[LLM]大模型训练DeepSpeed(二)
[LLM]大模型训练DeepSpeed(一)-原理介绍-CSDN博客
[LLM]大模型训练DeepSpeed(二)_deepspeed可以自动保存和恢复模型-CSDN博客
[LLM]大模型训练DeepSpeed(三)_deepspeed的hostfile-CSDN博客
安装DeepSpeed与集成
DeepSpeed可以通过pip安装,无需指定PyTorch和CUDA的版本。DeepSpeed内包含需要自定义的CUDA算子,将通过即时编译的方式在运行时构建。
pip install deepspeedDeepSpeed与HuggingFace Transformers直接集成。使用者可以通过在模型训练命令中加入简单的 --deepspeed 标志和配置文件,来轻松加速模型训练。
安装后可以通过ds_report验证算子兼容性,回显实例如下:
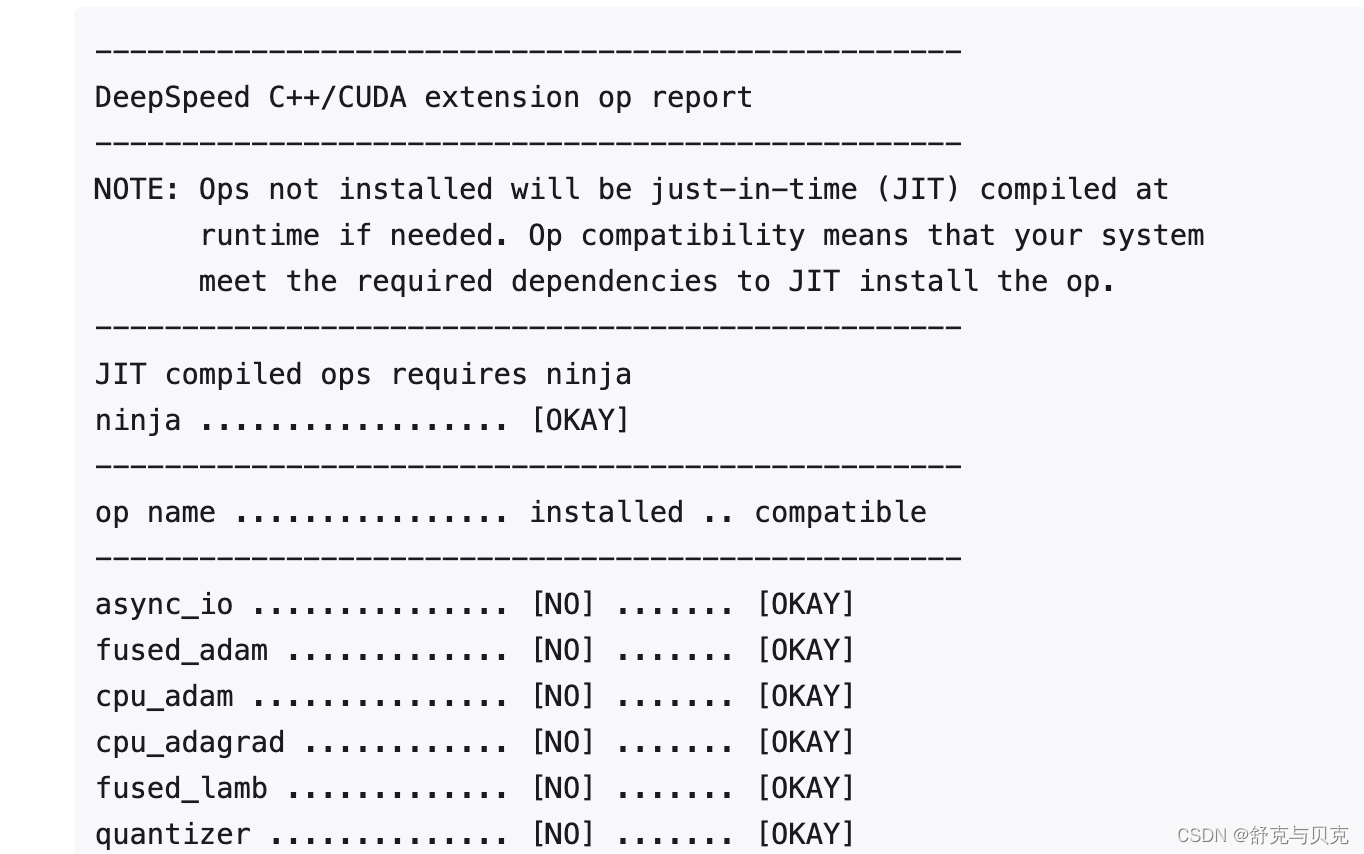
编写DeepSpeed模型
DeepSpeed是微软推出的大规模模型分布式训练的工具,主要实现了ZeRO并行训练算法。
本文旨在简要地介绍Deepspeed进行大规模模型训练的核心理念,以及最基本的使用方法。更多内容,笔者强烈建议阅读HuggingFace Transformer官网对于DeepSpeed的教程:
Transformer DeepSpeed Integration
原始文档链接:DeepSpeed Integration (huggingface.co)
DeepSpeed模型训练的核心是什么?它如何处理模型的初始化以及训练优化器、数据加载器和学习率调度器?对于分布式环境的设置,需要注意哪些细节?
DeepSpeed模型训练的核心在于DeepSpeed引擎,它能够包装任意类型为torch.nn.module的模型,并提供了一组最小的API用于训练和模型检查点。
在模型初始化方面,使用 `deepspeed.initialize()` 方法可以实现DeepSpeed引擎的初始化。此方法涵盖了训练优化器、数据加载器和学习率调度器的设置。具体来说:
模型初始化:
- 使用 `deepspeed.initialize()` 方法可以初始化DeepSpeed引擎。它接受参数并自动处理分布式数据并行或混合精度训练所需的所有设置。该方法包装模型并配置训练优化器、数据加载器和学习率调度器。

- 训练优化器、数据加载器和学习率调度器:
- DeepSpeed能够构建和管理训练优化器、数据加载器和学习率调度器,根据传递给 `deepspeed.initialize()` 方法和DeepSpeed配置文件中的参数进行设置。
- 深度学习引擎会根据传递给它的参数以及配置文件,自动执行学习率调度器中的学习率更新。 - 分布式环境的设置注意事项:
- 在分布式环境中,使用 `deepspeed.init_distributed()` 方法替换了通常的 `torch.distributed.init_process_group()` 方法来初始化分布式设置。如果已经有分布式环境设置,可以在 `deepspeed.initialize()` 之前调用,DeepSpeed在初始化时会自动处理分布式环境设置。
- 默认情况下,DeepSpeed使用NCCL后端进行分布式训练,但也可以覆盖默认设置。
需要注意的是,DeepSpeed引擎的关键在于简化了模型训练的流程,尤其是在分布式环境下。它通过`deepspeed.initialize()`方法集成了模型初始化、优化器设置、数据加载器和学习率调度器配置等步骤,使得用户能够更轻松地完成模型训练并且支持分布式环境下的加速训练。
训练过程
DeepSpeed引擎的训练过程包括哪些关键步骤?在训练过程中,DeepSpeed是如何处理分布式数据并行训练、混合精度等方面的细节?
