
滴滴 Flink 指标系统的架构设计与实践
毫不夸张地说,Flink 指标是洞察 Flink 任务健康状况的关键工具,它们如同 Flink 任务的眼睛一般至关重要。简而言之,这些指标可以被理解为滴滴数据开发平台实时运维系统的数据图谱。在实时计算领域,Flink 指标扮演着举足轻重的角色,例如,实时任务的消费延迟和检查点失败的警报都是基于对 Flink 报告的指标进行监控而触发的;同时,许多实时任务智能诊断的关键决策点也是依 Flink 指标
毫不夸张地说,Flink 指标是洞察 Flink 任务健康状况的关键工具,它们如同 Flink 任务的眼睛一般至关重要。简而言之,这些指标可以被理解为滴滴数据开发平台实时运维系统的数据图谱。在实时计算领域,Flink 指标扮演着举足轻重的角色,例如,实时任务的消费延迟和检查点失败的警报都是基于对 Flink 报告的指标进行监控而触发的;同时,许多实时任务智能诊断的关键决策点也是依 Flink 指标来制定的。
鉴于 Flink 指标系统的重要性,深入理解其工作原理显得尤为必要,这是灵活运用 Flink 指标系统的前提。作为一名平台工程师,我尝试对 Flink 的原理进行一次剖析,如果存在任何不准确之处,敬请各位指正。
Flink 指标系统的核心概念
接下来我们将探讨一些核心概念,它们是理解 Flink 指标系统不可或缺的基础。
Metric Reporters
Metric Reporter 是 Flink 用于导出指标数据的接口,通过 flink-conf.yaml 文件可以轻松配置所需的 MetricReporter。Flink 提供了多种 MetricReporter 的实现,包括 Prometheus、Datadog 等,以满足不同的监控需求。
值得注意的是,尽管 Flink 提供了众多 MetricReporter 的实现,但它如何根据需要动态加载这些实现呢?我们将在后文关于弹性设计的讨论中深入分析这一机制,现在先留个悬念。
MetricReporter 支持两种指标上报方式:Push 和 Pull。具体不赘述了,我们直接引用官方文档中的描述:
Metrics are exported either via pushes or pulls.
