

图像超分辨率重建:SRResNet算法原理详解
本文主要介绍了图像超分辨率重建中的SRResNet算法原理。SRResNet算法是图像超分辨率领域的一项重要创新,它通过引入深度结构、残差学习和子像素卷积等技术显著提升了超分辨率任务的性能,使其生成的高分辨率图像更加真实清晰。
目录
一、引言
图像的分辨率(Image Super-Resolution,SR)通常是指图像记录细节的能力,图像的分辨率越高,图像存储的细节就越多,人眼可见的清晰度就越高,与之相反,低分辨率图像通常缺乏清晰度和细节,这可能是图像采集设备的限制、传输中的压缩或其他因素导致的。为了更加便捷、低成本地改善视觉体验和更准确地分析图像内容,图像超分辨率重建技术得以应用。
图像的超分辨率重建是一种将输入的低分辨率图像经过特定算法转化为高分辨率图像的技术。通俗的说,图像超分辨率重建就像是为蒙着一层淡淡马赛克的图片褪去马赛克层,使图片更加清晰可见。具体效果如下:

图像超分辨率重建技术是当前计算机视觉和图像处理领域中的一个热门研究课题,因此有不少方法可以达到较好的重建效果,常见的方法有插值法、频域时域法、边缘先验法和学习法等。本文主要介绍的是基于深度学习的SRResNet算法。
二、SRResNet算法原理
SRResNet是一种用于图像超分辨率任务的深度学习模型。SRResNet的核心概念是通过残差连接(Residual Connection)和卷积神经网络(Convolutional Neural Networks,CNN)来实现图像超分辨率。当我们对图像进行超分辨率重建时,我们一般有两个目标:一是增强图像质量使图像的细节更加清晰,二是放大图像尺寸以增加图像的像素数量。对于前者,SRResNet使用了基于残差学习的深层网络结构来完成低分辨率到高分辨率的映射,对于后者则使用了子像素卷积来将低分辨率特征图上采样到高分辨率。本文将从以上两个方面介绍SRResNet算法原理。