DeepSpeed引擎的训练过程包括以下关键步骤:
- 初始化引擎:
使用 deepspeed.initialize 方法对引擎进行初始化。该方法包含参数设置、模型初始化和引擎构建,通过传递参数来指定分布式数据并行或混合精度训练等设置。 - 数据加载和分布式训练:
- 引擎利用数据加载器(data_loader)迭代训练数据。
- 在使用 model_engine(batch) 进行前向传播(forward)计算损失值时,DeepSpeed自动进行分布式数据并行训练,保证梯度在训练批次上进行平均。
3. 梯度反向传播和优化:
- 使用 model_engine.backward(loss) 进行梯度反向传播(backward),计算存储梯度。
- 接着使用 model_engine.step() 来执行权重更新,即优化器的步进操作。
for step, batch in enumerate(data_loader):
#forward() method
loss = model_engine(batch)
#runs backpropagation
model_engine.backward(loss)
#weight update
model_engine.step()在训练过程中,DeepSpeed处理以下方面的细节:
- 分布式数据并行训练:DeepSpeed引擎自动在多个设备或多个节点上执行数据并行训练,确保模型在各个设备上同步更新,实现分布式训练。
- 混合精度训练:在使用 FP16 或混合精度训练时,DeepSpeed会自动处理精度损失(precision loss)问题。它会自动调整损失值的缩放比例,以避免梯度计算过程中的精度损失。
- 学习率调度:当使用DeepSpeed的学习率调度器时,在训练过程中,DeepSpeed会在每个训练步骤中自动调用调度器的 step() 方法。这确保了学习率按照指定的调度规则进行更新。
模型检查占checkpoint
DeepSpeed如何处理模型的保存和加载?有哪些注意事项需要考虑?它是如何自动保存和恢复模型状态的?用户可以保存哪些额外数据?
由于存在模型和优化器的切分,因此不能使用PyTorch原生的接口保存和加载检查点,必须使用DeepSpeed的接口
DeepSpeed处理模型的保存和加载主要通过save_checkpoint和load_checkpoint两个API来完成。以下是一步一步的解释:
#load checkpoint
_, client_sd = model_engine.load_checkpoint(args.load_dir, args.ckpt_id)
step = client_sd['step']
#advance data loader to ckpt step
dataloader_to_step(data_loader, step + 1)
for step, batch in enumerate(data_loader):
#forward() method
loss = model_engine(batch)
#runs backpropagation
model_engine.backward(loss)
#weight update
model_engine.step()
#save checkpoint
if step % args.save_interval:
client_sd['step'] = step
ckpt_id = loss.item()
model_engine.save_checkpoint(args.save_dir, ckpt_id, client_sd = client_sd)注意:需要在所有rank上加入以上代码,因为优化器状态切片后每个rank都需要加载自身对应的一部分优化器的状态
模型保存:
使用model_engine.save_checkpoint函数进行模型保存。此函数需要指定以下两个参数:
- ckpt_dir:指定模型检查点保存的目录。
- ckpt_id:作为检查点在目录中唯一标识的标识符。在示例代码中,使用了loss值作为检查点标识符。
保存额外数据:用户可以传递client_sd字典参数来保存特定于模型训练的额外数据。例如,在示例中将step值存储在client_sd中。
模型加载:
使用model_engine.load_checkpoint函数进行模型加载。此函数需要指定以下两个参数:
- load_dir:指定加载模型检查点的目录。
- ckpt_id:指定要加载的检查点标识符。
加载额外数据:load_checkpoint函数还返回两个值,通常被分配给_和client_sd。client_sd是存储在检查点中的客户端状态字典,其中包含了保存的额外数据。
- 自动保存和恢复模型状态:DeepSpeed通过save_checkpoint和load_checkpoint实现模型状态的自动保存和恢复。这些函数会隐藏模型、优化器和学习率调度器状态的细节,从而简化用户的操作。
注意事项:需要确保所有进程都调用save_checkpoint函数,而不仅仅是进程0的调用。这是因为每个进程都需要保存其主要权重以及调度器和优化器的状态。 - 额外保存的数据:用户可以通过client_sd参数保存任何与特定模型训练相关的数据。在示例中,将step值存储在client_sd字典中。这可以是任何用户认为对模型训练重要的信息。
DeepSpeed配置
使用配置JSON文件来启用、禁用或配置DeepSpeed的功能时,需要注意哪些核心参数?如何使用配置文件来定义训练批次大小、梯度累积步数、优化器类型和参数、FP16以及零优化等?
