地理探测器(GeoDetector)原理及其实现
一、地理探测器原理与功能
1.1 用途与目的
地理学第二定律的核心思想是地理现象的空间(分层)异质性,其普遍存在于各种地理现象中。
空间分层异质性(spatial stratified heterogeneity),层内方差小于层间方差的地理现象。即同一地理现象在同一子区域内表现出相似性,但在不同子区域间的分布呈现差异性,例如土地类型、气候分区等。此处,层(strat)是统计学上的概念,对应地理学可理解为子区域。
地理探测器是探测空间分异性以及揭示其背后驱动力的空间分析方法,被广泛用于进行驱动力分析和因子分析。其核心思想是基于这样的假设:如果某个自变量对某个因变量有重要影响,那么自变量和因变量的空间分布应该具有相似性。地理分异可以利用地理探测器进行统计分析,其有两大优势:一是地理探测器既可以探测数值型数据,也可以探测定性数据;二是可以探测两因子交互作用于因变量。地理探测器通过分别计算和比较各单因子q值及两因子叠加后的q值,可以判断两因子是否存在交互作用,以及交互用用的强弱、方向、线性还是非线性等。两因子叠加既包括相乘关系,也包括其他关系,只要有关系,就能检验出来。
ref : 王劲峰,徐成东.地理探测器:原理与展望[J].地理学报,2017,72(01):116-134.
1.2 功能原理
地理探测器用于分析空间分层异质性,主要包括4个探测器(因子探测器、交互作用探测器、风险区探测器、生态探测器),分析结果可分别回答以下问题:
(1)是否存在空间异质性?什么因素造成了这种分层异质性?
(2)变量Y是否存在显著的区际差别?
(3)因素X之间的相对重要性如何?
(4)因素X对于因素Y是独立起作用还是具有广义的交互作用?
- 分异及因子探测
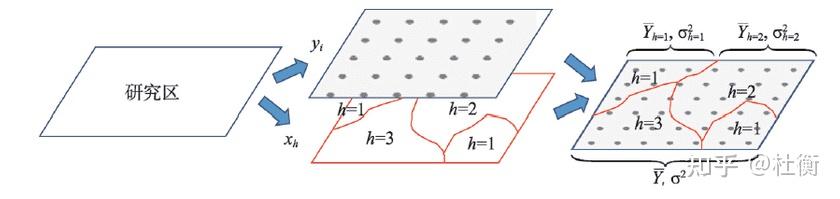
因子探测旨在探测Y的空间分异性以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量(Wang et al.,2010b),表达式为:
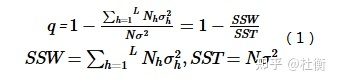
式中:h = 1, …, L为变量Y或因子X的分层,即分类或分区;Nh和N分别为层h和全区的单元数;σ2h和 σ2分别是层h和全区的Y值的方差。SSW和SST分别为层内方差之和(Within Sum of Squares)和全区总方差(Total Sum of Squares)。
q的值域为[0, 1],值越大说明Y的空间分异性越明显;如果分层是由自变量X生成的,则q值越大表示自变量X对属性Y的解释力越强,反之则越弱。极端情况下,q值为1表明因子X完全控制了Y的空间分布,q值为0则表明因子X与Y没有任何关系,q值表示X解释了100xq%的Y。
q值的一个简单变换满足非中心F分布:
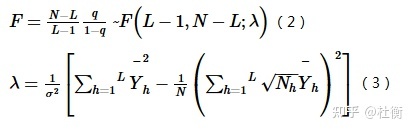
式中:λ为非中心参数;Yh为层h的均值。
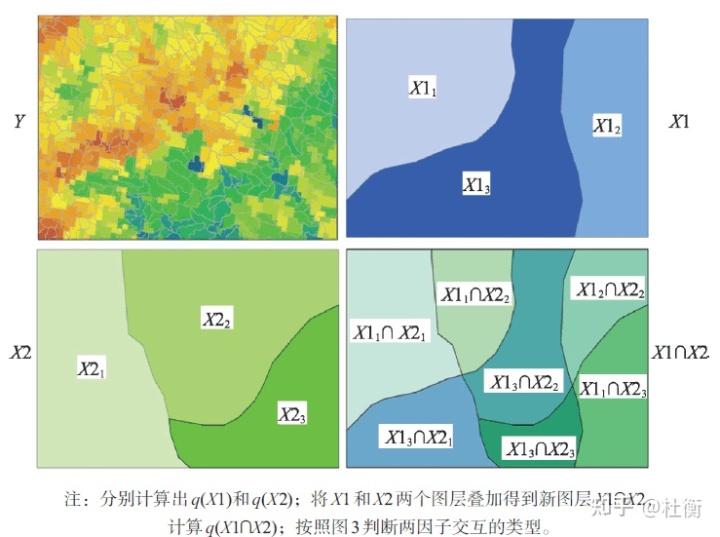
- 交互作用探测
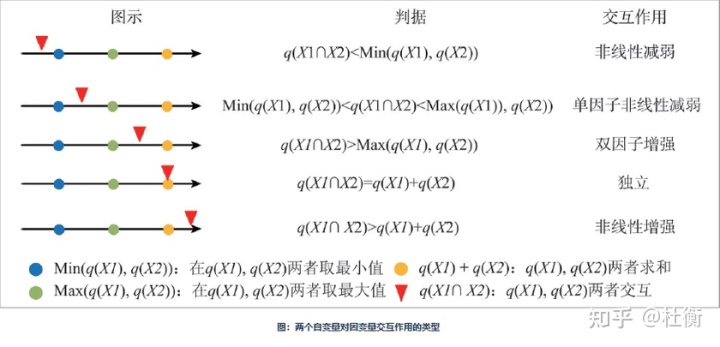
