
GAN的pytorch代码实现(代码详细注释)
·
GAN的思想
假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的“运动”,警察们开始恢复城市中的巡逻,很快,一批“学艺不精”的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。
警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。
为了避免被捕,小偷们努力表现得不那么“可疑”,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种“交流”与“切磋”,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了“火眼金睛”,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。
实现代码
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch
## 创建文件夹
os.makedirs("./images/gan/", exist_ok=True) ## 记录训练过程的图片效果
os.makedirs("./save/gan/", exist_ok=True) ## 训练完成时模型保存的位置
os.makedirs("./datasets/mnist", exist_ok=True) ## 下载数据集存放的位置
## 超参数配置
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=500, help="interval betwen image samples")
opt = parser.parse_args()
## opt = parser.parse_args(args=[]) ## 在colab中运行时,换为此行
print(opt)
## 图像的尺寸:(1, 28, 28), 和图像的像素面积:(784)
img_shape = (opt.channels, opt.img_size, opt.img_size)
img_area = np.prod(img_shape)
## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
## mnist数据集下载
mnist = datasets.MNIST(
root='./datasets/', train=True, download=True, transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
)
## 配置数据到加载器
dataloader = DataLoader(
mnist,
batch_size=opt.batch_size,
shuffle=True,
)
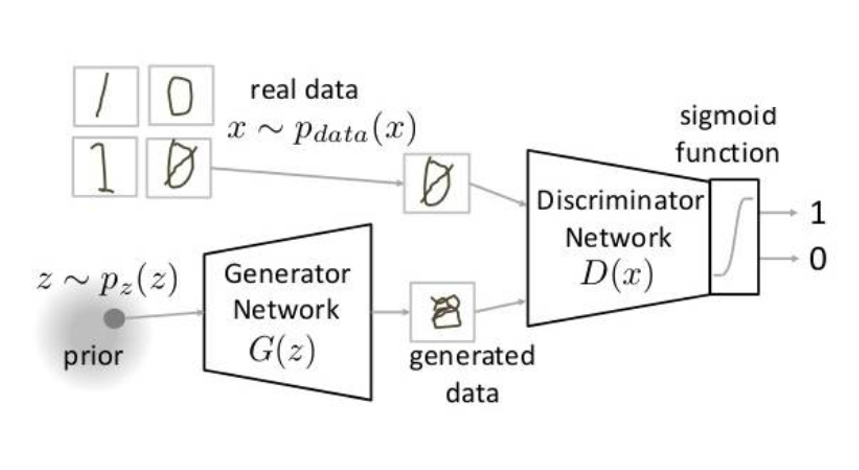
## ##### 定义判别器 Discriminator ######
## 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
## 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(img_area, 512), ## 输入特征数为784,输出为512
nn.LeakyReLU(0.2, inplace=True), ## 进行非线性映射
nn.Linear(512, 256), ## 输入特征数为512,输出为256
nn.LeakyReLU(0.2, inplace=True), ## 进行非线性映射
nn.Linear(256, 1), ## 输入特征数为256,输出为1
nn.Sigmoid(), ## sigmoid是一个激活函数,二分类问题中可将实数映射到[0, 1],作为概率值, 多分类用softmax函数
)
def forward(self, img):
img_flat = img.view(img.size(0), -1) ## 鉴别器输入是一个被view展开的(784)的一维图像:(64, 784)
validity = self.model(img_flat) ## 通过鉴别器网络
return validity ## 鉴别器返回的是一个[0, 1]间的概率
## ###### 定义生成器 Generator #####
## 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
## 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
## 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布, 能够在-1~1之间。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
## 模型中间块儿
def block(in_feat, out_feat, normalize=True): ## block(in, out )
layers = [nn.Linear(in_feat, out_feat)] ## 线性变换将输入映射到out维
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) ## 正则化
layers.append(nn.LeakyReLU(0.2, inplace=True)) ## 非线性激活函数
return layers
## prod():返回给定轴上的数组元素的乘积:1*28*28=784
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False), ## 线性变化将输入映射 100 to 128, 正则化, LeakyReLU
*block(128, 256), ## 线性变化将输入映射 128 to 256, 正则化, LeakyReLU
*block(256, 512), ## 线性变化将输入映射 256 to 512, 正则化, LeakyReLU
*block(512, 1024), ## 线性变化将输入映射 512 to 1024, 正则化, LeakyReLU
nn.Linear(1024, img_area), ## 线性变化将输入映射 1024 to 784
nn.Tanh() ## 将(784)的数据每一个都映射到[-1, 1]之间
)
## view():相当于numpy中的reshape,重新定义矩阵的形状:这里是reshape(64, 1, 28, 28)
def forward(self, z): ## 输入的是(64, 100)的噪声数据
imgs = self.model(z) ## 噪声数据通过生成器模型
imgs = imgs.view(imgs.size(0), *img_shape) ## reshape成(64, 1, 28, 28)