当使用配置JSON文件来启用、禁用或配置DeepSpeed功能时,需要注意一些核心参数。
在配置文件中可以配置:
- 优化器状态切分 (ZeRO stage 1)
- 梯度切分 (ZeRO stage 2)
- 参数切分 (ZeRO stage 3)
- 混合精度训练 (mixed precision training)
- ZeRO-Offload to CPU and NVMe
- 批量大小相关参数 (Batch size)
- 优化器相关参数 (Optimizer)
- 调度器 (scheduler)
- 其他
ZeRO-0 配置
{
"zero_optimization": {
"stage": 0
}
}不使用ZeRO任何功能,相当于DDP
ZeRO-1 配置
Stage 1 is Stage 2 minus gradient sharding. You can always try it to speed things a tiny bit to only shard the optimizer states with:
{
"zero_optimization": {
"stage": 1
}
}ZeRO-2 配置
以下时ZeRO2的配置示例,我们将参数描述分为两类,需要调优的和一般不需要修改的。
{
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
}
}一般不需要修改的参数:
- allgather_partitions(默认True):在每个step结束时,选择用allgather集合通信操作还是一系列的broadcast从所有GPUs收集更新后的参数,一般不需要修改,论文中在分析集合通讯开销时就用了allgather
- overlap_comm (默认False):推荐设置为True,尝试在反向传播期间并行进行梯度通信,也是一种显存换低通信开销的方法,该参数默认为False,但在一些集成了DeepSpeed的第三方库中(如PytorchLighting)默认为True,实践中也一般置为True。
- reduce_scatter (默认True):使用reduce_scatter代替allreduce来平均梯度。reduce_scatter和allreduce的区别在于reduce_scatter 近收集梯度均值的一部分,而allreduce将收集所有的梯度。由于在ZeRO2中切分了梯度,每个rank仅需收集自己所拥有的梯度切片的均值,并用于更新对应的参数,因此仅需使用reduce_scatter。
- contiguous_gradients (默认True)
需要调优的参数:
- allgather_bucket_size (默认5e8):allgather的元素数量,将张量分成较小的桶有助于在通信过程中更高效地传输数据。较大的allgather_bucket_size可能加速通信操作,但也需要更多内存来存储中间结果
- reduce_bucket_size (默认5e8):reduce和allreduce操作时的桶大小,影响与allgather_bucket_size 类似
ZeRO-3 配置
{
"zero_optimization": {
"stage": 3,
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}sub_group_size: 控制在优化器步骤中参数更新的粒度。参数被分组到大小为sub_group_size的桶中,每个桶依次进行一次更新。当与ZeRO-Infinity中的NVMe offload同时使用时,sub_group_size决定了在优化器步骤期间从NVMe迁移到CPU内存的模型状态的粒度。这有助于避免超大模型对CPU内存的过度占用。在不使用NVMe offload时,请保持其默认值。若遇到内存不足(OOM)情况,可以考虑减小sub_group_size。当优化器迭代较缓慢时,也可以考虑增大sub_group_size。(默认值:1e9)
stage3_prefetch_bucket_size: 预取参数的固定缓冲区大小。较小的值使用的内存较少,但可能会因通信而增加停顿。(默认值:5e8)
stage3_max_live_parameters: 保留在GPU上的完整参数数量的上限。(默认值:1e9)
stage3_max_reuse_distance: 根据参数在未来何时再次使用的指标来决定是舍弃还是保留参数。如果一个参数在不久的将来会再次被使用(小于stage3_max_reuse_distance),则会保留该参数以减少通信开销。在遇到内存不足(OOM)的情况下,可以降低stage3_max_live_parameters和stage3_max_reuse_distance的值。(默认值:1e9)
stage3_gather_16bit_weights_on_model_save: 在保存模型时启用模型FP16权重合并。对于大型模型和多GPU环境,这是一项在内存和速度方面代价较高的操作。(默认值:false)
注意:ZeRO-3 中不使用 allgather_partitions、allgather_bucket_size 和 reduce_scatter 配置参数
offload
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "nvme",
"pin_memory": true
}
在开启ZeRO第一阶段后,可以使用offload_optimizer,在开启ZeRO第三阶段后才可以同时使用offload_optimizer与offload_param
pin_memory: 转移到页面锁定的CPU内存。这可能会提升吞吐量,但代价是增加了额外的内存开销。(默认值:false)
ZeRO Infinity
除了stage2和3之外,这里简单介绍一下ZeRO-Infinity。
ZeRO-Infinity可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
官网对于ZeRO-Infinity的详细介绍:
DeepSpeed官方教程 :
ZeRO-Infinity has all of the savings of ZeRO-Offload, plus is able to offload more the model weights and has more effective bandwidth utilization and overlapping of computation and communication.
HuggingFace官网:
It allows for training incredibly large models by extending GPU and CPU memory with NVMe memory. Thanks to smart partitioning and tiling algorithms each GPU needs to send and receive very small amounts of data during offloading so modern NVMe proved to be fit to allow for an even larger total memory pool available to your training process. ZeRO-Infinity requires ZeRO-3 enabled.
NVMe Support
- ZeRO-Infinity 需要使用 ZeRO-3
- ZeRO-3 会比 ZeRO-2 慢很多。使用以下策略,可以使得ZeRO-3 的速度更接近ZeRO-2
- 将
stage3_param_persistence_threshold参数设置的很大,比如6 * hidden_size * hidden_size - 将
offload_params参数关闭(可以极大改善性能)
- 将
offload to NVMe
注意:offload to NVMe 只在stage 3开启后才能使用!
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/dev/shm",
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/dev/shm",
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
}nvme_path: 用于卸载优化器/参数的NVMe设备的文件系统路径。
buffer_count(offload_optimizer): 用于将优化器状态卸载到NVMe的缓冲池中的缓冲区数量。这个数量至少应该是优化器每个参数维护的状态数。例如,Adam优化器有4个状态(参数、梯度、动量和方差)。 (默认值:5)
fast_init: 启用在卸载至NVMe时的快速优化器初始化。 (默认值:false)
buffer_count(offload_param): 将参数卸载到NVMe的缓冲池中的缓冲区数量。 (默认值:5)
buffer_size: 将参数卸载到NVMe的缓冲池中的缓冲区大小。 (默认值:1e8)
max_in_cpu: 启用卸载至NVMe时在CPU内存中保留的参数元素数量。 (默认值:1e9)
混合精度训练
FP16(半精度浮点数) (fp16):可以通过设置这个参数来启用或禁用FP16混合精度训练。将其设置为true表示启用FP16,以减少模型训练时的内存占用。
由于 fp16 混合精度大大减少了内存需求,并可以实现更快的速度,因此只有在在此训练模式下表现不佳时,才考虑不使用混合精度训练。 通常,当模型未在 fp16 混合精度中进行预训练时,会出现这种情况(例如,使用 bf16 预训练的模型)。 这样的模型可能会溢出,导致loss为NaN。 如果是这种情况,使用完整的 fp32 模式。
NCCL
- 通讯会采用一种单独的数据类型
- 默认情况下,半精度训练使用 fp16 作为reduction操作的默认值
- 可以增加一个小的开销并确保reduction将使用 fp32 作为累积数据类型
{
"communication_data_type": "fp32"
}apex