Push-based reporters usually implement the Scheduled interface and periodically send a summary of current metrics to an external system.
Pull-based reporters are queried from an external system instead.
滴滴内部的Metric Reporters
滴滴内部没有采用社区的MetricReporter,而是根据滴滴内部实际情况,自研了flink-metrics-kafka。简单来讲,采用push的方式,
滴滴并未使用社区提供的 MetricReporter,而是根据自身需求自主研发了 flink-metrics-kafka。简单来说,该系统采用推送 Push 方式,周期性将 Flink 计算的指标推送到 kafka topic 当中。下文中的实现原理,也是基于 flink-metrics-kafka 介绍的。
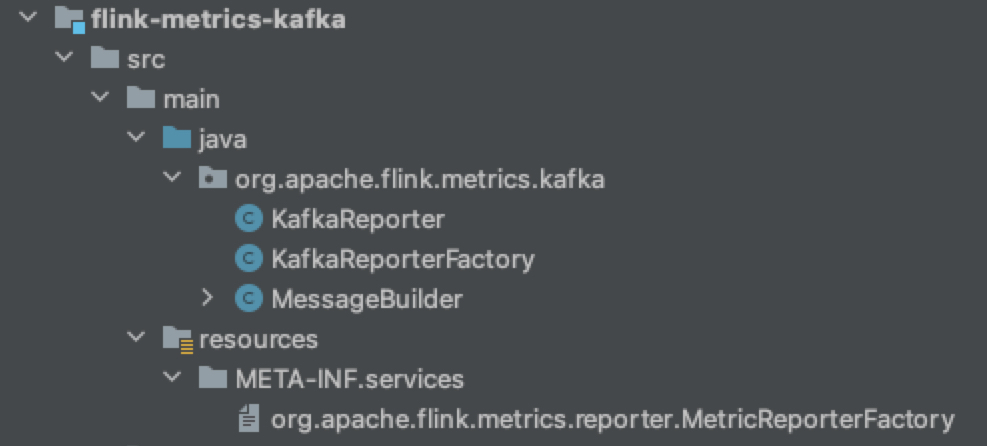
Metrics type
Flink 社区对指标进行了高度抽象,定义了四种主要的指标类型:Counter、Gauge、Histogram 和 Meter。
Counter:这是一种简单的计数器,用于记录事件的数量。
Gauge:这种指标非常灵活,可以返回任意类型的统计数据。Gauge 可以看作是 Counter 的泛化版本。
Histogram:正如其名,Histogram 表示的是一系列长整型数值的分布情况,常用于绘制直方图。
Meter:这种指标用于度量平均吞吐量,适用于评估系统的处理能力。
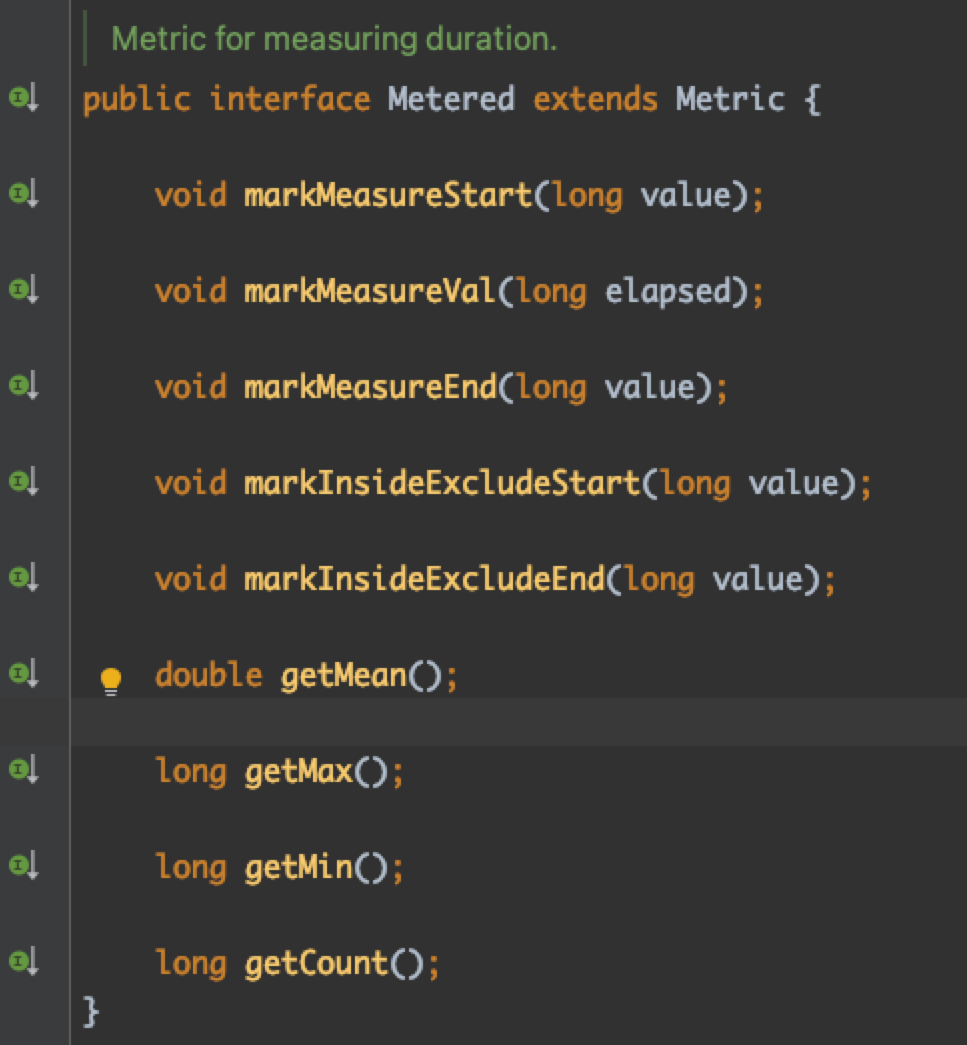
滴滴内部的 Metered
在滴滴内部,我们独创了一种名为 Metered 的指标类型(请注意与 Meter 区分),专门用于衡量一段时间内的指标数值。这包括了时间段内的平均值、最大值、最小值以及计数等。实际上,我们内部使用的许多指标都是基于 Metered 进行计算的。
View
另一个关键概念是 View,它通常与 Metric 结合使用。让我们先来了解一下 View 的定义:
An interface for metrics which should be updated in regular intervals by a background thread.
