
标准卷积、深度可分离卷积与GSConv,YOLOv8引入SlimNeck
本文介绍了标准卷积、深度可分离卷积以及paper中的GSConv,分析了它们的性能优劣,并简要介绍了如何将VoVGSP和GSConv引入YOLOv8

摘要:目标检测是计算机视觉中一项重要的下游任务。对于嵌入式边缘计算平台来说,很难实现实时检测的要求,使用巨大的模型也是困难的。此外,由大量深度可分离卷积层构建的轻量级模型无法达到足够的准确性。我们引入了一种新的轻量级卷积技术,GSConv,以减轻模型但保持准确性。GSConv在模型的准确性和速度之间实现了卓越的平衡。此外,我们提供了一种设计范式,即“slim-neck”,以实现更高的检测器计算成本效益。我们的方法在超过二十组对比实验中得到了稳健的验证。特别是,通过我们的方法改进的检测器与原始模型相比取得了最先进的结果(例如,在Tesla T4 GPU上以约100FPS的速度对SODA10M的mAP0.5为70.9%)。代码可在https://github.com/alanli1997/slim-neck-bygsconv 获取。
关键词:GSConv;目标检测;设计范式;轻量级;自动驾驶
paper:论文地址
code:代码地址
1 标准卷积
标准卷积(standard convolution)是卷积神经网络(Convolution Nerual Network)中的基本操作之一。它通过在输入数据上滑动卷积核kernel来提取特征。下面是普通卷积的基本原理:
-
卷积核: 卷积核是一个小的矩阵,它在输入数据上进行滑动。每个元素的值表示该位置上的权重。
-
滑动操作: 卷积核在输入数据上进行滑动操作。在每个位置,卷积核与输入数据的对应部分执行逐元素相乘,然后将结果相加,形成输出特征图的一个元素。
-
步长(Stride): 步长定义了卷积核在输入数据上滑动的距离。较大的步长会减小输出特征图的尺寸,而较小的步长会增加输出特征图的尺寸。
-
填充(Padding): 为了保持输入输出尺寸的一致性,可以在输入数据的边缘添加零值,这称为填充。填充可以防止卷积操作导致输出特征图尺寸减小太快。
卷积层的参数量和计算量可以用以下公式计算:
| Cin:输入的通道数 | Cout:输出的通道数 | Kh:卷积核的高度 |
| Kw:卷积核的宽度 | Param conv2d:卷积层的参数量 | M out-h,M out-w:输出特征图的高度和宽度 |
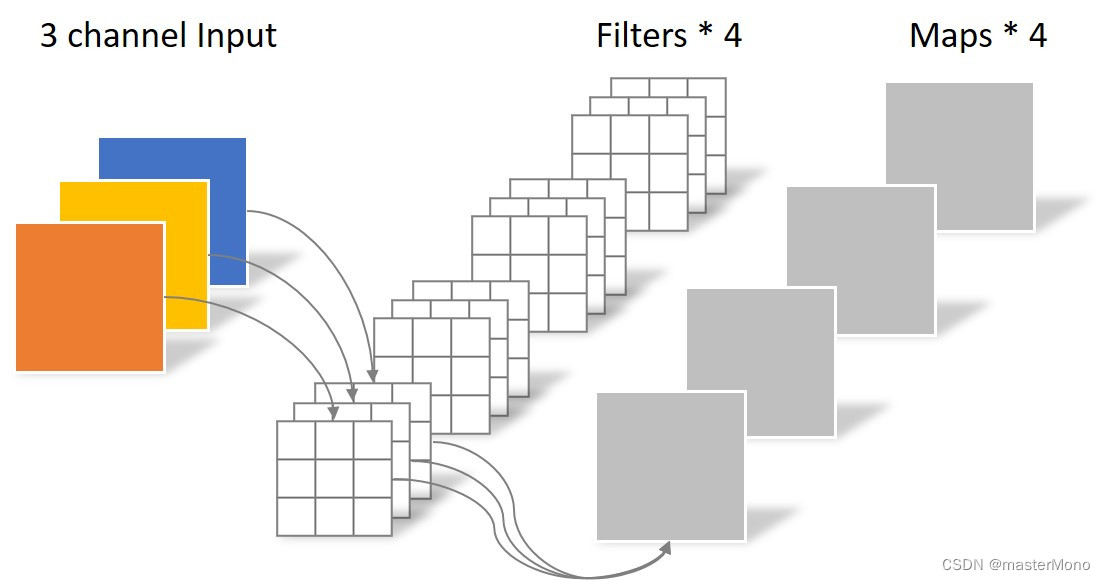
在上图中,输入通道为3,卷积核的高度和宽度均为3,输出的通道数为4,因此标准卷积的参数量为 3*4*3*3 = 108
由于卷积核的高度和宽度均为3,所以输出的特征图的高度和宽度也均为3。
可得计算量 = 108*3*3 = 972

