
单链表的插入删除(数据结构与算法)
单链表的插入删除(数据结构与算法)
一、单链表特性
单链表是一种常见的线性数据结构,由一个个节点组成,每个节点包含两个部分:数据部分和指针部分。
单链表的特点是每个节点只能指向下一个节点,而最后一个节点指向一个空指针。
这个空指针常用来表示链表的结尾,一般命名为 nullptr。
下面是一个简单的单链表的示意图:
头指针 -> 节点1 -> 节点2 -> 节点3 -> … -> 最后一个节点 -> nullptr
与数组不同,单链表的节点是通过指针来连接的,
因此在插入、删除节点时不需要移动其他节点,只需要修改指针的指向即可,这是单链表的一个优势。
由于单链表每个节点只存储了指向下一个节点的指针,
所以访问节点时需要从头指针开始依次遍历访问,直到找到需要的节点,或者到达链表的结尾。
单链表适用于需要频繁插入、删除节点的场景,但不适用于随机访问节点的场景,
因为随机访问需要从头指针开始遍历整个链表。
在 C++ 中,可以使用结构体或类来定义单链表的节点,
并通过指针来连接节点。这样就可以很方便地操作单链表的插入、删除和遍历等操作。
具体来说,单链表中的每个节点包含两个重要的成员变量:
- 数据部分:用于存储节点的数据。
- 指针部分:用于指示下一个节点的位置。
二、单链表的插入操作


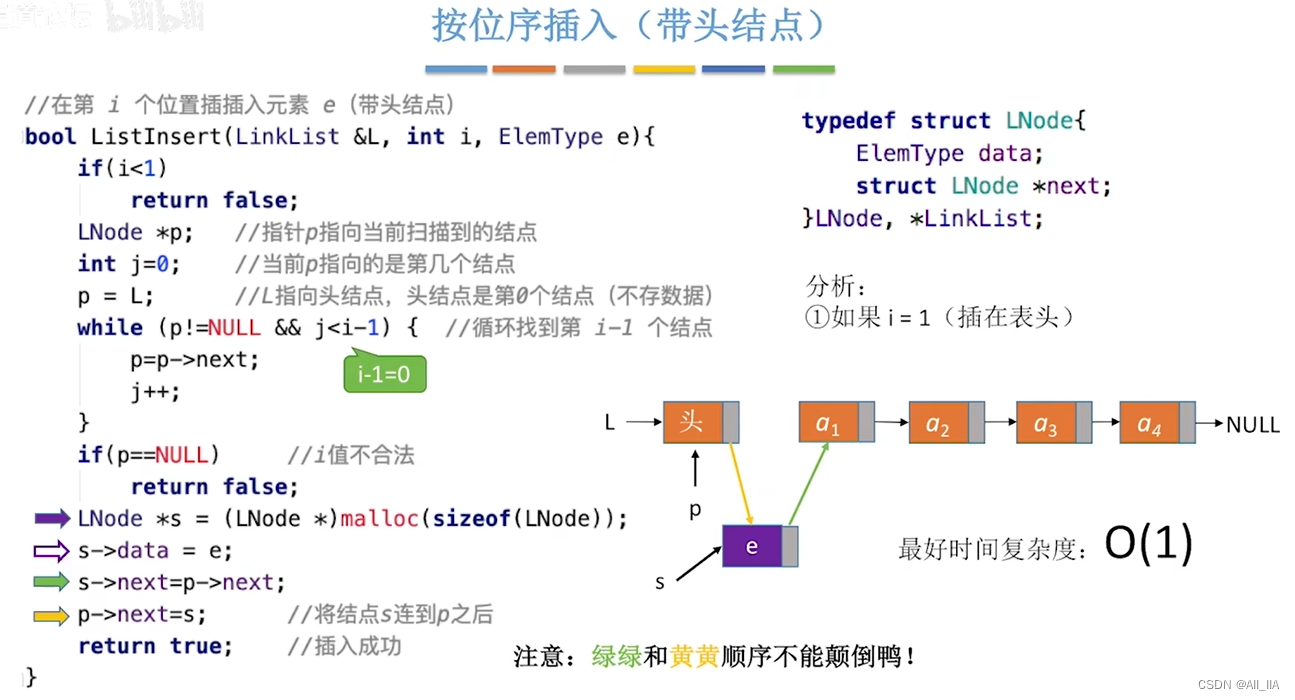
按位序插入(带头结点)