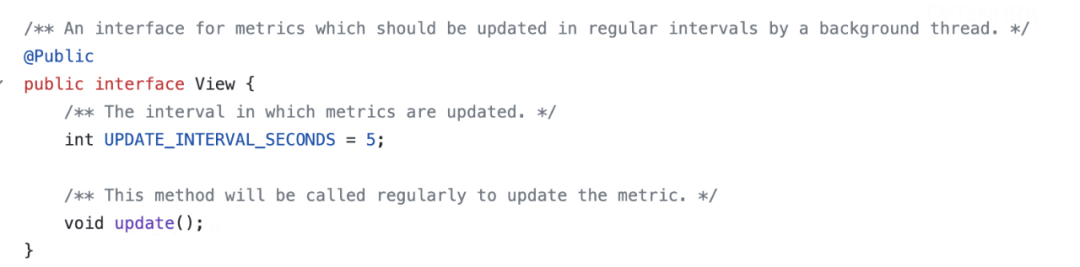
换句话说,View 为 Metric 提供了一种定时刷新的能力。
Scope
Scope 可以简单地理解为命名空间,它允许在指标名称前添加一系列前缀。我个人认为 Scope 的主要作用是为了区分不同来源或类型的指标,以便于管理和识别。
系统指标
Flink 社区提供了丰富的开箱即用的指标,主要集中在系统性能方面,比如CPU、内存等。这部分内容不是本文重点,下文我们会重点讲解一个滴滴内部非常重要的指标:消费延迟。
Flink 指标系统的弹性设计
作为一款成功的分布式实时计算引擎,Flink 在指标系统设计上展现出了其独特之处。它不仅对指标上报进行了标准化定义和设计,还充分考虑了指标上报实现的多样性和可扩展性问题,因此我将之称为指标系统的弹性设计。下面,我们将详细分析 Flink 是如何实现这一设计的。
首先,我们来看看 Flink 对 MetricReporter 接口的定义。这个接口的定义非常简洁,其中包含三个关键信息:
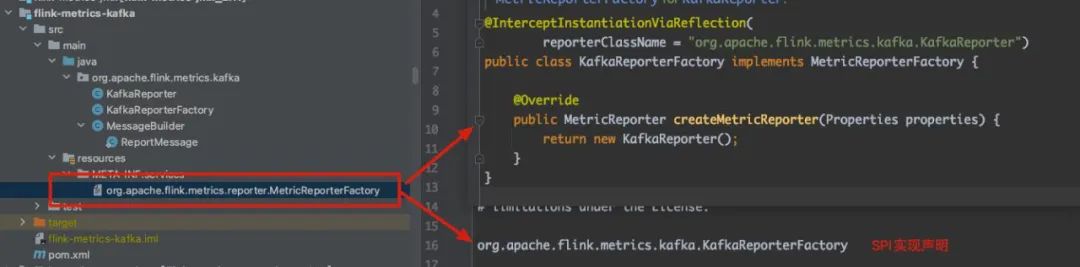
1、open 和 close 方法分别在 MetricReporter 初始化和关闭时被调用。以滴滴内部的 KafkaReporter 实现为例,其主要功能是 Kafka 客户端的初始化和关闭操作。
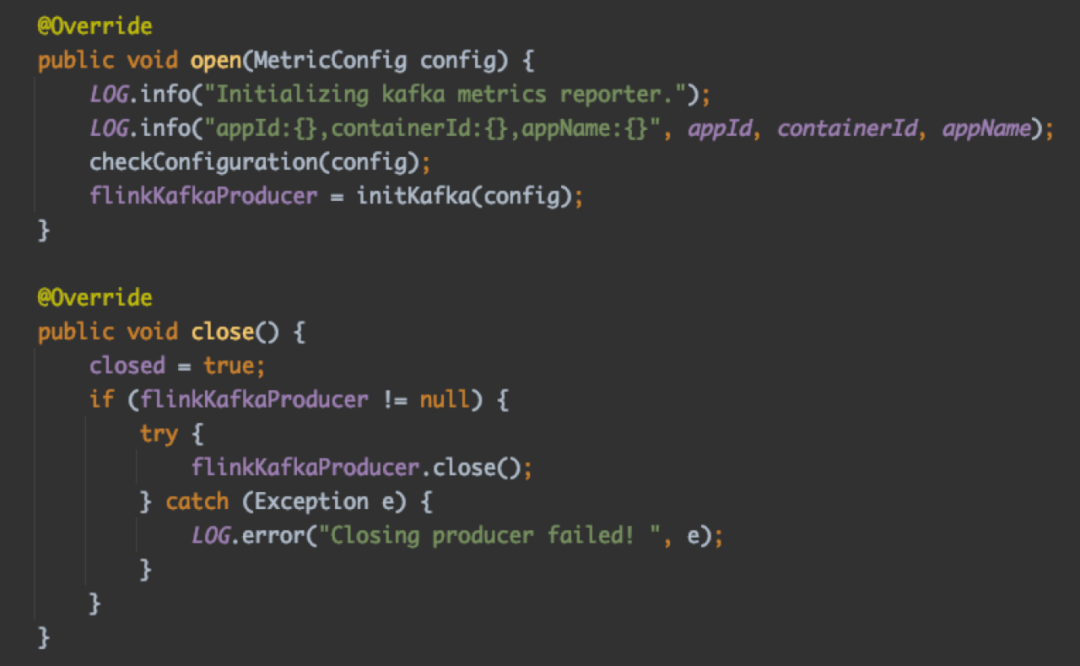
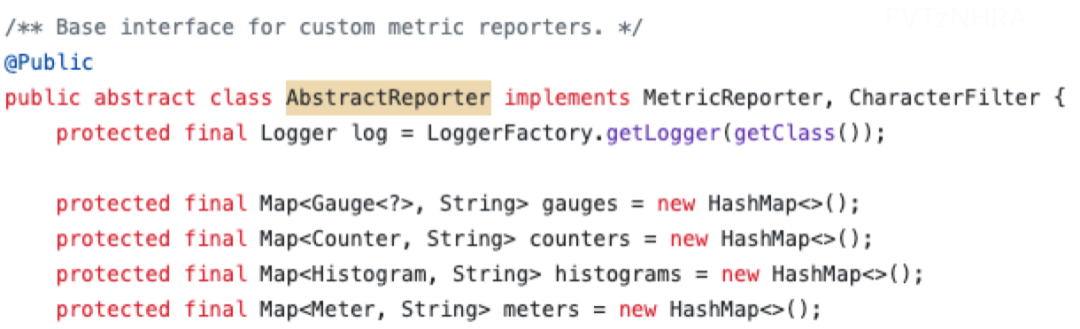
2、notifyOfAddedMetric 和 notifyOfRemovedMetric 方法的主要作用是在 MetricGroup 添加或删除指标时,通知 MetricReporter,使其能够感知需要发送哪些指标。Flink 对 MetricReporter 进行了基础实现 AbstractReporter,我们可以看到在调用 notifyOfAddedMetric/notifyOfRemovedMetric 方法时,主要是在内存中维护了对指标的引用。
3、Flink 框架是如何加载并初始化 MetricReporter 的呢?源码中的注释给了我们提示:
>Reporters are instantiated via a {@link MetricReporterFactory}.