1. 深度残差网络
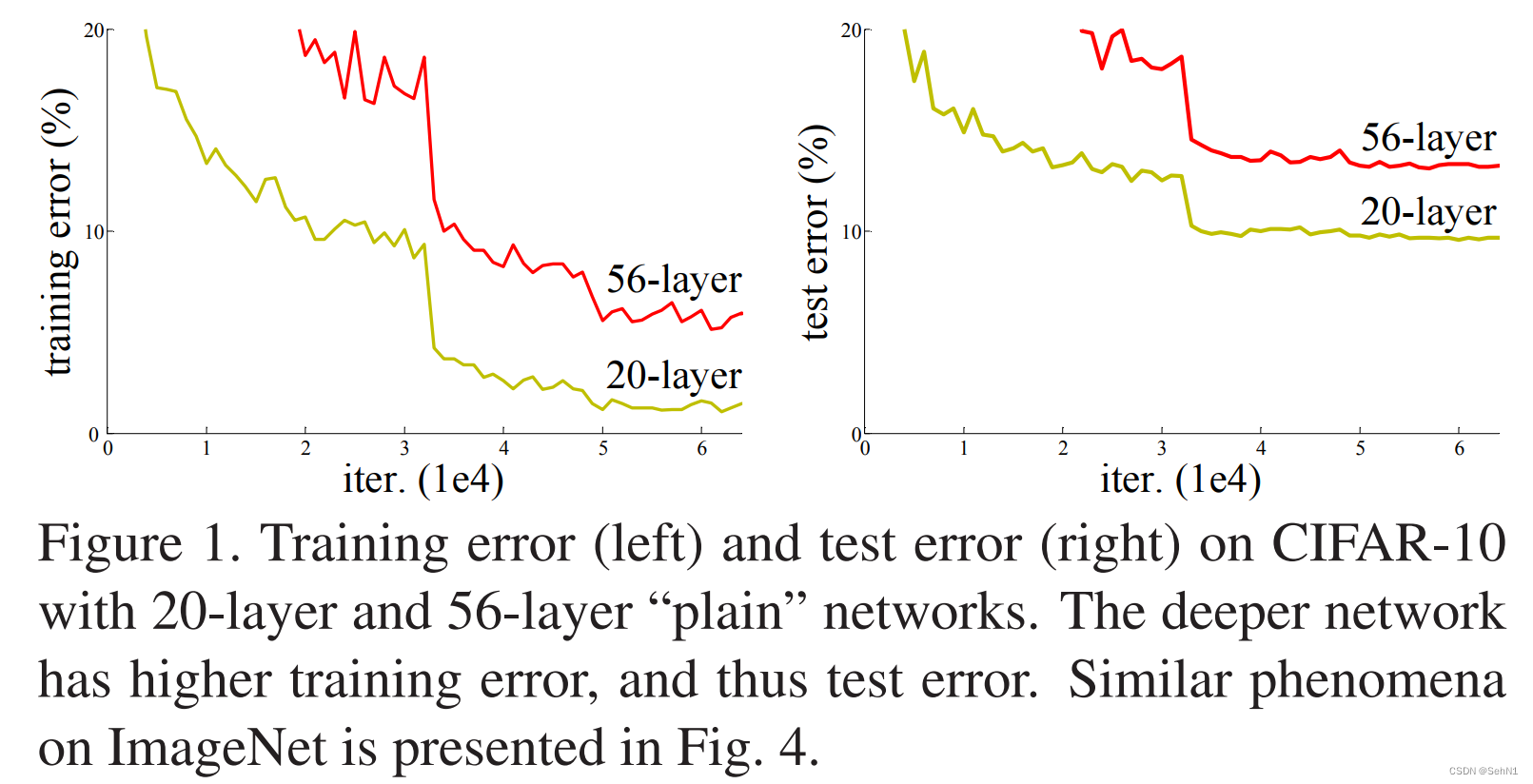
为了提高神经网络模型的准确性,我们常常会堆叠更多的层来帮助模型更好的学习特征表示,然而层数的增加也带来了不少问题,如梯度消失/爆炸、过拟合、计算资源消耗量大等。虽然梯度消失问题可以通过归一化初始化和中间归一化层得到有效的解决,但随着网络层数的增加,模型的准确率并不会一直增加。相反,当准确率达到饱和时,再增加网络层数,准确率反而会下降。如图2所示,网络层数更高的网络反而具有更高的训练损失和测试损失。 然而,残差学习不仅有效的解决了梯度消失/爆炸的问题,还大幅提升了深层神经网络的精度,使得模型准确率可以从网络层的大幅增加中可以获得提升。
如图3所示,残差学习的关键思想是引入一个捷径(shortcut)。与以往的神经网络模型每一层学习的是一个 y = f(x) 的映射不同,残差学习每一层的映射关系为y = f(x) + x,也就是将每一层的输入直接加入到该层的输出中。有了这样的shortcut,当深层网络中的某一层存在梯度消失问题时,梯度可以通过shortcut直接“跳过”该层,直接传播到更浅一层,这样就有效的缓解了梯度消失问题,也就可以实现更深层次的网络来提高模型的整体性能。如果对于某个输入x,f(x)学到了一个接近于零的映射,那么y就接近于x,此时,残差块可以近似地执行恒等映射,进行更加灵活的非线性学习,而不是被迫的学习一个复杂的映射,增加不必要的复杂性。除此之外,恒等快捷连接既不增加额外的参数,也不增加计算复杂度,可以轻松实现,不会给运算带来额外的负担。