- Apex 是一个在 PyTorch 深度学习框架下用于加速训练和提高性能的库。Apex 提供了混合精度训练、分布式训练和内存优化等功能,帮助用户提高训练速度、扩展训练规模以及优化 GPU 资源利用率。
- 使用
--fp16、--fp16_backend apex、--fp16_opt_level 01命令行参数时启用此模式
"amp": {
"enabled": "auto",
"opt_level": "auto"
}"fp16": {
"enabled": true,
"auto_cast": false,
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"consecutive_hysteresis": false,
"min_loss_scale": 1
}
"bf16": {
"enabled": true
}
auto_cast: 是否将输入强制转换为fp16数据类型 (默认值:false)
loss_scale: 表示FP16训练的损失缩放值。默认值0.0启用动态损失缩放,否则该值将用于静态固定损失缩放 (默认值:0.0)
initial_scale_power: 表示初始动态损失比例值的功率,实际损失规模计算为 2**initial_scale_power (默认值:16)
loss_scale_window: 代表动态损失缩放值上升/下降的窗口范围。(默认值:1000)
hysteresis: 表示动态损耗缩放中的延迟偏移 (默认值:2)
consecutive_hysteresis: 表示是否在达到不会溢出的迭代时重新填充滞后。(默认值:false)
min_loss_scale: 表示最小动态损失比例值 (默认值:1)

注意:开启fp16后可能出现如上图所示overflow情况
BF16: 配置以bfloat16浮点格式作为FP16的替代方式。bfloat16需要硬件支持(例如,NVIDIA A100)。使用bfloat16进行训练不需要损失缩放。(默认值:false)
批量大小相关参数
- 训练批次大小 (train_batch_size):在配置文件中,可以通过指定一个整数值来设置训练批次的大小。这个值代表每个训练步骤中用于训练的样本数。
- 梯度累积步数 (gradient_accumulation_steps):通过设置这个参数,可以定义梯度累积的步数。这意味着在执行优化器步骤之前,模型将进行多少次前向传播和反向传播。这对于处理大批量训练数据而内存有限的情况很有用。
"train_batch_size": "auto",
"gradient_accumulation_steps": "auto",
"train_micro_batch_size_per_gpu": "auto",
train_batch_size: 有效的训练批量大小。这指的是每次模型更新所涉及的数据样本数量。train_batch_size是单个GPU在一次前向/后向传递中处理的批量大小,也称为train_micro_batch_size_per_gpu,以及梯度累积步骤(也称为gradient_accumulation_steps),还有GPU数量,这些因素共同决定。如果同时提供train_micro_batch_size_per_gpu和gradient_accumulation_steps,可以忽略train_batch_size。(默认值:32)
gradient_accumulation_steps: 在计算平均并应用梯度之前累积梯度的训练步骤数。这个功能有时候对于提高可扩展性非常有用,因为它减少了步骤之间梯度通信的频率。另一个影响是,可以在每个GPU上使用更大的批量大小进行训练。如果同时提供train_batch_size和train_micro_batch_size_per_gpu,可以忽略gradient_accumulation_steps。(默认值:1)
train_micro_batch_size_per_gpu: 单个GPU在一个步骤中处理的微批量大小(不进行梯度累积)。如果同时提供train_batch_size和gradient_accumulation_steps,可以忽略train_micro_batch_size_per_gpu。(默认值:train_batch_size的值)
train_batch_size = train_micro_batch_size_per_gpu * gradient_accumulation * number of GPUs.(即训练批次的大小 = 每个GPU上的微批次大小 * 几个微批次 * 几个GPU)
优化器
优化器类型和参数 (optimizer):在配置文件中,可以指定优化器的类型(如"Adam")并定义相应的参数,比如学习率 (lr)。这样可以配置模型训练中所使用的优化器及其超参数。
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": [
0.9,
0.95
],
"eps": "auto",
"weight_decay": "auto"
"torch_adam": true,
"adam_w_mode": true
}
},
type: 优化器名称。DeepSpeed原生支持Adam、AdamW、OneBitAdam、Lamb和OneBitLamb优化器,并将从torch导入其他优化器。 (其他类型可查阅官方文档)
params: 参数字典,用于实例化优化器。参数名称必须与优化器构造函数的签名相匹配(例如,对于Adam优化器)。例如:{"lr": 0.001, "eps": 1e-8}。
torch_adam: 使用torch的Adam实现,而不是融合Adam实现。 (默认值:false)
adam_w_mode: 应用L2正则化(也称为AdamW)。 (默认值:true)
调度器
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": 5e-6,
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
DeepSpeed提供了 LRRangeTest、OneCycle、WarmupLR、WarmupDecayLR 学习率调度器的实现。当使用DeepSpeed的学习率调度器(在deepspeed_config.json文件中指定)时,DeepSpeed会在每个训练步骤(执行model_engine.step()时)调用调度器的step()方法。(其他类型可查阅官方文档)
warmup_min_lr: 最小学习率。 (默认值:0)
warmup_max_lr: 最大学习率。 (默认值:0.001)
warmup_num_steps: 从min_lr到max_lr的warm-up步数。 (默认值:1000)
total_num_steps: 训练总步数。
其他
"gradient_clipping": 1.0,
"zero_optimization": true
//Logging
"steps_per_print": 10,
"wall_clock_breakdown": false,
"dump_state":false
gradient_clipping: 启用梯度剪裁,剪裁阈值为指定值。(默认值:1.0)
零优化 (zero_optimization):这个参数用于启用或禁用零优化技术,即在模型训练中将零梯度忽略以减少计算。将其设置为true表示启用零优化。
steps_per_print: 每经过N个训练步骤打印进度报告。报告内容包括训练步骤数,由于混合精度训练中的溢出而跳过的优化器更新数,当前学习率以及当前动量。(默认值:10)
wall_clock_breakdown: 启用前向、反向和更新训练阶段的时序计时,以分析时间延迟。(默认值:false)
dump_state: 在初始化后打印出DeepSpeed对象的状态信息。(默认值:false)
关于auto
可以发现,配置示例中有参数被设置为auto。由于DeepSpeed目前已经被集成到了HuggingFace Transformer框架。而DeepSpeed的很多参数,和Transformer的Trainer参数设置是一模一样的。因此,官方推荐将很多常用的模型训练参数,设置为auto,在使用Trainer进行训练的时候,这些值都会自动更新为Trainer中的设置,或者帮你自动计算。
大多数情况下只需要注意DeepSpeed-specific参数(如:ZeRO,offload)。其他和Trainner重复的参数项,强烈建议设置成auto。
内存估计
如之前多次强调的,DeepSpeed使用过程中的一个难点,就在于时间和空间的权衡。
分配更多参数到CPU上,虽然能够降低显存开销,但是也会极大地提升时间开销。
DeepSpeed提供了一段简单的memory估算代码:
from transformers import AutoModel
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live## specify the model you want to train on your device
model = AutoModel.from_pretrained("t5-large")
## estimate the memory cost (both CPU and GPU)
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)
以T5-large,只使用一块GPU为例,使用DeepSpeed的开销将会如下:
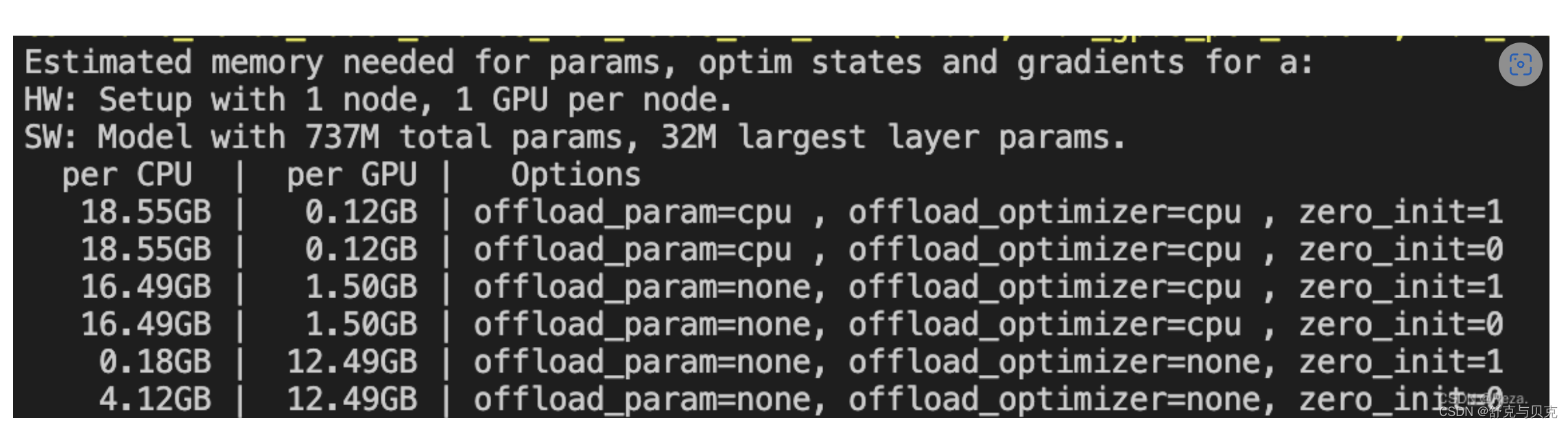
如上,如果不用stage2和stage3(最下面那两行),训练T5-large需要一张显存至少为12.49GB的显卡(考虑到很多其他的缓存变量,还有你的batch_size,实际上可能需要24GB大小的卡)。而在相继使用了stage2和3之后,显存开销被极大地降低,转而CPU内存消耗显著提升,模型训练时间开销也相应地增大。
建议:
在使用DeepSpeed之前,先使用上述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。
原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3.