这意味着,MetricReporter 是通过 MetricReporterFactory 创建的(当然,在实际实现中,如果用户没有定义 MetricReporterFactory 的实现,也可以通过反射的方式初始化 MetricReporter)。
MetricReporterFactory 的定义是典型的工厂模式,注释中也包含了丰富的信息。简单来说,MetricReporterFactory 的实现类是通过 Java SPI 机制加载和实例化的。这里实际上是 Flink 指标系统实现弹性设计的关键所在。

也就是说,Flink 框架能够通过 Java SPI 机制按需加载 MetricReporterFactory 的实现类,再通过 MetricReporterFactory 实例化各种 MetricReporter。
MetricReporter 是 Flink 对指标系统的规范,MetricReporterFactory 的 SPI 加载机制为框架提供了灵活性。用户可以直接使用社区已经实现的指标系统,也可以自定义指标系统(比如,滴滴的 KafkaReporter)。本质上来说,这是一种遵循开闭原则的设计思想。
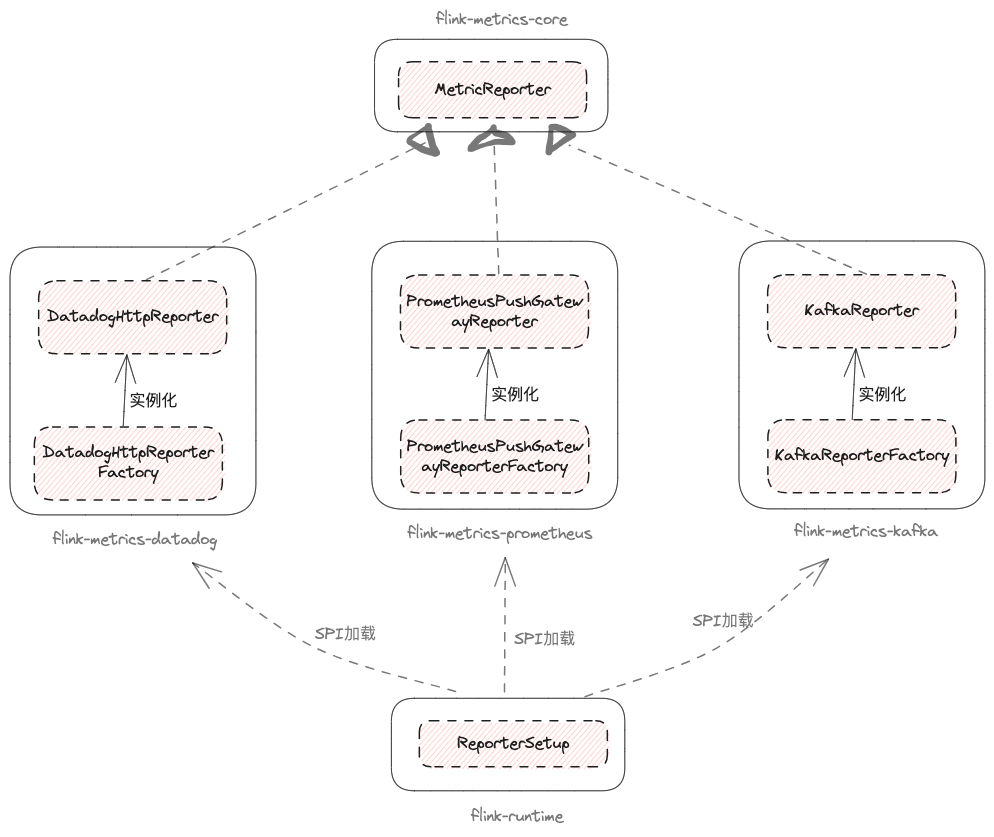
类似地,如果业务系统中有明确的业务逻辑,平台可以进行沉淀,同时将不同类型的需求通过 SPI 接口暴露出来,由业务方自行实现和维护,平台则按需加载业务方实现的 Jar 包即可,这就是插件思想的体现。
下面,我们将在源码层面详细分析弹性设计背后的实现细节:
当 Flink 启动 TaskManager 时,会触发 ReporterSetup 的初始化,其中的秘密都隐藏在这个类里。

让我们来详细分析一下 ReporterSetup 的 fromConfiguration 方法。简而言之,这个方法的核心步骤有两个:
第一步是通过 SPI 方式加载 MetricReporterFactory。
第二步是实例化 MetricReporter。
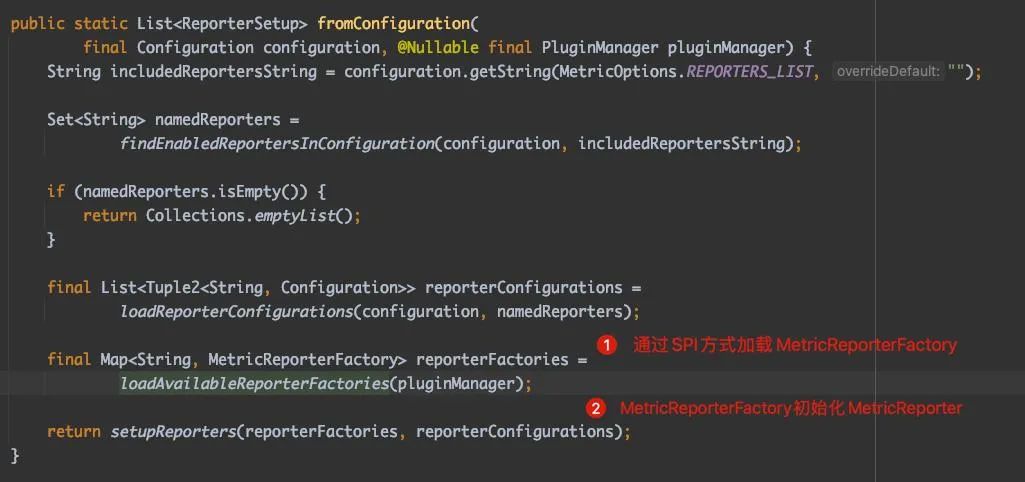