用于识别不同风险因子Xs之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量Y的解释力,或这些因子对Y的影响是相互独立的。评估的方法是首先分别计算两种因子X1和X2对Y的q值:q(X1)和q(X2),并且计算它们交互(叠加变量X1和X2两个图层相切所形成的新的多边形分布)时的q值: q(X1∩X2),比较 q(X1)、 q(X2)与 q(X1∩X2)的大小。两个因子之间的关系可分为以下几类:
- 风险区探测
用于判断两个子区域间的属性均值是否有显著的差别,用t统计量来检验:
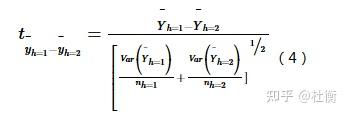
式中: Yh表示子区域h内的属性均值,如发病率或流行率;nh为子区域h内样本数量,Var表示方差。统计量t近似地服从Student’s t分布,其中自由度的计算方法为:
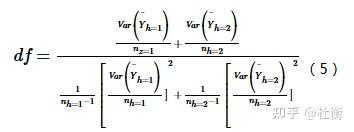
零假设H0: Yh=1=Yh=2,如果在置信水平α下拒绝H0,则认为两个子区域间的属性均值存在着明显的差异。
- 生态探测
用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,以F统计量来衡量。
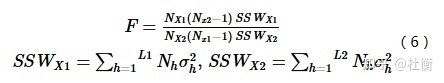
式中:NX1及NX2分别表示两个因子X1和X2的样本量;SSWX1和SSWX2分别表示由X1和X2形成的分层的层内方差之和;L1和L2分别表示变量X1和X2分层数目。其中零假设H0:SSWX1=SSWX2。如果在α的显著性水平上拒绝H0,这表明两因子X1和X2对属性Y的空间分布的影响存在着显著的差异。
1.3 功能入口
工具箱 >> 空间统计分析 >> 分析模式 >> 地理探测器。
1.4 主要参数
- 源数据 :设置待分析的数据集,支持点、线、面及属性表四类数据集。
- 因变量字段(Y):是被测定或被记录的变量,会随另一个(或另几个)变量的变动而发生变动,为数值量,如各村庄神经管畸形出生缺陷(NTDs)发生率。
- 自变量字段(X):是引起因变量发生变化的因素或条件,是对因变量的解释变量,支持设置多个解释变量,如土壤类型、高程、水文流域等。注意这里的自变量应为类型量,如果为数值量,则需对其进行分组或分层,使组内方差最小,组间方差最大。分组可以基于专家知识,也可以使用k-means,或者排序后等分。应保证各组或层分类变量中至少有因变量的两个样本单元,从而可以计算该层的均值或方差。
- 结果数据 :指定的保存分析结果的数据源。四种探测器分析结果将分别生成新的属性表数据集存放至该数据源中。
1.5 结果说明
所有探测器结果将生成新的属性表数据集存储至数据源中,同时在右侧地理探测器面板中输出分析结果,下面将对各探测器结果进行分析:
- 因子探测器 :探测变量Y的空间分层异质性,以及探测某因子X多大程度上解释了变量Y的空间分异,用q值度量。如果分层是由自变量X生成的,则q值越大表示X和Y的空间分布越一致,自变量X对属性Y的解释力越强,反之则越弱。FactorDetector_result 属性表数据集为因子探测结果。