具体参见官网:Memory Requirements
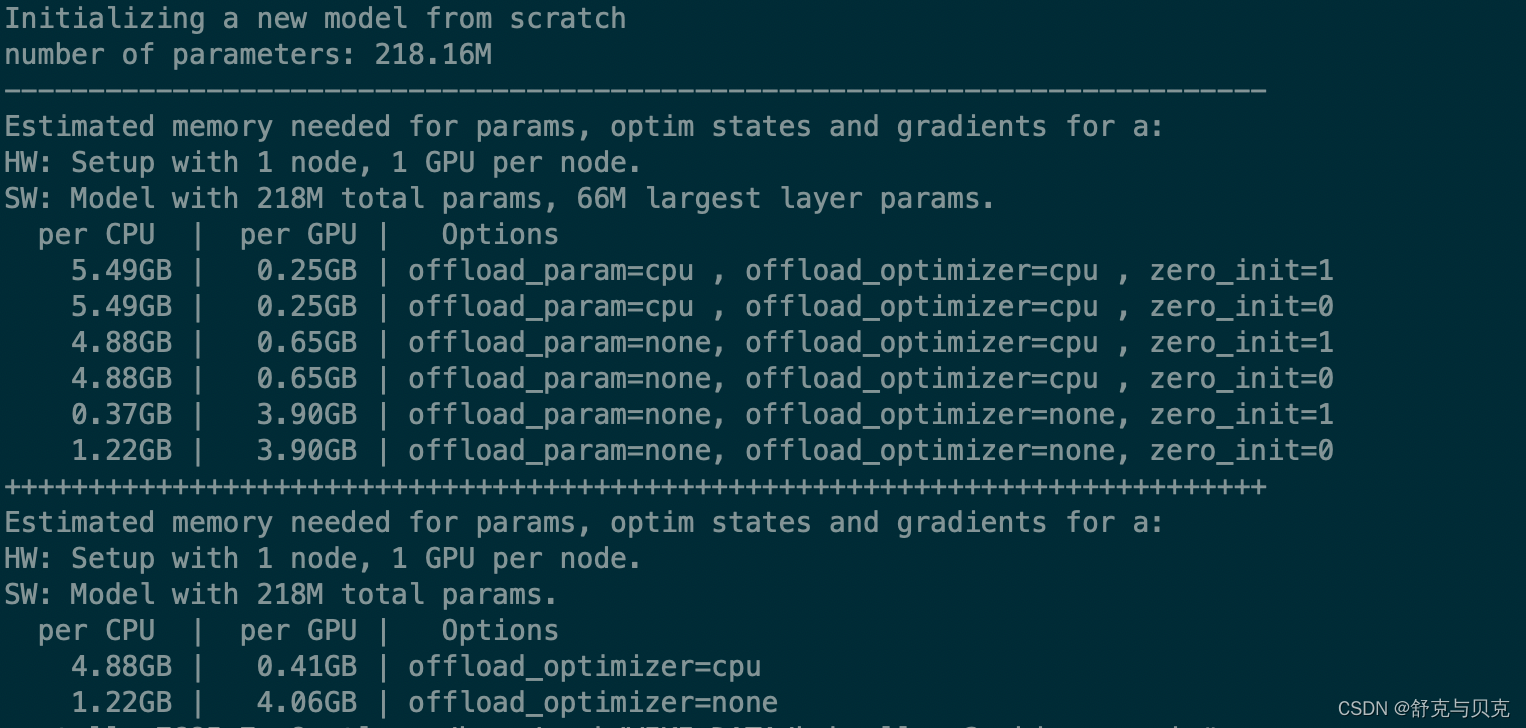
print('---' * 25)
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)
print('+++' * 25)
from deepspeed.runtime.zero.stage_1_and_2 import estimate_zero2_model_states_mem_needs_all_live
estimate_zero2_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)
对比实验
以下是进行的关于 deepspeed 主要功能的对比实验
实验基本deepspeed配置信息
(训练资源配置:A800 双机8卡)
// 实验使用 torchrun 启动器进行启动
{
"train_batch_size": "auto",
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": [
0.9,
0.95
],
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": 5e-6,
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"steps_per_print": 10,
"bf16": {
"enabled": true
},
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}实验一:关于开启ZeRO-3后关于不同offload设置对比实验结果如下
