
DeepLab V3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.
分割图像的语义编码器-解码器和带孔可分离卷积的技术
摘要
对于语义分割任务,深度神经网络通常使用空间金字塔池化模块或编码器-解码器结构。前者通过以多种速率和多种有效视野的滤波器或池化操作来探测传入特征以编码多尺度上下文信息,而后者则通过逐渐恢复空间信息来捕捉更加清晰的物体边界。在本文中,我们提出了将两种方法的优点结合起来的方法。具体而言,我们的提出的模型DeepLabv3+扩展了DeepLabv3,通过添加一个简单而有效的解码器模块来特别改善物体边界的分割结果。我们进一步探索了Xception模型,并将深度可分离卷积应用于空洞空间金字塔池化和解码器模块,从而得到了更快速和更强大的编码器-解码器网络。我们在PASCAL VOC 2012和Cityscapes数据集上展示了所提出模型的有效性,在没有任何后处理的情况下,实现了89.0%和82.1%的测试集性能。本文还提供了在Tensorflow中公开可用的所提出模型的参考实现,链接为https://github.com/tensorflow/models/tree/master/research/deeplab。
关键词:语义图像分割,空间金字塔池化,编码器-解码器,深度可分离卷积。
介绍
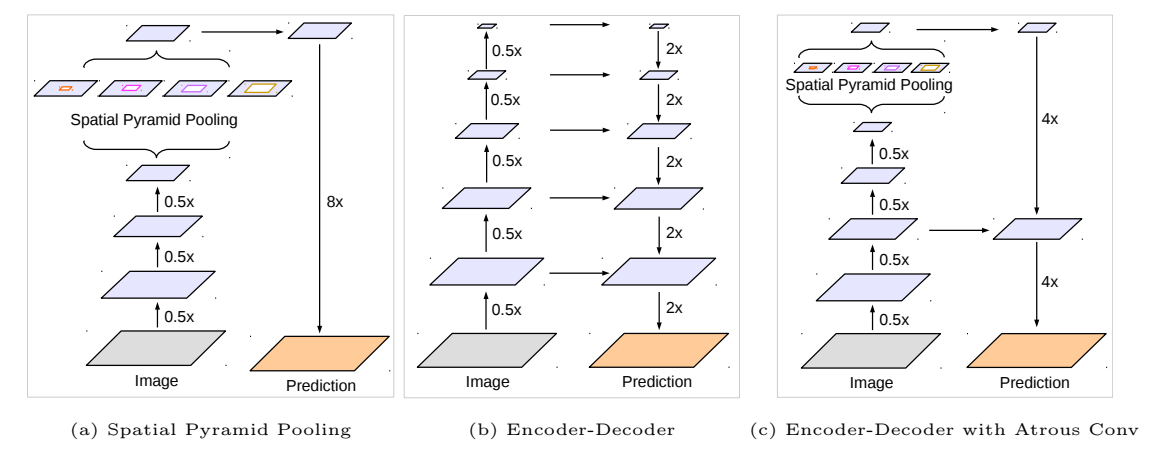
语义分割是计算机视觉中最基本的主题之一,其目的是为图像中的每个像素分配语义标签。基于全卷积神经网络的深度卷积神经网络在基准任务上比依赖于手工特征的系统[12,13,14,15,16,17]显示出惊人的改进。在本文中,我们考虑使用空间金字塔池化模块[18,19,20]或编码器-解码器结构[21,22]进行语义分割的两种类型的神经网络,其中前者通过在不同分辨率处汇聚特征来捕获丰富的上下文信息,而后者能够获得锐利的物体边界。
为了在多个尺度上捕获上下文信息,DeepLabv3[23] 应用了几个平行的具有不同速率的空洞卷积(称为空洞空间金字塔池化或ASPP),而PSPNet [24]在不同的网格尺度上执行池化操作。尽管丰富的语义信息编码在最后的特征图中,但由于池化或卷积中存在步幅操作,导致与物体边界相关的详细信息缺失。可以通过应用空洞卷积来提取更密集的特征图来缓解这个问题。然而,考虑到现有神经网络的设计[7,9,10,25,26]和有限的GPU内存,提取比输入分辨率小8倍,甚至是4倍的输出特征图是计算上禁止的。以ResNet-101 [25]为例,当应用空洞卷积来提取比输入分辨率小16倍的输出特征时,必须扩张最后3个残差块(9层)。更糟糕的是,如果需要比输入小8倍的输出特征,那么26个残差块(78层!)将会受到影响。因此,如果对这种模型提取更密集的输出特征,计算会变得非常复杂。另一方面,编码器-解码器模型[21,22]在编码器路径中不需要扩张特征,因此计算速度更快,并且在解码器路径中逐渐恢复锐利的物体边界。为了将两种方法的优点结合起来,我们建议通过将多尺度上下文信息纳入编码器模块来丰富编码器-解码器网络中的编码器模块。

我们提出了一种称为DeepLabv3+的模型,该模型通过添加一个简单但有效的解码器模块来扩展DeepLabv3,以恢复对象的边界,如图1所示。丰富的语义信息被编码在DeepLabv3的输出中,利用空洞卷积可以控制编码器特征的密度,具体取决于计算资源的预算。此外,解码器模块允许详细的对象边界恢复。受深度可分离卷积的最近成功启发,我们还探索了这个操作,并通过适应Xception模型 [26](类似于[31])进行了语义分割任务,并将空洞可分离卷积应用于ASPP和解码器模块。最后,我们在PASCAL VOC 2012和Cityscapes数据集上展示了所提出模型的有效性,并在没有任何后处理的情况下达到了89.0%和82.1%的测试集性能,创造了新的最优结果。
总之,我们的贡献包括:
- 我们提出了一种新颖的编码器-解码器结构,利用DeepLabv3作为强大的编码器模块和一个简单而有效的解码器模块。
