
【DrissionPage】入门指南及查找元素
目录
一、概述
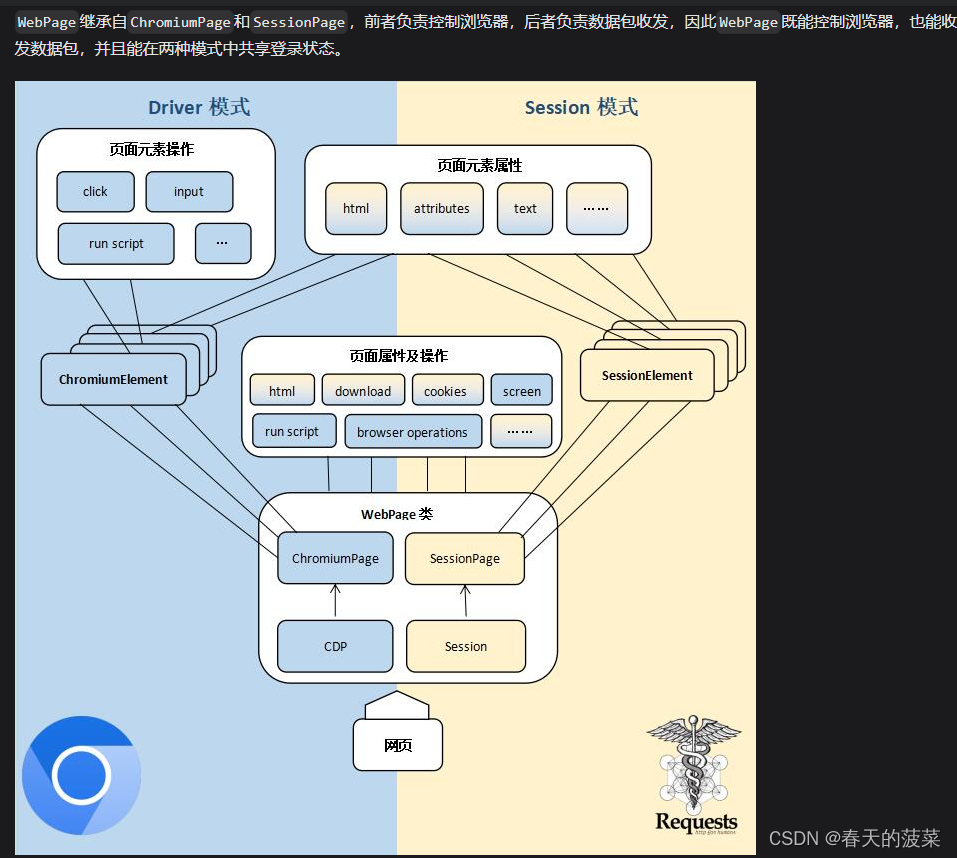
DrissionPage 是一个基于 python 的网页自动化工具。
它既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
它功能强大,内置无数人性化设计和便捷功能。
它的语法简洁而优雅,代码量少,对新手友好。
二、特性
2.1 强大的内核
本库采用全自研的内核,内置了 N 多实用功能,对常用功能作了整合和优化,对比 selenium,有以下优点:
- 无 webdriver 特征
- 无需为不同版本的浏览器下载不同的驱动
- 运行速度更快
- 可以跨 iframe 查找元素,无需切入切出
- 把 iframe 看作普通元素,获取后可直接在其中查找元素,逻辑更清晰
- 可以同时操作浏览器中的多个标签页,即使标签页为非激活状态,无需切换
- 可以直接读取浏览器缓存来保存图片,无需用 GUI 点击另存
- 可以对整个网页截图,包括视口外的部分(90以上版本浏览器支持)
- 可处理非
open状态的 shadow-root
2.2 亮点功能
- 极简的语法规则。集成大量常用功能,代码更优雅
- 定位元素更加容易,功能更强大稳定
- 无处不在的等待和自动重试功能。使不稳定的网络变得易于控制,程序更稳定,编写更省心
- 提供强大的下载工具。操作浏览器时也能享受快捷可靠的下载功能
- 允许反复使用已经打开的浏览器。无需每次运行从头启动浏览器,调试超方便
- 使用 ini 文件保存常用配置,自动调用,提供便捷的设置,远离繁杂的配置项
- 内置 lxml 作为解析引擎,解析速度成几个数量级提升
- 使用 POM 模式封装,可直接用于测试,便于扩展
- 高度集成的便利功能,从每个细节中体现
三、安装与升级
# 安装
pip install DrissionPage
# 升级
pip install DrissionPage --upgrade
# 升级指定版本
pip install DrissionPage==4.0.0b17
四、导包与简单示例
4.1 导包
# 如果只要控制浏览器,导入ChromiumPage。
from DrissionPage import ChromiumPage
# 如果只要收发数据包,导入SessionPage。
from DrissionPage import SessionPage
# WebPage是功能最全面的页面类,既可控制浏览器,也可收发数据包。
from DrissionPage import WebPage
4.2 简单示例
from DrissionPage import ChromiumPage
# 导入
from DrissionPage import ChromiumPage
# 创建对象
page = ChromiumPage()
# 访问网页
page.get('https://www.baidu.com')
# 输入文本
page('#kw').input('DrissionPage')
# 点击按钮
page('#su').click()
# 等待页面跳转
page.wait.load_start()
# 获取所有结果
links = page.eles('tag:h3')
# 遍历并打印结果
for link in links:
print(link.text)五、查找元素
5.1 概述
本库提供一套简洁易用的语法,用于快速定位元素,并且内置等待功能、支持链式查找,减少了代码的复杂性。
同时也兼容 css selector、xpath、selenium 原生的 loc 元组。
定位元素大致分为三种方法:
- 在页面或元素内查找子元素
- 根据 DOM 结构相对定位
- 根据页面布局位置相对定位
使用方式
所有页面对象和元素对象,都可以在自己内部查找元素,元素对象还能以自己为基准,相对定位其它元素。
页面对象包括:SessionPage、ChromiumPage、ChromiumTab、ChromiumFrame、WebPage、WebPageTab
元素对象包括:SessionElement、ChromiumElement、ShadowRoot
5.1.1 在页面中查找
使用页面对象的ele()和eles()方法,获取页面内指定元素对象。
from DrissionPage import SessionPage
page = SessionPage()
page.get('https://www.baidu.com')
ele = page.ele('#su')5.1.2 在元素中查找
使用元素对象的ele()、eles()、child()、children()方法,获取元素内指定后代元素对象。
ele1 = page.ele('#s_fm')
ele2 = ele1.ele('#su')
son = ele1.child('tag:div') # 获取第一个直接div子元素
sons = ele1.children('tag:div') # 获取所有直接div子元素5.1.3 链式查找
因为对象本身又可以查找对象,所有支持链式操作,上面两个例子可合并为:
ele = page.ele('#s_fm').ele('#su')5.1.4 相对查找
元素对象在以自己为基准,执行相对查找。
ele = page.ele('#su')
parent = ele.parent(2) # 获取ele元素的第二层父元素
brother = ele.next('tag:a') # 获取ele元素后面的第一个a元素
after = ele.after('tag:div') # 获取ele后面文档中第一个div元素5.1.5 shadow root
使用浏览器元素对象的shadow_root属性获取该元素下的ShadowRoot对象。
shadow = page.ele('#ele1').shadow_root在 shadow root 元素中搜索方法与普通元素一致。
shadow = page.ele('#ele1').shadow_root