接下来,我们来分析通过 SPI 方式加载 MetricReporterFactory 的过程。ServiceLoader.load 是关键所在,我们可以看到它并没有传入 ClassLoader,也就是说它默认使用了 AppClassLoader(Flink 还支持 PluginManager 加载 MetricReporterFactory,本文不展开讨论,但其本质也是通过自定义类加载器加载不同指标系统实现的 jar 包)。
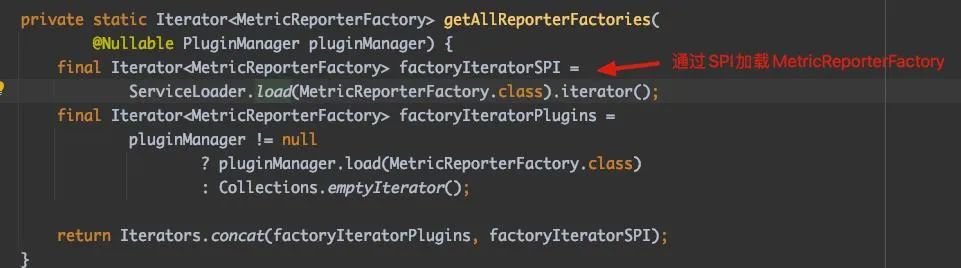
然后,我们再来分析一下 MetricReporter 的实例化过程。
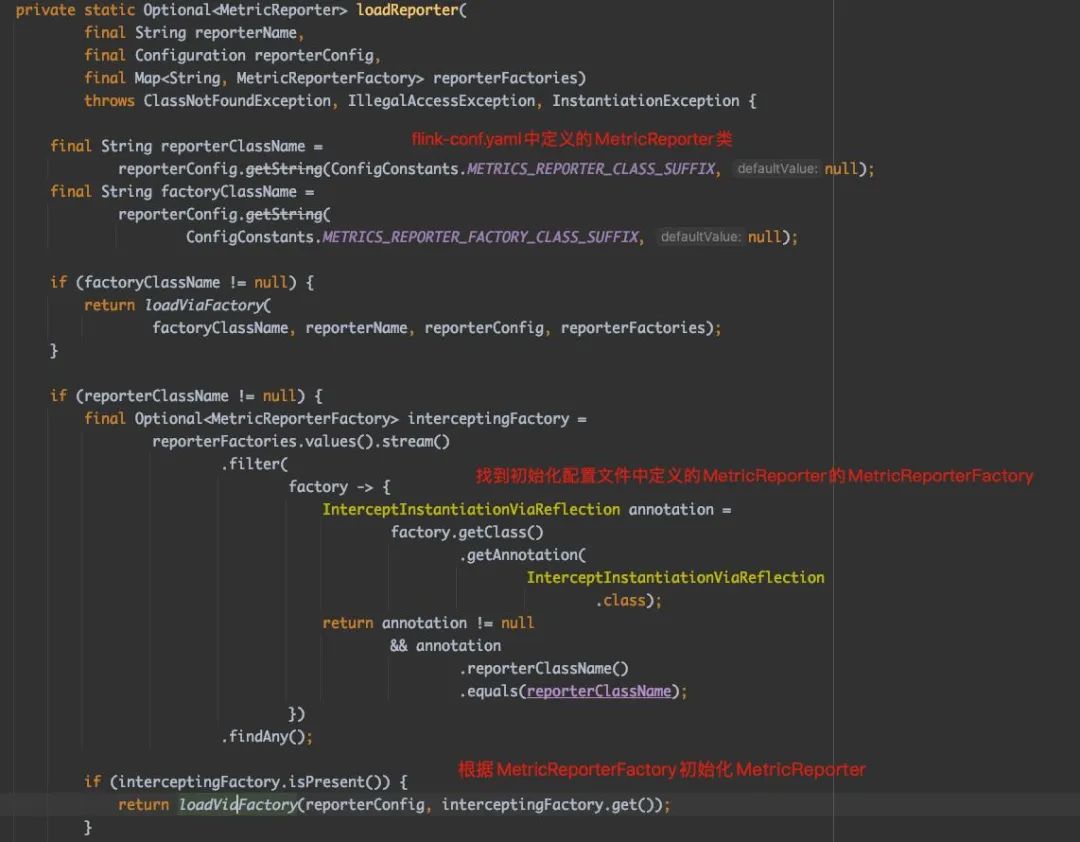
最后,让我们来看一个真实的 MetricReporterFactory 实现类,以便对整个过程有更具体的了解。
Flink 指标注册和周期上报
接下来,我们将详细分析 Flink 指标注册与周期上报指标的实现原理。
指标注册
注册 Flink 指标的过程非常简单,可以直接参考官网的介绍。

Flink 通过 MetricGroup 接口注册指标,这一功能的实现最终委托给了抽象类 AbstractMetricGroup 的 addMetric 方法。AbstractMetricGroup 将指标最终注册到了 MetricRegistry。MetricRegistry 是 MetricReporter 和指标之间的桥梁,负责跟踪所有已注册的指标。整体流程如下图所示:
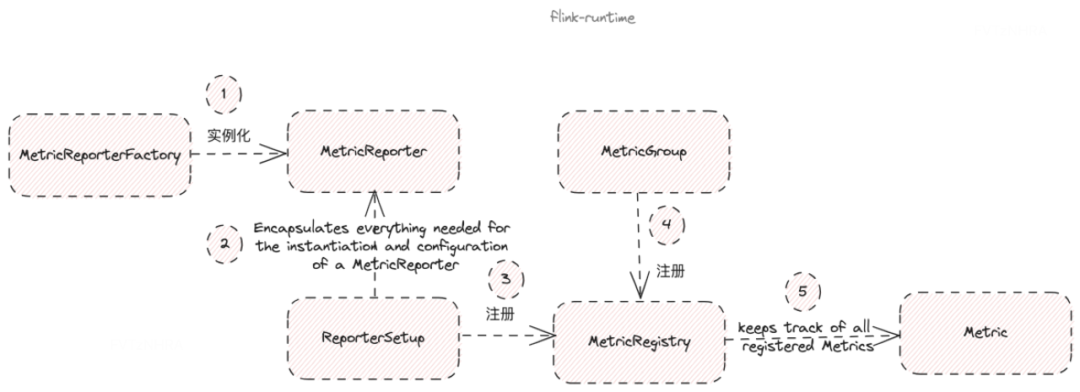
核心源码如下图所示:

总结一下,当 Flink 注册指标时,借助 MetricRegistry 的桥梁作用,最终将指标通知给了所有加载的 MetricReporter。因此,MetricReporter 在上报指标时,能够感知到 Flink job 中所有的指标。
周期上报
Flink 提供了周期性上报指标的能力,例如,滴滴内部的指标支持 10 秒和 1 分钟两种上报指标的频率,周期性上报指标为实时观测 Flink 任务运行的健康情况提供了可能。那么,Flink 是如何实现这一点的呢?