代码实现如下:
//在第i个位置插入元素e(带头结点)
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListInsert(LinkList &L, int i, ElemType e){
if(i < 1)
return false;
LNode *p; //指针p指向当前扫描到的结点
int j = 0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while (p != NULL && j < i-1){
//循环找到第i-1个结点
p = p->next; //p结点向后移动一位
j++;
}
if(p==NULL) //i值不合法
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e; //将数据元素e存入s数据域中
s->next = p->next; //令s指向p结点的后继结点。即使s结点连上p的后一个结点。
p->next = s; //将结点s连到p之后
return true; //插入成功
}


按位序插入(不带头结点)








三、单链表的删除操作
按位序删除(带头结点)
//删除第i个元素(带头结点)
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListDelete(LinkList &L, int i, ElemType &e)
{
if (i < 1)
return false;
LNode *p; //指针p指向当前扫描到的结点
int j = 0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p != NULL && j < i-1) //循环找到第 i - 1 个结点
{
p = p->next;
j++;
}
if (p == NULL)
return false;
if (p->next == NULL) //第i-1个结点之后已经无其他结点
return false;
LNode *q = p->next; //令q指向被删除结点
e = q->data; //用e返回元素的值
p->next = q->next; //将*q结点从链中“断开”
free(q); //释放结点的存储空间
return true; //删除成功
}

分析:删掉第 i 个结点, 即先循环找到第 i-1个结点。
如果 i = 4; 要删掉第4个结点a4,就要先通过while循环找到它的前驱结点,即第三个结点a3。
最终,p会指向第3个结点a3,接下来定义一个指针q, 指向p结点的next,也就是指向了第4个结点a4。
把q结点的数据元素复制到变量e中,注意变量e需要把此次删除的节点的值,通过变量e带回到ListDelete函数的调用者那,所以e是引用类型的。
p的next指向q的next,也就是指向NULL, 最后调用free()函数将q结点释放掉。具体实现如下图所示:

指定结点的删除

如果不带头结点,如何删除第一个元素,或者在前驱结点未知情况下,删除p结点?(偷天换日法,如下图所示)
- 创建一个q指针,指向p结点的后继结点。.

- p->data = p->next->data; 将q结点的数据元素赋值到p结点的数据域里面。

- 然后再让p结点的next指针指向q结点之后的位置。

- 再将q结点存储空间释放掉。从而实现删除操作,这种实现方式时间复杂度也是O(1)。

- 详细代码实现如下:
//删除指定结点p
bool DeleteNode(LNode * p)
{
if (p == NULL) //若删除的节点为空结点,操作无效
return false;
LNode *q = p->next; //定义一个q指针,令q指向*p的后继结点
p->data = p->next->data; //和后继结点交换数据域,相当于将p节点的后一个结点的数据赋值到p结点中
p->next = q->next; //将*q结点从链中“断开”
free(q); //释放后继结点的存储空间
return true;
}
由于需删除结点的前驱结点未知,或者要删除的是第一个结点,且不带头结点。那么换个思路,创建一个q指针指向p结点的后继结点,将p结点的后继结点q中的数据覆盖到p结点数据域中,然后令p结点指向q结点的后继结点: p->next = q->next;
再删掉“悬空”的q结点完成操作。等同于:1->2->3->4,若要删掉1,可以先令前两个数据交换,2->1->3->4,
再让1的指针链断开,令2指向3: 2->(1)-3->4, 把1断开,于是就是2->3->4。
如果要删除的p结点是最后一个结点,以上偷天换日法无法使用,我们只能从表头开始依次往后寻找p的前驱,时间复杂度为O(n)。

单链表只能单向地检索各个结点,无法逆向检索,有时不太方便。
如果有双向检索呢?是不是能解决这个不足,那就需要引出之后的双链表了。
四、知识点脉络回顾



旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 24
24 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)