ele = shadow.ele('#ele2')5.1.6 简单示例
<html>
<body>
<div id="one">
<p class="p_cls" name="row1">第一行</p>
<p class="p_cls" name="row2">第二行</p>
<p class="p_cls">第三行</p>
</div>
<div id="two">
第二个div
</div>
</body>
</html> id="su" class="btn self-btn bg s_btn">我们可以用页面对象去获取其中的元素:
# 获取 id 为 one 的元素
div1 = page.ele('#one')
# 获取 name 属性为 row1 的元素
p1 = page.ele('@name=row1')
# 获取包含“第二个div”文本的元素
div2 = page.ele('第二个div')
# 获取所有div元素
div_list = page.eles('tag:div')也可以获取到一个元素,然后在它里面或周围查找元素:
# 获取到一个元素div1
div1 = page.ele('#one')
# 在div1内查找所有p元素
p_list = div1.eles('tag:p')
# 获取div1后面一个元素
div2 = div1.next()5.2 基本用法 📌
5.2.1 查找元素的方法
ele()
页面对象和元素对象都拥有此方法,用于查找其内部的一个条件匹配的元素。
页面对象和元素对象的ele()方法参数名称稍有不同,但用法一样。
SessionPage和ChromiumPage获取元素的方法是一致的,但前者返回的元素对象为SessionElement,后者是ChromiumElement。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator(元素对象) | strTuple[str, str] | 必填 | 元素的定位信息。可以是查询字符串,或 loc 元组 |
locator(页面对象) | strSessionElementTuple[str, str] | 必填 | 元素的定位信息。可以是查询字符串、loc 元组或一个SessionElement对象 |
index | int | 1 | 获取第几个匹配的元素,从1开始,可输入负数表示从后面开始数 |
timeout | float | None | 等待元素出现的超时时间,为None使用页面对象设置,SessionPage中无效 |
| 返回类型 | 说明 |
|---|---|
SessionElement | SessionPage或SessionElement查找到的第一个符合条件的元素对象 |
ChromiumElement | 浏览器页面对象或元素对象查找到的第一个符合条件的元素对象 |
ChromiumFrame | 当结果是框架元素时,会返回ChromiumFrame,但 IDE 中不会包含该提示 |
NoneElement | 未找到符合条件的元素时返回 |
说明
- loc 元组是指 selenium 定位符,例:(By.ID, 'XXXXX')。下同。
ele('xxxx', index=2)和eles('xxxx')[1]结果一样,不过前者会快很多。
示例:
from DrissionPage import SessionPage
page = SessionPage()
# 在页面内查找元素
ele1 = page.ele('#one')
# 在元素内查找后代元素
ele2 = ele1.ele('第二行') eles()
此方法与ele()相似,但返回的是匹配到的所有元素组成的列表。
页面对象和元素对象都可调用这个方法。
eles()返回的是普通列表,链式操作需加下标,如page.eles('...')[0].ele('...')。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | 必填 | 元素的定位信息,可以是查询字符串,或 loc 元组 |
timeout | float | None | 等待元素出现的超时时间,为None使用页面对象设置,SessionPage中无效 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement] | SessionPage或SessionElement找到的所有元素组成的列表 |
List[ChromiumElement, ChromiumFrame] | 浏览器页面对象或元素对象找到的所有元素组成的列表 |
示例:
# 获取页面内的所有p元素
p_eles = page.eles('tag:p')
# 获取ele1元素内的所有p元素
p_eles = ele1.eles('tag:p')
# 打印第一个p元素的文本
print(p_eles[0])5.2.2 匹配模式
精确匹配 =
表示精确匹配,匹配完全符合的文本或属性。
# 获取name属性为'row1'的元素
ele = page.ele('@name=row1')模糊匹配 :
表示模糊匹配,匹配含有指定字符串的文本或属性。
# 获取name属性包含'row1'的元素
ele = page.ele('@name:row1') 匹配开头 ^
表示匹配开头,匹配开头为指定字符串的文本或属性。
# 获取name属性以'row1'开头的元素
ele = page.ele('@name^ro')匹配结尾 $
表示匹配结尾,匹配结尾为指定字符串的文本或属性。
# 获取name属性以'w1'结尾的元素
ele = page.ele('@name$w1')5.2.3 查找语法
id 匹配符 #
表示id属性,只在语句最前面且单独使用时生效,可配合匹配模式使用。
# 在页面中查找id属性为one的元素
ele1 = page.ele('#one')
# 在ele1元素内查找id属性包含ne文本的元素
ele2 = ele1.ele('#:ne')
class 匹配符 .