- 在我们的结构中,通过空洞卷积可以任意控制提取的编码器特征的分辨率,从而在精度和运行时之间进行权衡,这是现有编码器-解码器模型无法实现的。
- 我们将Xception模型用于分割任务,并将深度可分离卷积应用于ASPP模块和解码器模块,从而实现更快速和更强大的编码器-解码器网络。
- 我们的提出的模型在PASCAL VOC 2012和Cityscapes数据集上取得了新的最优性能。我们还对设计选择和模型变体进行了详细分析。
- 我们在https://github.com/tensorflow/models/tree/master/research/deeplab上公开了基于TensorFlow的实现。
2 相关工作
基于全卷积网络(FCNs)的模型已在几个分割基准测试中取得了显著的改进。已提出了几种模型变体来利用上下文信息进行分割,包括使用多尺度输入(例如图像金字塔)或采用概率图模型(例如使用高效推理算法的DenseCRF)。在本研究中,我们主要讨论使用空间金字塔池化和编码器-解码器结构的模型。
空间金字塔池化:PSPNet或DeepLab等模型在多个网格尺度上执行空间金字塔池化或使用具有不同速率的多个平行空洞卷积(称为空洞空间金字塔池化或ASPP)。这些模型通过利用多尺度信息在几个分割基准测试上展现了有希望的结果。
编码器-解码器:编码器-解码器网络已成功应用于许多计算机视觉任务,包括人体姿势估计、目标检测和语义分割。通常,编码器-解码器网络包含(1)逐渐减小特征图并捕获更高语义信息的编码器模块和(2)逐渐恢复空间信息的解码器模块。在此基础上,我们建议使用DeepLabv3作为编码器模块,并添加一个简单但有效的解码器模块以获得更锐利的分割结果。
深度可分离卷积:深度可分离卷积 [27,28] 或组卷积 [7,65] 是一种强大的操作,可以在保持类似(或略微更好)性能的同时减少计算成本和参数数量。许多最近的神经网络设计 [66,67,26,29,30,31,68] 都采用了这种操作。特别地,我们探索了 Xception 模型 [26],类似于 [31] 提交给 COCO 2017 检测挑战赛的作品,并在语义分割任务中展示了在准确性和速度方面的提高。
3 Methods
本节中,我们简要介绍了空洞卷积(atrous convolution)[69,70,8,71,42]和深度可分离卷积(depthwise separable convolution)[27,28,67,26,29]。然后,我们回顾了DeepLabv3 [23],作为我们的编码器模块,然后讨论了附加到编码器输出的提出的解码器模块。我们还介绍了改进的Xception模型 [26,31],它通过更快的计算进一步提高了性能。
3.1 Encoder-Decoder with Atrous Convolution
空洞卷积(Atrous convolution)是一种强大的工具,它允许我们显式地控制深度卷积神经网络计算的特征的分辨率,并调整滤波器的视野以捕捉多尺度信息,它是标准卷积操作的一种泛化。对于二维信号,在输出特征图y的每个位置i和卷积滤波器w上,空洞卷积在输入特征图x上应用如下:

其中空洞率r确定我们对输入信号进行采样的步长。更多细节请参阅[39]。请注意,标准卷积是空洞率r = 1的特殊情况。通过改变空洞率值,滤波器的感受野可以自适应地修改。
深度可分离卷积:将标准卷积分解为深度卷积和点卷积(即1×1卷积)的深度可分离卷积可大幅减少计算复杂度。具体而言,深度卷积独立地为每个输入通道执行空间卷积,而点卷积用于组合深度卷积的输出。在深度可分离卷积的TensorFlow [72]实现中,空洞卷积已被支持在深度卷积(即空间卷积)中,如图3所示。在本文中,我们将该结果卷积称为空洞可分离卷积,并发现空洞可分离卷积显著降低了所提出模型的计算复杂度,同时保持了类似或更好的性能。

(a) Depthwise conv. (b) Pointwise conv. (c ) Atrous depthwise conv.