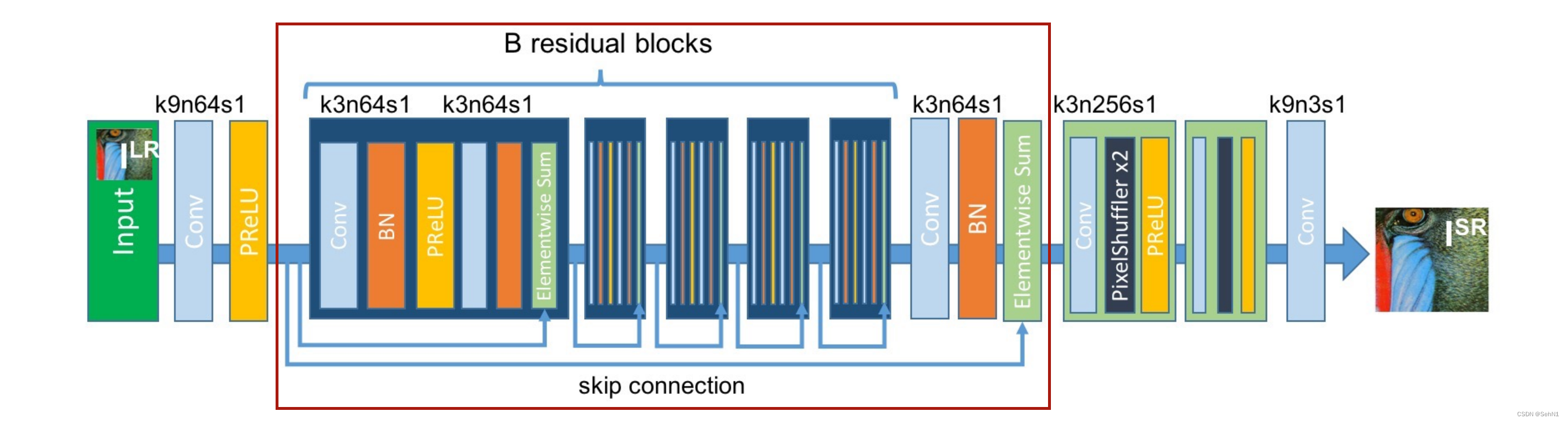
在SRResNet算法中,深度残差模块为图4红色方框内部分。可以发现,该模块由多个残差块(Residual Block)组成,每个残差块都具有一个跳跃连接(Skip Connection),也就是上文所说的shortcut。在每个残差块中,输入数据首先经过一次卷积(Convolution,Conv)和批标准化(Batch Normalization,BN),再使用PReLU函数进行激活,再次进行一次卷积和批标准化后将结果与输入进行逐元素求和(Elementwise sum),也就是实现y = f(x) + x的映射。
2. 子像素卷积
子像素卷积(Sub-pixel Convolution)又称像素清洗(Pixel Shuffle),是通过卷积操作实现上采样的一种方法,常用于图像超分辨率重建。在图像超分辨率重建中,常见的扩尺度方法有双线性插值,反卷积等等。与双线性插值相比,子像素卷积的上采样过程是可学习的,模型可以学习更加复杂的映射,具有更好的效果。反卷积虽然也是可学习的,但其参数量过大,运算时间长。仅在低分辨率空间进行卷积的子像素卷积可以在相同的速度下生成具有更多表示能力的网络。具体可以参照Is the deconvolution layer the same as a convolutional layer?
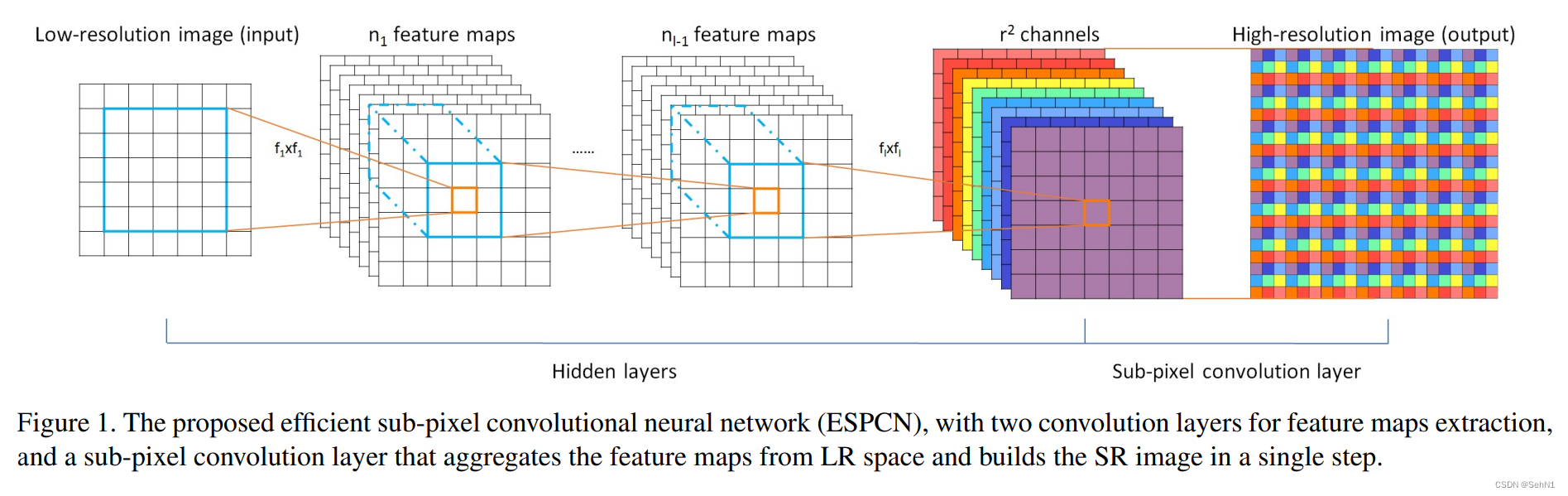
子像素卷积的原理如图5所示。左半部分Hidden layers为卷积神经网络(Convolutional Neural Networks, CNN),右半部分Sub-pixel Convolution layer则为子像素卷积。假设我们要对一个低分辨率图像放大r倍,那么就可以先通过卷积神经网络生成r^2个通道的特征图,再使用像素清洗将这r^2个通道的特征图以特定的方式进行排列,即可得到一张大图。由此可见,子像素卷积的核心步骤通常位于网络的最后一层,其名字里虽有卷积二字,却并没有进行卷积运算,而是进行简单的周期性排列(如图6所示)。