首先,我们需要了解接口 Scheduled,实现了 Scheduled 接口的 MetricReporter,Flink 会自动支持周期性上报的能力。

ReporterSetup 通过 SPI 的方式加载 MetricReporterFactory,在初始化 MetricReporter 后,同样会注册到 MetricRegistry。实现周期性上报的秘密,就在这里!

MetricRegistry 维护了一个 ScheduledExecutorService 线程池,根据 MetricReporter 配置的上报频率,周期性地触发 ReporterTask 的运行。ReporterTask 的定义一目了然,这里就不再赘述了。

一个例子 - 消费延迟指标是如何计算的?
在上一节关于 Flink 指标系统的弹性设计中,我们已经了解到 MetricReporter 主要负责将指标暴露给外部系统。同时,我们也介绍了 MetricReporter 如何感知 Flink 指标的注册,并能够周期性地上报这些指标。
除此之外,还有一个非常重要的环节值得我们关注:Flink 指标是如何计算的?
Flink 拥有众多的指标,其中包括许多内置的系统指标,它们的计算方式也各不相同。在这里,我将为大家介绍一个在日常工作中最为常见的指标:Flink 消费延迟指标。
消费延迟指标的计算公式如下(公式一):Max(数据进入 Flink Source 算子的机器时间 - 数据写入消息队列的时间)
