
【yolov5系列】yolov5的原理与核心代码解析
然后对左图是对右图的pool进行了合并连接。上面代码处理后,标签和匹配的anchor是的尺寸是【原图尺寸下的标签尺寸下采样到某一个输出层时的尺寸】(这里的原图尺寸 指的是图片像素级resize到神经网络输入时的尺寸,代码中备注的也是)。原因是为了正样本扩充,因为标签在扩充后的正样本的xy的数值范围在(-0.5,1.5)之间,所以需要转换后的偏移。】 为检测框对应的xywh,具体的为:xy检测框的中
打算写yolov5源码阅读和总结,已经打算了一年,如今已经更新到yolov8,只能说自己行动太慢了,哭泣(๑><๑)。趁着看要yolov8一起赶紧把yolov5总结总结。
在本篇博客中,从网络结构、正样本分配(与扩充)、损失函数、数据增强 四个方面来记录yolov5的工程。
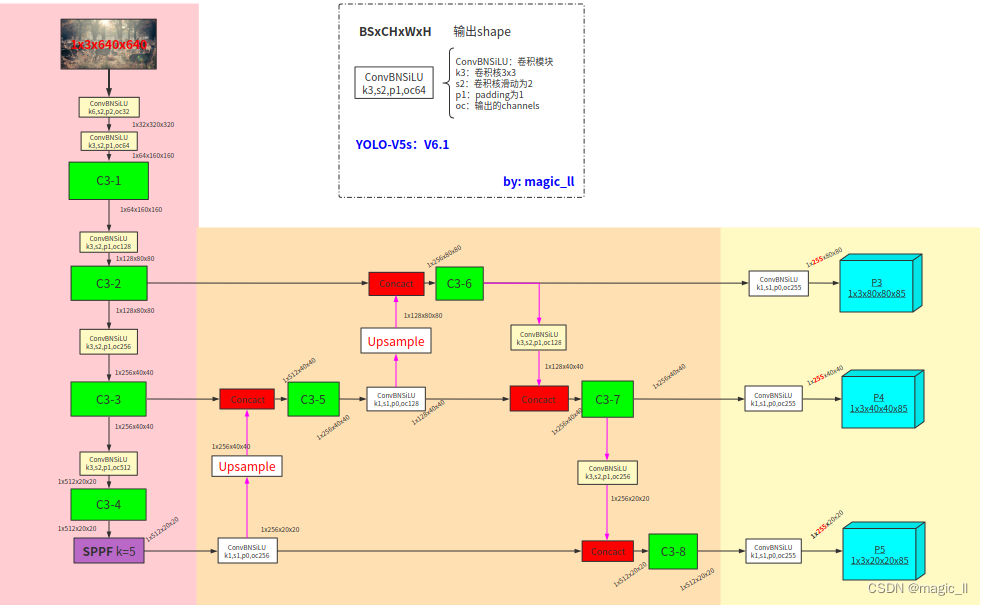
1 Yolov5的网络结构
该网络结构示意图中的featuremap的尺寸,为yolos的检测模型的尺寸

模型主要分为3部分
- backbone:C3、SPPF、Conv_BN_SiLU(strides=2,用于下采样)
- neck:FPN、PAN
- head:Conv_BN_SiLU、输出
1.1 backbone模块
1.1.1 ConvBNSiLU
对与yolov5,最基础的模块 卷积+BN+激活层 为【Conv_BN_SiLU】,下面使用conv直接指代,这部分的实现如下
class Conv(nn.Module): # Standard convolution def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): return self.act(self.conv(x))
1.1.2 C3
C3代替了yolov5较早版本中使用的CSP,起到作用:简化了体系结构,减少了参数计数,并在推理时更好地利用fuse。这里只画了C3的结构如下(虚线框里的输入输出通道假设为64)
class Bottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) class C3(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c1, c_, 1, 1) self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) def forward(self, x): return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
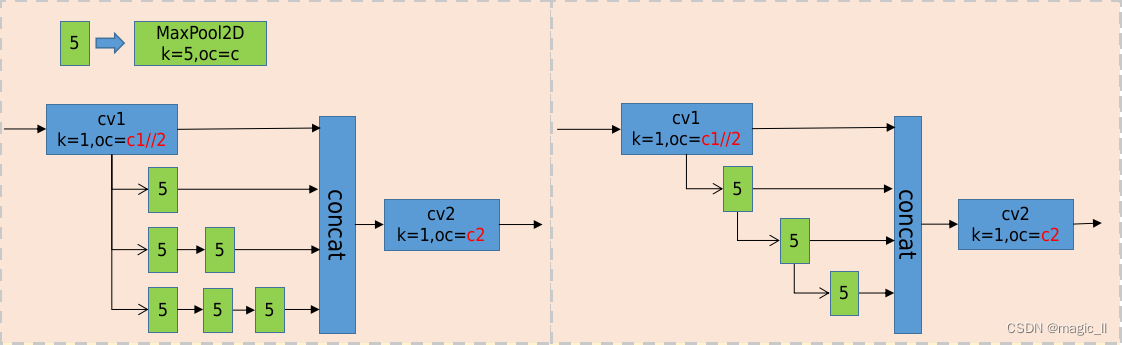
1.1.3 SPP vs SPPF
先摆出SPP和SPPF的对比图
分析一下两者区别
- SPP(空间金字塔池化):
原论文解读在 SPPNet,这里的SPP是借鉴了SPPNet中的模块,使用不同kernel的池化层对featuremap进行信息提取然后concat。具体的如下:
1)先在通过一个ConvBNSiLU。
2)然后分别通过三个MaxPool2D,默认stride=1,且进行padding,如此整个过程不会改变featuremap的尺寸;
对应的kernel分别为5,9,13,对应的感受野分别为5*5,9*9,13*13。
3)然后进行concat,再通过ConvBNSiLU得到模块最后的输出。- SPPF:
与SPP不同的是MaxPool2D的堆叠方式。
分析:
- 对于9*9的MaxPool2D 等价与 两个5*5的MaxPoolD2D的堆叠;13*13的MaxPoolD等价于三个5*5的MaxPoolD2D的堆叠,可将SPP的结构修改成下图左图;然后对左图是对右图的pool进行了合并连接。其中左图是完全等价SPP的,右图是则SPPF,与上图右图完全一致。