DeepLabv3作为编码器:DeepLabv3 [23]采用空洞卷积[69,70,8,71]在任意分辨率下提取由深度卷积神经网络计算的特征。这里,我们将输出步长定义为输入图像空间分辨率与最终输出分辨率(在全局池化或全连接层之前)之比。对于图像分类任务,最终特征图的空间分辨率通常比输入图像分辨率小32倍,因此输出步长=32。对于语义分割任务,可以采用输出步长=16(或8),通过删除最后一个(或两个)块中的步长并相应地应用空洞卷积来实现更密集的特征提取(例如,对于输出步长=8,我们分别应用速率=2和速率=4到最后两个块)。此外,DeepLabv3采用了空洞空间金字塔池化模块,通过应用不同速率的空洞卷积在多个尺度上探测卷积特征,并结合图像级特征[52]。我们使用原始DeepLabv3中logits之前的最后一个特征图作为我们提出的编码器-解码器结构中的编码器输出。请注意,编码器输出特征图包含256个通道和丰富的语义信息。此外,根据计算预算,可以通过应用空洞卷积以任意分辨率提取特征。
提出的解码器:DeepLabv3中的编码器特征通常使用输出步长=16计算。在[23]的工作中,特征通过双线性插值法上采样16倍,这可以被认为是一种朴素的解码器模块。然而,这种朴素的解码器模块可能无法成功恢复对象分割的细节。因此,我们提出了一个简单但有效的解码器模块,如图2所示。编码器特征首先通过4倍的双线性上采样,然后与具有相同空间分辨率的网络骨干(例如ResNet-101 [25]中的striding之前的Conv2)的相应低级特征[73]进行拼接。我们对低级特征应用另一个1×1卷积以减少通道数,因为相应的低级特征通常包含大量通道(例如256或512),这可能会超过丰富的编码器特征(我们的模型仅有256个通道)的重要性并使训练更加困难。拼接之后,我们应用几个3×3卷积来优化特征,,然后再进行一个简单的双线性上采样,倍数为 4。我们在第四节中表明,使用输出步幅为 16 的编码器模块可以在速度和精度之间取得最佳折衷。当使用输出步幅为 8 的编码器模块时,性能略有提高,但需要额外的计算复杂度。
3.2 Modified Aligned Xception
Xception模型[26]在ImageNet[74]的图像分类任务中表现出快速计算和良好的结果。最近,MSRA团队[31]改进了Xception模型(称为Aligned Xception)并在目标检测任务中进一步提高了性能。受这些发现的启发,我们朝着同样的方向调整Xception模型以适应语义图像分割任务。具体而言,我们在MSRA的改进基础上做了一些更改,包括(1)更深的Xception,与[31]中的相同,除了我们不修改入口流网络结构以实现快速计算和内存效率,(2)所有最大池化操作都被带步幅的可分离卷积所取代,这使我们能够应用可分离的空洞卷积提取任意分辨率的特征图(另一种选项是扩展空洞算法以适应最大池化操作),(3)在每个3×3深度卷积之后添加额外的批量归一化[75]和ReLU激活,类似于MobileNet的设计[29]。详见图4。

4 Experimental Evaluation
我们使用预训练的ImageNet-1k [74]的ResNet-101 [25]或经过修改的对齐Xception [26,31]通过空洞卷积提取密集特征图。我们的实现基于TensorFlow [72]构建,并已公开发布。
本文中提出的模型在PASCAL VOC 2012语义分割基准测试集[1]上进行评估,该数据集包含20个前景对象类别和1个背景类别。原始数据集包含1,464(训练)、1,449(验证)和1,456(测试)个像素级注释图像。我们通过[76]提供的额外注释对数据集进行扩充,最终得到10,582(trainaug)个训练图像。性能以21个类别(mIOU)的像素交集-联合平均值为度量标准。
我们遵循与[23]相同的训练协议,并将有兴趣的读者转至[23]了解详细信息。简而言之,我们采用相同的学习率调度(即“poly”策略[52]和相同的初始学习率0.007)、裁剪尺寸为513×513、在输出步幅=16时对批归一化参数进行微调,以及在训练期间进行随机尺度数据增强。注意,我们还在所提出的解码器模块中包括批归一化参数。我们的提出的模型是端到端训练的,没有对每个组件进行分段预训练。
4.1 Decoder Design Choices
我们定义“DeepLabv3特征图”为由DeepLabv3计算的最后一个特征图(即包含ASPP特征和图像级特征的特征),[k×k,f]表示具有核大小k×k和f个过滤器的卷积操作。
当使用输出步幅(output stride) = 16时,基于ResNet-101的DeepLabv3 [23]在训练和评估过程中通过双线性上采样将logits上采样16倍。这种简单的双线性上采样可以被视为一种朴素的解码器设计,其在PASCAL VOC 2012验证集上获得了77.21%的性能[23],比训练过程中不使用此朴素解码器(即在训练过程中对groundtruth进行下采样)好1.2%。为了改进这个朴素的基准线,我们提出的模型“DeepLabv3+”在编码器输出之上增加了解码器模块,如图2所示。在解码器模块中,我们考虑了三个不同的设计选择点,即(1)用于减少编码器模块中低级特征图通道的1×1卷积,(2)用于获得更锐利的分割结果的3×3卷积,以及(3)应使用哪些编码器低级特征。
