
大模型根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,模型会逐个预测每个 token,直到达到一个终止条件(如一个标点符号或一个最大长度)。在每一步,模型会给出一个概率分布,表示它对下一个单词的预测概率。
为什么要进行不同的采样策略
进行不同的采样策略可以对生成文本的多样性和质量进行调控,以满足不同的需求和应用场景。通过选择不同的采样策略,可以平衡生成文本的多样性和质量。贪婪采样适用于需要高准确性的任务,而温度采样、Top-k 采样和Top-p 采样则可以在一定程度上增加生成文本的多样性,使得输出更加丰富和有趣。具体选择哪种采样策略取决于应用的需求和期望的输出效果。
采样策略介绍
1.Greedy search
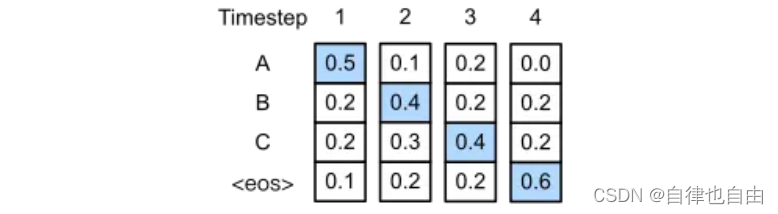
- 思路:直接选择分布中概率最大的token当作解码出来的词,但是该问题在于,总是选择概率最大的词,将会生成很多重复的句子
- 优点:计算简单高效
- 缺点:文本重复,没有多样性
2.Beam Search(集束搜索)
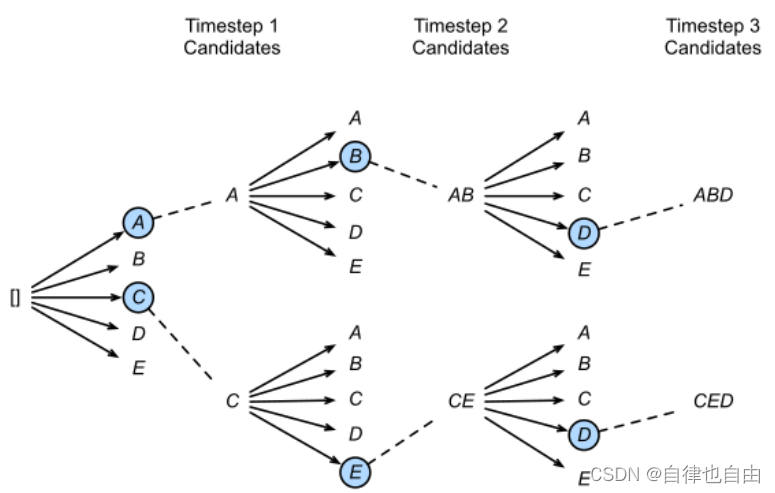
- 思路:beam search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率,但缺点就是有可能存在潜在的最佳方案被丢弃,因此Beam Search算法是不完全的,一般用于解空间较大的系统中。
- 优点:不仅仅关注当下的策略,一定程度上保证了最终得到的序列概率是最优的。
- 缺点:Beam Search虽然比贪心强了不少,但还是会生成出空洞、重复、前后矛盾的文本。
3.Top-k抽样
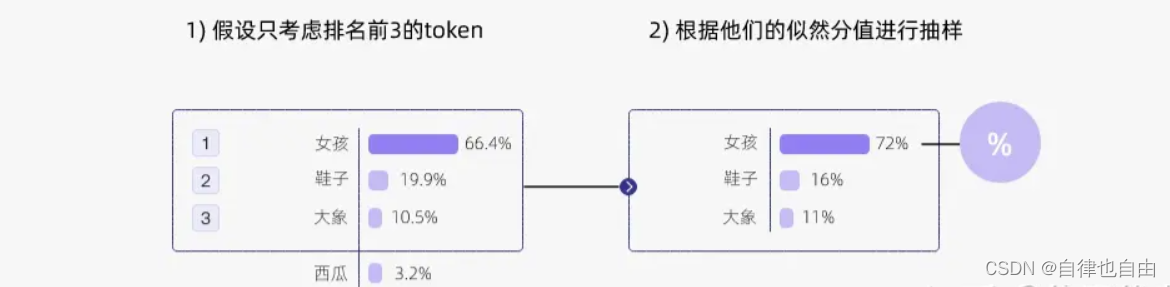
- 思路:从 tokens 里选择 k 个作为候选,然后根据它们的 likelihood scores 来采样模型从最可能的"k"个选项中随机选择一个,如果k=3,模型将从最可能的3个单词中选择一个
- 优点:Top-k 采样是对前面“贪心策略”的优化,它从排名前 k 的 token 中进行抽样,允许其他分数或概率较高的token 也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
- 缺点:在分布陡峭的时候仍会采样到概率小的单词,或者在分布平缓的时候只能采样到部分可用单词。k不太好选:k设置越大,生成的内容可能性越大;k设置越小,生成的内容越固定;设置为1时,和 greedy decoding 效果一样。
4.Top-p抽样——核采样(Nucleus Sampling)