基于 Starcoder 模型代码共跑20个steps的结果(所有实验皆使用bf16)
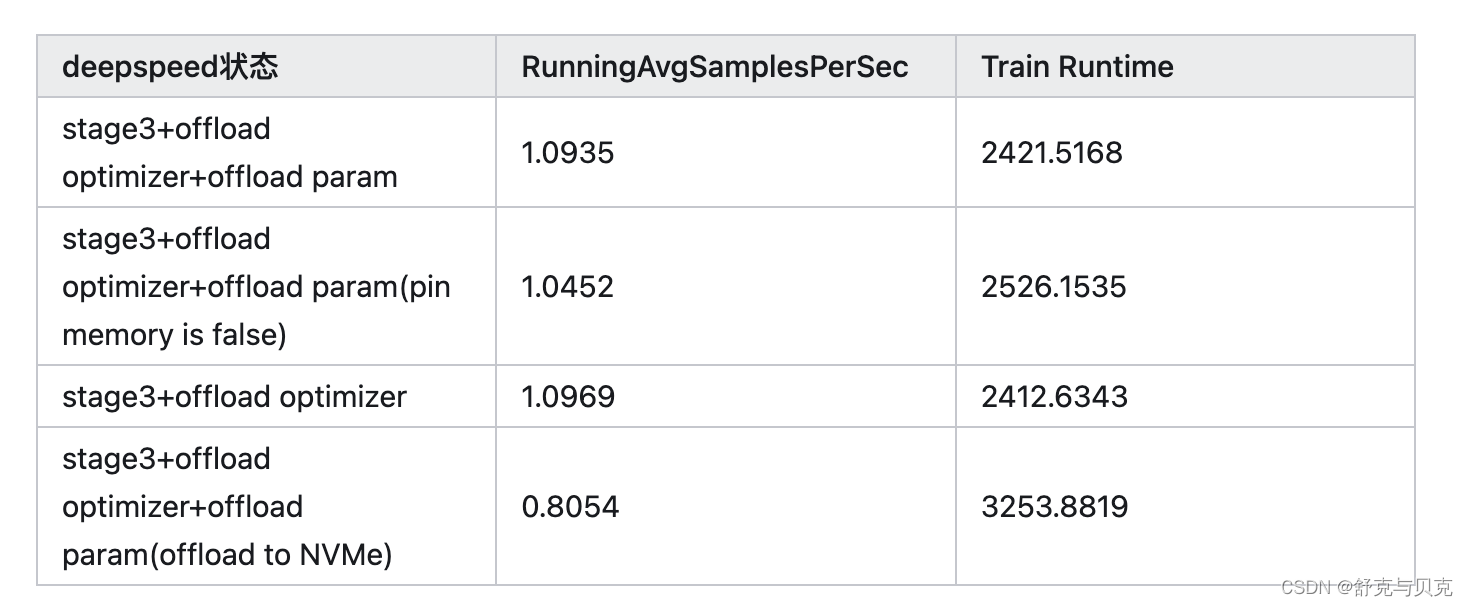
结论:使用ZeRO阶段三时,开启pin memory后吞吐率稍微加快。是否开启offload parameter对实际吞吐率影响比较小。将offload目标改为NVMe后,吞吐率下降明显。
建议:开启ZeRO阶段三后,若显存容量较小,可以将offload optimizer与offload parameter全部开启,并且开启pin memory,若显存仍然不够,可以尝试将offload的地址修改为NVMe,但需要输入NVMe的路径,但必须接受训练速度变慢的可能。
实验二:关于不同ZeRO状态的对比实验
基于 Starcoder 模型代码共跑50个steps的结果,输入大小减小至实验一的0.125倍(所有实验皆使用bf16)
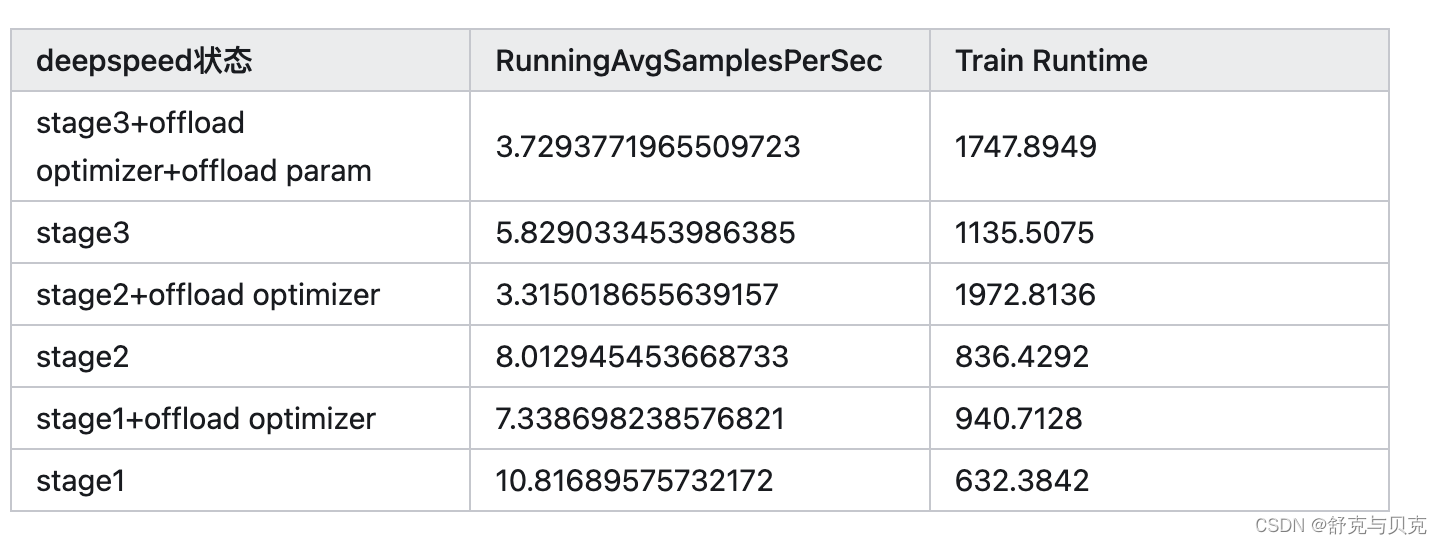
结论:在未开启offload的情况下,训练速度为
Stage 1 > stage 2 > stage 3
在开启offload(将能开启的全部开启)后,训练速度为
stage 1 > stage 3 > stage 2
建议:stage 3如果在其他配置相同的情况下,很可能比stage 2要慢,因为前者除了执行stage 2的操作外,还需要收集模型权重。但经实验结果显示,在多GPU的情况下将stage3的状态全部开启后,相对比stage2快一些。如果stage 2满足需求,而且不需要在少数几个GPU之外进行扩展,那么您可以选择继续使用它。若显存足够,可以使用stage 1.