为了评估解码器模块中1×1卷积的影响,我们采用[3×3, 256]和ResNet-101网络主干(Conv2特征),即res2x残差块中的最后一个特征图(具体来说,我们使用步幅之前的特征图)。如表1所示,将编码器模块中低级特征图的通道数减少到48或32会导致更好的性能。因此,我们采用[1×1, 48]进行通道缩减。
接下来我们设计解码器模块的 3×3 卷积结构并在表2中报告结果。我们发现,将 Conv2 特征图(在进行步长变化之前)与 DeepLabv3 特征图连接后,采用两个带有256个滤波器的3×3卷积比使用一个或三个卷积更有效。将滤波器数量从256减少到128或将核大小从3×3变为1×1会降低性能。我们还尝试了在解码器模块中同时利用Conv2和Conv3特征图的情况。在这种情况下,解码器特征图逐渐上采样2倍,先连接Conv3,然后连接Conv2,并分别通过[3×3,256]操作进行精炼。整个解码过程类似于U-Net/SegNet设计[21,22]。但是,我们没有观察到显著的改进。因此,最终,我们采用非常简单但有效的解码器模块:DeepLabv3特征图和通道降低后的Conv2特征图的串联通过两个[3×3,256]操作进行精炼。请注意,我们提出的DeepLabv3+模型的输出步长为4。由于受限于GPU资源,我们不会进一步追求更密集的输出特征图(即输出步长<4)。
4.2 ResNet-101 as Network Backbone
为了比较不同模型变体的精度和速度,我们在使用ResNet-101 [25]作为DeepLabv3+模型的网络骨干时,在表3中报告了mIOU和Multiply-Adds。由于采用了空洞卷积,我们能够在训练和评估过程中使用单个模型获得不同分辨率的特征。




基准模型:表3中的第一行块包含了[23]的结果,表明在评估过程中提取更密集的特征图(即eval输出步幅=8)和采用多尺度输入可以提高性能。此外,添加左右翻转的输入会使计算复杂度增加一倍,而性能提升仅微不足道。
添加解码器:第二行块中包含了使用提出的解码器结构时的结果。当使用eval输出步幅=16或8时,性能分别从77.21%提高到78.85%或从78.51%提高到79.35%,代价是额外的约20B计算开销。当使用多尺度和左右翻转的输入时,性能进一步提高。
较粗糙的特征图:我们还尝试使用train输出步幅=32(即在训练过程中根本不使用空洞卷积)以获得更快的计算速度。如表3中的第三行块所示,添加解码器可以带来约2%的改进,而只需74.20B的乘加运算。然而,性能始终比使用train输出步幅=16和不同的eval输出步幅值的情况下低1%到1.5%。因此,我们更喜欢在训练或评估中使用输出步幅=16或8,具体取决于计算复杂度预算。
4.3 Xception as Network Backbone
我们进一步采用更强大的Xception [26]作为网络的骨干。按照[31]的方法,我们进行了一些更改,如3.2节所述。
ImageNet预训练:我们在ImageNet-1k数据集上使用类似于[26]中的训练协议对提出的Xception网络进行预训练。具体来说,我们采用Nesterov动量优化器,动量为0.9,初始学习率为0.05,每2个epoch进行一次学习率衰减,速率衰减为0.94,权重衰减为4e-5。我们使用50个GPU进行异步训练,每个GPU的批处理大小为32,图像尺寸为299×299。我们并没有非常努力地调整超参数,因为我们的目标是在ImageNet上为语义分割预训练模型。我们在Tab.4中报告了在相同的训练协议下基准的Reproduced ResNet-101[25]以及验证集上的单模型误差率。我们观察到,如果在修改后的Xception中每个3x3的深度卷积之后不添加额外的批归一化和ReLU,则Top1和Top5准确性会分别下降0.75%和0.29%。
在Tab.5中报告了使用提出的Xception作为网络骨干进行语义分割的结果。
基准模型:首先在表5的第一行块中报告了不使用建议的解码器的结果,结果表明在训练输出步幅=评估输出步幅=16时,采用Xception作为网络主干相比使用ResNet-101时性能提高了约2%。在推理过程中,还可以通过使用评估输出步幅=8,多尺度输入和添加左右翻转输入来进一步改进性能。请注意,我们不采用多网格方法[77,78,23],因为我们发现它不能提高性能。
加入解码器:在表5的第一行中未使用建议的解码器的基线结果显示,当训练输出步幅=评估输出步幅=16时,使用Xception作为网络主干相比于使用ResNet-101时性能提高约2%。使用评估输出步幅=8、多尺度输入以及添加左右翻转的输入可以进一步改善性能。请注意,我们未使用多格方法[77,78,23],我们发现它不能改善性能。
使用深度可分离卷积:出于深度可分离卷积的高效计算的动机,我们进一步将其采用到ASPP和解码器模块中。如表5的第三行所示,乘法-加法计算复杂度减少了33%至41%,同时获得了类似的mIOU性能。
在COCO上预训练:为了与其他最先进的模型进行比较,我们还在MS-COCO数据集[79]上预训练了我们提出的DeepLabv3+模型,这为所有不同的推理策略带来了额外的2%改进。
在JFT上预训练:与[23]类似,我们还采用了在ImageNet-1k [74]和JFT-300M数据集[80,26,81]上预训练的建议的Xception模型,这带来额外的0.8%至1%的改进。