表示class属性,只在语句最前面且单独使用时生效,可配合匹配模式使用。
# 查找class属性为p_cls的元素
ele2 = ele1.ele('.p_cls')
# 查找class属性'_cls'文本开头的元素
ele2 = ele1.ele('.^_cls')
因为只加 . 时默认是精确匹配元素属性 class,所以如果某元素有多个类名,必须写 class 属性的完整值(类名的顺序也不能变)。如果需要只匹配多个类名中的一个,可以使用模糊匹配符 :。
# 精确查找class属性为`p_cls1 p_cls2 `的元素
ele2 = ele1.ele('.p_cls1 p_cls2 ')
# 模糊查找class属性含有类名 'p_cls2' 的元素
ele2 = ele1.ele('.:p_cls2')
若仍需要更复杂的匹配方式,请使用多属性匹配符。
单属性匹配符 @
表示某个属性,只匹配一个属性。
@关键字只有一个简单功能,就是匹配@后面的内容,不再对后面的字符串进行解析。因此即使后面的字符串也存在@或@@ ,也作为要匹配的内容对待。所以只要是多属性匹配,包括第一个属性在内的所有属性都必须用@@开头。
注意
如果属性中包含特殊字符(如包含@),用这个方式不能正确匹配到,需使用 css selector 方式查找。且特殊字符要用\转义。
# 查找name属性为row1的元素
ele2 = ele1.ele('@name=row1')
# 查找name属性包含row文本的元素
ele2 = ele1.ele('@name:row')
# 查找name属性以row开头的元素
ele2 = ele1.ele('@name^row')
# 查找有name属性的元素
ele2 = ele1.ele('@name')
# 查找没有任何属性的元素
ele2 = ele1.ele('@')
# 查找email属性为abc@def.com的元素,有多个@也不会重复处理
ele2 = ele1.ele('@email=abc@def.com')
# 属性中有特殊字符的情形,匹配abc@def属性等于v的元素
ele2 = ele1.ele('css:div[abc\@def="v"]')
多属性与匹配符 @@
匹配同时符合多个条件的元素时使用,每个条件前面添加@@作为开头。
注意
- 匹配文本或属性中出现
@@、@|、@!时,不能使用多属性匹配,需改用 xpath 的方式。- 如果属性中包含特殊字符(如包含
@),用这个方式不能正确匹配到,需使用 css selector 方式查找。且特殊字符要用\转义。
# 查找name属性为row1且class属性包含cls文本的元素
ele2 = ele1.ele('@@name=row1@@class:cls')
@@可以与下文介绍的tag配合使用:
ele = page.ele('tag:div@@class=p_cls@@name=row1')
多属性或匹配符@|
匹配符合多个条件中任一项的元素时使用,每个条件前面添加@|作为开头。
用法与@@一致,注意事项与@@一致。
注意
@@和@|不能同时出现在语句中。
# 查找id属性为one或id属性为two的元素
ele2 = ele1.ele('@|id=one@|id=two')
@|可以与下文介绍的tag配合使用:
ele = page.ele('tag:div@|class=p_cls@|name=row1')
属性否定匹配符@!
