
特征选择(筛选特征)
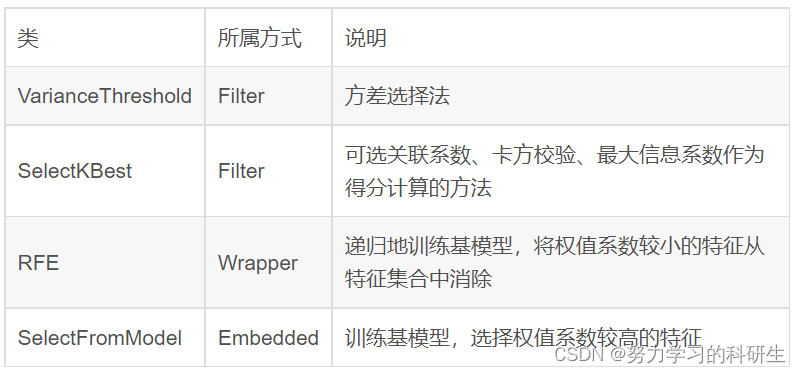
根据特征选择的形式可以将特征选择方法分为3种:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
使用sklearn中的feature_selection库来进行特征选择:
Filter
一、方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征:
(1)其特征选择原理只关心特征变量X,而不需要数据中的输出结果y,因此可以被用于无监督学习。
(2)code:
from sklearn.feature_selection import VarianceThreshold
x=data(特征数据)
y=data_1(标签)
var=VarianceThreshold(threshold=3) #参数threshold为方差的阈值。threshold:可以有很多选择【特征中位数np.median(x.var.valuse);特征/特征均值:x/x.mean ;x.var().mean()等等】
var.fit_transform(x)#返回值为选择后的数据
var.feature_names_in_ #查看模型拟合时导入的特征名称
var.get_feature_names_out() #查看被留下特征的字符名称
var.variances_ #每个特征对应的方差值
(3)缺点:
每个特征的方差不一,其重要程度无法准确估量,用一个特征方差去评估另一个,风险太大。
二、相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。使用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据
#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
#参数k为选择的特征个数
x=data (特征)
y=label(biaoqian)
SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T,k=2).fit_transform(x, y)
三、卡方检验
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
SelectKBest(chi2, k=2).fit_transform(x,y)
Wrapper
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#递归特征消除法,返回特征选择后的数据
#参数estimator为基模型
#参数n_features_to_select为选择的特征个数
x=data(特征)
y=label(标签)
RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(x,y)
Embedded
一、基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
1 from sklearn.feature_selection import SelectFromModel
2 from sklearn.linear_model import LogisticRegression
4 #带L1惩罚项的逻辑回归作为基模型的特征选择
5 SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(x,y)
L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合L2惩罚项来优化。
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
1 from sklearn.feature_selection import SelectFromModel
3 #带L1和L2惩罚项的逻辑回归作为基模型的特征选择
4 #参数threshold为权值系数之差的阈值
5 SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(x,y)
二、基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
1 from sklearn.feature_selection import SelectFromModel
2 from sklearn.ensemble import GradientBoostingClassifier
4 #GBDT作为基模型的特征选择
5 SelectFromModel(GradientBoostingClassifier()).fit_transform(x,y)

当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,要进行降低特征矩阵维度。
常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
1 from sklearn.decomposition import PCA
3 #主成分分析法,返回降维后的数据
4 #参数n_components为主成分数目
5 PCA(n_components=2).fit_transform(x)
1 from sklearn.lda import LDA
3 #线性判别分析法,返回降维后的数据
4 #参数n_components为降维后的维数
5 LDA(n_components=2).fit_transform(x,y)
不管是数据预处理,还是特征选择,抑或降维,它们都是通过某个类的方法fit_transform完成的,fit_transform要不只带一个参数:特征矩阵,要不带两个参数:特征矩阵加目标向量。
特征筛选是指从所有特征中选出最重要的特征用于模型训练,以提高模型的准确性和泛化能力。以下是一些特征筛选方法的示例代码:
- 相关系数法:
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
corr_matrix = data.corr().abs()
# 取出与目标特征相关系数大于等于0.5的特征
important_features = [col for col in corr_matrix.columns if any(corr_matrix[col] >= 0.5)]
- 方差选择法:
from sklearn.feature_selection import VarianceThreshold
data = pd.read_csv('data.csv')
# 特征方差小于0.1的特征将被删除
selector = VarianceThreshold(threshold=0.1)
selector.fit_transform(data)
important_features = [col for i, col in enumerate(data.columns) if selector.get_support()[i]]
- 卡方检验:
from sklearn.feature_selection import SelectKBest, chi2
data = pd.read_csv('data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 选择前10个最重要的特征
selector = SelectKBest(chi2, k=10)
selector.fit_transform(X, y)
important_features = X.columns[selector.get_support()]
- 基于模型的特征选择:
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 使用随机森林模型进行特征选择
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
important_features = X.columns[np.argsort(rf.feature_importances_)[::-1]][:10]
以上是一些特征筛选方法的示例代码,具体应该选择哪种方法取决于数据集的特点和实际情况。
补充:
20230316
特征筛选代码:



旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)