测试集结果:由于基准评估中没有考虑计算复杂度,因此我们选择最佳性能模型并将其训练为输出步幅=8和冻结批量归一化参数。最终,我们的“DeepLabv3+”在没有和有JFT数据集预训练的情况下均取得了87.8%和89.0%的性能。
定性结果:我们在图6中提供了最佳模型的视觉结果。如图所示,我们的模型能够非常好地分割对象而无需任何后处理。
失败模式:如图6的最后一行所示,我们的模型在分割(a)沙发与椅子,(b)重度遮挡的对象和(c)视角罕见的对象时存在困难。
4.4 Improvement along Object Boundaries

在本小节中,我们采用了 trimap 实验 [14,40,39] 来评估提议的解码器模块在物体边界附近的分割精度。具体来说,我们在 val 集上对“void”标签注释进行形态膨胀,该标签通常出现在物体边界周围。然后,我们计算那些位于扩张带(称为 trimap)内的“void”标签的像素的平均 IOU。如图 5(a)所示,对于 ResNet-101 [25] 和 Xception [26] 网络骨干,采用提议的解码器相对于朴素的双线性上采样改进了性能。当扩张带较窄时,改进更为显著。如图所示,在最小 trimap 宽度处,我们观察到 ResNet-101 和 Xception 的 mIOU 分别提高了 4.8% 和 5.4%。我们还在图 5(b)中可视化了采用提议的解码器的效果。
4.5 Experimental Results on Cityscapes


本节中,我们在Cityscapes数据集上进行了DeepLabv3+的实验,这是一个大规模的数据集,包含5000张图像(分别为训练集,验证集和测试集中的2975、500和1525张图像),以及大约20000个粗略注释的图像。
如Tab.7(a)所示,将提出的Xception模型作为DeepLabv3[23]的网络骨干(表示为X-65)应用于该数据集,包括ASPP模块和图像级特征[52],在验证集上取得了77.33%的性能。添加提出的解码器模块将性能显著提高到78.79%(提高了1.46%)。我们发现,去掉增强的图像级特征可将性能提高到79.14%,表明在DeepLab模型中,图像级特征在PASCAL VOC 2012数据集上更加有效。我们还发现,在Cityscapes数据集上,增加Xception[26]入口流中的更多层对模型有效,这与[31]在目标检测任务中所做的相同。构建在更深的网络骨干之上的模型(在表格中表示为X-71)在验证集上取得了最佳性能,达到了79.55%。


在验证集上找到最佳模型变体后,我们进一步对粗略注释的数据进行微调,以便与其他最先进的模型竞争。如表7(b)所示,我们的提出的DeepLabv3+在测试集上获得了82.1%的性能,创造了Cityscapes上的新的最先进性能。
5 Conclusion
我们提出的“DeepLabv3+”模型采用了编码器-解码器结构,其中DeepLabv3用于编码丰富的上下文信息,而采用简单而有效的解码器模块来恢复对象边界。根据可用的计算资源,还可以应用空洞卷积以在任意分辨率下提取编码器特征。我们还探索了Xception模型和空洞可分离卷积,使得该提议模型更快且更强。最终,我们的实验结果表明,该提议模型在PASCAL VOC 2012和Cityscapes数据集上设置了新的最先进表现。
致谢:我们要感谢Haozhi Qi和Jifeng Dai关于Aligned Xception的有价值的讨论,Chen Sun的反馈以及Google移动视觉团队的支持。
References
- Everingham, M., Eslami, S.M.A., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge a retrospective. IJCV (2014)
- Mottaghi, R., Chen, X., Liu, X., Cho, N.G., Lee, S.W., Fidler, S., Urtasun, R.,
Yuille, A.: The role of context for object detection and semantic segmentation in
the wild. In: CVPR. (2014) - Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R.,
Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene
understanding. In: CVPR. (2016) - Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing
through ade20k dataset. In: CVPR. (2017) - Caesar, H., Uijlings, J., Ferrari, V.: COCO-Stuff: Thing and stuff classes in context.
In: CVPR. (2018) - LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to