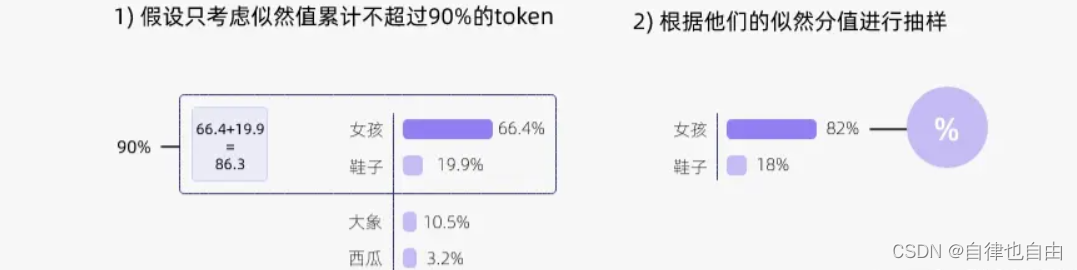
- 思路:候选词列表是动态的,从 tokens 里按百分比选择候选词,模型从累计概率大于或等于“p”的最小集合中随机选择一个,如果p=0.9,选择的单词集将是概率累计到0.9的那部分。
- top-P采样方法往往与top-K采样方法结合使用,每次选取两者中最小的采样范围进行采样,可以减少预测分布过于平缓时采样到极小概率单词的几率。如果k和p都启用,则p在k之后起作用。
- top-P越高,候选词越多,多样性越丰富。top-P越低,候选词越少,越稳定
- 优点:top-k 有一个缺陷,那就是“k 值取多少是最优的?”非常难确定。于是出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)。
- 缺点:采样概率p设置太低模型的输出太固定,设置太高,模型输出太过混乱。
5.Temperature
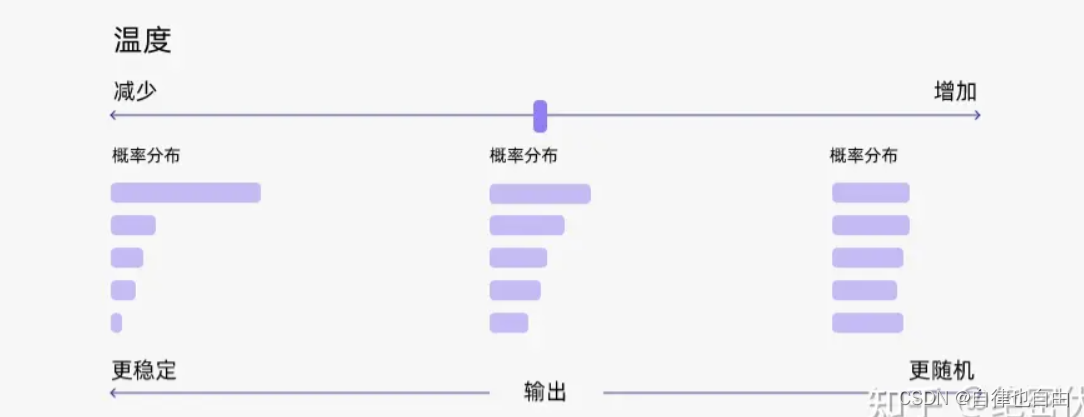
- 思路:通过温度,在采样前调整每个词的概率分布。温度越低,概率分布差距越大,越容易采样到概率大的字。温度越高,概率分布差距越小,增加了低概率字被采样到的机会。
- 参数:temperature(取值范围:0-1)设的越高,生成文本的自由创作空间越大,更具多样性。温度越低,生成的文本越偏保守,更稳定。
- 一般来说,prompt 越长,描述得越清楚,模型生成的输出质量就越好,置信度越高,这时可以适当调高 temperature 的值;反过来,如果 prompt 很短,很含糊,这时再设置一个比较高的 temperature 值,模型的输出就很不稳定了。
6.联合采样(top-k & top-p & Temperature)
- 思路:通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
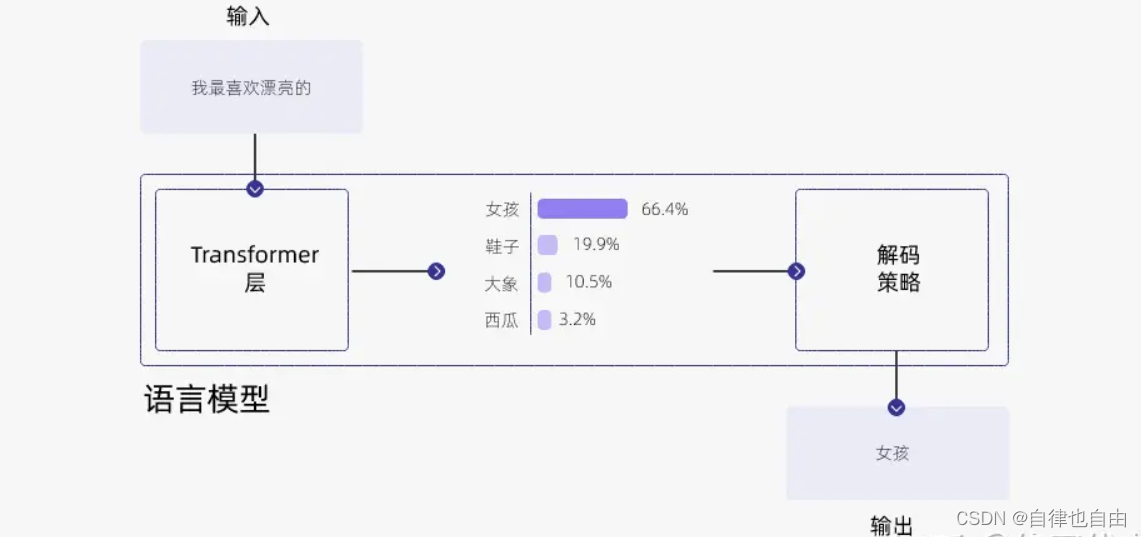
- 首先我们设置 top-k = 3,表示保留概率最高的3个 token。这样就会保留女孩、鞋子、大象这3个 token。
女孩:0.664
鞋子:0.199
大象:0.105 - 接下来,我们可以使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。接着我们使用 Temperature = 0.7 进行归一化,变成:
女孩:0.660
鞋子:0.340 - 接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)