用于否定某个条件,可与@@或@|混用,也可单独使用。
混用时,与还是或关系视@@还是@|而定。
示例:
# 匹配arg1等于abc且arg2不等于def的元素
page.ele('@@arg1=abc@!arg2=def')
# 匹配arg1等于abc或arg2不等于def的div元素
page.ele('t:div@|arg1=abc@!arg2=def')
# 匹配arg1不等于abc
page.ele('@!arg1=abc')
# 匹配没有arg1属性的元素
page.ele('@!arg1')
文本匹配符 text
要匹配的文本,查询字符串如开头没有任何关键字,也表示根据传入的文本作模糊查找。
如果元素内有多个直接的文本节点,精确查找时可匹配所有文本节点拼成的字符串,模糊查找时可匹配每个文本节点。
没有任何匹配符时,默认匹配文本。
# 查找文本为“第二行”的元素
ele2 = ele1.ele('text=第二行')
# 查找文本包含“第二”的元素
ele2 = ele1.ele('text:第二')
# 与上一行一致
ele2 = ele1.ele('第二')
TIPS
若要查找的文本包含
text:,可下面这样写,即第一个text:为关键字,第二个是要查找的内容:
ele2 = page.ele('text:text:')
文本匹配符 text()
作为查找属性时使用的文本关键字,必须与@或@@配合使用。
# 查找文本为“第二行”的元素
ele2 = ele1.ele('@text()=第二行')
# 查找文本包含“第二行”的元素
ele2 = ele1.ele('@text():二行')
# 查找文本以“第二”开头且class属性为p_cls的元素
ele2 = ele1.ele('@@text()^第二@@class=p_cls')
# 查找文本为“二行”且没有任何属性的元素(因第一个 @@ 后为空)
ele2 = ele1.ele('@@@@text():二行')
# 查找直接子文本包含“二行”字符串的元素
ele = page.ele('@text():二行')
@@text()的技巧
值得一提的是,text()配合@@或@|能实现一种很便利的按查找方式。
网页种经常会出现元素和文本混排的情况,比如:
<li class="explore-categories__item">
<a href="/explore/new-tech" class="">
<i class="explore"></i>
前沿技术
</a>
</li>
<li class="explore-categories__item">
<a href="/explore/program-develop" class="">
<i class="explore"></i>
程序开发
</a>
</li>
示例中,如果要用文本获取'前沿技术'的<a>元素,可以这样写:
ele = page.ele('text:前沿技术')
# 或
ele = page.ele('@text():前沿技术')
这两种写法都能获取到包含直接文本的元素。
但如果要用文本获取<li>元素,就获取不到,因为文本不是<li>的直接内容。
我们可以这样写:
ele = page.ele('tag:li@@text():前沿技术')
@@text()与@text()不同之处在于,前者可以搜索整个元素内所有文本,而不仅仅是直接文本,因此能实现一些非常灵活的查找。
注意
需要注意的是,使用
@@或@|时,text()不要作为唯一的查询条件,否则会定位到整个文档最高层的元素。❌ 错误做法:
ele = page.ele('@@text():前沿技术') ele = page.ele('@|text():前沿技术@|text():程序开发')⭕ 正确做法:
ele = page.ele('tag:li@|text():前沿技术@|text():程序开发')
类型匹配符 tag
表示元素的标签,只在语句最前面且单独使用时生效,可与@、@@或@|配合使用。tag:与tag=效果一致,没有tag^和tag$语法。
# 定位div元素
ele2 = ele1.ele('tag:div')
# 定位class属性为p_cls的p元素
ele2 = ele1.ele('tag:p@class=p_cls')
# 定位文本为"第二行"的p元素
ele2 = ele1.ele('tag:p@text()=第二行')
# 定位class属性为p_cls且文本为“第二行”的p元素
ele2 = ele1.ele('tag:p@@class=p_cls@@text()=第二行')
# 定位class属性为p_cls或文本为“第二行”的p元素
ele2 = ele1.ele('tag:p@|class=p_cls@|text()=第二行')
# 查找直接文本节点包含“二行”字符串的p元素
ele2 = ele1.ele('tag:p@text():二行')
# 查找内部文本节点包含“二行”字符串的p元素
ele2 = ele1.ele('tag:p@@text():二行')
注意
tag:div@text():text和tag:div@@text():text是有区别的,前者只在div的直接文本节点搜索,后者搜索div的整个内部。
css selector 匹配符 css
表示用 css selector 方式查找元素。css:与css=效果一致,没有css^和css$语法。
# 查找 div 元素
ele2 = ele1.ele('css:.div')
# 查找 div 子元素元素,这个写法是本库特有,原生不支持
ele2 = ele1.ele('css:>div')
xpath 匹配符 xpath
表示用 xpath 方式查找元素。xpath:与xpath=效果一致,没有xpath^和xpath$语法。
另外,元素对象的ele()支持完整的 xpath 语法,如能使用 xpath 直接获取元素属性(字符串类型)。
# 查找后代中第一个 div 元素
ele2 = ele1.ele('xpath:.//div')
# 和上面一行一样,查找元素的后代时,// 前面的 . 可以省略
ele2 = ele1.ele('xpath://div')
# 使用xpath获取div元素的class属性(页面元素无此功能)
ele_class_str = ele1.ele('xpath://div/@class')
TIPS
查找元素的后代时,selenium 原生代码要求 xpath 前面必须加
.,否则会变成在全个页面中查找。 作者觉得这个设计是画蛇添足,既然已经通过元素查找了,自然应该只查找这个元素内部的元素。 所以,用 xpath 在元素下查找时,最前面//或/前面的.可以省略。
selenium 的 loc 元组 📌
查找方法能直接接收 selenium 原生定位元组进行查找,便于项目迁移。
from DrissionPage.common import By
# 查找id为one的元素
loc1 = (By.ID, 'one')
ele = page.ele(loc1)
# 按 xpath 查找
loc2 = (By.XPATH, '//p[@class="p_cls"]')
ele = page.ele(loc2)
5.2.4 相对定位
以下方法可以以某元素为基准,在 DOM 中按照条件获取其直接子节点、同级节点、祖先元素、文档前后节点。
TIPS
这里说的是“节点”,不是“元素”。因为相对定位可以获取除元素外的其它节点,包括文本、注释节点。