document recognition. In: Proc. IEEE. (1998) - Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep
convolutional neural networks. In: NIPS. (2012) - Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., LeCun, Y.: Overfeat:
Integrated recognition, localization and detection using convolutional networks. In:
ICLR. (2014) - Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale
image recognition. In: ICLR. (2015) - Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D.,
Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: CVPR. (2015) - Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic
segmentation. In: CVPR. (2015) - He, X., Zemel, R.S., Carreira-Perpindn, M.: Multiscale conditional random fields
for image labeling. In: CVPR. (2004) - Shotton, J., Winn, J., Rother, C., Criminisi, A.: Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture,
layout, and context. IJCV (2009) - Kohli, P., Torr, P.H., et al.: Robust higher order potentials for enforcing label
consistency. IJCV 82(3) (2009) 302–324 - Ladicky, L., Russell, C., Kohli, P., Torr, P.H.: Associative hierarchical crfs for
object class image segmentation. In: ICCV. (2009) - Gould, S., Fulton, R., Koller, D.: Decomposing a scene into geometric and semantically consistent regions. In: ICCV. (2009)
- Yao, J., Fidler, S., Urtasun, R.: Describing the scene as a whole: Joint object
detection, scene classification and semantic segmentation. In: CVPR. (2012) - Grauman, K., Darrell, T.: The pyramid match kernel: Discriminative classification
with sets of image features. In: ICCV. (2005) - Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: Spatial pyramid
matching for recognizing natural scene categories. In: CVPR. (2006) - He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional
networks for visual recognition. In: ECCV. (2014) - Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. (2015)
- Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional
encoder-decoder architecture for image segmentation. PAMI (2017) - Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution
for semantic image segmentation. arXiv:1706.05587 (2017) - Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In:
CVPR. (2017) - He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition.