如此,SPPF相较于SPP的效果精度并未改变的同时,节省了三个k=5的MaxPool2D的计算,较大的提升了运行时间
- 注意:
特征图的输入尽量保证尺寸 大于等于13、且靠近13,此时网络的状态将会相对更优。
1)若SPPF的输入尺寸为13,神经网络此时输入尺寸为13*32=418。此时效果和运行时间达到最佳
2)若SPPF的输入尺寸为8(小于13较多),MaxPool2D提供13的感受野 将会有冗余的操作以及冗余的时间消耗。此时对于SPPF可去掉一个MaxPool2D,节省时间的同时获取相近的效果。
3)若SPPF的输入尺寸为25 (大于13较多),MaxPool2D提供的13的感受野 无法获取到图像的全局特征,此时效果将会降低一些,自己在训练时可留意这里的处理。class SPP(nn.Module): # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729 def __init__(self, c1, c2, k=(5, 9, 13)): super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1) self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k]) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1)) class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x) with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))



1.2 neck模块
neck模块部分, 包含 FPN (Feature Pyramid Network)、PAN (Path Aggregation Network)。两者都是在解决目标检测中 多尺度检测任务上的不足,都是将高层的语义信息与低层的空间信息结合,然后再进行信息提取。换句话说就是 自上而下或自下而上地融合不同尺度信息的特征。
FPN和PAN都有对应的论文和完整的网络结构,但在后来的使用中,很少指原论文中的网络结构,而是来强调 不同特征进行融合的模块。FPN是unsample+merge,PAN是downsample+merge,其中merge有add、concat,具体为哪种形式看每个工程自己的使用情况。在yolov5中,使用的是concat。
1.2.1 FPN
Feature Pyramid Network是由FAIR在2017年提出的一种处理多尺度问题的方法。
上图是多尺度问题,其中(d)为FPN。具体的细节如下,主打一个upsample + concat,将不同尺度的特征图融合,然后再特征提取:
1.2.2 PAN
Path Aggregation Network是由Megvii在2018年提出的一种处理多尺度问题的方法。与FPN类似,PAN也是一种金字塔式的特征提取网络,但是它采用的是自下而上的特征传播方式。




1.3 head
对于检测头,就是一个ConvBNSiLU,然后得到神经网络的输出。
共有三个尺度的输出分别为 1x255x20x20、1x255x40x40、1x255x80x80。其中
- 【1】 为batch
- 【255】 为 (80+1+4)*3:
- 【80:class】 为coco数据集中目标检测的类别数,将其转换成one-hot形式;
- 【1:confidence】 为是否为目标;