注意
如果元素在
<iframe>中,相对定位不能超越<iframe>文档。
获取父级元素
🔸 parent()
此方法获取当前元素某一级父元素,可指定筛选条件或层数。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
level_or_loc | intstrTuple[str, str] | 1 | 第几级父元素,从1开始,或用定位符在祖先元素中进行筛选 |
index | int | 1 | 当level_or_loc传入定位符,使用此参数选择第几个结果,从当前元素往上级数;当level_or_loc传入数字时,此参数无效 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
NoneElement | 未获取到结果时返回NoneElement |
示例:
# 获取 ele1 的第二层父元素
ele2 = ele1.parent(2)
# 获取 ele1 父元素中 id 为 id1 的元素
ele2 = ele1.parent('#id1')
获取直接子节点
🔸 child()
此方法返回当前元素的一个直接子节点,可指定筛选条件和第几个。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str]int | '' | 用于筛选节点的查询语法,为int类型时index参数无效 |
index | int | 1 | 查询结果中的第几个,从1开始,可输入负数表示倒数 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
str | 获取非元素节点时返回字符串 |
NoneElement | 未获取到结果时返回NoneElement |
🔸 children()
此方法返回当前元素全部符合条件的直接子节点组成的列表,可用查询语法筛选。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | '' | 用于筛选节点的查询语法 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement, str] | 结果列表 |
获取后面的同级节点
🔸 next()
此方法返回当前元素后面的某一个同级节点,可指定筛选条件和第几个。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str]int | '' | 用于筛选节点的查询语法,为int类型时index参数无效 |
index | int | 1 | 查询结果中的第几个,从1开始,可输入负数表示倒数 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
str | 获取非元素节点时返回字符串 |
NoneElement | 未获取到结果时返回NoneElement |
示例:
# 获取 ele1 后面第一个兄弟元素
ele2 = ele1.next()
# 获取 ele1 后面第 3 个兄弟元素
ele2 = ele1.next(3)
# 获取 ele1 后面第 3 个 div 兄弟元素
ele2 = ele1.next('tag:div', 3)
# 获取 ele1 后面第一个文本节点的文本
txt = ele1.next('xpath:text()', 1)
🔸 nexts()
此方法返回当前元素后面全部符合条件的同级节点组成的列表,可用查询语法筛选。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | '' | 用于筛选节点的查询语法 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement, str] | 结果列表 |
示例:
# 获取 ele1 后面所有兄弟元素
eles = ele1.nexts()
# 获取 ele1 后面所有 div 兄弟元素
divs = ele1.nexts('tag:div')
# 获取 ele1 后面的所有文本节点
txts = ele1.nexts('xpath:text()')
获取前面的同级节点
🔸 prev()
此方法返回当前元素前面的某一个同级节点,可指定筛选条件和第几个。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str]int | '' | 用于筛选节点的查询语法,为int类型时index参数无效 |
index | int | 1 | 查询结果中的第几个,从1开始,可输入负数表示倒数 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
str | 获取非元素节点时返回字符串 |
NoneElement | 未获取到结果时返回NoneElement |
示例:
# 获取 ele1 前面第一个兄弟元素
ele2 = ele1.prev()
# 获取 ele1 前面第 3 个兄弟元素
ele2 = ele1.prev(3)
# 获取 ele1 前面第 3 个 div 兄弟元素
ele2 = ele1.prev(3, 'tag:div')
# 获取 ele1 前面第一个文本节点的文本
txt = ele1.prev(1, 'xpath:text()')
🔸 prevs()
此方法返回当前元素前面全部符合条件的同级节点组成的列表,可用查询语法筛选。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | '' | 用于筛选节点的查询语法 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement, str] | 结果列表 |
示例:
# 获取 ele1 前面所有兄弟元素
eles = ele1.prevs()
# 获取 ele1 前面所有 div 兄弟元素
divs = ele1.prevs('tag:div')
在后面文档中查找节点
🔸 after()
此方法返回当前元素后面的某一个节点,可指定筛选条件和第几个。查找范围不限同级节点,而是整个 DOM 文档。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str]int | '' | 用于筛选节点的查询语法,为int类型时index参数无效 |
index | int | 1 | 查询结果中的第几个,从1开始,可输入负数表示倒数 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
str | 获取非元素节点时返回字符串 |
NoneElement | 未获取到结果时返回NoneElement |
示例:
# 获取 ele1 后面第 3 个元素
ele2 = ele1.after(index=3)
# 获取 ele1 后面第 3 个 div 元素
ele2 = ele1.after('tag:div', 3)
# 获取 ele1 后面第一个文本节点的文本
txt = ele1.after('xpath:text()', 1)
🔸 afters()
此方法返回当前元素后面符合条件的全部节点组成的列表,可用查询语法筛选。查找范围不限同级节点,而是整个 DOM 文档。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | '' | 用于筛选节点的查询语法 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement, str] | 结果列表 |