In: CVPR. (2016) - Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In:
CVPR. (2017) - Sifre, L.: Rigid-motion scattering for image classification. PhD thesis (2014)
- Vanhoucke, V.: Learning visual representations at scale. ICLR invited talk (2014)
- Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for
mobile vision applications. arXiv:1704.04861 (2017) - Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolutional neural network for mobile devices. In: CVPR. (2018)
- Qi, H., Zhang, Z., Xiao, B., Hu, H., Cheng, B., Wei, Y., Dai, J.: Deformable
convolutional networks – coco detection and segmentation challenge 2017 entry.
ICCV COCO Challenge Workshop (2017) - Mostajabi, M., Yadollahpour, P., Shakhnarovich, G.: Feedforward semantic segmentation with zoom-out features. In: CVPR. (2015)
- Dai, J., He, K., Sun, J.: Convolutional feature masking for joint object and stuff
segmentation. In: CVPR. (2015) - Farabet, C., Couprie, C., Najman, L., LeCun, Y.: Learning hierarchical features
for scene labeling. PAMI (2013) - Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with
a common multi-scale convolutional architecture. In: ICCV. (2015) - Pinheiro, P., Collobert, R.: Recurrent convolutional neural networks for scene
labeling. In: ICML. (2014) - Lin, G., Shen, C., van den Hengel, A., Reid, I.: Efficient piecewise training of deep
structured models for semantic segmentation. In: CVPR. (2016) - Chen, L.C., Yang, Y., Wang, J., Xu, W., Yuille, A.L.: Attention to scale: Scaleaware semantic image segmentation. In: CVPR. (2016)
- Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab:
Semantic image segmentation with deep convolutional nets, atrous convolution,
and fully connected crfs. TPAMI (2017) - Kr¨ahenb¨uhl, P., Koltun, V.: Efficient inference in fully connected crfs with gaussian
edge potentials. In: NIPS. (2011) - Adams, A., Baek, J., Davis, M.A.: Fast high-dimensional filtering using the permutohedral lattice. In: Eurographics. (2010)
- Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic
image segmentation with deep convolutional nets and fully connected crfs. In:
ICLR. (2015) - Bell, S., Upchurch, P., Snavely, N., Bala, K.: Material recognition in the wild with
the materials in context database. In: CVPR. (2015) - Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V., Su, Z., Du, D., Huang,
C., Torr, P.: Conditional random fields as recurrent neural networks. In: ICCV.
(2015) - Liu, Z., Li, X., Luo, P., Loy, C.C., Tang, X.: Semantic image segmentation via
deep parsing network. In: ICCV. (2015) - Papandreou, G., Chen, L.C., Murphy, K., Yuille, A.L.: Weakly- and semisupervised learning of a dcnn for semantic image segmentation. In: ICCV. (2015)
- Schwing, A.G., Urtasun, R.: Fully connected deep structured networks.
arXiv:1503.02351 (2015) - Jampani, V., Kiefel, M., Gehler, P.V.: Learning sparse high dimensional filters:
Image filtering, dense crfs and bilateral neural networks. In: CVPR. (2016) - Vemulapalli, R., Tuzel, O., Liu, M.Y., Chellappa, R.: Gaussian conditional random
field network for semantic segmentation. In: CVPR. (2016) - Chandra, S., Kokkinos, I.: Fast, exact and multi-scale inference for semantic image
segmentation with deep Gaussian CRFs. In: ECCV. (2016) - Chandra, S., Usunier, N., Kokkinos, I.: Dense and low-rank gaussian crfs using
deep embeddings. In: ICCV. (2017) - Liu, W., Rabinovich, A., Berg, A.C.: Parsenet: Looking wider to see better.
arXiv:1506.04579 (2015) - Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose estimation. In: ECCV. (2016)
- Lin, T.Y., Doll´ar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature
pyramid networks for object detection. In: CVPR. (2017) - Shrivastava, A., Sukthankar, R., Malik, J., Gupta, A.: Beyond skip connections:
Top-down modulation for object detection. arXiv:1612.06851 (2016) - Fu, C.Y., Liu, W., Ranga, A., Tyagi, A., Berg, A.C.: Dssd: Deconvolutional single
shot detector. arXiv:1701.06659 (2017) - Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: ICCV. (2015)
- Lin, G., Milan, A., Shen, C., Reid, I.: Refinenet: Multi-path refinement networks
with identity mappings for high-resolution semantic segmentation. In: CVPR.