动画来源:GitHub - animatedai/animatedai.github.io
2 深度可分离卷积
2.1 深度卷积(Depthwise Convolution)
在深度卷积步骤中,每个输入通道都被单独地与一个卷积核进行卷积操作。这意味着对于具有C个输入通道的输入特征图,会有C个单通道的卷积核,每个卷积核与输入的一个通道进行卷积。
深度卷积负责捕捉输入的通道之间的空间相关性。

与标准卷积的不同之处在于此次的卷积完全是在二维平面内进行,且Filter的数量与上一层的Depth相同。所以一个三通道的图像经过运算后生成了3个Feature map。
深度卷积的参数量计算为 3*3*3 =27
计算量为 27 *3*3 =243
2.2 逐点卷积(Pointwise Convolution)
在逐点卷积中,使用1x1的卷积核,对深度卷积的输出进行卷积。这个步骤的目的是将深度卷积的输出映射到新的特征空间,通常通过调整通道的数量来实现。
逐点卷积的作用是引入跨通道的关联性,将不同通道的信息整合在一起。

逐点卷积的参数量为3*4*1*1 = 12
计算量为12*3*3 = 108
对比:
| SC | DSC | |
| Param | 108 | 39 |
| FLOP | 972 | 351 |
由图表可知,同样是得到了4张feature map ,深度可分离卷积的参数量与计算量大约为标准卷积的,所以深度可分离卷积的优势在于它相对于传统的卷积操作有较少的参数量和计算量,在一定程度上减少了模型的复杂性。但是深度可分离卷积相较于标准卷积精度较低。

3 GSConv
对于自动驾驶汽车来说,速度和准确性同样重要。先前的轻量级工作,如Xception 、MobileNets 和ShuffleNets,通过DSC(深度可分离卷积)操作极大地提高了检测器的速度。但是,当这些模型应用于自动驾驶车辆时,这些模型的较低准确性令人担忧。实际上,这些工作提出了一些缓解DSC固有缺陷(也是其特殊性)的方法:MobileNets使用大量的1*1密集卷积来融合独立计算的通道信息;ShuffleNets使用“通道混洗”来实现通道信息的交互;GhostNet 使用“半分”SC(普通卷积)操作保留通道之间的交互信息。然而,1*1密集卷积占用更多计算资源,使用“通道混洗”的效果仍然无法接触SC的结果,而GhostNet或多或少又回到了SC的路上,受影响的因素可能来自多个方面。许多轻量级模型使用类似的思路设计基本架构:从深度神经网络的一开始到结束只使用DSC。但是,DSC的缺陷在骨干网络中直接放大,无论是用于图像分类还是检测。我们认为SC和DSC可以合作。我们注意到,仅通过混洗DSC的输出通道生成的特征图仍然是“深度分离的”。为了使DSC的输出尽可能接近SC,我们引入了一种新方法 - 使用SC、DSC和混洗的混合卷积,称为GSConv。
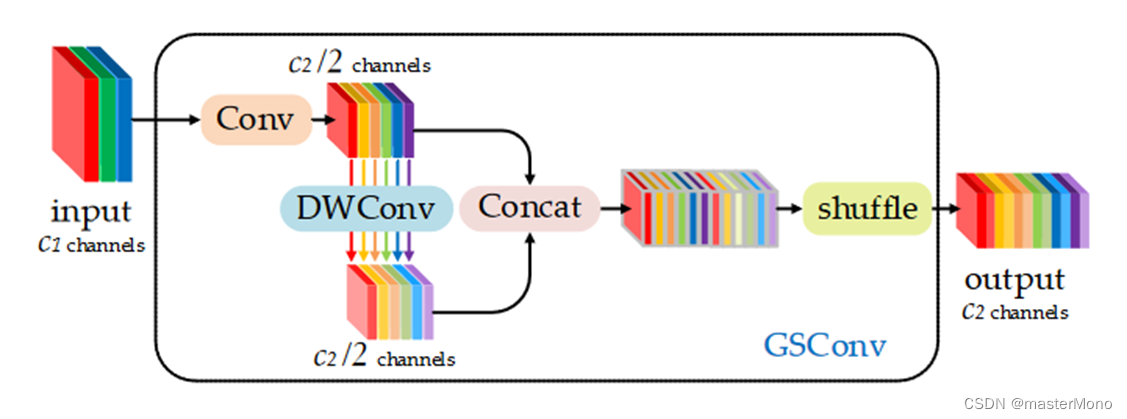
如图2所示,我们使用混洗(shuffle)将由SC(通道密集卷积操作)生成的信息渗透到DSC(深度可分离卷积)生成的所有信息的各个部分中。混洗是一种均匀混合策略。这种方法允许SC的信息通过均匀地交换不同通道上的局部特征信息,完全混合到DSC的输出中,没有繁琐的步骤。图3展示了SC、DSC和GSConv的可视化结果。GSConv的特征图与SC的相似性明显高于DSC与SC的相似性。在轻量级模型上,我们通过仅使用GSConv层替换SC层获得了显著的准确性提升;在其他模型上,当我们在骨干网络中使用SC并在颈部(slim-neck)使用GSConv时,模型的准确性非常接近原始模型;如果我们加入一些技巧,模型的准确性和速度将超过原始模型。slim-neck与GSConv方法最小化了DSC缺陷对模型的负面影响,并有效利用了DSC的优势。