- 交互探测器 :用于识别不同解释变量之间的交互作用,评估两因子共同作用时是否会增加或减弱对因变量的解释力,或这些因子对其影响是否相互独立的。InteractionDetector_result 属性表数据集为交互探测结果,解释变量对因变量交互作用的类型包括:
- Weaken,nonlinear:非线性减弱;
- Weaken,uni-:单因子非线性减弱;
- Enhance, bi-:双因子增强;
- Independent:独立;
- Enhance,nonlinear:非线性增强。
- 风险探测器 :用于判断不同区域的属性均值是否具有显著性。RiskDetector_result 属性表数据集为风险区探测结果。
- 生态探测器 :用于比较不同影响因子对属性值的空间分布的影响是否有显著的差异。EcologicalDetector_result 属性表数据集为生态探测结果。
1.6 适用条件
- 擅长自变量X为类型量 (如土地利用图),因变量Y为数值量(碳排放)的分析;
- 当因变量Y和自变量X均为数值量,对X离散化转换为类型量后,运用地理探测器建立的 Y 和X 之间的关系将比经典回归更加可靠,尤其当样本量<30 时。
- 对变量无线性假设,属于方差分析 (ANOVA)范畴,物理含义明确的,其大小反映了X (分层或分类) 对Y解释的百分比100×q%。
- 地理探测器探测两变量真正的交互作用,而不限于计量经济学预先指定的乘性交互。
- 地理探测器原理保证了其对多自变量共线性免疫。
- 在分层中,要求每层至少有2个样本单元。样本越多,估计方差越小。
1.7 应用领域
包括:土地利用、公共健康、区域经济、区域规划、旅游、考古、地质、气象、植物、生态、环境、污染、遥感和计算机网络等,地理探测器作为驱动力和因子分析的有力工具已经在以上案例中得到充分验证。
1.8 数据要求与预处理
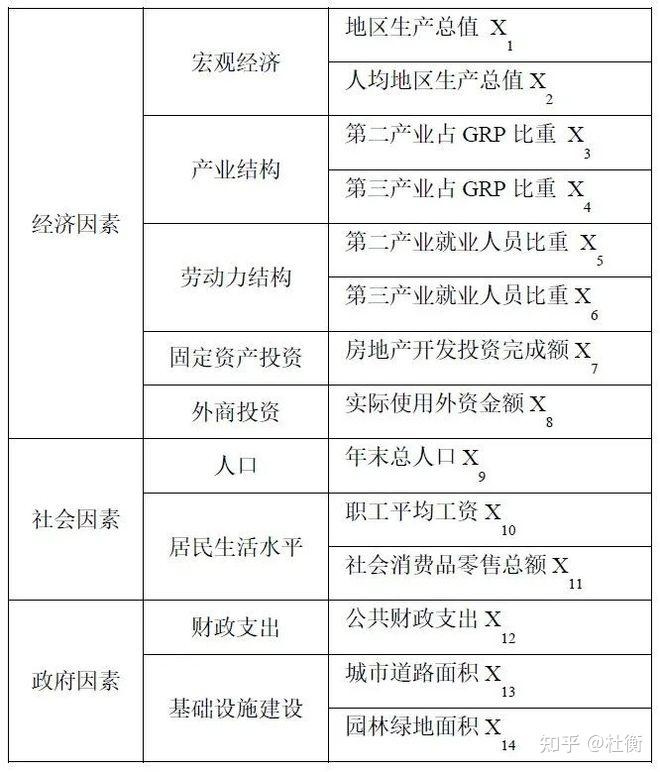
输入数据包括因变量Y和自变量数据X。自变量应为类型量;如果自变量为数值量,则需要进行离散化处理。离散可以基于专家知识,也可以直接等分或使用分类算法如K-means等。若数据为GIS数据,需要先将其转化为下图所示的Excel数据。小编以现有数据2017年城市蔓延度为因变量,选取自变量指标如下表,并将这14个指标进行自然断点法划分为5类。
二、实现方法
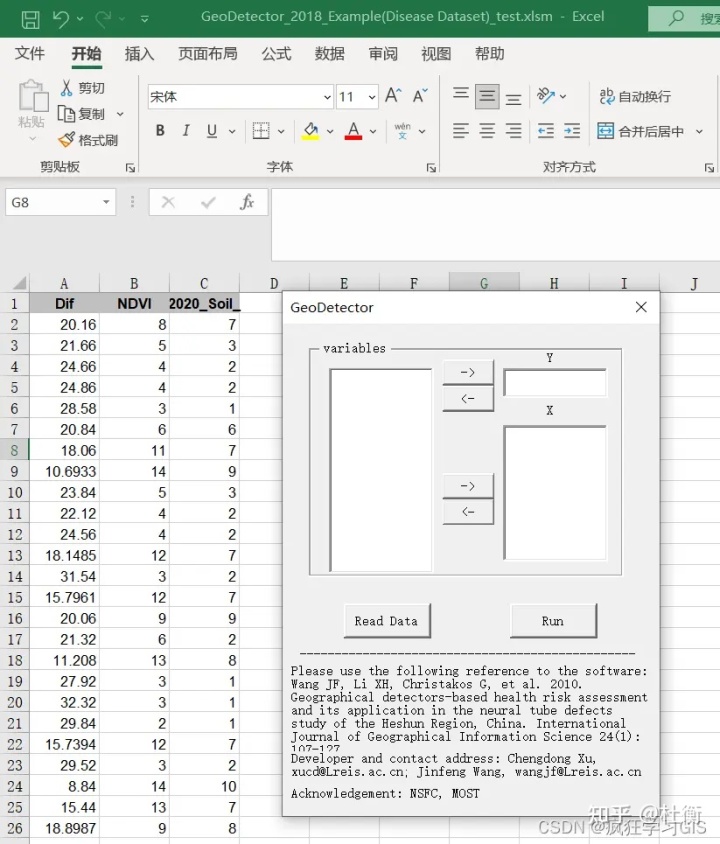
2.1 实现方法一:Geodetector 软件
该软件是基于Excel表格运行的,Geodetector软件就相当于是Excel表格文件中的一个宏。
需要注意,在进行地理探测器操作时,我们的自变量(上图中最后两列)必须是类别数据(比如土壤类型数据、土地利用类型数据),不能是连续数据(比如人口数据、GDP数据);如果大家的自变量中有连续数据的话,一定要先转换成类别数据,再进行地理探测器分析。转换的方式有很多,比如假设你的连续数据是栅格格式的,那就可以用ArcGIS中的重分类工具,对原有的连续数据栅格进行转换。
2.2 实现方法二:R语言之geodetector包
from: R语言实现地理探测器的流程及代码
谷粒故里:R语言实现地理探测器的流程及代码6 赞同 · 0 评论文章编辑