(2017) - Pohlen, T., Hermans, A., Mathias, M., Leibe, B.: Full-resolution residual networks
for semantic segmentation in street scenes. In: CVPR. (2017) - Peng, C., Zhang, X., Yu, G., Luo, G., Sun, J.: Large kernel matters–improve
semantic segmentation by global convolutional network. In: CVPR. (2017) - Islam, M.A., Rochan, M., Bruce, N.D., Wang, Y.: Gated feedback refinement
network for dense image labeling. In: CVPR. (2017) - Wojna, Z., Ferrari, V., Guadarrama, S., Silberman, N., Chen, L.C., Fathi, A.,
Uijlings, J.: The devil is in the decoder. In: BMVC. (2017) - Fu, J., Liu, J., Wang, Y., Lu, H.: Stacked deconvolutional network for semantic
segmentation. arXiv:1708.04943 (2017) - Zhang, Z., Zhang, X., Peng, C., Cheng, D., Sun, J.: Exfuse: Enhancing feature
fusion for semantic segmentation. In: ECCV. (2018) - Xie, S., Girshick, R., Dollr, P., Tu, Z., He, K.: Aggregated residual transformations
for deep neural networks. In: CVPR. (2017) - Jin, J., Dundar, A., Culurciello, E.: Flattened convolutional neural networks for
feedforward acceleration. arXiv:1412.5474 (2014) - Wang, M., Liu, B., Foroosh, H.: Design of efficient convolutional layers using single intra-channel convolution, topological subdivisioning and spatial ”bottleneck”
structure. arXiv:1608.04337 (2016) - Zoph, B., Vasudevan, V., Shlens, J., Le, Q.V.: Learning transferable architectures
for scalable image recognition. In: CVPR. (2018) - Holschneider, M., Kronland-Martinet, R., Morlet, J., Tchamitchian, P.: A real-time
algorithm for signal analysis with the help of the wavelet transform. In: Wavelets:
Time-Frequency Methods and Phase Space. (1989) 289–297 - Giusti, A., Ciresan, D., Masci, J., Gambardella, L., Schmidhuber, J.: Fast image
scanning with deep max-pooling convolutional neural networks. In: ICIP. (2013) - Papandreou, G., Kokkinos, I., Savalle, P.A.: Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding
window detection. In: CVPR. (2015) - Abadi, M., Agarwal, A., et al.: Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv:1603.04467 (2016)
- Hariharan, B., Arbel´aez, P., Girshick, R., Malik, J.: Hypercolumns for object
segmentation and fine-grained localization. In: CVPR. (2015) - Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z.,
Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet Large
Scale Visual Recognition Challenge. IJCV (2015) - Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by
reducing internal covariate shift. In: ICML. (2015) - Hariharan, B., Arbel´aez, P., Bourdev, L., Maji, S., Malik, J.: Semantic contours
from inverse detectors. In: ICCV. (2011) - Wang, P., Chen, P., Yuan, Y., Liu, D., Huang, Z., Hou, X., Cottrell, G.: Understanding convolution for semantic segmentation. arXiv:1702.08502 (2017)
- Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: ICCV. (2017)
- Lin, T.Y., et al.: Microsoft COCO: Common objects in context. In: ECCV. (2014)
- Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network.
In: NIPS. (2014) - Sun, C., Shrivastava, A., Singh, S., Gupta, A.: Revisiting unreasonable effectiveness
of data in deep learning era. In: ICCV. (2017) - Li, X., Liu, Z., Luo, P., Loy, C.C., Tang, X.: Not all pixels are equal: Difficultyaware semantic segmentation via deep layer cascade. In: CVPR. (2017)
- Wu, Z., Shen, C., van den Hengel, A.: Wider or deeper: Revisiting the resnet model
for visual recognition. arXiv:1611.10080 (2016) - Wang, G., Luo, P., Lin, L., Wang, X.: Learning object interactions and descriptions
for semantic image segmentation. In: CVPR. (2017) - Luo, P., Wang, G., Lin, L., Wang, X.: Deep dual learning for semantic image
segmentation. In: ICCV. (2017) - Bul`o, S.R., Porzi, L., Kontschieder, P.: In-place activated batchnorm for memoryoptimized training of dnns. In: CVPR. (2018)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)