return imgs ## 输出为64张大小为(1, 28, 28)的图像
## 创建生成器,判别器对象
generator = Generator()
discriminator = Discriminator()
## 首先需要定义loss的度量方式 (二分类的交叉熵)
criterion = torch.nn.BCELoss()
## 其次定义 优化函数,优化函数的学习率为0.0003
## betas:用于计算梯度以及梯度平方的运行平均值的系数
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
## 如果有显卡,都在cuda模式中运行
if torch.cuda.is_available():
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion = criterion.cuda()
## ----------
## Training
## ----------
## 进行多个epoch的训练
for epoch in range(opt.n_epochs): ## epoch:50
for i, (imgs, _) in enumerate(dataloader): ## imgs:(64, 1, 28, 28) _:label(64)
## =============================训练判别器==================
## view(): 相当于numpy中的reshape,重新定义矩阵的形状, 相当于reshape(128,784) 原来是(128, 1, 28, 28)
imgs = imgs.view(imgs.size(0), -1) ## 将图片展开为28*28=784 imgs:(64, 784)
real_img = Variable(imgs).cuda() ## 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度
real_label = Variable(torch.ones(imgs.size(0), 1)).cuda() ## 定义真实的图片label为1
fake_label = Variable(torch.zeros(imgs.size(0), 1)).cuda() ## 定义假的图片的label为0
## ---------------------
## Train Discriminator
## 分为两部分:1、真的图像判别为真;2、假的图像判别为假
## ---------------------
## 计算真实图片的损失
real_out = discriminator(real_img) ## 将真实图片放入判别器中
loss_real_D = criterion(real_out, real_label) ## 得到真实图片的loss
real_scores = real_out ## 得到真实图片的判别值,输出的值越接近1越好
## 计算假的图片的损失
## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新
z = Variable(torch.randn(imgs.size(0), opt.latent_dim)).cuda() ## 随机生成一些噪声, 大小为(128, 100)
fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。
fake_out = discriminator(fake_img) ## 判别器判断假的图片
loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的loss
fake_scores = fake_out ## 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
## 损失函数和优化
loss_D = loss_real_D + loss_fake_D ## 损失包括判真损失和判假损失
optimizer_D.zero_grad() ## 在反向传播之前,先将梯度归0
loss_D.backward() ## 将误差反向传播
optimizer_D.step() ## 更新参数
## -----------------
## Train Generator
## 原理:目的是希望生成的假的图片被判别器判断为真的图片,
## 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
## 反向传播更新的参数是生成网络里面的参数,
## 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的, 这样就达到了对抗的目的
## -----------------
z = Variable(torch.randn(imgs.size(0), opt.latent_dim)).cuda() ## 得到随机噪声
fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片
output = discriminator(fake_img) ## 经过判别器得到的结果
## 损失函数和优化
loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的loss
optimizer_G.zero_grad() ## 梯度归0
loss_G.backward() ## 进行反向传播
optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数
## 打印训练过程中的日志
## item():取出单元素张量的元素值并返回该值,保持原元素类型不变
if (i + 1) % 100 == 0:
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(), fake_scores.data.mean())
)
## 保存训练过程中的图像
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(fake_img.data[:25], "./images/gan/%d.png" % batches_done, nrow=5, normalize=True)
## 保存模型
torch.save(generator.state_dict(), './save/gan/generator.pth')
torch.save(discriminator.state_dict(), './save/gan/discriminator.pth')

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 93
93 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)