- 【4:box】 为检测框对应的xywh,具体的为:xy检测框的中心下采样到某层输出上,距离grid ceil 左上角的偏移,wh为检测框的长宽与当前anchor的长宽的比值。
- 【3】 为在每个grid cell 上预测3个检出信息,分别对应3个anchor。
- 【80x80/40x40/20x20】不同降采样层的输出尺寸,80x80对应有80x80个grid cell。


2 标签的正样本分配
首先回一下 anchor的相关内容。在yolov5中会先匹配数据集中的anchor和工程中默认的anchor,如果差异较大,则启动自动计算anchor操作。
已知特征图尺寸越大,感受野相对较小。遵循“大尺寸预测小物体,小尺寸预测大物体”的原则,将9个anchor分配到3个输出层,平均每层3个anchor。
当我们有了一个标签[class, x,y,w,h],那么我们将它与网络输出矩阵的哪些维度进行loss呢?
- 标签的wh:决定了与网络输出的哪一层哪一个anchor对应的维度进行匹配。
- 标签的xy:决定了与网络输出的哪一grid_ceil进行匹配,然后再进行正样本扩充
- 标签的class:决定了onehot的表达
如下图中的标签与输出矩阵 在图中青蓝色的部分匹配上,然后对齐两者的数值表达最后进行loss。一个标签框可匹配多个anchorBox,也就有可能匹配到多层检测头上进行lossfunction。
2.2 标签的与anchor的匹配(由标签的wh决定)
在yolov5中,标签的分配采用静态分配策略。网络有三层输出层,每层输出层有3个anchor。如何将每个标签分配到具体的位置上进行loss的计算呢?
使用anchor和目标框的高宽比进行筛选的。具体的分配规则如下: r w = w g t / w a t r h = h g t / h a t r w m a x = max ( r w , 1 / r w ) r h m a x = max ( r h , 1 / r h ) r m a x < a n c h o r t \begin{aligned} &r_w = w_{gt}/w_{at} \\ &r_h = h_{gt}/h_{at} \\ &r^{max}_{w} = \max (r_w, 1/r_w) \\ &r^{max}_{h} = \max (r_h, 1/r_h) \\ &r^{max} <anchor_t \end{aligned} rw=wgt/watrh=hgt/hatrwmax=max(rw,1/rw)rhmax=max(rh,1/rh)rmax<anchort其中 a n c h o r t anchor_t anchort在yolov5中默认设置为4。这代表着在grid ceil 中预测的框的大小为对应anchor的1/4或者4倍。
通过上面的方式,就可确定了哪一层的哪一个anchor对应的输出channel上的 [是否为目标项] 就可设置为有效的数值(一般的默认为1,yolov5中使用的是输出框和标签框的ciou,后面会讲),计算loss进行梯度
2.3正样本的选定 与 正样本扩充(由标签的xy决定)
标签的中心分别下采样到3个输出层的尺寸,即可得到对应grid ceil的位置,该grid ceil为正样本。结合上面可选定对应的anchor。
目标检测中,通常背景(负样本,没有目标的grid ceil)占据比例较大,为了降低正负样本的失衡程度,需要扩增正样本。在YOLO-V5的代码中,是在正样本的上/下/左/右四个位置,选择两个进行扩增。举个例子:
- 蓝点:目标框的中心位置
黄色grid ceil:正常样本
淡橙色grid ceil:备选的四个扩充样本
黑色 ∗ * ∗:正常样本的grid ceil的左上角
红色 ∗ * ∗:扩充样本的grid ceil的左上角- 那么如何确定扩充样本的位置呢?