实验三:fp16与bf16的对比实验
基于 Starcoder 模型代码共跑50个steps的结果,输入大小减小至实验一的0.125倍,实验使用stage3+offload optimizer+offload param 进行测试

结论:使用bf16训练快于fp16
建议:若硬件支持,请选择bf16进行训练
实验四:关于NCCL三个参数的对比实验
经过对比可以发现,将IB,SHM,P2P传输全都禁用后运行速度最慢,全部开启后运行速度最快。此外,发现将P2P禁用,即禁用NVlink对于训练速度影响最大;在不禁用P2P的情况下,同时禁用IB,SHM对训练时间会有影响,但影响较弱,会略微增加训练时长,单独禁用对训练无影响
建议:为了更快的训练速度,如果机器允许,请不要开启任何一个禁用。
其他补充
首先是stage 2,也就是只把optimizer放到cpu上。下面是使用前后的GPU显存占用和训练速度对比:
- GPU显存:
20513MB =>17349MiB - 训练速度 (由
tqdm估计):1.3iter/s =>0.77iter/s
可以明显看到,GPU的显存占用有了明显降低,但是训练速度也变慢了。以笔者当前的使用体感来说,deepspeed并没有带来什么收益。
笔者的机器配有24000MB的显卡,batch_size为2时,占用20513MB;而DeepSpeed仅仅帮助笔者空出了3000MB的显存,还是完全不够增加batch_size, 导致笔者总训练时长变长。
因此,DeepSpeed或许仅适用于显存极度短缺(i.e., 模型大到 batch_size == 1也跑不了)的情况;亦或是,使用DeepSpped节省下来的显存,刚好够支持更大的batch_size。否则,像笔者当前这种情况下,使用DeepSpeed只会增加时间开销,并没有其他益处。
此后,笔者还尝试使用stage 3,但是速度极其缓慢。一个原先需要6h的训练过程,用了DeepSpeed stage3之后,运行了2天2夜,也没有结束的迹象。无奈笔者只好终止测试。
此外,在使用DeepSpeed stage2时,由于分配了模型参数到多个设备上,console里面也看不到任何输出信息(但是GPU还是在呼呼响,utility也为100%),让人都不知道程序的运行进度,可以说对用户非常不友好了。
一些常见问题
由于DeepSpeed会通过占用CPU内存来减缓GPU的开销,当系统CPU不够的时候,DeepSpeed进程就会自动被系统停止,造成没有任何报错,DeepSpeed无法启动的现象。建议先用上文介绍的estimation估计一下CPU内存占用,然后用free -h查看一下机器的CPU内存空余量,来判断能否使用DeepSpeed。
另外,还有可能因为训练精度问题,出现loss为NAN的情况。详见:Troubleshooting.
- 启动时,进程被杀死,并且没有打印出traceback:CPU内存不够
- loss是NaN:训练时用的是bf16,使用时是fp16。常常发生于google在TPU上train的模型,如T5。此时需要使用fp32或者bf16。
参数调节步骤
如何选择最佳性能的ZeRO阶段和offload方式
一般而言,以下规则适用:
从速度角度来看 Stage 0 (DDP) > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads
从GPU内存使用角度来看 Stage 0 (DDP) < Stage 1 < Stage 2 < Stage 2 + offload < Stage 3 < Stage 3 + offloads
因此,当想要在适合最少数量的GPU的情况下获得最快的执行速度时,可以遵循以下过程。我们从最快的方法开始,如果遇到GPU内存不足,然后转到下一个速度较慢但使用更少GPU内存的方法,依此类推。
- 将
batch_size设置为1,通过梯度累积实现任意的有效batch_size - 如果OOM则,设置
--gradient_checkpointing 1(HF Trainer),或者model.gradient_checkpointing_enable() - 如果OOM则,尝试ZeRO stage 2
- 如果OOM则,尝试ZeRO stage 2 +
offload_optimizer - 如果OOM则,尝试ZeRO stage 3
- 如果OOM则,尝试offload_param到CPU
- 如果OOM则,尝试offload_optimizer到CPU
- 如果OOM则,尝试降低一些默认参数。比如使用generate时,减小beam search的搜索范围
- 如果OOM则,使用混合精度训练,在Ampere的GPU上使用bf16,在旧版本GPU上使用fp16
- 如果仍然OOM,则使用ZeRO-Infinity ,使用offload_param和offload_optimizer到NVME
性能优化
- 一旦使用batch_size=1时,没有导致OOM,测量此时的有效吞吐量,然后尽可能增大batch_size,因为批量大小越大,GPU的效率越高,因为它们在乘法的矩阵很大时表现最佳。
- 开始优化参数,可以关闭offload参数,或者降低ZeRO stage,然后调整batch_size,然后继续测量吞吐量,直到性能比较满意(调参可以增加66%的性能)
一些其他建议
- 如果训模型from scratch,hidden size最好可以被16整除
- batch size最好可以被2整除
启动DeepSpeed训练
为什么单卡的情况,也可以使用deepspeed?
- 使用ZeRO-offload,将部分数据offload到CPU,降低对显存的需求
- 提供了对显存的管理,减少显存中的碎片
运行方法
使用DeepSpeed之后,你的命令行看起来就会像下面这样:
deepspeed --master_port 9900 --num_gpus=2 run_s2s.py \
--deepspeed ds_config.json
--master_port:端口号。最好显示指定,默认为9900,可能会被占用(i.e., 跑了多个DeepSpeed进程)。--num_gpus: GPU数目,默认会使用当前所见的所有GPU。--deepspeed: 提供的config文件,用来指定许多DeepSpeed的重要参数。
使用DeepSpeed的一个核心要点,就在于写一个config文件(可以是.json,也可以是类json格式的配置文件),在这个配置文件中,你可以指定你想要的参数,例如,权衡时间和显存 (前文所提到的,这是一个很重要的权衡)。因此,上面几个参数里,最重要的便是--deepspeed,即你提供的config文件,即ZeRO。这也是本文接下来要重点介绍的。
# 1.单卡的使用方法
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py ...
# 单卡,并指定对应的GPU
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
# 2.多GPU的使用方法1
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json
# 多GPU的使用方法2
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
# 3.多节点多卡方法1,需要在多个节点上手动启动
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 --master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
# 多节点多卡方法2,需要创建一个 hostfile 文件,只需在一个节点上启动
hostname1 slots=8
hostname2 slots=8
# 然后运行
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
# 在SLURM上运行,略,参见原始文档
# 在jupyter中运行,略,参见原始文档在启动分布式训练时,对于资源配置(多节点)和资源配置(单节点),有哪些不同的设置步骤?如何通过DeepSpeed的启动脚本来控制使用的节点和GPU数量?
在启动分布式训练时,资源配置(多节点)和资源配置(单节点)有一些不同的设置步骤。通过DeepSpeed的启动脚本来控制使用的节点和GPU数量涉及以下步骤:
单机单卡多卡
在单节点运行时,DeepSpeed无需使用主机文件。它将根据本地机器上的GPU数量自动发现可用的插槽数量。
仅在单节点运行DeepSpeed时,需要注意以下几点不同的配置和使用情况:
- 不需要指定hostfile:
在单节点运行时,不需要使用hostfile来指定计算资源。DeepSpeed会自动检测本地机器上的GPU数量,并使用这些GPU进行训练。 - --include和--exclude参数的使用:
虽然在单节点情况下不需要hostfile,但仍可以使用--include和--exclude参数来指定使用的GPU资源。此时应将主机名指定为'localhost',例如:deepspeed --include localhost:1 ...
