
ChatGLM3-6B的本地api调用
ChatGLM3-6B的本地api调用方式
1.运行openai_api_demo路径下的openai_api.py
启动后界面:

注意:本地api调到的前提是——本地部署了ChatGLM3-6B,本地部署的教程可参考:
20分钟部署ChatGLM3-6B
部署了若CUDA可用,默认会以CUDA方式运行,占用显存约5.9G;若CUDA不可用,则会以内存方式进行加载,官方称CPU调用需要32G内存(实际约30G)
2.api调用
官方给了两种调用示例:
1)使用Curl进行测试:
curl -X POST “http://127.0.0.1:8000/v1/chat/completions”
-H “Content-Type: application/json”
-d “{“model”: “chatglm3-6b”, “messages”: [{“role”: “system”, “content”: “You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user’s instructions carefully. Respond using markdown.”}, {“role”: “user”, “content”: “你好,给我讲一个故事,大概100字”}], “stream”: false, “max_tokens”: 100, “temperature”: 0.8, “top_p”: 0.8}”
- 使用Python进行测试:
cd openai_api_demo
python openai_api_request.py
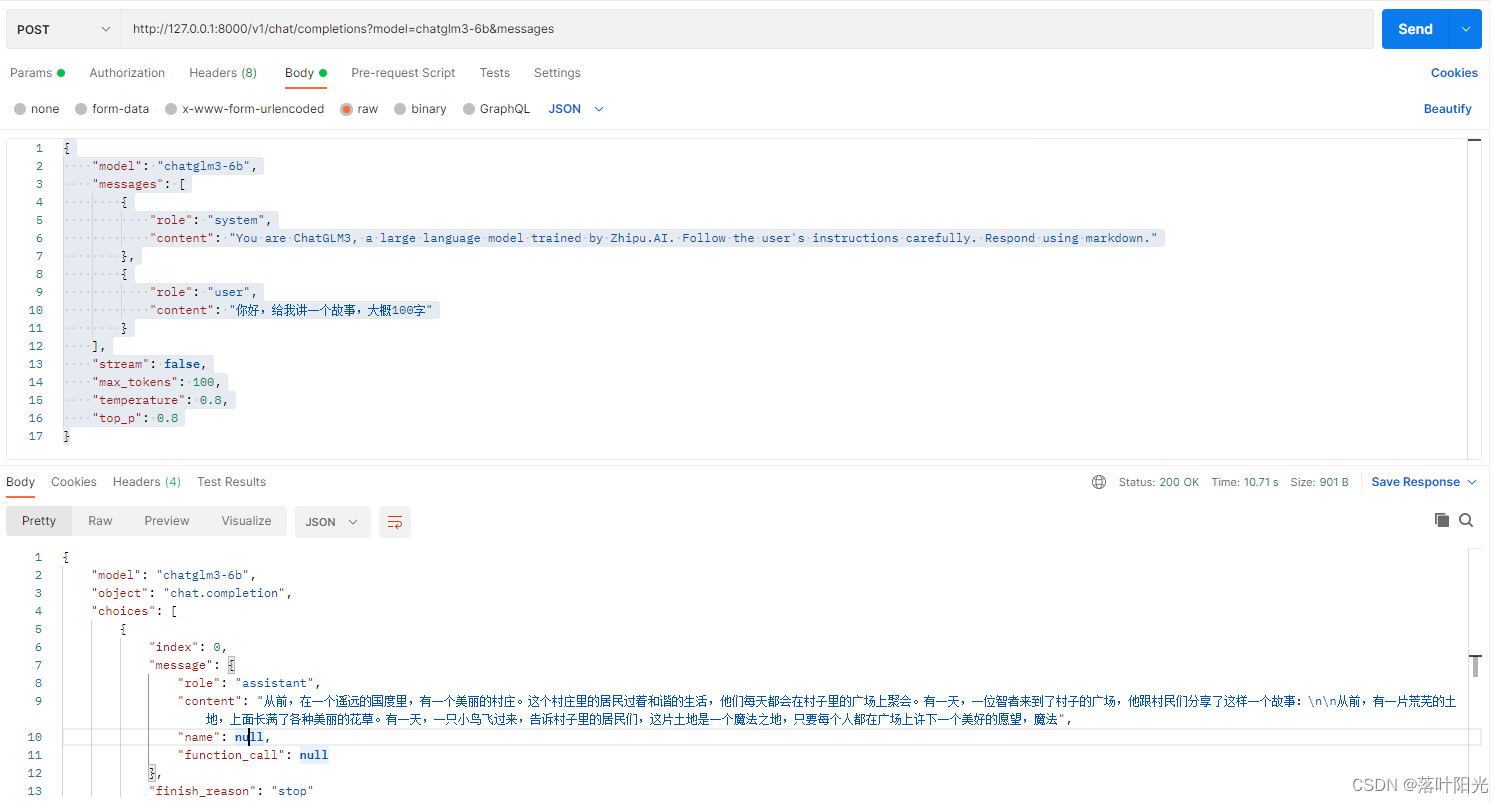
3)postman调用(推荐):
这里,我补充一个postman接口调用的方式,更能理解接口和参数分别是什么。

接口:
http://127.0.0.1:8000/v1/chat/completions
注意是POST方法!
传递参数:
{
“model”: “chatglm3-6b”,
“messages”: [
{
“role”: “system”,
“content”: “You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user’s instructions carefully. Respond using markdown.”
},
{
“role”: “user”,
“content”: “你好,给我讲一个故事,大概100字”
}
],
“stream”: false,
“max_tokens”: 100,
“temperature”: 0.8,
“top_p”: 0.8
}
返回结果:
{
“model”: “chatglm3-6b”,
“object”: “chat.completion”,
“choices”: [
{
“index”: 0,
“message”: {
“role”: “assistant”,
“content”: “从前,在一个遥远的国度里,有一个美丽的村庄。这个村庄里的居民过着和谐的生活,他们每天都会在村子里的广场上聚会。有一天,一位智者来到了村子的广场,他跟村民们分享了这样一个故事:\n\n从前,有一片荒芜的土地,上面长满了各种美丽的花草。有一天,一只小鸟飞过来,告诉村子里的居民们,这片土地是一个魔法之地,只要每个人都在广场上许下一个美好的愿望,魔法”,
“name”: null,
“function_call”: null
},
“finish_reason”: “stop”
}
],
“created”: 1704786453,
“usage”: {
“prompt_tokens”: 54,
“total_tokens”: 154,
“completion_tokens”: 100
}
}
可以看到,ChatGLM3-6B的默认调用接口和传递参数,及返回结果的参数与chatGLM2-6B的API有非常大的区别,并不兼容,需要有较大的修改
ChatGLM2-6B的本地api调用方式
ChatGLM2-6B在2024年已经属于过去时了,若有小伙伴有需求,可留言,我抽时间把它补充上。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)