那么,在源码层面,这个指标是如何计算并收集的呢?
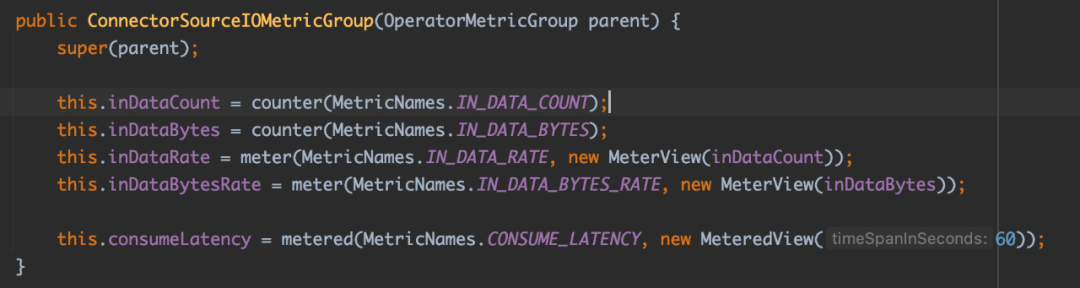
消费延迟指标是由 ConnectorSourceIOMetricGroup 注册的。当 Flink Connector 消费一条数据后,会触发一次「公式一」的计算。

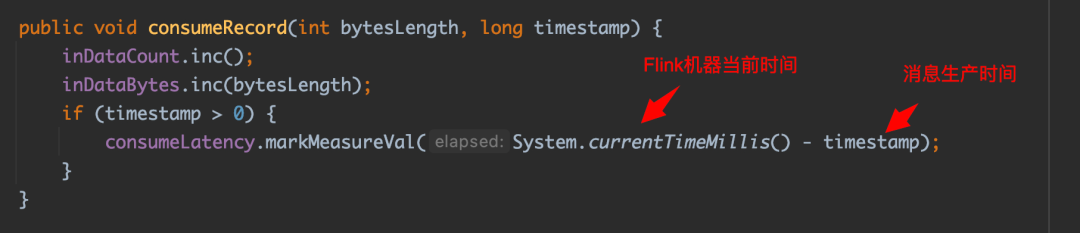
消息延迟指标最终由指标类型 MeteredView 计算,MeteredView 是上文提到的 Metered 和 View 接口的实现类。实现 View 接口主要是为了周期性地刷新指标的计算。
MeteredView 在内部维护了两个大小为 13 的循环数组,分别用于记录每次计算的消费延迟值和上报的次数。
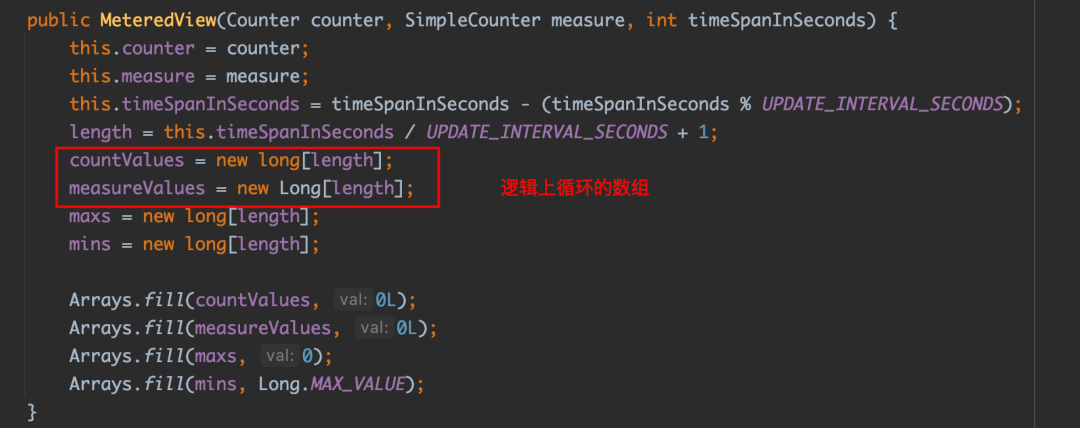
每次计算消费延迟指标时,会更新最近 5 秒内延迟指标的累积和以及上报次数。
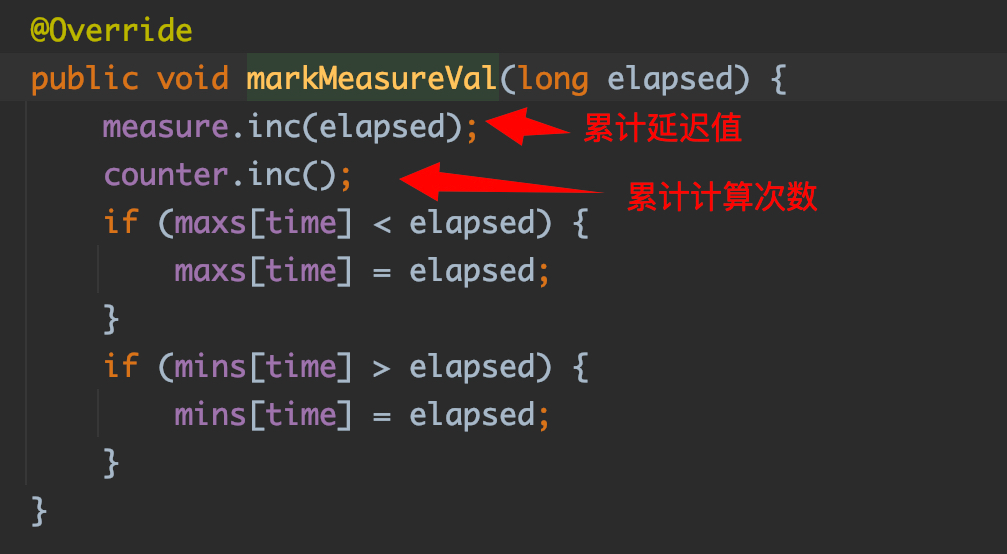
当 View 接口的 update 方法每 5 秒被触发执行时,会计算最近 1 分钟延迟指标的均值。
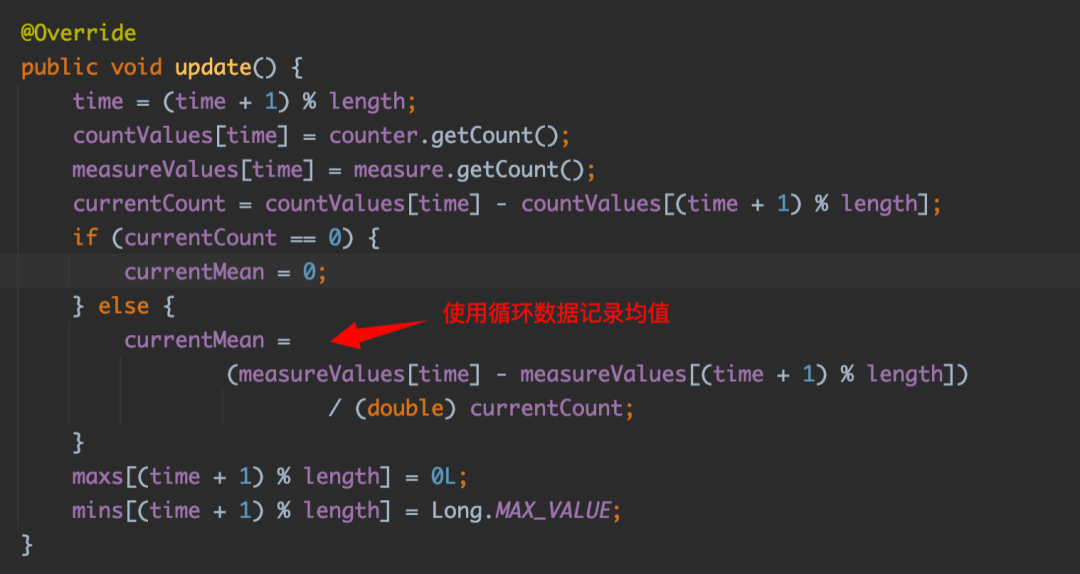
消费延迟指标最近 1 分钟的最大和最小值分别由两个数组维护,逻辑相对简单,这里就不再赘述了。