R语言geodetector包涵盖五个函数:factor_detector,interaction_detector,risk_detector,ecological_detector和geodetector。前四个功能实现因子检测器,交互检测器,风险检测器和生态检测器的计算,可以使用表数据计算,例如csv格式。最后一个函数geodetector是一个辅助函数,可用于实现shapefile格式映射数据的计算。
数据要求:需要保证输入的自变量数据已经全部为类别数据。
关于geodetector包官网有详细的介绍和教程,地址如下:https://cran.r-project.org/web/packages/geodetector/vignettes/geodetector.html#factor-detector
实现过程如下:
# (1)数据预处理
X 处理为离散型数据(对于栅格数据,可用栅格重分类;对于矢量数据(渔网),在mapGIS中建立gdb文件,将数据导入文件地理数据库,属性-符号化-将字段分级,或矢量数据分级显示之后,convert symbology to representation)
Y 处理为点数据(渔网)
# (2) 加载geodetector包及数据导入(操作时将”文件夹名称“替换成需处理的文件即可)
> install.packages("geodetector") *加载包*
> library(geodetector) *引用包*
> install.packages("readr")
> library(readr)
> read_csv(“文件夹名称.csv”) *读自己命名的数据 (注意,数据要放在当前工作的文件夹中)*
> 文件夹名称=read_csv("文件夹名称.csv") *数据赋值*
> 文件夹名称 *指定文件*
## 2.2.1 因子探测器
> factor_detector("Y", "X", as.data.frame(文件夹名称)) *其中as函数为转换为数据框*
## 2.2.2 交互探测器
> interaction_detector (17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database))
*其中当”X"为多个因子的时候,可以用c(2,3,4,5,6,7,8,9,10,11) 表示,数字代表列号。*
## 2.2.3 风险探测
> risk_detector(17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database))
## 2.2.4 生态探测
> ecological_detector(17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database))
# (3) 导出结果
> result<-factor_detector(17,c(2,3,4,5,6,7,8,9,10,11),as.data.frame(database))
> write.csv(result,'./factor_detector_CMI.csv') *将结果写入csv文件*