备选的扩充正样本的位置为 标准正样本所在的grid ceil 的上下左右4个grid ceil。从其中选两个为扩充正样本,选择标准直观的理解是:目标框中心更靠近的两个grid ceil,具体操作为:
- x方向,框中心偏移<0.5,就选择左边的为扩充正样本;框中心偏移>0.5,就选择右边的为扩充正样本
y方向,框中心偏移<0.5,就选择上边的为扩充正样本;框中心偏移>0.5,就选择下边的为扩充正样本
扩充后目标框中心与扩充正样本的左上角的偏移范围变成了(-0.5,1.5),yolov3中的偏移范围为(0,1),左右各扩大了0.5的偏移。
假设蓝点的xy距离自身grid ceil左上角的偏移为 (0.2, 0.4),此时的扩充正样本为【上、左】的两个grid ceil。此时xy与两个扩充样本的grid ceil的左上角的偏移为上(0.2, 1.4),左(1.2, 0.4)。
目标框中心与其余两个没被选上的grid ceil的偏移分别为下(0.2, -0.6),右(-0.8, 0.4),我们可以发现它超过了(-0.5,1.5)范围。2.4 负样本
在yolov5中没有忽略样本。上面的正样本分配和扩充的位置除外,其余的都是负样本,这里可以先提一下,负样本在loss中只进行 object loss的反向传播,关于xywh和类别的loss不进行反向传播
2.5 相关代码解析







3 模型输出与loss
3.1 模型输出的box转换
网络的输出矩阵的元素,会经过sigmoid函数,将其范围处理到(0,1)之间。上面代码处理后,标签和匹配的anchor是的尺寸是【原图尺寸下的标签尺寸下采样到某一个输出层时的尺寸】(这里的原图尺寸 指的是图片像素级resize到神经网络输入时的尺寸,代码中备注的也是)。
两者是不对齐,是不能进行loss的。那么就需要将网络输出的xywh转换成与标签尺度一致的尺寸。
- 在yolov2和v3中使用的是
- 在yolov5中有所改进:
b x = ( 2 ∗ σ ( t x ) − 0.5 ) + c x b y = ( 2 ∗ σ ( t y ) − 0.5 ) + c y b w = p w ∗ ( 2 σ ( t w ) ) 2 b h = p h ∗ ( 2 σ ( t h ) ) 2 \begin{aligned} b_x&=(2*\sigma (t_x)-0.5)+c_x \\ b_y&=(2*\sigma (t_y)-0.5)+c_y \\ b_w&=p_w*(2\sigma(t_{w}))^2 \\ b_h&=p_h*(2\sigma(t_{h}))^2 \end{aligned} bxbybwbh=(2∗σ(tx)−0.5)+cx=(2∗σ(ty)−0.5)+cy=pw∗(2σ(tw))2=ph∗(2σ(th))2其中, t x , t y , t w , t h t_x,t_y,t_w,t_h tx,ty,tw,th为网络输出的部分内容; b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh为预测框的中心和宽高(归一化后的); p w , p h p_w,p_h pw,ph是归一化后的先验框的宽高; c x , c y c_x,c_y cx,cy是预测框处于的grid ceil 在对应featuremap中的位置。
那么这样改动带来了什么变化呢?