为了加速CNN中最终预测的计算过程,馈送到CNN的图像几乎总是需要在骨干网络中经历类似的转换过程:空间信息逐步向通道传递。每次对特征图进行空间(宽度和高度)压缩和通道扩展都会导致语义信息的部分丢失。通道密集卷积计算最大程度地保留了每个通道之间的隐藏连接,但通道稀疏卷积则完全切断了这些连接。GSConv以更低的时间复杂度尽可能地保留这些连接。通常,卷积计算的时间复杂度由FLOPs(浮点运算数)定义。因此,SC(通道密集卷积)、DSC(通道稀疏卷积)和GSConv的时间复杂度(不考虑偏置)分别为:

其中,W是输出特征图的宽度;H是输出特征图的高度;K1·K2是卷积核的大小;C1是每个卷积核的通道数,也是输入特征图的通道数;C2是输出特征图的通道数。在表3中,我们比较了五种不同卷积块(SC、DSC、ShuffleNet方法、GhostNet方法和GSConv方法)对模型性能的贡献。

GSConv结构图如下所示。
class GSConv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
super().__init__()
c_ = c2 // 2
self.cv1 = Conv(c1, c_, k, s, None, g, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
def forward(self, x):
x1 = self.cv1(x)
x2 = torch.cat((x1, self.cv2(x1)), 1)
b, n, h, w = x2.data.size()
b_n = b * n // 2
y = x2.reshape(b_n, 2, h * w)
y = y.permute(1, 0, 2)
y = y.reshape(2, -1, n // 2, h, w)
return torch.cat((y[0], y[1]), 1)
代码解释:
init函数:
- 函数参数:接收参数
c1、c2、k、s、g和act。这些参数分别表示输入通道数,输出通道数,卷积核大小,步长,分组数(用于分组卷积),以及是否使用激活函数。 - 函数第二行:计算
c_,它是输出通道数c2的一半。 - 函数第三四行:创建两个卷积层
cv1和cv2,分别是 Conv 类的实例。cv1用于执行卷积操作,而cv2似乎使用了一个较大的卷积核,其输出通道数为c_。
forward函数:
- 函数第一行:对输入
x执行cv1操作,得到x1。 - 函数第二行:使用
torch.cat将x1和cv2(x1)沿着通道维度拼接在一起,形成新的特征图x2。 - 第二行之后:对
x2进行 shuffle 操作。具体来说,它将数据张量进行了一些形状变换操作,最终返回一个沿着通道维度进行了重新排序的输出张量。这里使用了分组卷积的思想,将通道分成两组,并在这两组之间进行 shuffle 操作。
总之,在上述结构图及代码中,首先对输入进行标准卷积,然后再进行深度卷积,把两次卷积的结果进行concatenation(拼接)操作,最后进行shuffle(混洗)操作。
4 YOLOv8轻量化:引入SlimNeck
1 获取SlimNeck源码
2 task.py中引入GSConv和VoVGSP
3 创建myyolov8-slimneck.yaml
在改进中,YOLOv8的neck部分中的c2f和Conv分别被替换为了VoVGSP和GSConv。
改进方法不唯一,可尝试于backbone部分引入VoVGSP和GSConv。
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, VoVGSCSP, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, VoVGSCSP, [256]] # 15 (P3/8-small)
- [-1, 1, GSConv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, VoVGSCSP, [512]] # 18 (P4/16-medium)
- [-1, 1, GSConv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, VoVGSCSP, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
#head:
# - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
# - [[-1, 6], 1, Concat, [1]] # cat backbone P4
# - [-1, 3, C2f, [512]] # 12
#
# - [-1, 1, nn.Upsample, [None, 2, 'nearest']]
# - [[-1, 4], 1, Concat, [1]] # cat backbone P3
# - [-1, 3, C2f, [256]] # 15 (P3/8-small)
# - [-1, 1, Conv, [256, 3, 2]]
# - [[-1, 12], 1, Concat, [1]] # cat head P4
# - [-1, 3, C2f, [512]] # 18 (P4/16-medium)
#
# - [-1, 1, Conv, [512, 3, 2]]
# - [[-1, 9], 1, Concat, [1]] # cat head P5
# - [-1, 3, C2f, [1024]] # 21 (P5/32-large)
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)