geodetector包应用示例代码:
geo_data = read_xlss("his1_1.xlsx")
#11代表第11列的因变量;c(6,7,8,9,10)代表五个因变量;
result_1<-factor_detector(11, c(6,7,8,9,10),as.data.frame(geo_data))
result_2<-interaction_detector (11, c(6,7,8,9,10),as.data.frame(geo_data))
result_3<-risk_detector(11, c(6,7,8,9,10),as.data.frame(geo_data))
result_4<-ecological_detector(11, c(6,7,8,9,10),as.data.frame(geo_data))
#分别保存
write.csv(result_1,'./factor_detector_CMI.csv')若出现以下缺少程辑包的类似错误,就通过install.packages("utf8"),安装这个包就可以;
Error in loadNamespace(name) : 不存在叫‘utf8’这个名字的程辑包
函数返回结果中,q表示决定程度,p表示显著性。
2.3 实现方法二:R语言之GD包
GD package,全称 Geographical Detectors for Assessing Spatial Factors。
下载:https://cran.r-project.org/web/packages/GD/index.html
> install.packages("GD") *加载包*
> library("GD") *引用包*
> install.packages("readr")
> library(readr)
Examples
## NDVI: ndvi_40
# set optional parameters of optimal discretization
# optional methods: equal, natural, quantile, geometric, sd and manual
discmethod <- c("equal", "quantile")
discitv <- c(4:5)
## "gdm" function
ndvigdm <- gdm(NDVIchange ~ Climatezone + Mining + Tempchange, continuous_variable = c("Tempchange"), data = ndvi_40, discmethod = discmethod, discitv = discitv)
ndvigdm
plot(ndvigdm)
# H1N1:h1n1_100
# set optional parameters of optimal discretization
discmethod <- c("equal","natural","quantile")
discitv <- c(4:6)
continuous_variable <- colnames(h1n1_100)[-c(1,11)]