示例:
# 获取 ele1 后所有元素
eles = ele1.afters()
# 获取 ele1 前面所有 div 元素
divs = ele1.afters('tag:div')
在前面文档中查找节点
🔸 before()
此方法返回当前元素前面的某一个符合条件的节点,可指定筛选条件和第几个。查找范围不限同级节点,而是整个 DOM 文档。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str]int | '' | 用于筛选节点的查询语法,为int类型时index参数无效 |
index | int | 1 | 查询结果中的第几个,从1开始,可输入负数表示倒数 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 找到的元素对象 |
str | 获取非元素节点时返回字符串 |
NoneElement | 未获取到结果时返回NoneElement |
示例:
# 获取 ele1 前面第 3 个元素
ele2 = ele1.before(3)
# 获取 ele1 前面第 3 个 div 元素
ele2 = ele1.before('tag:div', 3)
# 获取 ele1 前面第一个文本节点的文本
txt = ele1.before('xpath:text()', 1)
🔸 befores()
此方法返回当前元素前面全部符合条件的节点组成的列表,可用查询语法筛选。查找范围不限同级节点,而是整个 DOM 文档。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | '' | 用于筛选节点的查询语法 |
timeout | float | None | 无实际作用 |
ele_only | bool | True | 是否只查找元素,为False时把文本、注释节点也纳入查找范围 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement, str] | 结果列表 |
示例:
# 获取 ele1 前面所有元素
eles = ele1.befores()
# 获取 ele1 前面所有 div 元素
divs = ele1.befores('tag:div')5.3 更多用法
5.3.1 静态方式查找元素
静态元素即 s 模式的SessionElement元素对象,是纯文本构造的,因此用它处理速度非常快。
对于复杂的页面,要在成百上千个元素中采集数据时,转换为静态元素可把速度提升几个数量级。
作者曾在实践的时候,用同一套逻辑,仅仅把元素转换为静态,就把一个要 30 秒才完成的页面,加速到零点几秒完成。
我们甚至可以把整个页面转换为静态元素,再在其中提取信息。
当然,这种元素不能进行点击等交互。
用s_ele()可在把查找到的动态元素转换为静态元素输出,或者获取元素或页面本身的静态元素副本。
s_ele()
页面对象和元素对象都拥有此方法,用于查找第一个匹配条件的元素,获取其静态版本。
页面对象和元素对象的s_ele()方法参数名称稍有不同,但用法一样。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator(元素对象) | strTuple[str, str] | 必填 | 元素的定位信息,可以是查询字符串,或 loc 元组 |
locator(页面对象) | strChromiumElementTuple[str, str] | 必填 | 元素的定位信息,可以是查询字符串、loc 元组或一个ChromiumElement对象 |
index | int | 1 | 获取第几个匹配的元素,从1开始,可输入负数表示从后面开始数 |
| 返回类型 | 说明 |
|---|---|
SessionElement | 返回查找到的第一个符合条件的元素对象的静态版本 |
NoneElement | 限时内未找到符合条件的元素时返回NoneElement对象 |
注意
页面对象和元素对象的
s_ele()方法不能搜索到在<iframe>里的元素,页面对象的静态版本也不能搜索<iframe>里的元素。 要使用<iframe>里元素的静态版本,可先获取该元素,再转换。而使用ChromiumFrame对象,则可以直接用s_ele()查找元素,这在后面章节再讲述。
TIPS
从一个
ChromiumElement元素获取到的SessionElement版本,依然能够使用相对定位方法定位祖先或兄弟元素。
from DrissionPage import ChromiumPage
page = ChromiumPage()
# 在页面中查找元素,获取其静态版本
ele1 = page.s_ele('search text')
# 在动态元素中查找元素,获取其静态版本
ele = page.ele('search text')
ele2 = ele.s_ele()
# 获取页面元素的静态副本(不传入参数)
s_page = page.s_ele()
# 获取动态元素的静态副本
s_ele = ele.s_ele()
# 在静态副本中查询下级元素(因为已经是静态元素,用ele()查找结果也是静态)
ele3 = s_page.ele('search text')
ele4 = s_ele.ele('search text')
s_eles()
此方法与s_ele()相似,但返回的是匹配到的所有元素组成的列表,或属性值组成的列表。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
locator | strTuple[str, str] | 必填 | 元素的定位信息,可以是查询字符串,或 loc 元组 |
| 返回类型 | 说明 |
|---|---|
List[SessionElement] | 返回找到的所有元素的SessionElement版本组成的列表 |
示例:
from DrissionPage import WebPage
page = WebPage()
for ele in page.s_eles('search text'):
print(ele.text)
5.3.2 获取当前焦点元素
使用active_ele属性获取页面上焦点所在元素。
ele = page.active_ele
5.3.3 iframe元素
查找 iframe 元素
<iframe>和<frame>也可以用ele()查找到,生成的对象是ChromiumFrame而不是ChromiumElement。
但不建议用ele()获取<iframe>元素,因为 IDE 无法正确提示后续操作。
建议用 Page 对象的get_frame()方法获取。
使用方法与ele()一致,可以用定位符查找。还增加了用序号、id、name 属性定位元素的功能。
示例:
iframe = page.get_frame(1) # 获取页面中第一个iframe元素
iframe = page.get_frame('#theFrame') # 获取页面id为theFrame的iframe元素对象
在页面下跨级查找
与 selenium 不同,本库可以直接查找同域<iframe>里面的元素。