CUDA_VISIBLE_DEVICES与DeepSpeed的异同
异同点:
- CUDA_VISIBLE_DEVICES是环境变量,用于指定哪些GPU设备可以被程序看到和使用。它可以限制程序在单节点内使用的GPU设备。
- DeepSpeed提供了--include和--exclude参数,用于在启动时指定要使用的GPU资源,类似于CUDA_VISIBLE_DEVICES的功能,但更加灵活且可以在命令行中指定不同的节点和GPU。
相同点:
- 两者都可以用于限制DeepSpeed或其他深度学习框架在单节点上使用的GPU设备。
在单节点情况下,DeepSpeed的配置更多地集中在指定的节点内,因此不需要显式指定hostfile,而可以通过命令行参数更灵活地控制使用的GPU资源。相比之下,CUDA_VISIBLE_DEVICES是一个环境变量,需要在运行程序之前设置,控制整个进程可见的GPU设备。
deepspeed train.py --deepspeed_config xxx.json
多机多卡
准备主机文件(hostfile): 创建一个主机文件(hostfile),其中列出了可访问且支持无密码SSH访问的机器名称或SSH别名,以及每台机器上可用于训练的GPU数量。
例如:

启动多节点训练作业: 使用DeepSpeed启动脚本和相应的命令行选项,在命令行中指定hostfile,DeepSpeed将根据hostfile配置在所有可用节点和GPU上启动训练作业。
示例命令:
deepspeed --hostfile=myhostfile <client_entry.py> <client args> --deepspeed_config ds_config.json控制节点和GPU数量: 可以通过DeepSpeed启动脚本的命令行选项来控制分布式训练作业使用的节点和GPU数量。
使用 --num_nodes 和 --num_gpus 参数限制训练作业使用的节点数和GPU数。例如,--num_nodes=2 限制使用两个节点进行训练。
使用 --include 和 --exclude 参数选择性地包含或排除特定资源。例如,--exclude="worker-2:0@worker-3:0,1" 表示排除worker-2上的GPU 0和worker-3上的GPU 0和1。
在这些设置步骤中,DeepSpeed的启动脚本提供了多种命令行选项,使用户能够根据需求有效地控制分布式训练作业在多节点或单节点上使用的节点和GPU数量。
关于NCCL(NVIDIA Collective Communications Library)参数的使用说明
在多节点环境中,DeepSpeed是如何处理用户定义的环境变量传播的?与MPI相关的配置,如何结合DeepSpeed启动多节点训练作业?
环境变量传播方式:
DeepSpeed默认情况下会传播设置的NCCL和PYTHON相关环境变量。
这些变量包括NCCL_IB_DISABLE和NCCL_SOCKET_IFNAME等。
| 参数 | 意义 | 说明 |
|---|---|---|
| NCCL_IB_DISABLE | 禁用IB网卡传输端口 | IB (InfiniBand)是一种用于高性能计算的计算机网络通信标准。 |
| NCCL_SHM_DISABLE | 禁用共享内存传输 | 共享内存(SHM)传输支持运行在相同处理单元/机器中的实体之间的快速通信,这依赖于主机操作系统提供的共享内存机制 |
| NCCL_P2P_DISABLE | 禁用GPU之间信息的传输 | P2P使用CUDA和NVLink直接实现GPU之间的传输与访问 |
关于如何查看GPU是否支持 NVLINK
使用命令
nvidia-smi topo -p2p n具体操作步骤:
若用户需要传播其他环境变量,可以在名为.deepspeed_env的点文件中指定,该文件包含以新行分隔的VAR=VAL条目。这些环境变量定义可以放置在执行命令的当前路径下或用户的主目录(~/)中。若用户想要使用不同的文件名或自定义路径和文件名,可以通过环境变量DS_ENV_FILE来指定。
用户可以在自己的主目录中创建名为.deepspeed_env的文件,并在其中添加需要传播的特定环境变量定义,例如:
NCCL_IB_DISABLE=1
NCCL_SOCKET_IFNAME=eth0DeepSpeed启动器会在执行时检查当前路径和用户主目录中是否存在这个文件,然后根据其中的定义传播这些环境变量到每个节点的每个进程。
至于与MPI相关的配置,DeepSpeed提供了兼容MPI的能力,并且可以通过MPI来启动多节点训练作业。但需要注意的是,DeepSpeed仍然会使用torch分布式的NCCL后端,而不是MPI后端。
在使用MPI来启动多节点训练作业时,用户只需要安装mpi4py Python包。DeepSpeed会利用mpi4py发现MPI环境,并将必要的状态(例如,world size、rank等)传递给torch分布式后端。
在需要使用模型并行、管道并行或在调用deepspeed.initialize(...)之前需要torch分布式调用的情况下,用户可以使用以下DeepSpeed的API调用代替初始的torch.distributed.init_process_group(...):
deepspeed.init_distributed()
这样,用户就能够结合MPI和DeepSpeed,在多节点环境下启动训练作业。
模型推理
除了模型训练,有时候模型太大,连预测推理都有可能炸显存。
ZeRO 推理使用与 ZeRO-3 训练相同的配置。您只需要不需要优化器和调度器部分。实际上,如果要与训练共享相同的配置文件,则可以将它们留在配置文件中。它们将被忽略。
具体参考:ZeRO-Inference
只有ZeRO-3是有意义的,因为可以将参数分片:
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.jsonDeepspeed-Inference已经可用,使用 DeepSpeed 和 Accelerate 进行超快 BLOOM 模型推理
deepspeed-train入门教程 - 知乎 (zhihu.com)
关于Deepspeed的一些总结与心得 - 知乎 (zhihu.com)
DeepSpeed使用经验分享 - 知乎 (zhihu.com)
关于Deepspeed的一些总结与心得 - 知乎 (zhihu.com)
在Transformers中集成DeepSpeed - 知乎 (zhihu.com)
DeepSpeed使用指南(简略版) (betheme.net)
deepspeed入门教程 - 知乎 (zhihu.com)

新一代开源开发者平台 GitCode,通过集成代码托管服务、代码仓库以及可信赖的开源组件库,让开发者可以在云端进行代码托管和开发。旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 43
43 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)