Flink 指标在滴滴内部的使用场景
Flink上报的指标在滴滴数据开发平台上的实时计算平台应用广泛,归纳来讲,主要有三类:
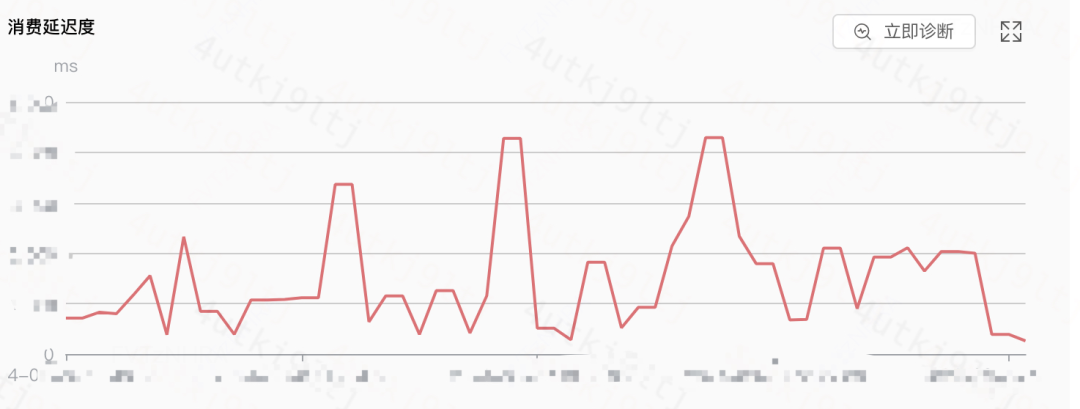
数据曲线
实时运维所看到的所有数据曲线指标均来源于本文所介绍的 Flink 指标系统。
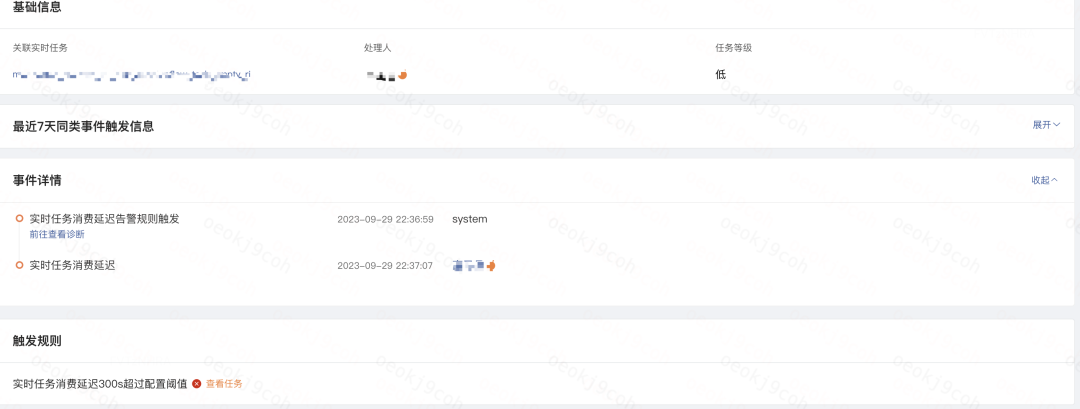
监控告警
滴滴数据开发平台实时任务的消费延迟告警、Checkpoint 失败监控告警等功能依赖于 Flink 指标系统上报的指标。这些指标经过加工清洗和任务维度聚合后,实时监控任务是否触发了告警阈值。
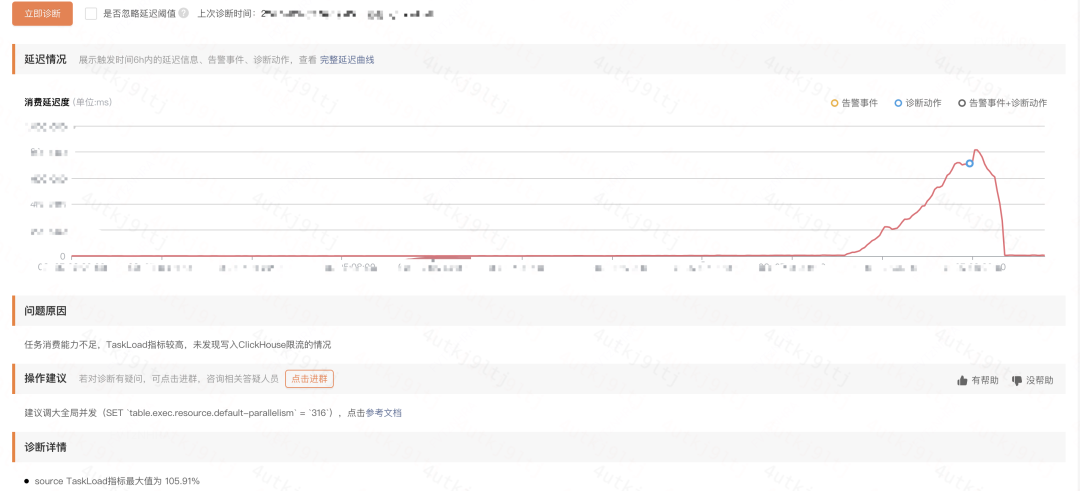
实时任务智能诊断
该功能的决策树依赖于大量的 Flink 指标。结合 Flink 指标的结果,可以诊断任务出现问题的原因所在。
总结
作为一名平台工程师,深入研究 Flink 指标的应用以及 Flink 指标系统的架构与实践,让我受益匪浅。在这个过程中,我不仅汲取了优秀框架的设计理念,还从平台的视角更加全面地理解了 Flink 指标的实际应用,从而更深刻地理解了 Flink 指标背后的深层含义。
如果您觉得这篇文章对您有所帮助,请不吝点赞。您的认可和鼓励将是我持续前行的动力!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)