而且无视层级,可以直接获取到多层<iframe>里的元素。无需切入切出,大大简化了程序逻辑,使用更便捷。
假设在页面中有个两级<iframe>,其中有个元素<div id='abc'></div>,可以这样获取:
page = ChromiumPage()
ele = page('#abc')
获取前后无需切入切出,也不影响获取页面上其它元素。
如果用 selenium,要这样写:
driver = webdriver.Chrome()
driver.switch_to.frame(0)
driver.switch_to.frame(0)
ele = driver.find_element(By.ID, 'abc')
driver.switch_to.default_content()
显然比较繁琐,而且切入到<iframe>后无法对<iframe>外的元素进行操作。
注意
- 跨级查找只是页面对象支持,元素对象不能直接查找内部 iframe 里的元素。
- 跨级查找只能用于与主框架同域名的
<iframe>,不同域名的请用下面的方法。
在 iframe 元素下查找
本库把<iframe>看作一个特殊元素/页面对象看待,可以实现同时操作多个<iframe>,而无需来回切换。
对于跨域名的<iframe>,我们无法通过页面直接查找里面的元素,可以先获取到<iframe>元素,再在其下查找。当然,非跨域<iframe> 也可以这样操作。
假设一个<iframe>的 id 为 'iframe1',要在其中查找一个 id 为'abc'的元素:
page = ChromiumPage()
iframe = page('#iframe1')
ele = iframe('#abc')
这个<iframe>元素是一个页面对象,因此可以继续在其下进行跨<iframe>查找(相对这个<iframe>不跨域的)。
5.3.4 ShadowRoot
本库把 shadow-root 也作为元素对象看待,是为ShadowRoot对象。 该对象可与普通元素一样查找下级元素和 DOM 内相对定位。
对ShadowRoot对象进行相对定位时,把它看作其父对象内部的第一个对象,其余定位逻辑与普通对象一致。
用元素对象的shadow_root属性可获取ShadowRoot对象。
注意
- 如果
ShadowRoot元素的下级元素中有其它ShadowRoot元素,那这些下级ShadowRoot- 元素内部是无法直接通过定位语句查找到的,只能先定位到其父元素,再用
shadow-root属性获取。
# 获取一个 shadow-root 元素
sr_ele = page.ele('#app').shadow_root
# 在该元素下查找下级元素
ele1 = sr_ele.ele('tag:div')
# 用相对定位获取其它元素
ele1 = sr_ele.parent(2)
ele1 = sr_ele.next('tag:div', 1)
ele1 = sr_ele.after('tag:div', 1)
eles = sr_ele.nexts('tag:div')
# 定位下级元素中的 shadow+-root 元素
sr_ele2 = sr_ele.ele('tag:div').shadow_root
由于 shadow-root 不能跨级查找,链式操作非常常见,所以设计了一个简写:sr,功能和shadow_root一样,都是获取元素内部的ShadowRoot。
多级 shadow-root 链式操作示例:
以下这段代码,可以打印浏览器历史第一页,可见是通过多级 shadow-root 来获取的。
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('chrome://history/')
items = page('#history-app').sr('#history').sr.eles('t:history-item')
for i in items:
print(i.sr('#item-container').text.replace('\n', ''))
5.3.5 等待
由于网络、js 运行时间的不确定性等因素,经常需要等待元素加载到 DOM 中才能使用。
浏览器所有查找元素操作都自带等待,时间默认跟随元素所在页面timeout属性(默认 10 秒),也可以在每次查找时单独设置,单独设置的等待时间不会改变页面原来设置。
from DrissionPage import ChromiumPage
# 页面初始化时设置查找元素超时时间为 15 秒
page = ChromiumPage(timeout=15)
# 设置查找元素超时时间为 5 秒
page.set.timeouts(5)
# 使用页面超时时间来查找元素(5 秒)
ele1 = page.ele('search text')
# 为这次查找页面独立设置等待时间(1 秒)
ele1 = page.ele('search text', timeout=1)
# 查找后代元素,使用页面超时时间(5 秒)
ele2 = ele1.ele('search text')
# 查找后代元素,使用单独设置的超时时间(1 秒)
ele2 = ele1.ele('some text', timeout=1) 5.4 简化写法
为进一步精简代码,定位语法都可以用简化形式来表示,使语句更短,链式操作时更清晰。
5.4.1 定位符语法简化
- 定位语法都有其简化形式
- 页面和元素对象都实现了
__call__()方法,所以page.ele('...')可简化为page('...') - 查找方法都支持链式操作
示例:
# 查找tag为div的元素
ele = page.ele('tag:div') # 原写法
ele = page('t:div') # 简化写法
# 用xpath查找元素
ele = page.ele('xpath://xxxxx') # 原写法
ele = page('x://xxxxx') # 简化写法
# 查找text为'something'的元素
ele = page.ele('text=something') # 原写法
ele = page('tx=something') # 简化写法
简化写法对应列表
| 原写法 | 简化写法 | 说明 |
|---|---|---|
@id | # | 表示 id 属性,简化写法只在语句最前面且单独使用时生效 |
@class | . | 表示 class 属性,简化写法只在语句最前面且单独使用时生效 |
text | tx | 按文本匹配 |
@text() | @tx() | 按文本查找与 @ 或 @@ 配合使用时 |
tag | t | 按标签类型匹配 |
xpath | x | 用 xpath 方式查找元素 |
css | c | 用 css selector 方式查找元素 |
5.4.2 shadow root 简化
一般获取元素的 shadow root 元素,用ele.shadow_root属性。
由于此属性经常用于大量链式操作,名字太长影响可读性,因此可简化为ele.sr
示例:
txt = ele.sr('t:div').text
5.4.3 相对定位参数简化
相对定位时,有时需要获取当前元素后某个元素,而不关心该元素是什么类型,一般是这样写:ele.next(index=2)。
但有一种简化的写法,可以直接写作ele.next(2)。
当第一个参数filter_loc接收数字时,会自动将其视作序号,替代index参数。因此书写可以稍微精简一些。