在SRResNet算法中,子像素卷积模块为图7红色方框内部分。每个框内有一次卷积(Conv),两次像素清洗(Pixel Shuffle)以及一次PReLU激活。经过子像素卷积模块后再通过一次卷积将图像还原为3通道图像,即可输出最终结果。

三、实验结果
本文仅作原理解释,参考代码来源:超分辨率——基于SRResNet的图像超分辨率重建(Pytorch实现)
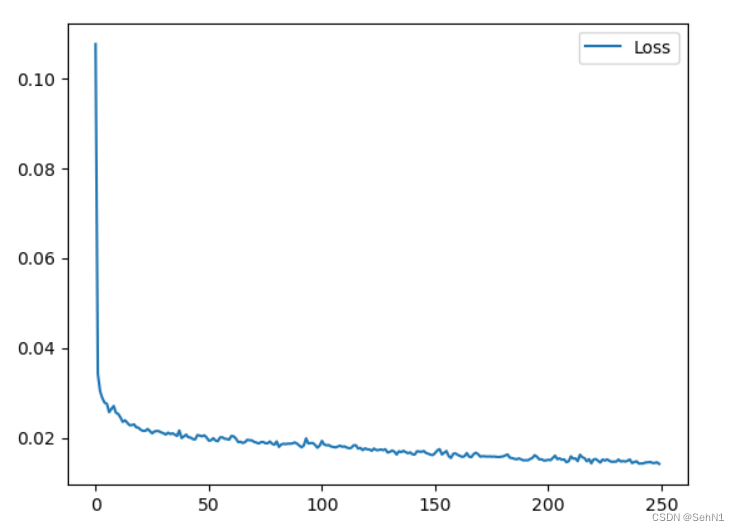
训练250epoch, 将每次迭代的loss可视化,损失变化如图8所示。可以看出大约在150次迭代时loss降到了0.02以下,说明模型训练比较有效。
以下为部分测试展示,左下角为低分辨率图。

四、总结
SRResNet算法是图像超分辨率领域的一项重要创新,它通过引入深度结构、残差学习和子像素卷积等技术显著提升了超分辨率任务的性能,使其生成的高分辨率图像更加真实清晰。一些SRResNet变体通过引入生成对抗网络(Generative Adversarial Network,GAN)能够更好地学习到图像分布,提高生成图像的自然度。总体而言,SRResNet算法在图像超分辨率领域的出色表现使其成为深度学习中的一项重要工具,为图像处理领域带来了新的可能性。
参考文献
Deep Residual Learning for Image Recognition
Is the deconvolution layer the same as a convolutional layer?

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)