- 1)模型输出转换后的中心点偏移范围从(0,1)调整到(-0.5,1.5)。原因是为了正样本扩充,因为标签在扩充后的正样本的xy的数值范围在(-0.5,1.5)之间,所以需要转换后的偏移 ( 2 ∗ σ ( t x ) − 0.5 ) (2*\sigma (t_x)-0.5) (2∗σ(tx)−0.5)范围也是(-0.5,1.5)。
- 2)模型输出后转换后的高宽与anchor的高宽的比例范围为(0,4)。 原因是yolov5在标签静态分配时,选择的是在输出层的尺度下,标签与anchor的宽高之间比例 ( 2 σ ( t w ) ) 2 (2\sigma(t_{w}))^2 (2σ(tw))2范围为(0.25,4)。这样标签的xywh和网络输出转换后的具有范围,有效的能够训练。
在yolov3中,box方程有一个严重的缺陷:宽度和高度是完全无限制的,out=exp(in)可能导致梯度爆炸、训练不稳定。
3.2 loss function
yolov5目标检测的loss function分为3项:box loss,object loss,class loss。工程为 L o s s = w b o x ∗ l b o x + w o b j ∗ l o b j + w c l s ∗ l c l s Loss = w_{box}*l_{box}+w_{obj}*l_{obj }+ w_{cls}*l_{cls} Loss=wbox∗lbox+wobj∗lobj+wcls∗lcls
- 【box function】在得到每个输出尺寸下的标签和网络的输出,然后损失函数设置为 IOUloss=(1-IOU).mean()。在yolov5中选择了CIOUloss,box的损失函数发展IOULoss、GIOUloss、DIOUloss、CIOUloss…
- 【object function】使用的是sigmoid交叉熵。
- 这里的标签不是1,而是输出和标签的CIOU,所以该项也可称作为IOU confidence。这样训练好测试时可以用这一维度的输出代表框检测的质量,当该值较大,说明预测的检测框与真实框更贴近(虽然此时是没有真实框)。但有个明显的影响是label值的减小使得预测的值也变小。
- 在三个输出层,对应的特征点的数量为 4:1:0.25,所以该损失在每层设置了不同的权重。在工程中设置了4:1:0.4,相似的比例可达相同的效果。
- 【class function】使用的是sigmoid交叉熵。因为输出层的某一个grid ceil可能存在多个目标框的中心,所以是同一个数据对应了多个类别标签。所以需要使用sigmoid交叉熵,而不是softmax交叉熵。
常用的分类损失函数有两种:
1) softmax交叉熵:适用于多分类的情况,数据和标签是一对一的,每个类别之间是互斥的。在pytoch中的api为【nn.CrossEntropyLoss()】
2) sigmoid交叉熵:适用于2分类,或数据和标签一对多的情况。在pytorch中的api为【nn.BCEWithLogitsLoss()】
这两个api的入参有个权重的信息,可一定程度上解决数据集中类别样本不均衡的问题。正负样本的训练:
- 当为正样本,三个损失都参与反向传播;当为负样本时,只有object loss参与反向传播
损失函数这里主要设置的超参数为:
- 损失函数中每个部分的权重:hyp['box ']、hyp['obj ']、hpy['cls ']
是否为目标的2分类、目标类别分类之间的权重分别为:hpy['cls_pw ']、hpy['obj_pw ']





4 数据读取与增强
首先我们需要先了解pytorch框架的数据读取的常规操作pytorch记录】torch.utils.data.Dataset、DataLoader、分布式读取并数据。
然后为了更方便debug每一步数据处理都操作了什么:
- 在【train.py】最开始时添加【
os.environ["CUDA_VISIBLE_DEVICES"]="0"】,使得工程为单GPU训练模式
- 在【dataloaders.py】中的【def create_dataloader()】函数中将【num_workers=nw】改为【num_workers=0】,不给数据读取分配额外的线程,使得数据读取不具有随机性,在debug数据处理时 每次运行呈现的是相同的图片
在yolov5工程中,数据读取与增强的操作主要有:
- def __init__() 中判断是否已将标签保存为cache文件。
否:读取路径或列表中的标签文件,提前保存成cache文件,节省训练时读取标签并处理的时间。
是:判断cache内存储的版本、判断cache内保存的哈希值和 数据集路径列表的所有文件大小总值的哈希值是否一致。如果出现不一致说明数据集标签发生了变化,则重新保存cache文件。- def __getitem__()中,包含了图片的增强处理。增强超参数设置可选择其是否进行某项增强。具体的增强方式有:
- mosaic、mixup
- 旋转、平移、缩放、错切、透视
- HSV色域泛化、左右翻转、上下翻转
我们先定义个函数draw,将标签画到图片上并保存用于可视化(我这里是服务器上运行,所以只能保存图片可视化),注意这里的标签输入是xyxy
def draw(path, image, labels): img_T = image.copy() for s in range(len(labels)): l = labels[s].astype(np.int) cv2.rectangle(img_T, (l[1],l[2]),(l[3],l[4]), (0, 0, 255), 3) cv2.imwrite(path, img_T)然后多次修改判断条件,加上保存图片的调用。








旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)