示例:
ele2 = ele1.parent(2)
ele2 = ele1.next(2)('tx=xxxxx')
ele2 = ele1.before(2)
# 如此类推5.5 找不到元素时
5.5.1 默认情况
默认情况下,找不到元素时不会立即抛出异常,而是返回一个NoneElement对象。
这个对象用if判断表现为False,调用其功能会抛出ElementNotFoundError异常。
这样可以用if判断是否找到元素,也可以用try去捕获异常。
查找多个元素找不到时,返回空的list。
示例,用if判断:
ele = page.ele('xxxxxxx')
# 判断是否找到元素
if ele:
print('找到了。')
if not ele:
print('没有找到。')
示例,用try捕获:
try:
ele.click()
except ElementNotFoundError:
print('没有找到。')
5.5.2 立即抛出异常
如果想在找不到元素时立刻抛出异常,可以用以下方法设置。
此设置为全局有效,在项目开始时设置一次即可。
查找多个元素找不到时,依然返回空的list。
设置全局变量:
from DrissionPage.common import Settings
Settings.raise_when_ele_not_found = True
示例:
from DrissionPage import ChromiumPage
from DrissionPage.common import Settings
Settings.raise_when_ele_not_found = True
page = ChromiumPage(timeout=1)
page.get('https://www.baidu.com')
ele = page('#abcd') # ('#abcd')这个元素不存在
输出:
DrissionPage.errors.ElementNotFoundError:
没有找到元素。
method: ele()
args: {'locator': '#abcd'}
5.5.3 设置默认返回值
如果查找元素后要获取一个属性,但这个元素不一定存在,或者链式查找其中一个节点找不到,可以设置查找失败时返回的值,而不是抛出异常,可以简化一些采集逻辑。
使用浏览器页面对象的set.NoneElement_value()方法设置该值。
| 参数名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
value | Any | None | 将返回的设定值 |
on_off | bool | True | bool表示是否启用 |
返回:None
示例
比如说,遍历页面上一个列表中多个对象,但其中有些元素可能缺失某个子元素,可以这样写:
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.set.NoneElement_value('没找到')
for li in page.eles('t:li'):
name = li('.name').text
age = li('.age').text
phone = li('.phone').text
这样,假如某个子元素不存在,不会抛出异常,而是返回'没找到'这个字符串。
5.6 语法速查表
5.6.1 定位语法
基本用法
以下语法只出现在语句开头。
| 写法 | 精确匹配 | 模糊匹配 | 匹配开头 | 匹配结尾 | 说明 |
|---|---|---|---|---|---|
@属性名 | @属性名= | @属性名: | @属性名^ | @属性名$ | 按某个属性查找 |
@!属性名 | @!属性名= | @!属性名: | @!属性名^ | @!属性名$ | 查找属性不符合指定条件的元素 |
text | text= | text:或不写 | text^ | text$ | 按某个文本查找 |
@text() | @text()= | @text(): | text()^ | text()$ | text与@或@@配合使用时改为text(),常用于多条件匹配 |
tag | tag=或tag: | 无 | 无 | 无 | 查找某个类型的元素 |
xpath | xpath=或xpath: | 无 | 无 | 无 | 用 xpath 方式查找元素 |
css | css=或css: | 无 | 无 | 无 | 用 css selector 方式查找元素 |
组合用法
| 写法 | 说明 |
|---|---|
@@属性1@@属性2 | 匹配属性同时符合多个条件的元素 |
@@属性1@!属性2 | 多属性匹配与否定匹配同时使用 |
| `@ | 属性1@ |
tag:xx@属性名 | tag与属性匹配共同使用 |
tag:xx@@属性1@@属性2 | tag与多属性匹配共同使用 |
| `tag:xx@ | 属性1@ |
tab:@@text()=文本@@属性 | tab与文本和属性匹配共同使用 |
简化写法
| 原写法 | 简化写法 | 精确匹配 | 模糊匹配 | 匹配开头 | 匹配结尾 | 备注 |
|---|---|---|---|---|---|---|
@id | # | #或#= | #: | #^ | #$ | 简化写法只能单独使用 |
@class | . | .或.= | .: | .^ | .$ | 简化写法只能单独使用 |
tag | t | t:或t= | 无 | 无 | 无 | 只能用在句首 |
text | tx | tx= | tx:或不写 | tx^ | tx$ | 无标签时使用模糊匹配文本 |
@text() | @tx() | @tx()= | @tx(): | @tx()^ | @tx()$ | |
xpath | x | x:或x= | 无 | 无 | 无 | 只能单独使用 |
css | c | c:或c= | 无 | 无 | 无 | 只能单独使用 |
5.6.2 相对定位
| 方法 | 说明 |
|---|---|
parent() | 查找当前元素某一级父元素 |
child() | 查找当前元素的一个直接子节点 |
children() | 查找当前元素全部符合条件的直接子节点 |
next() | 查找当前元素之后第一个符合条件的兄弟节点 |
nexts() | 查找当前元素之后所有符合条件的兄弟节点 |
prev() | 查找当前元素之前第一个符合条件的兄弟节点 |
prevs() | 查找当前元素之前所有符合条件的兄弟节点 |
after() | 查找文档中当前元素之后第一个符合条件的节点 |
afters() | 查找文档中当前元素之后所有符合条件的节点 |
before() | 查找文档中当前元素之前第一个符合条件的节点 |
befores() | 查找文档中当前元素之前所有符合条件的节点 |
5.6.3 其它
| 方法 | 简化写法 | 说明 | 备注 |
|---|---|---|---|
get_frame() | 无 | 在页面中查找一个<iframe>元素 | 只有页面对象有此方法 |
shadow_root | sr | 获取当前元素内的 shadow root 对象 | 只有元素对象有此属性 |

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 93
93 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)