# "gdm" function
h1n1gdm <- gdm(H1N1 ~ ., continuous_variable = continuous_variable, data = h1n1_100, discmethod = discmethod, discitv = discitv)
h1n1gdm
plot(h1n1gdm)
# endGD包与geodetector的不同是,GD包输入连续的数据(不需要分级),通过gdm函数的以下两个参数完成自动选择最适合的分级方法和分级类别数量;而geodetector包需要的自变量数据需要是分级之后的(如使用ArcGIS的reclassify工具实现栅格数据分级,再使用点数据提取分级数值),可以是Excel、CSV等格式(分别通过调用readxl,readr包中的read_xlsx,read_csv函数实现)。
2.4 实现方法三:Geodetector software in QGIS (please use google to access)
链接:https://github.com/gsnrguo/QGIS-Geographical-detector
三、实例
下面利用地理探测器功能对某县神经管畸形出生缺陷(NTDs)发生率进行分析,环境因子变量包括:土壤类型、高程、水文流域。下图为环境因子分析的数据示意:

分析结果如下:
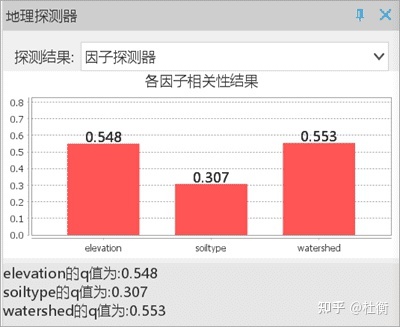
- 因子探测器:结果展示了所有因子 q 值的计算结果,结果表明,水文流域变量(watershed)具有最高的 q 值,说明这些变量中河流是决定 NTDs 空间格局最主要的环境因子。
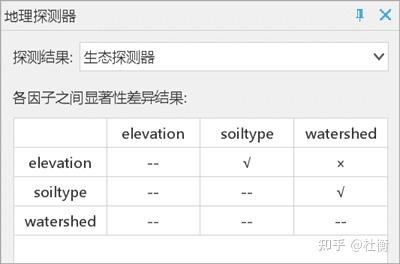
- 生态探测器:结果采用显著性水平为0.05的 t 检验,“√” 表示存在显著性,“×” 表示不显著。就对NTDs空间分布的作用而言,土壤类型与其他变量存在着显著差异。
- 交互探测器:以高程因子( elevation)为例,结果表明任何两种变量对 NTDs 空间分布的交互作用都要大于第一种变量的独自作用,两两解释变量对NTDs空间分布的交互作用为双因子增强。
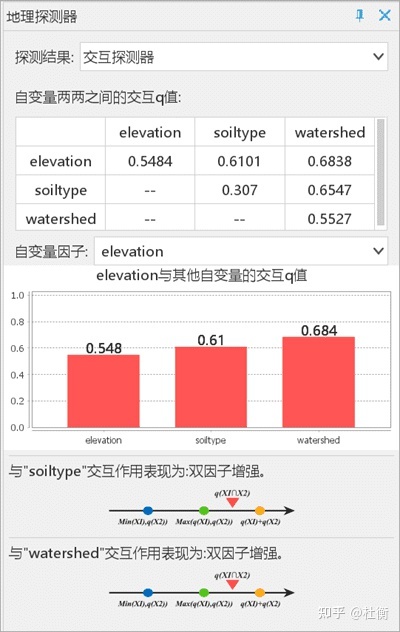
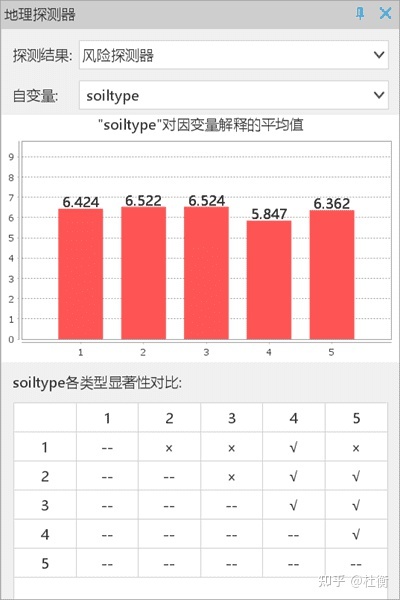
- 风险探测器:结果显示了对于单个风险因子而言的风险区探测的结果。以土壤类型( soiltype)为例,柱状图中 x 轴为 Unique Value,是环境因子各分层编号;y 轴为 Mean od explained variable,是在每种土壤类型区内的NTDs的平均发病率。
各类型显著性对比是,采用显著性水平为0.05的t检验,对比各类土壤类型(1-5)上的NTDs发病率是否显著大于另一土壤类型上的 NTDs 发病率,“√” 表示存在显著性,“×” 表示不显著。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 58
58 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)